
一步一步从原理跟我学邮件收取及发送 10.四句代码说清base64
经过前几篇的文章,大家应该都能预感到一定要讲解 base64 函数的内容了。是的,马上要到程序登录的代码,base64 是必须要实现的。
base64 很早以前我就接触了,在项目中也很喜欢用。但每换一个新语言我总是很害怕,很排斥用它。这主要是缘于曾经的经历:多年前 base64 还没有这样普及,为了在 java 中使用 base64 找了很多的代码,虽然 jdk 中是有,但那是 sun 专用的,在网上找倒是很多,但要自己改造一下是非常的困难(其实是 java 的语言特性导致很复杂,base64 本身还是很简单的)。因为找了很多的文档一直都似懂非懂,因为不懂嘛,所以心理上就有排斥。直到我接了一个 xmpp 的项目必须要在纯 C 中实现 base64 时仔细研究了一下,其实是很简单的。说实在的关于 base64 的文章和前面提到的多线程文章一样也挺汗牛充栋的,为什么我不讲解多线程,要特别讲解 base64 呢?
因为我觉得网上的 base64 讲解文章基本上都是没用的!所以我一定要再写一篇。而我这篇,我保证您一定能看得懂!
首先我先给出完整代码,大家也可以到 github 地址去下载:
https://github.com/clqsrc/c_lib_lstring/tree/master/base64
核心的代码直接就来自博客园的博友,在 rfc 文档和其他一些地方也很容易找到。我直接再贴一个 C++ 的版本,这些代码我都默认折叠了,因为先看代码你是学不会的。


//算法来自 http://www.cnblogs.com/IwAdream/p/6088283.html, 加了我自己的注释 //基本上就是靠移位算法将 3 个字节变成 4 个字节,或者将 4 个字节变成 三个字节 //可以看 https://zh.wikipedia.org/wiki/Base64 中的表格图示 //图片可以在本源码中附带的 base64.png 中看到[如果转载的网友也转载有图片的话就会有] //其实一张图就能明白它的原理 //把变量提前以便更多编译器支持 #ifndef _BASE64_H_ #define _BASE64_H_ #include <stdio.h> #include <stdint.h> //clq 这个其实也不是必须的 #include <string.h> #include <malloc.h> //clq 可以不用,有时会冲突 char base64_table[] = { 'A','B','C','D','E','F','G','H','I','J', 'K','L','M','N','O','P','Q','R','S','T', 'U','V','W','X','Y','Z','a','b','c','d', 'e','f','g','h','i','j','k','l','m','n', 'o','p','q','r','s','t','u','v','w','x', 'y','z','0','1','2','3','4','5','6','7', '8','9','+', '/', '\0' }; void base64_map(uint8_t *in_block, int len) { int i = 0; for(i = 0; i < len; ++i) { in_block[i] = base64_table[in_block[i]]; //printf("%d %c",in_block[i], base64_table[in_block[i]]); } if(len % 4 == 3) in_block[len] = '='; else if(len % 4 == 2) in_block[len] = in_block[len+1] = '='; return ; } void base64_unmap(char *in_block) { int i; char *c; int decode_count = 0; for(i = 0; i < 4; ++i) { c = in_block + i; if(*c>='A' && *c<='Z') { *c -= 'A'; continue; } if(*c>='a' && *c<='z') { *c -= 'a'; *c += 26; continue; } if(*c == '+') { *c = 62; continue; } if(*c == '/') { *c = 63; continue; } if(*c == '=') { *c = 0; continue; } *c -= '0'; *c += 52; } } int _base64_encode(char *in, int inlen, uint8_t *out) { char *in_block; uint8_t *out_block; char temp[3]; int outlen = 0; //clq add 加一个解码后的数据长度 int i = 0; out_block = out; in_block = in; for(i = 0; i < inlen; i += 3) { memset(temp, 0, 3); memcpy(temp, in_block, i + 3 < inlen ? 3 : inlen - i); memset(out_block, 0, 4); //memset(out_block, '=', 4); //好象也不用 out_block[0] = (temp[0] >> 2) & 0x3f; out_block[1] = ((temp[0] << 4) & 0x30) | ((temp[1] >> 4) & 0x0f); out_block[2] = ((temp[1] << 2) & 0x3c) | ((temp[2] >> 6) & 0x03); out_block[3] = (temp[2]) & 0x3f; //printf("%.2x %.2x %.2x\n", temp[0], temp[1], temp[2]); //printf("%.2x %.2x %.2x %.2x\n", out_block[0], out_block[1], out_block[2], out_block[3]); out_block += 4; in_block += 3; outlen += 4; //clq add 加一个编码后的数据长度 } base64_map(out, ((inlen * 4) - 1) / 3 + 1); return outlen; } int _base64_decode(char *in, int inlen, uint8_t *out) { char *in_block; uint8_t *out_block; char temp[4]; int outlen = 0; //clq add 加一个解码后的数据长度 int i = 0; out_block = out; in_block = in; for(i = 0; i < inlen; i += 4) { if(*in_block == '=') return 0; memcpy(temp, in_block, 4); memset(out_block, 0, 3); base64_unmap(temp); out_block[0] = ((temp[0]<<2) & 0xfc) | ((temp[1]>>4) & 3); out_block[1] = ((temp[1]<<4) & 0xf0) | ((temp[2]>>2) & 0xf); out_block[2] = ((temp[2]<<6) & 0xc0) | ((temp[3] ) & 0x3f); out_block += 3; in_block +=4; outlen += 3; //clq add 加一个解码后的数据长度//这个长度其实不对,因为不一定是 3 的倍数 //if (temp[3] == '=') outlen -= 1; //clq add 有一个等号就表示补充了一个字节//优化放到最后去好了 //if (temp[3] == '=') outlen -= 1; //clq add 有一个等号就表示补充了一个字节//优化放到最后去好了 } if (in[inlen-1] == '=') outlen -= 1; //clq add 有一个等号就表示补充了一个字节//优化放到最后去好了 if (in[inlen-2] == '=') outlen -= 1; //clq add 有一个等号就表示补充了一个字节//优化放到最后去好了 //return 0; return outlen; //clq add 加一个解码后的数据长度 } /* int main2() { char cipher_text[64]; int i = 0; while(scanf("%s", cipher_text) != EOF) { printf("%s\n", cipher_text); uint8_t *tran_cipher = (uint8_t *)malloc(sizeof(uint8_t) * 64); memset(tran_cipher, 0, sizeof(uint8_t) * 64); #define ENCODE #define DECODE #ifdef ENCODE printf("----------------ENCODE-----------------"); base64_encode(cipher_text, strlen(cipher_text), tran_cipher); int len = (strlen(cipher_text) * 4 - 1) / 3 + 1; len = len % 4 == 3 ? len + 1 : len + 2; for(i = 0; i < len ; ++i) printf("%c", tran_cipher[i]); printf("\n"); #endif // ENCODE #ifdef DECODE printf("----------------DECODE-----------------"); base64_decode(cipher_text, strlen(cipher_text), tran_cipher); len = strlen(cipher_text); int n = len; while(cipher_text[--n] == '=') ; if(n == len-2) len = (len >> 2) * 3 - 1; else if(n == len-3) len = (len >> 2) * 3 - 2; else if(n == len-1) len = (len >> 2) * 3; for(i = 0; i < len; ++i) printf("%c", tran_cipher[i]); printf("\n"); #endif // DECODE } return 0; } */ #endif
/* base64.cpp and base64.h Copyright (C) 2004-2008 René Nyffenegger This source code is provided 'as-is', without any express or implied warranty. In no event will the author be held liable for any damages arising from the use of this software. Permission is granted to anyone to use this software for any purpose, including commercial applications, and to alter it and redistribute it freely, subject to the following restrictions: 1. The origin of this source code must not be misrepresented; you must not claim that you wrote the original source code. If you use this source code in a product, an acknowledgment in the product documentation would be appreciated but is not required. 2. Altered source versions must be plainly marked as such, and must not be misrepresented as being the original source code. 3. This notice may not be removed or altered from any source distribution. René Nyffenegger rene.nyffenegger@adp-gmbh.ch */ #include "stdafx.h" #include "base64.h" #include <iostream> static const std::string base64_chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" "abcdefghijklmnopqrstuvwxyz" "0123456789+/"; static inline bool is_base64(unsigned char c) { return (isalnum(c) || (c == '+') || (c == '/')); } std::string base64_encode(unsigned char const* bytes_to_encode, unsigned int in_len) { std::string ret; int i = 0; int j = 0; unsigned char char_array_3[3]; unsigned char char_array_4[4]; while (in_len--) { char_array_3[i++] = *(bytes_to_encode++); if (i == 3) { char_array_4[0] = (char_array_3[0] & 0xfc) >> 2; char_array_4[1] = ((char_array_3[0] & 0x03) << 4) + ((char_array_3[1] & 0xf0) >> 4); char_array_4[2] = ((char_array_3[1] & 0x0f) << 2) + ((char_array_3[2] & 0xc0) >> 6); char_array_4[3] = char_array_3[2] & 0x3f; for(i = 0; (i <4) ; i++) ret += base64_chars[char_array_4[i]]; i = 0; } } if (i) { for(j = i; j < 3; j++) char_array_3[j] = '\0'; char_array_4[0] = (char_array_3[0] & 0xfc) >> 2; char_array_4[1] = ((char_array_3[0] & 0x03) << 4) + ((char_array_3[1] & 0xf0) >> 4); char_array_4[2] = ((char_array_3[1] & 0x0f) << 2) + ((char_array_3[2] & 0xc0) >> 6); char_array_4[3] = char_array_3[2] & 0x3f; for (j = 0; (j < i + 1); j++) ret += base64_chars[char_array_4[j]]; while((i++ < 3)) ret += '='; } return ret; } std::string base64_decode(std::string const& encoded_string) { //-------------------------------------------------- //clq add //-------------------------------------------------- int in_len = encoded_string.size(); int i = 0; int j = 0; int in_ = 0; unsigned char char_array_4[4], char_array_3[3]; std::string ret; while (in_len-- && ( encoded_string[in_] != '=') && is_base64(encoded_string[in_])) { char_array_4[i++] = encoded_string[in_]; in_++; if (i ==4) { for (i = 0; i <4; i++) char_array_4[i] = base64_chars.find(char_array_4[i]); char_array_3[0] = (char_array_4[0] << 2) + ((char_array_4[1] & 0x30) >> 4); char_array_3[1] = ((char_array_4[1] & 0xf) << 4) + ((char_array_4[2] & 0x3c) >> 2); char_array_3[2] = ((char_array_4[2] & 0x3) << 6) + char_array_4[3]; for (i = 0; (i < 3); i++) ret += char_array_3[i]; i = 0; } } if (i) { for (j = i; j <4; j++) char_array_4[j] = 0; for (j = 0; j <4; j++) char_array_4[j] = base64_chars.find(char_array_4[j]); char_array_3[0] = (char_array_4[0] << 2) + ((char_array_4[1] & 0x30) >> 4); char_array_3[1] = ((char_array_4[1] & 0xf) << 4) + ((char_array_4[2] & 0x3c) >> 2); char_array_3[2] = ((char_array_4[2] & 0x3) << 6) + char_array_4[3]; for (j = 0; (j < i - 1); j++) ret += char_array_3[j]; } return ret; }
java 里一直到 jdk1.6 才有正式的 base64 函数,ios 的开发工具 xcode 的支持也很晚,搞得到处都是各种 base64 的讲解和第三方代码,甚至我最喜欢的 delphi 里都有不同的控件实现了不同的版本。给人的印象就成了这东西一定很难啊,没事别去碰。
所以我一语道破天机的话,接触过 base64 的网友一定会跌破一地的眼镜:其实 base64 的核心算法只有 4 行代码! 是的就是只需要 4 行! 其他的代码不过是补充字节不足,找数字和字符串进行映射转换而已。
base64 其实就是将 3 个字节的字符串变成 4 个字节的字符串。就这么简单。然后再规定了一下字符串不够 3 个字节的话怎样补充而已。至于超过 3 字节的字符串嘛,是个人都明白:分割成多个 3 字节的循环就可以了。至于解码,反过来 4 字节的结果变成 3 个原文的就行了呗,所以根本不用讲解解码,我们讲解编码过程就行了。
讲解编码过程时先说下原因大家就更好理解,base64 产生的原因是要将文件中的二进制内容以可见的字符串发送出去(或者是类似的地方传输)。为什么要转换成可见的字符呢?大家看到前面的内容应该都知道网络协议基本上就是一些命令字符串了吧。那么假如要传输的内容有 '\0' '\1' '\2' 这样的内容显然就不行了嘛。所以想个办法把它们变成 'a' 'b' 'c' 就行了嘛。全部的字符嘛有 256 个,需要 8 个字节来表示(2的8次方嘛),可见的字符没有这么多,全部一对一的肯定不行。我们假设只有 64 个可见字符,怎样去表示这 256 个实际字符呢。很简单,每个字节是8位的,所以需要 256 个字符来表示才够,那把它变成每个字节 6 位的(2的6次方是64)不就行了吗。用二进制的模拟一下大家会更深清楚这个算法:
----------------
1|2|3|4|5|6|7|8|
----------------
=>
-------------
|1|2|3|4|5|6|
-------------
用计算机术语来说相当于将 8 位机换成了 6 位机。但是因为我们现在都是 8 位机(当然实际是32位或者64位,8位数据只是兼容而已)。所以变通一下,用8位地址表示 6 位的数据就行了,这样的话前两位就固定为 0 ,而数据向右移动一下就可以了,如下图:
----------------
1|2|3|4|5|6|7|8|
----------------
=>
----------------
0|0|1|2|3|4|5|6|
----------------
好了,这就是 base64 算法!这也是为什么所有的 base64 编码算法都有移位运算符。
等等,你会说,那第7、8位置上的数据岂不是丢失了。这个好办啊,放到下一个字节上就行了呗。4个保存6位数据的字节刚好可以保存住3个保存8位数据的字节嘛(因为它们都能表示24位二进制数据,3x8=24 4x6=24 嘛)。这个"巧合"应该也是前人选择用 64 个可见字符而不是其他数目的原因之一吧。用图形表示那真是再明白不过了:
---------------- ---------------- ----------------
1|2|3|4|5|6|7|8| 1|2|3|4|5|6|7|8| 1|2|3|4|5|6|7|8|
---------------- ---------------- ----------------
=>
---------------- ---------------- ---------------- ----------------
0|0|1|2|3|4|5|6| 0|0|7|8|1|2|3|4| 0|0|5|6|7|8|1|2| 0|0|3|4|5|6|7|8|
---------------- ---------------- ---------------- ----------------
在 base64 中的 wiki 文档中也有类似的图形,实际上我上面的图示就是受了 wiki 的启发。如图: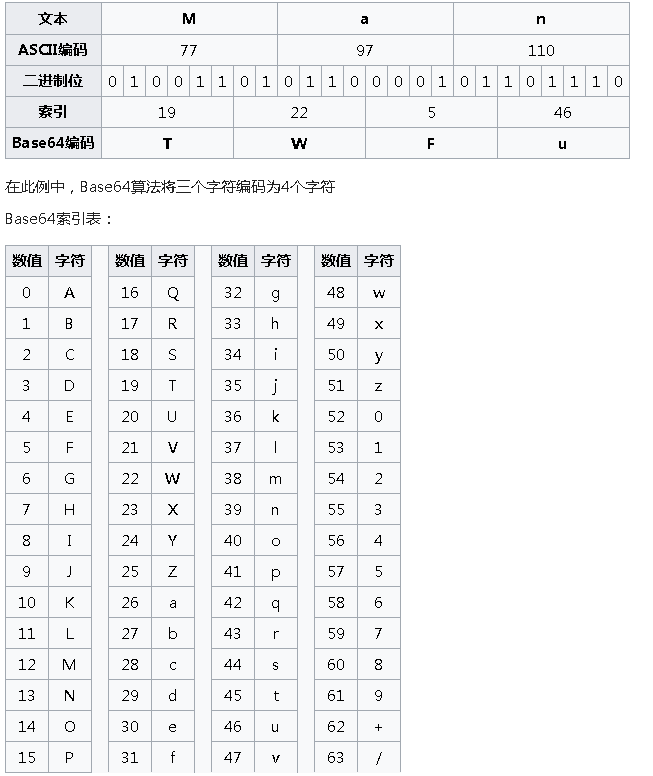
上面的文字表格可能排版后不太好看,我再传张图片吧:

移位操作用 java 来讲解就太不合适了,所以我们只讲解 C 语言的代码,更直观。代码中唯一要注意的是队了第一个字节可以直接通过移位来得到外,其他三个字节的数据,都要从源数据的两个字节中同时得到一部分"组合"起来(算法如此,实际上第四个字节刚好只来自于源数据的第三个字节的后半部分)。组合两个个字节的运算大家在大学应该都学过了,那就是二进制的 "或" 操作。所以这篇文章虽然我自认为应该人人都能懂,不过也要读者上过基本的计算机原理课程。所以大学的教育并不是很多程序员认为的那样不实用 -- 那些都是有用的基础。在后面的文章中大家还会看到需要大学课程内容的部分。我知道有很多程序员是非科班的,那确实应该用业余时间内自己补充一下专业课程。要不确实有很多东西是不易理解的。比如没学过汇编语言并实机操作的话恐怕是永远也理解不了指针的。当然优秀的程序员与是否科班出身没有什么关系。
有了以上的知识,再来看看算法的核心,基本上就是不用讲解了(当然了我们还是要再讲解一下)。
核心的代码非常的简单,就象我们开始说的那样,只要4句话:
out_block[0] = (temp[0] >> 2) & 0x3f; out_block[1] = ((temp[0] << 4) & 0x30) | ((temp[1] >> 4) & 0x0f); out_block[2] = ((temp[1] << 2) & 0x3c) | ((temp[2] >> 6) & 0x03); out_block[3] = (temp[2]) & 0x3f;
除了移位和 "或" 操作外,还用了 "与" 操作来去掉无关的数据位。与 0x3f 进行 "与" 操作是为了将前两位置成 0 。与其他数字进行 "与" 操作的作用类似,只是要置 0 的位置不同罢了。
结合前面的图示,这4句话的意思如下:
1.第一个结果字节直接来自原文第一个字节移位,再保证前两位是空就行了;
2.第二个结果字节由原文第一个字节和第二个字节的各一部分组成;
3.第三个结果字节由原文第二个字节和第三个字节的各一部分组成;
4.第四个结果字节直接来自原文第三个字节,并且不用移位,再保证前两位是空就行了.
另外一份的 C++ 代码,算法思想也是一样的,只是处理方法略有差异而已,大家有兴趣可以自己分析。具体如下:
char_array_4[0] = (char_array_3[0] & 0xfc) >> 2; char_array_4[1] = ((char_array_3[0] & 0x03) << 4) + ((char_array_3[1] & 0xf0) >> 4); char_array_4[2] = ((char_array_3[1] & 0x0f) << 2) + ((char_array_3[2] & 0xc0) >> 6); char_array_4[3] = char_array_3[2] & 0x3f;
我个人觉得前面的 C 代码更清晰直接,所以用 C 的代码进行的讲解。其他补位、字符映射、变种什么的实在不用说了,明白了前面的算法一通百通,大家可以自己去看 wiki 或者其他文章,wiki 的链接为:
https://zh.wikipedia.org/wiki/Base64
有了这部分代码,电子邮箱的登录过程就易如反掌。具体可以到文末链接下载,核心代码非常简单:
//用 base64 登录 s = NewString("AUTH LOGIN\r\n", m); SendBuf(gSo, s->str, s->len); rs = RecvLine(gSo, m, &buf); //只收取一行 printf("\r\nRecvLine:%s\r\n", rs->str); s = NewString("test1@newbt.net", m); //要换成你的用户名,注意 163 邮箱的话不要带后面的 @域名 部分 s = base64_encode(s); LString_AppendConst(s,"\r\n"); SendBuf(gSo, s->str, s->len); rs = RecvLine(gSo, m, &buf); //只收取一行 printf("\r\nRecvLine:%s\r\n", rs->str); s = NewString("123456", m); //要换成您的密码 s = base64_encode(s); LString_AppendConst(s,"\r\n"); SendBuf(gSo, s->str, s->len); rs = RecvLine(gSo, m, &buf); //只收取一行 printf("\r\nRecvLine:%s\r\n", rs->str);
为了避免大家误以为 lstring 很庞杂,所以我特意把 base64 的代码放到一个独立目录,实际写程序时最好还是放到同一个目录中比较方便.本章节的完整源码可以到以下地址下载(附带了那份 C++ 的代码,实际上并不需要编译它):
https://github.com/clqsrc/c_lib_lstring/tree/master/email_book/book_10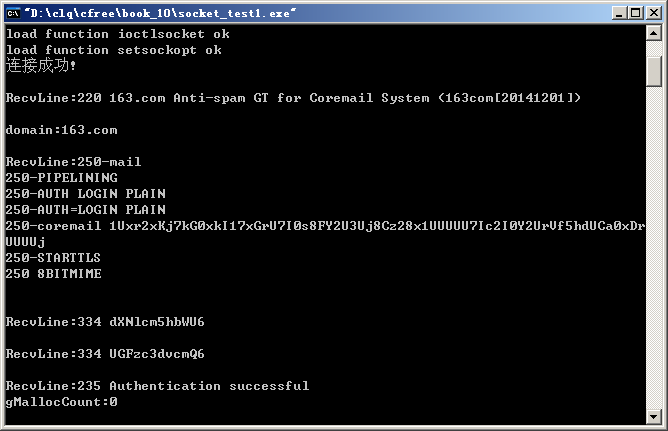
(成功登录的运行截图)
--------------------------------------------------
版权声明:
本系列文章已授权百家号 "clq的程序员学前班" . 文章编排上略有差异.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号