
Hadoop的HA的搭建
在非高可用分布的集群的基础上进行搭建:
一般使用HDFS High Availability Using the Quorum Journal Manager此方式进行搭建。
Zookeeper部署:
1.tar -zxvf zookeeper-3.4.10.tar.gz -C ./ (解压zk到当前路径下)
2.在zookeeper-3.4.10/这个目录下创建zkData ,接着创建myid文件,写入2或者3.。。,代表zk的服务器id (mkdir -p zkData)
3.重命名zookeeper-3.4.10/conf这个目录下的zoo_sample.cfg为zoo.cfg(mv zoo_sample.cfg zoo.cfg)
4.具体配置zoo.cfg文件内容
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
5.分发zk到其他机器上
scp -r zookeeper-3.4.10/ root@hadoop2:/opt/app/
并更改相应的myid编号
--------------------------------------------------
配置参数解读
Server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
B是这个服务器的IP地址;
C是这个服务器与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
----------------------------------------------
命令步骤:
1、zk1、zk2、zk3分别启动journalnode
hadoop-daemon.sh start journalnode
2、在node01(NameNode)格式化 hdfs namenode -format (集群无数据可执行操作,有数据考虑备份或慎用此命令)
3. 查看结果,successful表示成功
4.在node01节点启动namenode hadoop-daemon.sh start namenode
5.在node02节点将namenode同步数据 hdfs namenode -bootstrapStandby
6.在node01节点让zkfc格式化 Zookeeper hdfs zkfc -formatZK
7.启动hdfs!!! start-dfs.sh
PS:如果是从单节点集群的基础上到HA,此时不需要高可用,只需要重新启动即可!!! 反之一样(从HA到单节点)
Hive及其他数据也会造成丢失!
出现问题:
DataNode起不来 ,或者namespaceID不一致情况
注:查看启动日志为.log文件而不是.out
查看DataNode节点日志报错为:
2017-11-06 14:21:40,779 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Got finalize command for block pool BP-597189047-192.168.2.21-1509948331108
2017-11-06 14:24:54,716 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: IOException in offerService
java.io.EOFException: End of File Exception between local host is: "test-hadoop-2-24/192.168.2.24"; destination host is: "test-hadoop-2-21":9000; : java.io.EOFException; For more details see: http://wiki.apach
e.org/hadoop/EOFException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:792)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:765)
at org.apache.hadoop.ipc.Client.call(Client.java:1480)
at org.apache.hadoop.ipc.Client.call(Client.java:1407)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy13.sendHeartbeat(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolClientSideTranslatorPB.sendHeartbeat(DatanodeProtocolClientSideTranslatorPB.java:153)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.sendHeartBeat(BPServiceActor.java:553)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.offerService(BPServiceActor.java:653)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:823)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.io.EOFException
at java.io.DataInputStream.readInt(DataInputStream.java:392)
at org.apache.hadoop.ipc.Client$Connection.receiveRpcResponse(Client.java:1079)
at org.apache.hadoop.ipc.Client$Connection.run(Client.java:974)
2017-11-06 14:24:57,231 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: RECEIVED SIGNAL 15: SIGTERM
2017-11-06 14:24:57,234 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DataNode at test-hadoop-2-24/192.168.2.24
************************************************************/
从上述启动日志未找到具体错误原因。接着去namenode节点或者DataNode节点去查找hadoop服务相关错误日志。
2020-11-24 14:17:48,517 INFO org.apache.hadoop.hdfs.server.common.Storage: Lock on /home/pirate/programs/hadoop/hadoopdata/dfs/data/in_use.lock acquired by nodename 26436@test-hadoop-2-24 2020-11-24 14:17:48,518 WARN org.apache.hadoop.hdfs.server.common.Storage: java.io.IOException: Incompatible clusterIDs in /home/pirate/programs/hadoop/hadoopdata/dfs/data: namenode clusterID = CID-88337611-91a2-4002-84a0-c556737eb225; datanode clusterID = CID-a2d38c48-545f-4f41-8c02-cf1d58841f52 2020-11-24 14:17:48,519 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to test-hadoop-2-22/192.168.2.22:8020. Exiting. java.io.IOException: All specified directories are failed to load. at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:477) at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1361) at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1326) at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:316) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:223) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:801) at java.lang.Thread.run(Thread.java:745) 2020-11-24 14:17:48,519 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to test-hadoop-2-21/192.168.2.21:8020. Exiting. java.io.IOException: All specified directories are failed to load. at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:477) at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1361) at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1326) at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:316) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:223) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:801) at java.lang.Thread.run(Thread.java:745) 2020-11-24 14:17:48,522 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Ending block pool service for: Block pool <registering> (Datanode Uuid unassigned) service to test-hadoop-2-22/192.168.2.22:8020 2020-11-24 14:17:48,522 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Ending block pool service for: Block pool <registering> (Datanode Uuid unassigned) service to test-hadoop-2-21/192.168.2.21:8020 2020-11-24 14:17:48,623 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Removed Block pool <registering> (Datanode Uuid unassigned)
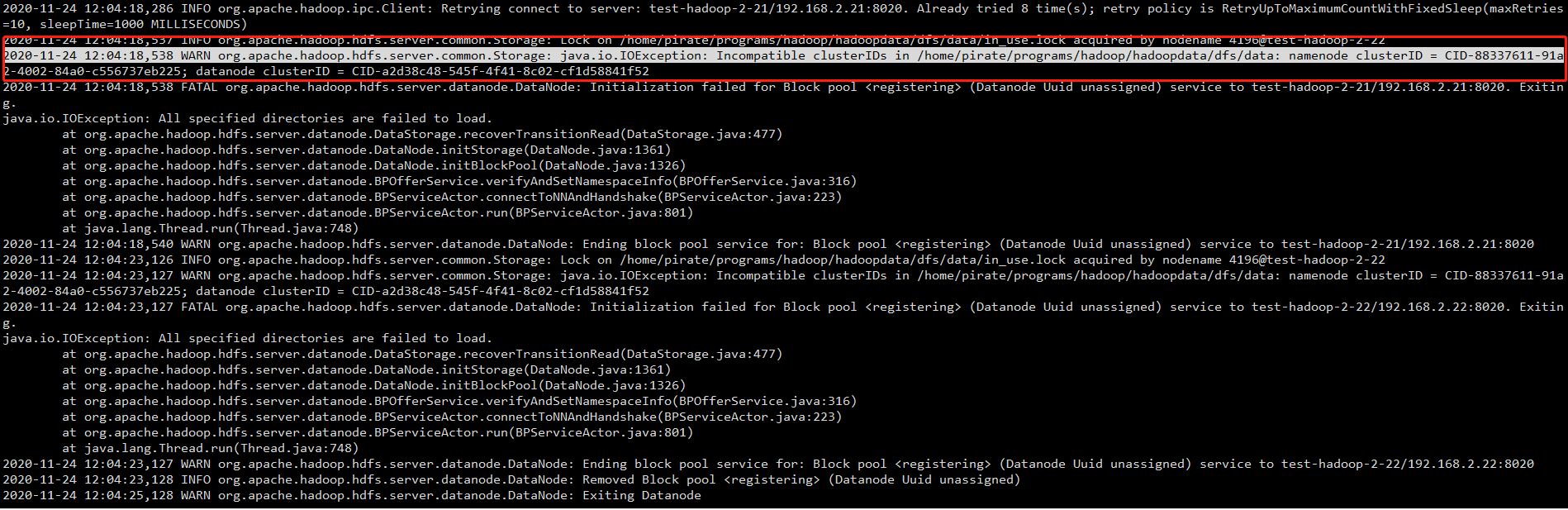
找到问题原因,然后参考上述问题链接,问题解决
实操参考:
NameNode的作用:
1、NameNode元数据信息
文件名,文件目录结构,文件属性(生成时间,副本数,权限)每个文件的块列表。
以及列表中的块与块所在的DataNode之间的地址映射关系
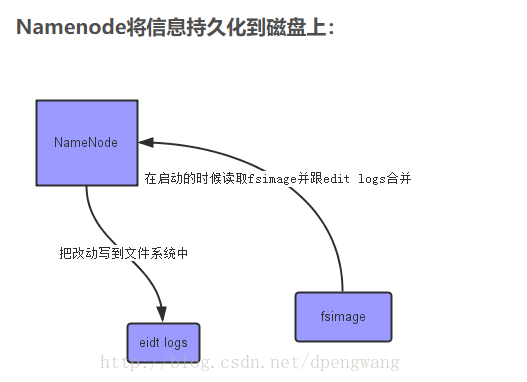
在内存中加载文件系统中每个文件和每个数据块的引用关系(文件、block、datanode之间的映射信息)
数据会定期保存到本地磁盘,但不保存block的位置信息而是由DataNode注册时上报和在运行时维护
2、NameNode文件操作
NameNode负责文件元数据的操作
DataNode负责处理文件内容的读写请求,数据流不经过NameNode,会询问它跟那个DataNode联系
3、NameNode副本
文件数据块到底存放到哪些DataNode上,是由NameNode决定的,NN根据全局情况做出放置副本的决定
读取文件的时候,NN尽量让client读取离它最近的datanode上的副本,降低带宽消耗和读取时延
4、NameNode职责
全权管理数据块的复制,周期性的接受心跳和块的状态报告信息(包含该DataNode上所有数据块的列表)
若接受到心跳信息,NN认为DN工作正常,如果在接收不到DN的心跳,那么NN认为DN已经宕机,这时候NN准备要把DN上的数据块进行重新的复制。
5、NameNode容错机制
没有Namenode,HDFS就不能工作。事实上,如果运行namenode的机器坏掉的话,系统中的文件将会完全丢失,因为没有其他方法能够将位于不同datanode上的文件块(blocks)重建文件。
NameNode在内存中保存着整个文件系统的名字空间和文件数据块的地址映射(Blockmap)。如果NameNode宕机,那么整个集群就瘫痪了
因此,namenode的容错机制非常重要,Hadoop提供了两种机制。
一、QJM((quorum journal manager))是一个专用的HDFS实现,为提供一个高可用的编辑日志而设计,被推荐用于大多数HDFS部署中。QJM以一组日志节点 Journalnode的形式运行,每一次编辑必须写入多数日志节点,典型的,有三个 journalnode节
点,所以系统能够忍受其中任何一个的丢失。
同一时间QJM仅允许一个namenode向编辑日志中写入数据。
二、
当使用NFS过滤器实现共享编辑日志时,不可能同一时间只允许一个namenode共享编辑日志。
HDFS HA升级操作步骤:
1、zk1、zk2、zk3分别启动journalnode hadoop-daemon.sh start journalnode
--2、在node01(NameNode)格式化 hdfs namenode -format (慎用)
--3. 查看结果,successful表示成功
4.hadoop-daemon.sh stop namenode (不关闭的话,则会报错in use directory lock之类的错误)
5.在node01节点让zkfc格式化 Zookeeper hdfs zkfc -formatZK (如果要将非HA NameNode转换为HA,则应运行命令“ hdfs namenode -initializeSharedEdits ” )
6.在node01节点启动namenode hadoop-daemon.sh start namenode (启动为standby状态,便于向node02节点拷贝数据)
7.在node02节点将namenode同步数据 hdfs namenode -bootstrapStandby
hdfs zkfc -formatZK
8.启动hdfs start-dfs.sh
常见问题:
一、当时用start-all.sh 或者start-dfs.sh时,报错日志类似为:(java.io.IOException: There appears to be a gap in the edit log. We expected txid 1, but got txid 3.)
启动名称节点并启用恢复标志。看日志报错其实为hadoop元数据不匹配,
存储hadoop元数据的地方一般有journalnode节点和namenode相关节点,校验元数据是否一致,然后决定以什么位置的元数据为主。如果集群数据不关心丢失,则可以使用以下命令
(此命令慎用,会造成数据丢失,)
./bin/hadoop namenode -recover
二、安全模式问题处理:
hdfs dfsadmin -safemode get
hadoop dfsadmin -safemode leave (强制离开,会丢失数据)
三、可以在core-site.xml文件中修改ha.health-monitor.rpc-timeout.ms参数值,来扩大zkfc监控检查超时时间(优化)。
ha.health-monitor.rpc-timeout.ms 180000
ha.zookeeper.session-timeout.ms 20000
<property>
<name>ha.health-monitor.rpc-timeout.ms</name>
<value>180000</value>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>20000</value>
</property>
四、hadoop处于active状态, shell命令访问集群却处于standby状态
在mapred-site.xml增加配置
<property>
<name> fs.defaultFS </ name>
<value> hdfs:// mycluster </ value>
</property>
常用命令:
将active的NameNode从nn1切换到nn2 。
hdfs haadmin -DfSHAadmin -failover nn1 nn2
hdfs haadmin -getServiceState nn1
hdfs haadmin -transitionToActive/transitionToStandby -forcemanual nn1
hdfs haadmin -transitionToStandby -forcemanual nn1
hdfs haadmin -transitionToActive -forcemanual nn1
hdfs getconf -confKey fs.default.name
更改HIVE元数据:
SDS、DBS表(这两个表存有与hadoop 集群节点相关的地址)
select replace(LOCATION,'hdfs://hadoop01:8020','hdfs://mycluster') from SDS ;
update SDS set LOCATION = replace(LOCATION,'hdfs://hadoop01:8020','hdfs://mycluster');
update DBS set DB_LOCATION_URI = replace(DB_LOCATION_URI,'hdfs://hadoop01:8020','hdfs://mycluster');
update SDS set LOCATION = replace(LOCATION,'hdfs://mycluster','hdfs://hadoop01:8020');
update DBS set DB_LOCATION_URI = replace(DB_LOCATION_URI,'hdfs://mycluster','hdfs://hadoop01:8020');
具体HA参考官网:
posted on 2020-11-16 00:04 RICH-ATONE 阅读(326) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号