MySQL索引原理
数据结构B+树
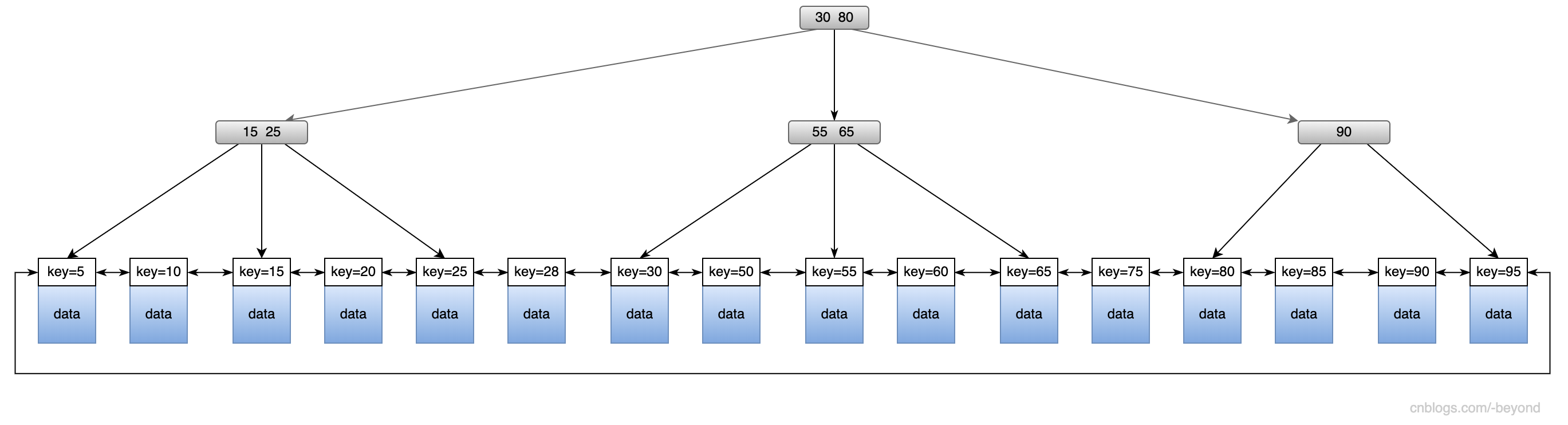
从上面的图中可以看出来:
1.B+树的叶子节点包含了所有的数据;
2.叶子节点可以直接访问其他叶子节点(双向指针),不需要回到根节点(或者上一层);
InnoDB的B+树
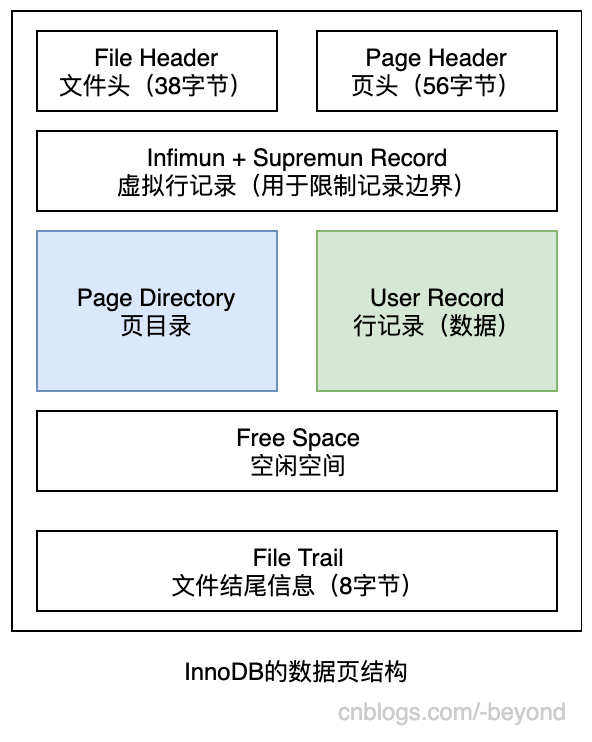
叶子节点保存的页数据,InnoDB的数据页结构如下图所示:
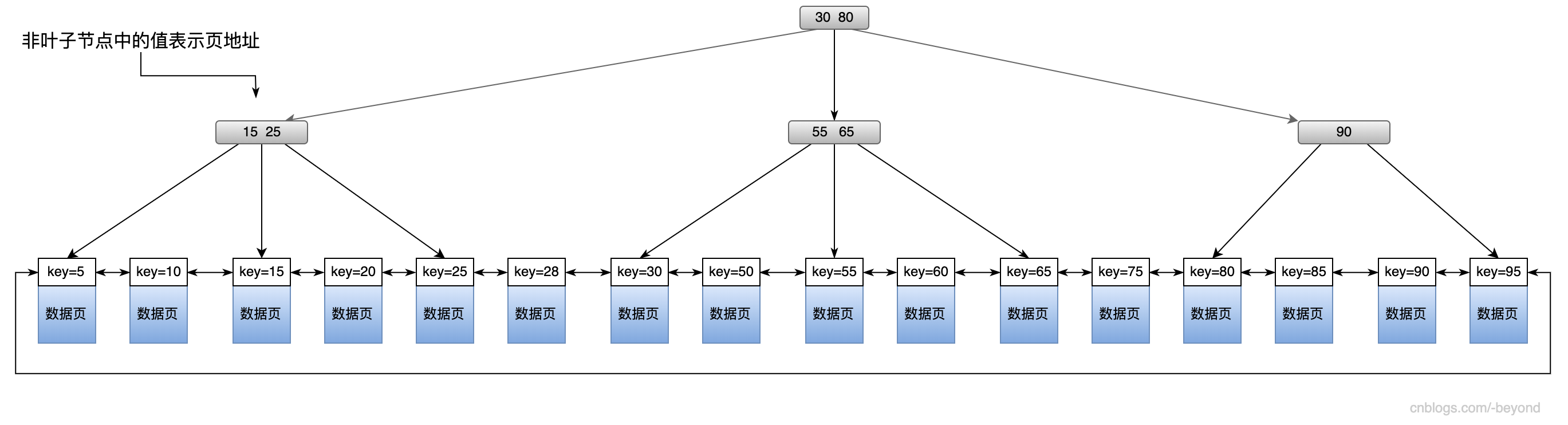
B+树的所有数据节点都是在叶子节点上(叶子节点包含了所有的数据),叶子节点是双链表,一个叶子节点可以直接访问另一个叶子节点,而不需要回到根节点。
操作系统中,默认的是每一页是4KB;而InnoDB存储引擎,默认每一页是16KB(可以设置);
UserRecord(行记录)区域,保存的是真正的数据,会包含多条数据记录,记录是按照链表方式存储,这些数据记录是按照主键或者索引值从小到大依次排列的;因为User Record的行记录是使用链表方式存储,如果链表太长,查询效率就比较低了,所以此时有Page Directory来进行解决问题低下的问题。
Page Directory,存放了User Record区域中行记录的相对位置(也是一个索引),用来提升查找User Record中行记录的速度,;
Free Space:空闲空间,当User Record区域的一条数据被删除,那么该数据所占用的空间就会链入Free Space(Free Space也是链表结构);
很重要的一点:B+树索引本身并不能找到具体的一条记录,能找到的只是该记录所在的页。数据库把页载入内存,然后通过Page Directory在进行二叉查找。
索引的分类
看了上面B+树的图,那么问题就来了,InnoDB是使用什么字段来进行B+树的构建,也就是上面图中的非叶子节点是什么值?其实这就是索引值。
聚集索引(主键索引)
创建表的时候,我们一般都会设置主键,主键也是一种索引,如果有主键索引,那么上面的B+树索引,就会使用主键字段来构建;
如果没有创建主键索引,那么InnoDB就会将取第一个not null的唯一索引列作为主键,然后进行B+树索引的构建;
如果没有唯一索引,那么InnoDB默认会为表创建一个隐藏字段(rowid,6字节)作为主键,然后进行B+树索引的构建;
一个表只能拥有一个聚集索引,因为聚集索引是根据主键构建的,而一个表只能有一个主键。
聚集索引又称为“一级索引”,聚集索引的索引顺序与表数据行的物理存储顺序一致。
普通索引(非聚集索引)
一个表只能有一个聚集索引,但是可以有多个非聚集索引,普通索引又称为“二级索引”。
普通索引(联合索引、覆盖索引),可以使用其他字段(一个或者多个字段)来组成索引。
需要注意的是,通过普通索引进行查询时,不能直接定位到数据页,而是根据普通索引定位到主键,然后根据主键去聚集索引(一级索引)查询,才能查询到数据页,这个过程就称为“回表”,也就是说,建立普通索引的时候,不是建立index到数据页的索引,而是建立index到主键的索引。
需要注意的是覆盖索引的前缀原则。
不一定会使用索引
即使创建了索引,但是MySQL也不一定会使用索引,MySQL内部有查询优化,会自动选择合适的索引或者不使用索引(直接全表扫描)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号