
缓存LRU算法——使用HashMap和双向链表实现
LUR算法介绍
LRU(Least Recently Used),最近最少使用算法,从名字上可能不太好理解,我是这样记的:LRU算法,淘汰最近一段时间内,最久没有使用过的数据。
详细的介绍可以参考百度百科:https://baike.baidu.com/item/LRU
实现LUR的原理
本文使用HashMap和双向链表来实现LRU算法,原理如下图所示:
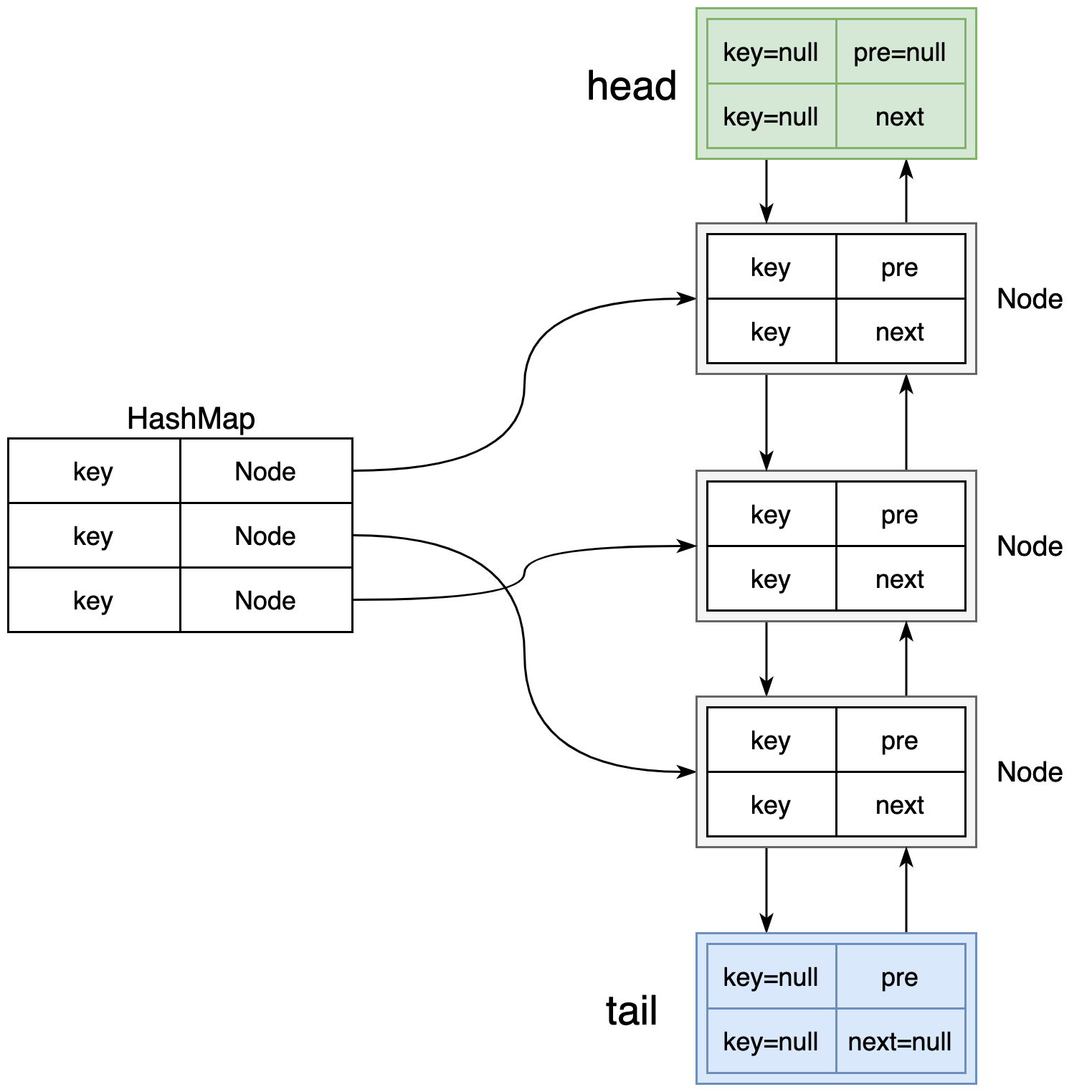
其中:
1.双向链表的主要功能是维护Node节点的顺序;
2.HashMap的主要功能是存储K-V缓存项,另外V为Node类型,也就是能通过key快速找到Node节点(快速定位到该Node节点在双链表中的位置,而不用遍历双链表来找该Node节点);
比如我要删除key为100的缓存项,那么根据HashMap的key快速找到100对应的node节点,然后在双向链表中将节点进行删除(修改前后Node的指针即可)。
当然可以将双向链表替换为单链表(也能保存顺序),但是这样会有问题:
1.每次定位到要删除的node后,都要从头开始再遍历一次链表,找到要删除的节点的前一个节点,然后修改指针进行删除节点操作;
2.每次查询到key对应的value后,需要将对应的Node移动到第一个位置(表示最近访问),那么有需要遍历一遍链表,然后在修改指针将节点进行移动;
鉴于以上原因,所以不考虑使用单链表。
实现代码
双向链表节点
package cn.ganlixin.lru;
public class DLinkedNode {
public String key;
public String value;
public DLinkedNode pre;
public DLinkedNode next;
}
缓存类
package cn.ganlixin.lru;
import java.util.HashMap;
import java.util.Map;
/**
* 描述:使用Lru算法实现的cache
*
* @author ganlixin
* @link https://www.cnblogs.com/-beyond/p/13026406.html
* @create 2020-07-01
*/
public class LruCache {
/**
* 真正缓存数据的容器
*/
private Map<String, DLinkedNode> cache = new HashMap<>();
/**
* 当前缓存中的数据数量
*/
private int count;
/**
* 缓存的容量(最多能存多少个数据KV)
*/
private int capacity;
/**
* 双向链表的头尾节点(数据域key和value都为null)
*/
private DLinkedNode head, tail;
/**
* 唯一构造器,进行初始化
*
* @param capacity 最多能保存的缓存项数量
*/
public LruCache(int capacity) {
this.count = 0;
this.capacity = capacity;
this.head = new DLinkedNode();
this.tail = new DLinkedNode();
this.head.pre = null;
this.head.next = this.tail;
this.tail.pre = this.head;
this.tail.next = null;
}
/**
* 从缓存中获取数据
*
* @param key 缓存中的key
* @return 缓存的value
*/
public String get(String key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return null;
}
// 每次访问后,就需要将访问的key对应的节点移到第一个位置(最近访问)
moveToFirst(node);
return node.value;
}
/**
* 向缓存中添加数据
*
* @param key 元素key
* @param value 元素value
*/
public void set(String key, String value) {
// 先尝试从缓存中获取key对应缓存项(node)
DLinkedNode existNode = cache.get(key);
// key对应的数据不存在,则加入缓存
if (null == existNode) {
DLinkedNode newNode = new DLinkedNode();
newNode.key = key;
newNode.value = value;
// 放入缓存
cache.put(key, newNode);
// 将新加入的节点存入双链表,且放到第一个位置
addNodeToFirst(newNode);
count++;
// 如果加入新的数据后,超过缓存容量,则要进行淘汰
if (count > capacity) {
DLinkedNode delNode = delLastNode();
cache.remove(delNode.key);
--count; // 淘汰后,数量建议
}
} else {
// key对应的数据已存在,则进行覆盖
existNode.value = value;
// 将访问的节点移动到第一个位置(最近访问)
moveToFirst(existNode);
}
}
/**
* 添加新节点到双向链表(新加入的节点位于第一个位置)
*
* @param newNode 新加入的节点
*/
private void addNodeToFirst(DLinkedNode newNode) {
newNode.next = head.next;
newNode.pre = head;
head.next.pre = newNode;
head.next = newNode;
}
/**
* 删除双向链表的尾节点(淘汰节点)
*
* @return 被删除的节点
*/
private DLinkedNode delLastNode() {
DLinkedNode last = tail.pre;
delNode(last);
return last;
}
/**
* 将节点移动到双向链表的第一个位置
*
* @param node 需要移动的节点
*/
private void moveToFirst(DLinkedNode node) {
// 将节点移动到头部,有两种方式:
delNode(node);
addNodeToFirst(node);
}
/**
* 删除双链表的节点(直接连接前后节点)
*
* @param node 要删除的节点
*/
private void delNode(DLinkedNode node) {
DLinkedNode pre = node.pre;
DLinkedNode post = node.next;
pre.next = post;
post.pre = pre;
}
}
测试LRU cache
package cn.ganlixin.lru;
import org.junit.Test;
public class LruCacheTest {
@Test
public void test() {
LruCache cache = new LruCache(3);
cache.set("one", "111");
System.out.println(cache.get("one")); // 111
cache.set("two", "222");
System.out.println(cache.get("two")); // 222
cache.set("three", "333");
System.out.println(cache.get("three")); // 333
cache.set("four", "444");
System.out.println(cache.get("four")); // 444
System.out.println(cache.get("one")); //null
}
}
总结
上面实现的LRU cache存在很多问题:
1.只支持了get和set两个操作,一般缓存还会支持其他操作,比如size、remove、expire、update....;
2.不支持并发修改,因为底层使用了HashMap,如果需要支持并发,可以修改为ConcurrentHashMap,同时对count、head、tail、capacity等属性增加volatile关键字,各种修改接口(比如set、remove)增加锁,以此来实现并发安全;
3.存储开销比较大,每一个缓存项(set的k-v)都会创建额外的数据,比如node、pre node、next node;
4.时间开销也不小,get和set不仅会修改map,还会修改双向链表(将操作的节点移到第一个位置)。
总之,上面只是模拟了一下LRU算法,大家可以根据自己的理解进行修改完善。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号