深度学习
学习深度学习: 深度学习是实现机器学习的一种技术,机器学习是实现人工智能的一种方法。 人工智能包括机器学习,机器学习包括深度学习。
数据集: 三部分: 训练集:测试集:验证集=7:2:1
在训练之前对数据做特征工程。(计算机没法对数值以外的内容做处理,所以只好做特征工程来将其他内容处理为数值,即数值预处理,文本预处理,图像预处理)
记录错误:
代码中的路径中用\\,在文件管理器之中用\
如何从百度上爬取图片:
 View Code
View Code
如何在pycharm中查看文件运行的位置:
EDIT->COPY PATH
如何给图片打上标记:Make Sense
使用vscode上的GUI可以进行版本控制,比起直接使用git bash命令行简单了不是一点半点。
主要的操作有:add,从工作区到暂存区;commit从暂存区到本地仓库;push从本地仓库到远程仓库;pull从远程仓库到本地仓库。
使用yolov5进行目标检测:
教程保姆式yolov5教程,训练你自己的数据集 - 知乎 (zhihu.com)
python虚拟环境:在anaconda目录下的envs中。不同的虚拟环境就是不同的解释器,其中的功能包,依赖也是不同的,并不同步。
结构化数据:数字等。常被用在手机上的广告推送,视频推荐上。
非结构化数据:图片,音频等。比如识别一只猫什么的。
如何使电脑在锁屏后后台依然保持运行,不同担心锁屏后程序暂停
为什么深度学习这些年才兴起呢?很重要的一个原因是数据的规模,硬件上相机,录音机的普及使得我们可以获取更多的数据;其次是算法和硬件的计算速度等等。
正式开课!
资料:LeeML-Notes (datawhalechina.github.io)
机器学习三大任务:
regression:回归,输出一个数字
classification:分类,在几个标签中选择一个
structured learning:结构化学习
机器学习之linear model:
step1:looking for a function like y=b+w*x,b=bias,w=weight.
找到一个function set,又叫model
step 2:define a function represent loss.这个函数就叫做loss function,或者cost function
step 3:optimize parameter with gradient descent,也就是optimization
为model设置一个初始值,通过梯度下降算法找到最优参数。
用relu,sigmoid,tanh(双曲正切函数),leak relu这些激活函数activation加和来拟合function
学习率:每次更新参数时决定移动距离的一个因素,learning rate,让其跟随参数的改变而改变,在最初距离目标参数较远时,学习率应较大;最后距离较近时,学习率应较小。
数据预处理:为了防止不同的参数因规模不同而导致参数变化对结果的影响权重不同,应通过归一化手段使数据规模统一。
在function set中寻找function时,可以通过不断提高function的最高次数以及factor的个数来提高对testing data的识别准确度,但次数过高会导致over fitting过拟合,为了防止过拟合可以通过regularizatioin
正则化使function变得平滑一些。
使用colab之白嫖GPU大法好:
如何在colab使用linux命令:在命令前加! 特殊的,在cd前要加%,所以cd是一个magic commond,这样的magic commond不止一个,想知道请自行查阅。
linux命令补充:
wget:down files from the internet;
gdown:downfiles files from the internet.
从MP到MLP:
M-P模型:Mculloch-Pitts模型,一个最简单的神经元。
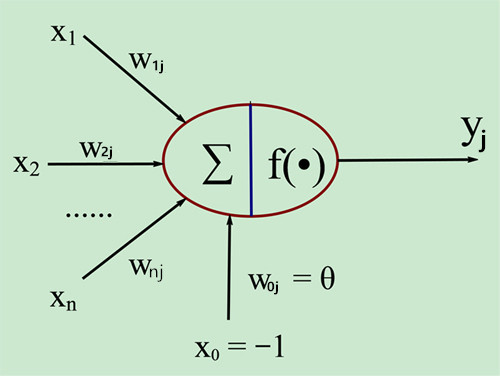
MLP模型:multilayer perceptron,多层感知机,又称ANN(artificial neural network人工神经网络)。有了hidden layer,可以解决无隐层,单隐层不能解决的问题。
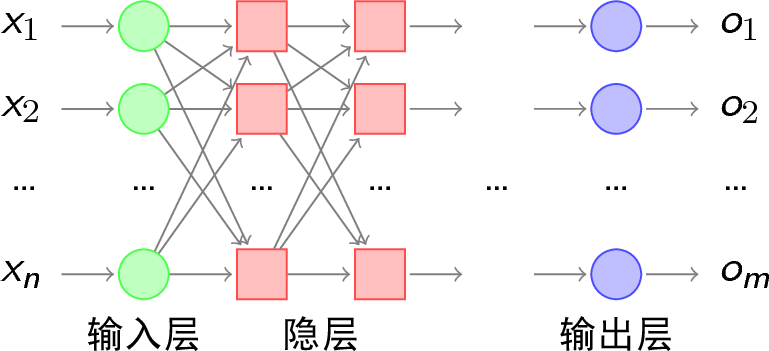
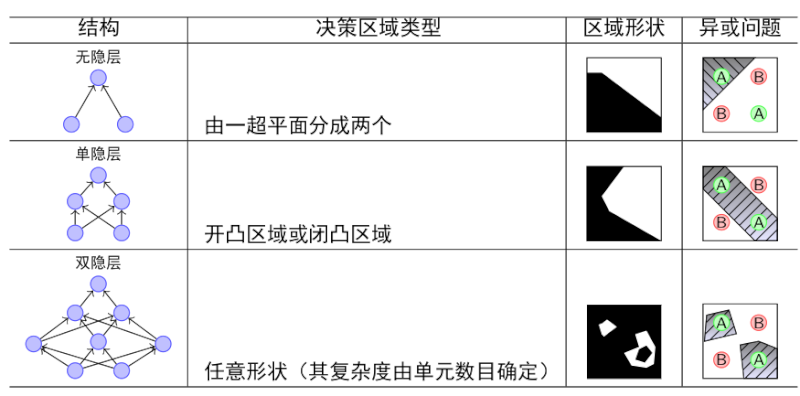
neural network:
由许多hidden layer组成,每一层包含多个neuron,一层层之间相互影响。输入一个向量即可得到另一个向量。GPU对于向量的计算比较快,tensorflow是针对向量的python库,想计算向量推荐使用它们(注:早期有人就是因为不能使用GPU快速地计算而失去了通过深度学习发家致富的机会,他的名字是李宏毅。。。。)
deep learning概念早在上世纪六七十年代就已经提出来了,但因为一系列乌龙原因搞臭了名声,知道21实际10年代,人们在语音识别、图片识别等方面意外地发现了它的威力,才让深度学习再次爆火。
实际上用一个layer的neuron就可以找到我们想要的函数,用一个constant+sum of a set of 阶梯型function(这种阶梯型的函数可以用sigmoid函数去近似得到,这也是阶梯型函数被称之为hard sigmoid函数的原因;也可以用rectified linear unit,也即ReLU来近似),可以制造出任何你想要的由piecewise组成的function的近似图形,只要piecewise切分得够细碎,就可以拟合任意一种函数。何必将网络堆得这么高呢?难道是因为fat network的名头来得不如deep network炫酷吗?
为了回答这个问题,我们需要意识到:模型中neuron很多意味着model的弹性大,function set足够大。但也意味着数据可能不够用,所以训练的效果不会太好,我们可能得到的最好模型很好,但很难得到这个最好的模型;neuron小的时候弹性小,但数据够用,结果比较接近我们能得到的最好结果。
为了克服这种鱼与熊掌不可兼得的矛盾,我们希望在同样的neuron规模下得到更好的效果,同样多的neuron,deep learning 比 fat learning 更有效率,这就是我们之所以选择deep learning 而不是fat learning的原因。
机器学习需要挑选feature,深度学习不用,一股脑将数据塞入model即可->deep learning在nlp方面比起传统方法提升不那么明显(相较之下在影响等方面就提升非常明显),也许是因为人类对文字把握的比较好吧,我们可以通过给出一个正向情绪和负向情绪的词汇列表来判断一篇文章的情感倾向,但像“爷笑了”这种话语中所蕴含的幽微感情显然需要深度学习才搞得定。
线性加和(y=weight*x+bias)+加入非线性(比如sigmoid函数)=感知机
back propagation反向传播:
一种通过gradient desent计算loss function的方法,可以让计算变得很有效率。
classification:
不可以使用regression模型,因为不能很好地处理极端数据,且不能处理好多分类模型(给target画上1,2,3的标记其实是默认这三个target有关联,1和2接近一点,1和3远离一点,事实上这种关联不一定存在)。
共两种分类模型,
1.generative生成模型:对数据做assumption,当数据多时效果比discriminative差,但数据少时效果(可能)会更好(case by case),因为对噪音鲁棒性好。
2.discriminative判别模型
具体方法(二分类):logistic classification
1.looking for a function使用regression+sigmoid的函数,regression求出结果,sigmoid将结果保持在0-1之间,>0.5是一类,<0.5是另一类。为避免过拟合,在regression时共享协方差矩阵。
2.goodness function:有三种方法可供选择:1.最小二乘法(mean square error均方误差,简称MSE),直接将traing出的target与正确结果的target进行比较,并不推荐使用这种方式,因为MSE往往在0-1之间,但feature的数据规模可能会非常大(此句存疑)2.最大似然估计法,假设出不同参数的模型,看看哪种可能最大(概率统计知识)3.交叉熵法 (这个方法写出来和最大似然估计是一模一样的,并不是因为其十分相似却又有所不同,而是因为他们本质一样,只是叙述的角度不同罢了):熵即不确定性,可以衡量两个模型的差异。(参见b站王木头学科学)
这三种方法中,后两种较为优越,第一种比较蠢笨。
多分类:
1.softmax将logit(要处理的数据)处理成0-1之间且和为1的一组数,同时,这个行为还放大了logit之间的差距。如果是binary classification的话可以用sigmoid(事实上和softmax是一回事)。
2.计算交叉熵cross entropy.
有时候classification没法实现(因为一条直线没法划分所有feature特征值),所以要做(任意次)线性变换,变成可以用直线划分的样子,一层regression的输入是另一层regression的输出,这个就是类神经网络(好潮的名字)。
TESTING DATA LOSS FUNCTION太大怎么办:
两种可能:1.model bias:大海捞针,针却不在大海之中,model弹性不够大,其中没有足够好的function;2.optimization issue,优化没做好
判断:给model降层,做一个层数更低的model观察其loss,如果其loss更小的话,说明是optimization问题。
原因:层数浅的model可以做到的事,层数深的一定也可以做到(让浅层和浅层一样,深层什么都不做即可),如果深层的loss反而大了,那一定是因为optimization不够好。
过拟合overfitting:
training data上loss小,testing data上loss大。
(极端情况:
function一无是处,输入x1则输出y1,输入不认识的x就输出random,这样的function training data是0,testing data大的要死。
用这种屁用没有的模型,多次尝试误打误撞可以在testing data上得到很好的结果,这样一来就是一个training data和testing data双优的model了,为了避免这种状况,我们将training data划分为training和validation两部分,用validation来判断好坏,testing data再做一次判断,都不是太差才行
如何分割呢?:n-folder validation)
解决方法:
1.增加training data.
2.data augmentation:例如影像识别中左右颠倒图片
3.给model加上限制,不要让其弹性那么大(能力那么强),让model一定是一条抛物线或者其他。(比如fully-connected之CNN,CNN之所以牛逼很大一部分原因就是这个)
mismatch:
training data 和 testing data根本不是同一个分布,training data结果很好,testing data很差,这种情况和over-fitting很相似,但根本不一样,over-fitting可以通过增加数据变好,但mismatch增加了数据也没用。
OPTIMIZATION问题:
loss停留在critical point(零界点,驻点):
1.saddle point(鞍点):周围有的点比其大,有的小。不要害怕,有的是数学方法解它。
2.local minima(局部最小值):实际上这样的点很少,因为在低维度上无路可走的local minima,在高维也许是有路可走的saddle point。
loss surface很崎岖不平可能的原因:
数据的scale差距很大,在不同维度上,将weight进行相同程度的改变,可能导致完全不同的规模的改变。如果可以将data全部调整到一个范围内,就可以让error surface变得好处理一些,平滑一些。这个行为就叫feature normalization。
BATCH:
在对training data梯度下降中计算LOSS时将数据分成多个batch,每处理完一个batch称为一个epoch。有两种处理方式:
1.batch size == N(所有数据分成一笔,即full size),更加稳定
2.batch size == 1(数据分成很多笔),更加noisy
GPU并行计算之下,一个batch对二者来说时间差不多。但考虑到epoch的次数,小的batch size花的时间比较多,大的batch size花的时间少。
这么一看,大的batch劣势被GPU抹去,岂不是只剩下优势?实际不然,随着数据的增大,大的batch size只有一个loss function,其走到local minimum的可能性会增大,但对于小的batch size来说,每次epoch都会更换loss function,多个loss function意味着上次卡住的local minimum可能会在下一次被消去。这样一来具有noisy的小batch size反而是更好的选择。
与此同时,在testing data上,小的batch size也更有效(涉及mismatch):
local minimum有好有坏,在盆地上的更好(在training data和testing data上的差别并不那么巨大),在峡谷中的不那么好(在training data和testing data上的差异可能会非常巨大)。
大的batch size能困将梯度下降的target困在峡谷中,而小的batch size因为loss function很多,左跳一下右跳一下所以不太能困在峡谷中,更多是在盆地中。
momentum:
对抗critical point的技术。
对普通的gradient desent,下一步是这一步的梯度的反方向;
让gradient+momentum,下一步是梯度的反方向+上一步(这上一步实际带有之前每一步的方向),这样可以让gradient desent带有惯性,这可就牛起来了嗷,区区一个小小的critical point,直接一跃而过。
调整learning rate:
学习率跳太大了容易找不到最低点,太小了在有限次数之内也找不到,所以使用adaptive learning rate自动调节learning rate。
learning rate scheduling:
1.learning rate decay:学习率随着接近destination而慢慢变小。
2.warm up:超级黑科技,学习率先变大后变小,原因未知。
卷积:一个系统的输入是变量,输出是定量,便可以用卷积来表示存量。
应用到图象识别中,对图像的卷积操作可以记录图像中的不同特征,多层对图像的卷积可以将特征不断地提取提取再提取。
卷积神经网络CNN(convolutional neural network)分为三层:1.多个卷积层提取图像特征2.池化层将特征取其精华3.全连接层将池化的结果与输出连接起来,多用于处理图像。
最简朴的做法:fully-connected,弹性超级大,但也过分复杂了。
1.convolutionn:
simplification1:考虑到不必让每个neuron都关注每个pixel,所以为每个neuron设置receptive field,只接受上一层中在其receptive field之内的数据。receptive field随意设置,大小形状位置多少个channel(BGRA四个channel)随你的便。
kernal在图像中移动,抓取pattern,filter对应的kernal size往往是3*3,kernal的stride往往是1或者2,不会太离散,这是因为我们不想错过也许会出现在两个receptive field边缘的图像特征。将图像每个pixel的数据传入下一层,如果出现了overlap的问题,就进行一次padding填充边缘的pixel。
kernal是那个小方块,filter里面是有数字的,kernal中的数字和filter中的数值之积即inner prodeuct。所有filter扫描的结果我们称为feature map。第一层如果是黑白图,有一层channel,第一层的filter有64个的话,得到的feature map就是64层的。
随着层数的加深,filter可以覆盖到的范围会越来越大。
simplification2:对于某一个特征,不同位置的neuron的参数完全可以共享,即parameter sharing。
综合以上两个防止过拟合,降低了model弹性的特点,即是model biais很大的convolution。CNN之所以称之为CNN正是因为这一步的操作叫做convolution。
2.pooling(subsampling):
最初是为了减少运算而设计,将多个pixel的内容通过平均或者max,min等方式变少。随着算力提升,有些人舍弃了pooling(比如alpha go就没用)。
convolution和pooling可以反复执行几次,然后丢进flatten,再丢进fully-connected layers,再softmax一下,就是一个经典完整的CNN。
GNN(graph neural network图卷积网络):
图这种数据结构的表现能力是非常强大的,许多种关系,比如社交网络,交通流量乃至于图像影音都可以使用节点和边来表示。
我们在欧氏空间将CNN运用的炉火纯青,自然想将图结构也嫁接到CNN中去,在此过程中,我们主要解决两个问题:
1.如何用矩阵表示图结构:
方法:邻接矩阵呗,还能是啥呀,你瞧你问的。如果是稀疏图的话就用一个邻接表好了。
2.层内与层间的消息传递:
方法:聚合(aggregate),将一个点及其周围节点的信息表示出来即可在层内完成消息传递,这种聚合称之为pooling;层间的消息传递通过节点就可以完成。
不同的聚合方法就构成了不同的GNN。
循环神经网络RNN(recurrent neural network)(encoder-decoder):通过建立不同时刻隐藏层之间的关系,考虑到时间的影响,对nlp这种需要考虑上下文的任务非常友好,因此在该领域以及语音识别等领域大受欢迎;当然,因为其只能考虑前一时刻的影响,所以只能处理小批量低算力的任务。因此捉襟见肘之处,我们找到了新技术LSTM。
LSTM长短期记忆网络(long-short time memory):在RNN基础上增加了一条与short-time memory平行的long-time memory,每进入一个新的时间序列,long-time memory会与short-time memory互换信息,其中包括三个步骤:1.forget gate增加long的新内容2.input gate修改long的旧内容3.long给short给出指导,修正short的内容。从而进行长期记忆。该技术是20世纪最重要的深度学习技术。深度学习三大基石之一(CNN也是其中之一)。
self-attention自注意力机制:
针对的问题:神经网络的输入往往是一个向量,如果向量的规模不一致,有大有小怎么办?比如一段声音,一段话语,一张social network graph,单词的长度和语音的长度是不同的。
对于output:
1.each vector has a lable.又叫sequnce labling.比如词性判别
2.the whole vector has a lable.比如情绪判别
3.seq2seq:未知的输入,未知的输出.比如翻译。
以词性判别举例:
为了克服fully-connected不能识别单词与单词之间关系的问题,先将整句话放进self-attention的model,再将得到的vector放进fully-connected。你甚至可以交替使用这俩model来得到你想要的结果。
具体怎么做self-attention呢?
对输入的vector中的每个值a,通过乘以矩阵Wq,Wk,Wv得到矩阵q(query),k(key),v,再将q,k,v进行计算得到a处理过后的值就可以得到self-attention的结果,总之就是一系列的矩阵乘法,唯一的参数就是Wq,Wk,Wv而已。
这套系统中没有单词位置的信息,你可以自己加一个向量进行positional encoding。
如果你觉得输入太过庞大,比如语音识别是以一毫秒的音讯为一个单元的,一秒钟就有一百份资料。为了处理这样庞大的数据,可以使用truncated self-attention技术,只观察一小部分数据。
让我们来看看CNN和self-attention的关系吧:
self-attention是更加flexible的CNN,它的弹性更大,在data比较多的时候可以得到比较好的结果;CNN是简化版本的self-attention,在data比较少的时候可以得到比较好的结果。事实上,CNN能做到的事,self-attention都可以做到。从实现的角度考虑,CNN有自己的receptive field,这个field是人为设定的任意大小任意格式的;但self-attention却可以考虑到所有其他元素,对它来说真可谓天涯若比邻,随便一个pixel的元素都唾手可得。
让我们再看看RNN和self-attention的关系:
二者实际差不多,但RNN做不到天涯若比邻,其接收远处的pixel的信息比较困难,所以现在越来越多的RNN被self-attention逐渐替代。
self-attention也可以处理graph,你可以将graph视作一组vector,进而放入self-attention进行处理。
Generative adversarial network(GAN生成对抗网络篇)(黑客帝国)(芝麻街外传):
pretraining:
用BERT(bidirectional encoding representation from transformer)举例:其架构与transformer的encoder一模一样,只不过是多个encoder的相加,encoder是一个又一个的语料编码器,transformer中的decoder是将经过编码的语料翻译成语言,就这么简单。
输入的token是单词片段,也就是word piece,实际上就是把一个完整的单词拆分成各种词根和后缀,得到embadding,这样的embadding分为三部分:1.token embaddings记录语义2.segment embaddings记录句子的信息3.position embaddings记录位置信息。
当然了这其中还要做一些其他事来提取一句话在词汇和句子上的信息,具体是指屏蔽(MASK)15%的语料让BERT猜来获得词汇层面的知识;以及判断输入的两个句子(CLS)是否是同一句话而获得句子层面的知识。
注:用上下文预测单词就是BERT中bidirection双向的含义。
fine-tuning:
针对不同的任务对模型进行优化,具体值通过一个softmax层得到一个概率分布,将概率分布和真值进行对比,再通过cross entrophy进行优化。
Transformer模型(谷歌的NLP王者):
attention is all you need真正将attention机制发扬光大。
其是seq2seq的一个模型(与BERT有关系),应用极其广泛,很多机器翻译,语音翻译(把一种没有文字的语言直接翻译过来),Q&A,multi-lable classification等等nlp任务都可以被强行硬train出来,当然了,最好的方法还是客制化处理。
第一部分:encoding 部分由多个block组成,在一个block中,首先进行self-attention,再进行residual(add最初的feature和经过了self-attention的feature),再进行layer normalization(not batch normalization)。
注:以上的第一部分是最原始论文中的版本,后人发现如果先做layer normalization,再做self-attention。将得到的结果与原始feature做residual反而可以得到更好的结果。
总之是输入一个vector,输出一个vector。
第二部分:decoder:
1.autoregression:(简称AT)
在输入前加上一个begin字符,得到一个softmax后的输出,再这个输出取max,得到一个向量,将这个向量作为下一次的decoder的输入,反复数次直到得到结果是END即可输出结果。因为这种前一步影响后一步的机制,可能会造成error popagation错误传播。
总之是输入encoding的结果,输出一个结果。
此处的self-attention是masked self-attention,只能考虑左边的内容,不能考虑右边的内容(废话,右边的内容都还没有你怎么考虑呢?)
先masked self-attention,再和encoding的输出一起加权矩阵运算得到一个结果,再将此结果接着用下去直到得到END。
2.non-autoregression:(简称NAT)
先用一个classifier输出一个句子的长度L。1.再输入L个start token。直接得到一个句子。2.输出max个start token,输出的结果中end右边的不采纳。
由于NAT比较平行化,所以速度比auto regression更快。由于平行化的优势,可以被用于输出语音的变速等好处,但NAT的效果往往比AT差。
transformer中的小技巧:
copy mechanism复制机制:
举例:user:"hello,i am 马小丫."answer:"hello,马小丫."当机器遇到了不认识的"马小丫",不会进行学习,而是直接复制下来这三个字。
guided attention:
有时候模型里会出现非常莫名其妙的结果,比如将文字转换成语音的语音合成TTS中,出现过“发财”的“发”读不出来的状况。
具体不细讲,大致内容是通过给模型一种固定程式而对其进行指导。
beam search束搜索:
类似将贪心算法转化为动态规划,舍弃当下的最优,追求全局最优。
实际上beam search有时候也没那么好,比如需要你的文章生成器由一些创造性的时候,beam search就没那么好,在decoding中加入一些noise,模型效果会更好(格局打开)。
scheduled sampling:
为了防止TTS在应用中遇见noise无所适从,我们在训练时就放入许多noise。这就是计划抽样scheduled sampling技术。
SVM(Support Vector Machine支持向量机)(低维空间的混乱,高维空间的秩序):
一种二分类模型,两个类最边缘的点连接起来称之为支持向量support vector,它们之间的边界区域称之为margin,margin的中心线称之为hyperplain(在低维度,hyperplain是一条线,但在高维度,hyperplane是一个平面)。
算法的目标是找到一个decision boundary来分开不同的样本,并找到距离decision boundary一样远的margin boundary来确保两种样本尽可能得不同。
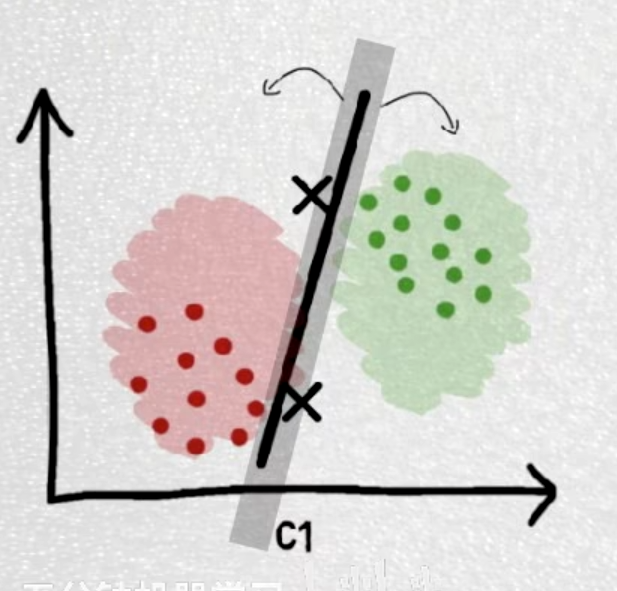
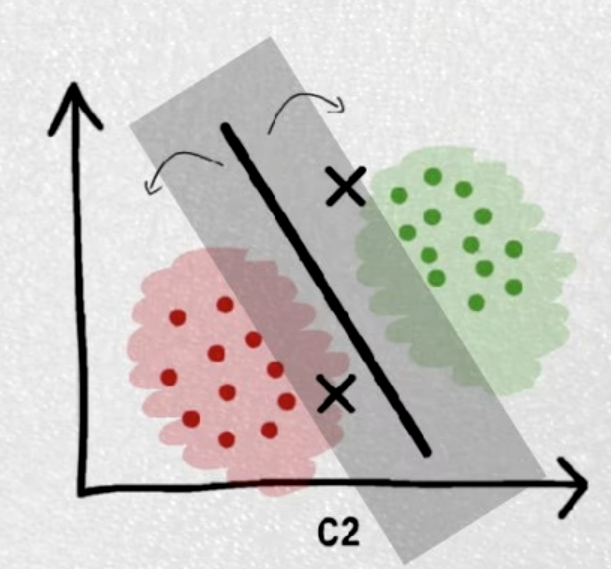
最理想的可以将两个类完全分开的称之为硬分类(hard-margin svm),允许错误出现的称之为软分类(soft-margin svm)。
实际生活中许多看似不可分的问题经过kernel运算将问题从低维的欧氏空间映射到高维的希尔伯特空间中,从而在高维很好地进行线性分类(为何如此执着于线性?因为计算机的底层架构擅于线性运算)。
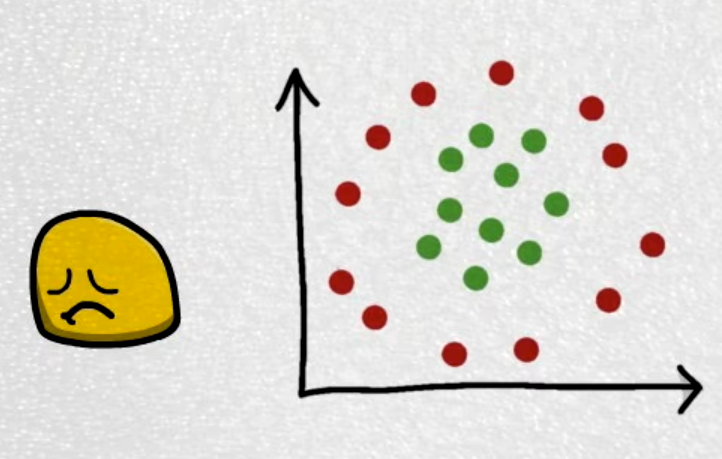
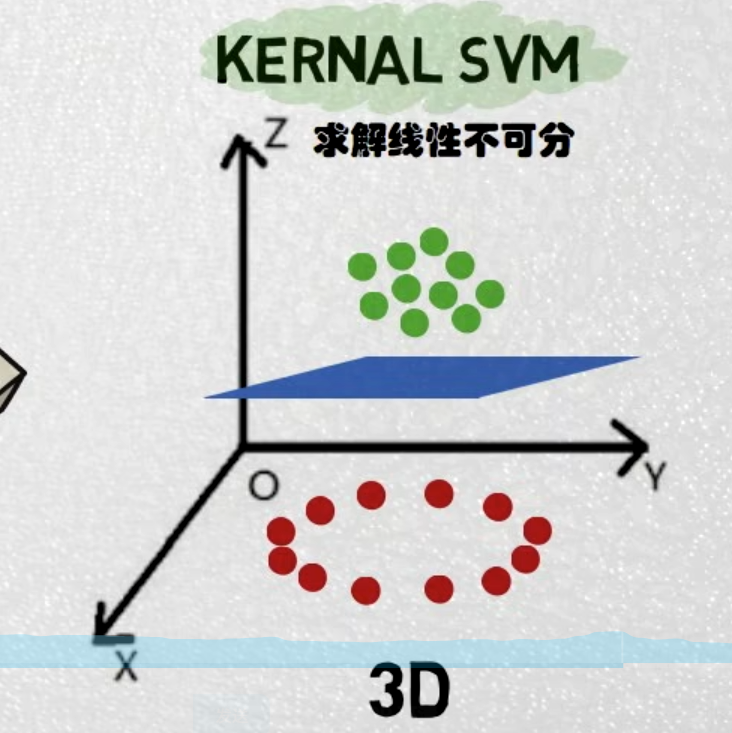
SVM在大规模数据处理上远远不如深度学习,但在小规模的数据处理上任然有着用武之地。
优点:比起KNN这些每次分类要考虑每一个点的算法,SVM只考虑最margin的点,不考虑margin之后的点,节省了很多运算;随着维度升高,很多低维的非线性函数在高维变成了线性,线性比起非线性总是精度较高。
KNN(k nearest neighbor)(K近邻算法):
一个分类算法。
想知道一个物体X是属于A类还是B类,那就看看这个物体的特征与A之间的差距,与B之间的差距(欧式距离,汉明距离,曼哈顿距离等等距离),将已经确定了类别的A,B物品按照到X的距离大小排序,只考虑距离X最近的K个,在此范围内,A多X就是A,B多X就是B。(k是超参数)
缺点:k太小或太大都容易受极端情况左右。
决策树问题:
分类算法。
通过一个物品的不同特点,在二叉树中层层分类进行,进而得到分类结果。过程就像高尔顿钉板一样层层向下。每一层的熵都比上层小,这就叫做熵增益,选择决策树的方法就是找到一个又一个能让当前层熵增益最大的二分决策。
优点:可解释性强;从其良好的可解释性出发,可以手动修改其中某一层
缺点:正如KNN的超参数K一样,决策树的超参数是其树的深度。如果树太浅,就没法精确预测,进而导致欠拟合;如果树太深,就会导致过拟合。
随机森林Random Forest:加强版决策树
随机森林是集成学习ensemble learning中bagging类型算法的典型代表,由许许多多的决策树组成,随机指的是给这些决策树不同的数据(看问题的角度不同)。使用时,这些决策树得到不同的结果,对这些结果,回归问题取均值,分类问题取众数(投票),即可得到结果。
优点;多个决策树小批数据分别训练,速度快;使用不同的数据喂给决策树,防止过拟合;准确率很高(分类不错,回归不太行);树状结构的可解释性强;
缺点:无法照顾到特殊点,这点可用boosting的ensamble learning解决。
其意义在于三个臭皮匠,胜过诸葛亮,集多个weak learning的长处于一身,变成很强很稳定的model。
K-Means(K均值聚类):
一种聚类算法,不要label即可训练,属于无监督学习。
过程:
1.随机从数据中找到K个点作为K个cluster(簇)的centroid
2.遍历图中每个点,将未分类的点分到不同的cluster中去
3.更新每个cluster的centroid(使用means作为其centroid)
4.重复2.3直到centroid不再被更新
与KNN进行对比:
相似之处:通过与其他点的距离判断其属于哪个类别;K都是超参数且都很敏感;
不同之处:KNN最初有一些已知点,K means完全没有已标注点;KNN的K是分类是参考的点的数目,K-means的K是要分出的类别;KNN只关注局部信息,K-means关注的是全局信息;
缺点:对数据本身的分布十分敏感,训练效果很尴尬。
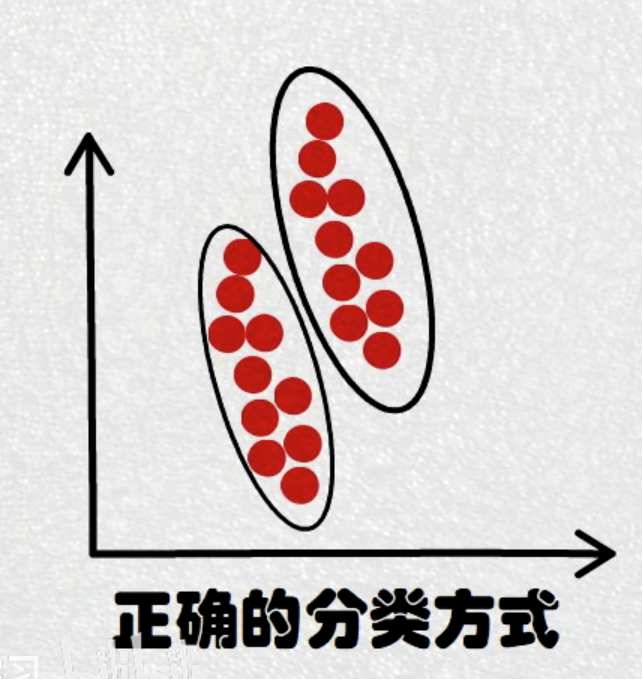
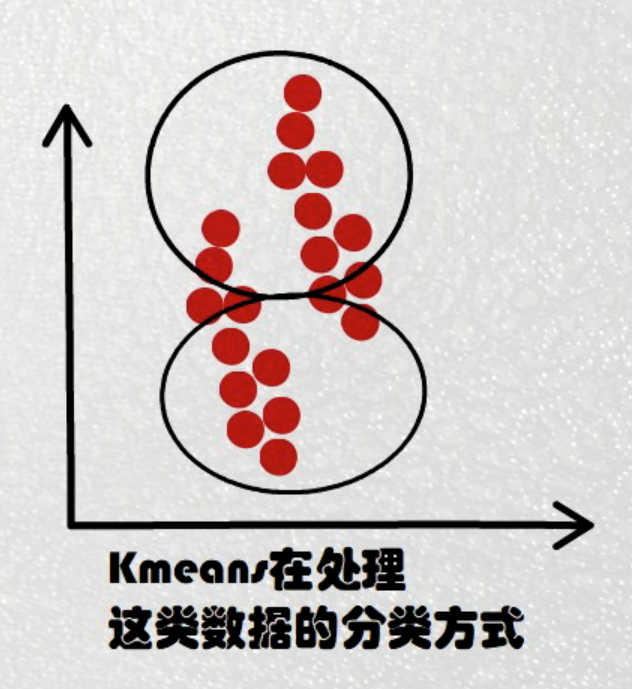
Adaboost(adaptive boosting自适应增强算法):
random forest虽然可以集多者之长处,但由于照顾不到outlier(异常点),所以天花板比较低。
adaboost是emsemble learning中boosting类算法的佼佼者,可以照顾到outlier,所以天花板很高。但过分追逐于解决outlier会使model对outlier异常敏感,所以地板也很低,同时训练速度慢。
其逻辑在于组成大模型的不同小模型之间拥有级联关系,上一个model没有处理好的地方下一个model会增大权值。
训练过程:
1.初始化所有样本的困难度为同一个值;
2.通过不同的weak model训练数据,在此过程中不断更新model,根据是否正确区分了样本来调整样本的困难度。
3.训练完所有样本之后,对所有model的性能做一个评估,以此为结果为每个model设置权重,最终将这些model加起来即可得到最终结果。
Embedding:
其本质就是矩阵乘法,用来升维或者降维。
word2vec:
这是embedding的一种,通过skip-gram,CBOW等模型,把自然语言领域最细粒度的词语转换为数学表达式。
Tensor:
高维数组罢了。
激活函数:将神经元的特征保留下来再输出。常见的有relu求最大值,sigmoid,softmax
epoch轮,每轮数据分为若干batch批
深度学习可以完成传统机器学习中的特征工程,所以对特征工程的要求不高。
卷积神经网络:
(120条消息) 多通道图片的卷积_小小川_的博客-CSDN博客
卷积层负责提取特征,采样层负责特征选择,全连接层负责分类
