大数据MapReduce词频统计
学习网站链接06-Hadoop MapReduce官方示例--WordCount单词统计_哔哩哔哩_bilibili(过程中可能会出现没有权限的问题)
下面这个网站教程比较复杂,不同的电脑可能会不适配(不推荐)MapReduce编程实践(Hadoop3.1.3)_厦大数据库实验室博客 (xmu.edu.cn)
1.首先启动在虚拟机中启动hadoop,按要求创建input文件夹,并在该文件夹下创建文件wordfile1.txt和wordfile2.txt
input文件夹的创建(进入hadoop目录下执行)
在命令行窗口输入下面的命令:
hadoop fs -mkdir /input
创建文件(首先要将wordfile1.txt和wordfile2.txt导入到虚拟机本地任意文件夹中)
在命令行窗口输入下面的命令:
hadoop fs -put /(本地该文件路径) /input
2.执行语句(mapreduce目录下)(jar版本可能不同不要直接复制)
hadoop jar hadoop-mapreduce-examples-3.3.4.jar wordcount /input /output
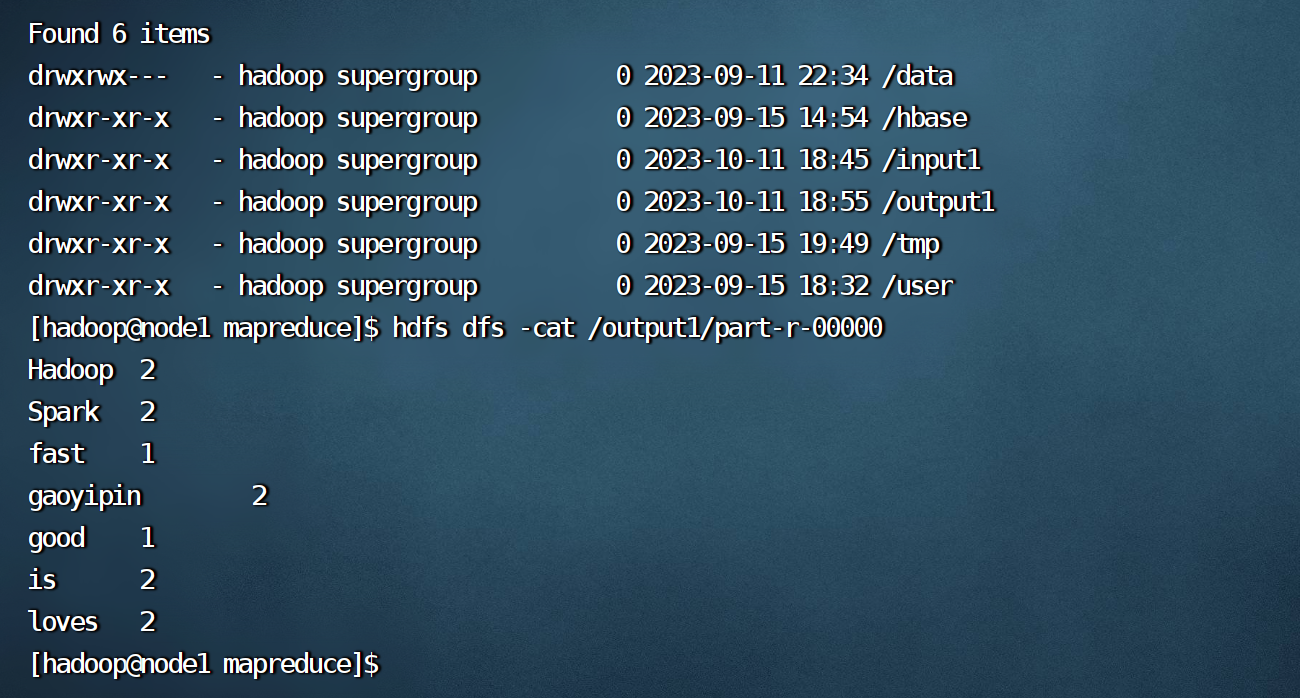
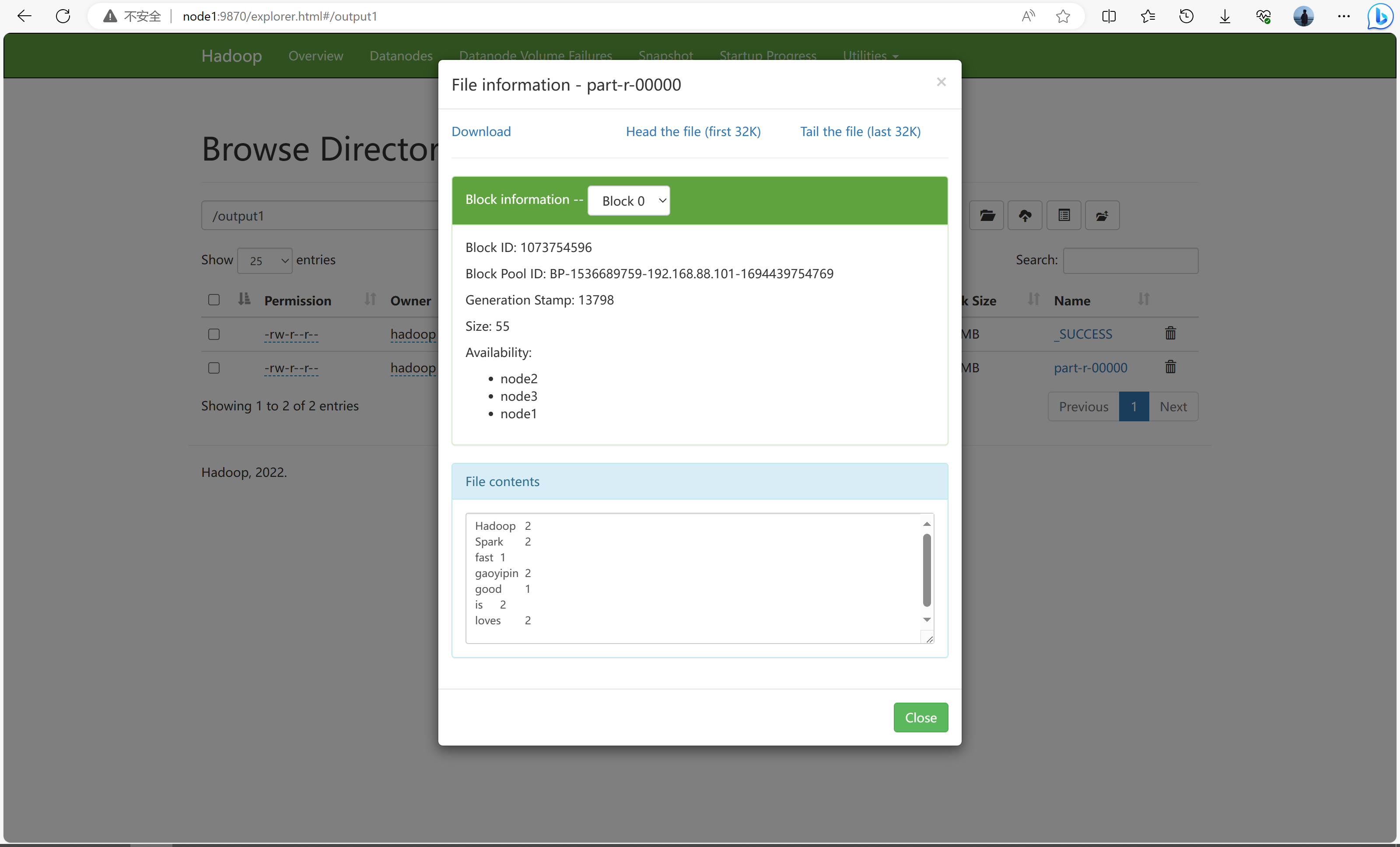
3.查看执行结果
两种查看方式:1.输入如下图的cat命令 2.浏览器访问node1:9870找到文件位置

 浙公网安备 33010602011771号
浙公网安备 33010602011771号