缓存雪崩与一致性hash
缓存雪崩介绍
选择缓存,都是为了提供“高速”的查询服务,这个“高速”是指数据库扛不住的高速,比如对于redis或者memcache来说,5万QPS不值一提,但是对于MySQL来说,上千QPS就要引起重视了。
以redis为例,如果一个数据从DB查出来放入redis缓存后,之后的查询直接在redis中进行,这样可以避免高并发的访问数据库,降低数据库的负载;
但是,如果redis服务器宕机,或者redis服务器中的数据过期了(大量过期),那么就会进行数据库查询,如果QPS很高(比如上万),那么数据库的压力可想而知,轻轻松松压垮数据库。
缓存雪崩的解决方案
数据过期导致的雪崩不是特别好处理,因为数据要过期,总不能让人家不过期吧,不过期,难道使用过期数据吗?
既然过期了就要查询数据库,压垮数据库的原因就是高并发连接数据库执行sql,那么可以根据自己的业务进行优化(没有绝对的解决方式),比如过期时间能否岔开,或者过期时间设置的更短一点;
除此之外,还应该控制数据库连接池中的连接,当数据库的连接池用完后,应用程序就会阻塞,但是数据库是不会崩溃的。由于连接池用完,大量请求被阻塞,服务短暂不可用,但是可以采取其他的手段,比如熔断、降级、限流。服务和数据库不挂,事情就不算太差。
但是对于redis服务器宕机引起的雪崩,一般就是依靠一致性哈希来解决。
取模算法导致的雪崩
由于现在企业中基本都是使用Redis集群来缓存热点数据,数据会按照sharding规则,被存储到redis集群中不同的节点上,最常用的就是hash后取模的算法。
比如redis集群有4台机器(0~3号),根据userId对4取模决定数据写入或者查询哪个节点:
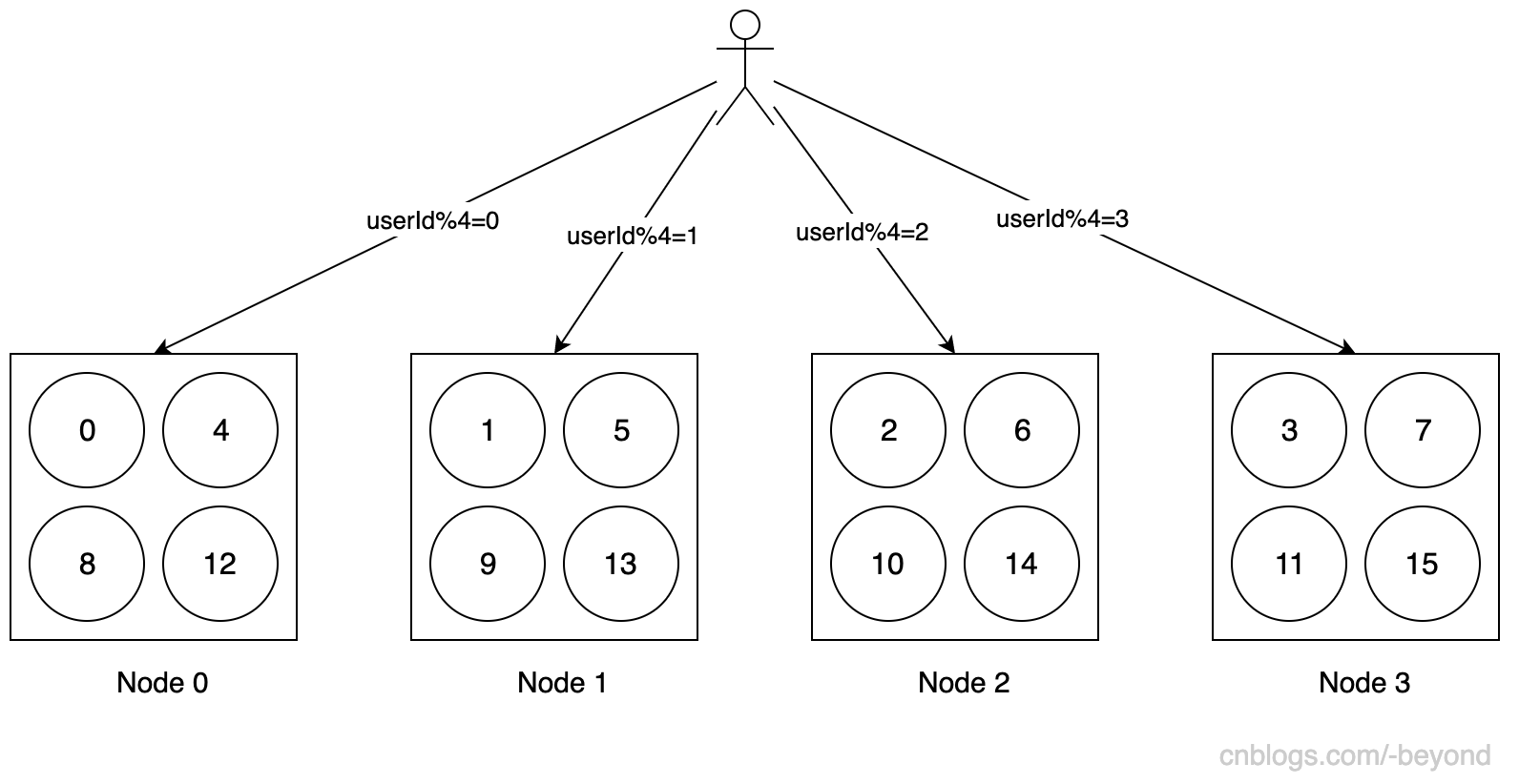
上面的这种模式,一般来说能将数据大致均分到各个节点上,也是一种不错的方式。
但是,如果有一个机器宕机,比如Node2宕机了,此时会发生什么呢?
Node2宕机后,相当于redis集群中只有3个节点了,那么再进行查询缓存时,就会发现出大问题了:
以前查询userId为2的机器,应该在Node节点2中,但是Node2节点宕机后,数据全部丢失了,所以userId为2的数据需要查DB,查出来之后,放到Node3上(Node3此时相当于Node2),同理,userId=6、10、14,都需要查询DB,并以此放入Node1,Node2,Node3中,这是对于丢失的数据。
对于其他的数据,比如userId=5的数据之前是存放在Node1中的,如果现在查询Node1,是能查到userId=5数据的;但是现在是对3取模后,发现数据应该在Node3(Node2)中,于是查询了一下Node3,发现Node3中没有userId=5的数据,于是查询DB,将userId为5的数据存入Node3中。同理,userId为7之前是存放在Node3中,但是现在对3取模后,发现数据应该是存在Node1中,查询Node1后,发现数据Node1没有userId为7的数据,于是查询DB,将userId=7的数据查出来放入Node1中........最终发现,除了userId为0和1的两条数据还在原来的Node节点上,其他的数据都变化了位置(也就是说,变换了位置的数据都需要查询DB重新放入缓存中),也就是下面这幅图:
绿色表示在宕机前后,位置没有发生改变的数据,这部分数据不需要查询DB就能从缓存中获取;
而红色,则表示宕机前后,位置发生变化的数据,这部分数据需要查询DB,再放入缓存中。
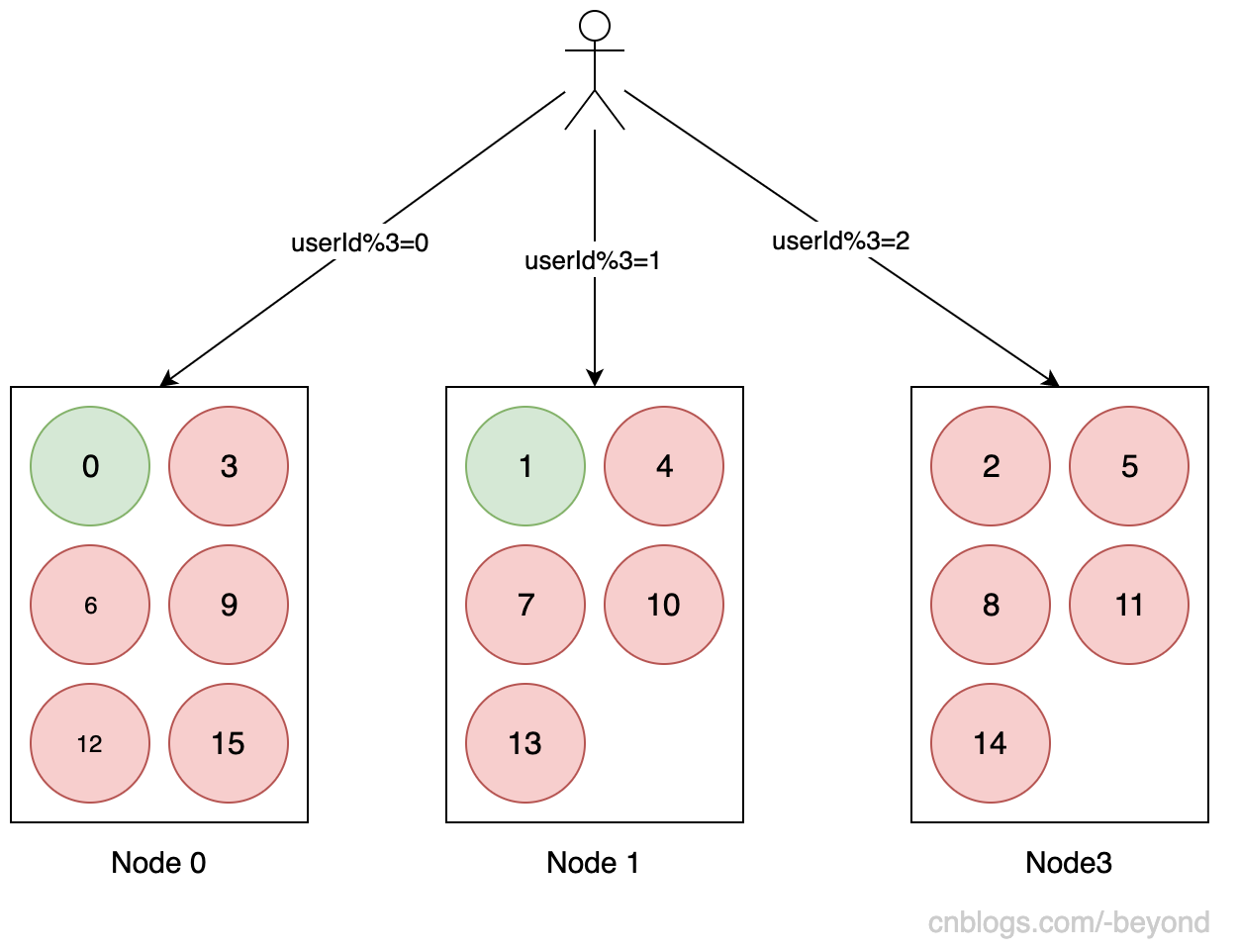
可以想象,上面一个机器上存了多少数据,如果一台机器宕机,那么不超过n(机器数量)的数据可以在原机器查询到,其他的数据(都发生了错位),都需要查询DB,那么数据库是肯定不能扛住这么高的QPS的,此时就会发生雪崩现象。
一致性哈希
推荐阅读:https://zhuanlan.zhihu.com/p/34985026
代码实现,可以参考:https://www.cnblogs.com/xrq730/p/5186728.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号