

zk的基础知识基本分为三大模块
- 数据模型
- ACL 权限控制
- Watch 监控
数据模型
默认配置文件
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
- tickTime client-server 通信心跳时间
- zk 服务器之间或client 与服务器之间维持心跳的时间间隔、也就是每个tickTime 就会发送一个心跳、tickTime 以毫秒为单位
- initLimit leader-follower 初始通信时限
- 集群中 follower 与leader 之间初始连接时最多能容忍的最多心跳数 。
- syncLimit leader follower 同步通信时限
- follower与 leader 服务器请求与应答之间能容忍的最多心跳数
- dataDir 数据目录
启动zk
bin/zkServer.sh start
使用客户端连接
bin/zkCli.sh -server 127.0.0.1:2181
create /locks ""
create /servers ""
create /works ""
成功创建之后,命令窗口显示
Created /servers

1. 不支持递归创建,必须先创建父节点
2. 节点不能以 / 结尾,会直接报错
3. ZooKeeper 树中的每一层级用斜杠(/)分隔开, 且只能用绝对路径(如“get /work/task1”)的方式查询 ZooKeeper 节点, 而不能使用相对路径
数据模型是一种树形结构 。
znode 节点类型与特性
zk中的数据节点也分为持久节点、临时节点和顺序节点 。
持久节点
持久节点一旦创建、该数据节点会一直存储在zk服务器上、即使创建该节点的客户端与服务端的会话关闭了、该节点也不会被删除
临时节点
如果将节点创建为临时节点、那么该节点数据不会一只存储在zk服务器上、当创建该临时节点的客户端绘画因超时或发生异常而关闭时、该节点也相应的在zk上被删除 。
有序节点
有序节点并不是一种单独种类的节点、而是在吃酒节点和临时节点的基础上、增加了一个节点有序的性质 。
create -s /sequence-node- ""
Created /sequence-node-0000000017
第二次
create -s /sequence-node- ""
Created /sequence-node-0000000018
.......
.......
上述几种数据节点虽然类型不同、但zk中每个节点都维护有这些内容:一个二进制数组(用来存储节点数据)、ACL访问控制信息、子节点数据(因为临时节点不允许有子节点、所以其子节点字段为null)、自身状态信息字段stat 。
节点的状态结构
get /servers stat /servers
返回的结果
cZxid = 0x4f0
ctime = Thu May 07 21:53:04 CST 2020
mZxid = 0x4f0
mtime = Thu May 07 21:53:04 CST 2020
pZxid = 0x4f0
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 0
- cZxid 创建这个节点的事务id
- ctime 创建这个节点的时间
- mZxid 修改这个节点的事务id
- mtime 修改这个节点的时间
- pZxid 表示该节点的子节点列表最后一次被修改时的事务id
- cversion 这表示对此znode的子节点进行的更改次数
- dataVersion 表示对该znode的数据所做的更改次数
- aclVersion 表示对此znode的ACL进行更改的次数
- ephemeralOwner 如果该节点是临时节点、那么此字段记录的是znode所有者的sessionId、如果不是则为0
- dataLength znode 数据字段的长度 .
- numChildre znode 子节点的数量
使用zookeeper实现锁
针对超卖问题、使用zk实现锁
悲观锁
认为对临界区的竞争总是会出现、为了保证在操作数据时、该数据不被其他进程修改、数据一直会处于锁定的状态 。
我们假设一个具有 n 个进程的应用,同时访问临界区资源,我们通过进程创建 ZooKeeper 节点 /locks 的方式获取锁。
线程 a 通过成功创建 ZooKeeper 节点“/locks”的方式获取锁后继续执行,如下图所示:
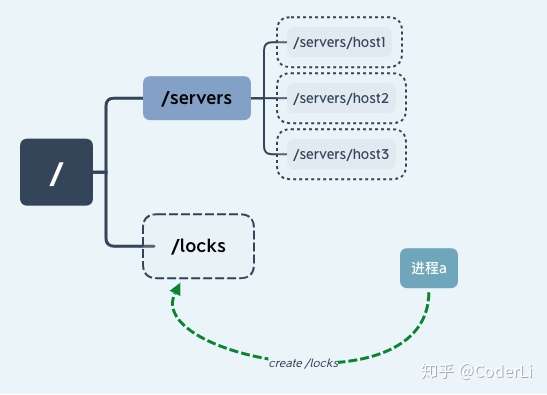
线程 a 通过成功创建 ZooKeeper 节点“/locks”的方式获取锁后继续执行,如下图所示:
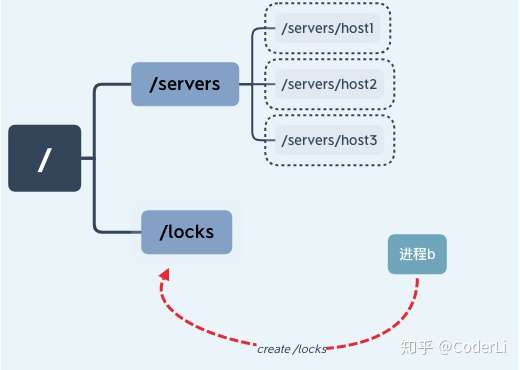
这样就实现了一个简单的悲观锁,不过这也有一个隐含的问题,就是当进程 a 因为异常中断导致 /locks 节点始终存在,其他线程因为无法再次创建节点而无法获取锁,这就产生了一个死锁问题。针对这种情况我们可以通过将节点设置为临时节点的方式避免。并通过在服务器端添加监听事件来通知其他进程重新获取锁。
乐观锁
进程对临界区资源的竞争不会总是出现、所以相对悲观锁而已、假锁方式没那么激烈、不会全程锁定资源、而是在数据进行提交更新的时候、对数据的冲突与否进行检查、如果发现冲突了、则拒绝操作
乐观锁基本都是CAS、CAS有三个操作数、内存值V、旧的预期值A、修改的新值B、当预期值与内存值V 相等时、才将内存值V改成B
在zk中的version 属性就是用来实现乐观锁机制中的检验的、zk中每个节点都有 dataVersion 这个字段、在调用更新操作的时候、加入有一个客户端试图进行更新操作、他会携带上次获取到的version值进行更新、如果在这段时间内、zk服务器上该节点的数值恰好已经被其他客户端更新了、那么 dataVersion一定发生变化、那么与当前客户端的version 无法匹配、便无法更新
在 ZooKeeper 的底层实现中,当服务端处理 setDataRequest 请求时,首先会调用 checkAndIncVersion 方法进行数据版本校验。ZooKeeper 会从 setDataRequest 请求中获取当前请求的版本 version,同时通过 getRecordForPath 方法获取服务器数据记录 nodeRecord, 从中得到当前服务器上的版本信息 currentversion。如果 version 为 -1,表示该请求操作不使用乐观锁,可以忽略版本对比;如果 version 不是 -1,那么就对比 version 和 currentversion,如果相等,则进行更新操作,否则就会抛出 BadVersionException 异常中断操作。
思考问题
为啥zk不采用相对路径来查找结点?
这是因为 ZooKeeper 大多是应用场景是定位数据模型上的节点,并在相关节点上进行操作。像这种查找与给定值相等的记录问题最适合用散列来解决。因此 ZooKeeper 在底层实现的时候,使用了一个 hashtable,即 hashtableConcurrentHashMap<String, DataNode> nodes ,用节点的完整路径来作为 key 存储节点数据。这样就大大提高了 ZooKeeper 的性能。
新版本
zookeeper 3.5.x 中引入了 container 节点 和 ttl 节点(不稳定)
- container 节点用来存放子节点,如果container节点中的子节点为0 ,则container节点在未来会被服务器删除。
- ttl 节点默认禁用,需要通过配置开启, 如果ttl 节点没有子节点,或者 ttl 节点在 指定的时间内没有被修改则会被服务器删除。
https://www.cnblogs.com/skyl/p/4854553.html
https://www.cnblogs.com/IcanFixIt/p/7846361.html
https://kaiwu.lagou.com/course/courseInfo.htm?courseId=158#/detail/pc?id=3131

 浙公网安备 33010602011771号
浙公网安备 33010602011771号