
day4
1.文件执行完后的关闭:python自带有垃圾回收机,会把不运行的程序自动关闭,但这有个问题,一旦程序运行一多,那么打开的文件地址不会清空,就会占用内存,因而,关于:
f = open("yesterday2","r",encoding="utf-8")
f_new = open("yesterday2.bar","w",encoding="utf-8")
for line in f:
if "肆意的快乐等我享受" in line:
line = line.replace("肆意的快乐等我享受","肆意的快乐等Chubo_Lin享受")
f_new.write(line)
f.close()
f_new.close()
#一旦程序执行,最好在后面加上close()
当然,还有另种方法:
with open("yesterday","r",encoding="utf-8") as f:
for line in f:
print(line)
'''
这里的open("yesterday","r",encoding="utf-8") as f相当于
f = open("yesterday","r",encoding = "utf-8"),with语句下,一旦程序执行完,则自动关闭
自py2.7之后,with支持同时对多个文件的上下文进行管理,但应python的官方规定,一行代码不应超过80个字符,因而:
with open("yesterday","r",encoding="utf-8") as f,\
open("yesterday","r",encoding="utf-8") as f2:
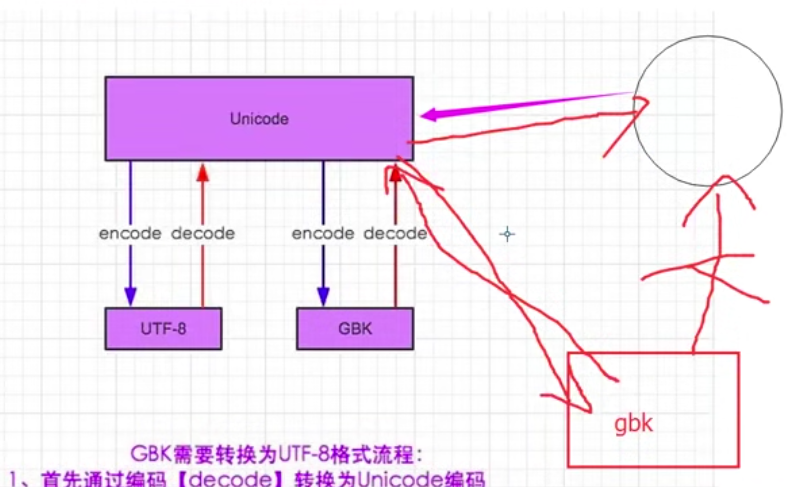
2.windows 上传输的中文默认是gbk
ASCII一个英文占1字节-8位,ASCII不能存中文,因为它只有英文或特殊字符
unicode里,1个中文或英文都统一占2个字节-16位 ----- > 国际编码
为了解决浪费的情况,自unicode之后,出现了utf-8,也就是unicode的扩展集,可变长的字符编码
utf-8默认所有的英文字符都按ascii的形式存,所有的中文字符统一3个字节
uncode向下兼容,支持gbk
eg:假如,中国的一款游戏用的是gbk进行编码,但到日本,想运行这游戏,想让他不以乱码的形式出现,则有2种方法:
1)在机器上安装gbk 2)机器支持unicode--将gbk转为国际通用编码unicode,再将它解编成日本的编码语言
py3.x默认用utf-8;py2.x默认ASCII,若想使用中文,则要声明使用utf-8:
#-*- coding:utf-8 -*-
gbk要转unicode,得告诉unicode我是什么编码,这时,unicode才会去相对应的进行转换
s_gbk.decode("gbk")
在utf-8的环境中,用unicode进行打印,可直接打印出,但打印gbk的不行
s = U'你好' print(s) #这里的u代表unicode
python3.x里,所有只要进行encode()的,都要在进行decode(),这样才可以打印出字符,因为encode出来把编码集改了,同时,还让他变成了byte类型
#-*- coding:utf-8 -*- 他只是声明文件的编码,但程序执行时该用什么编码还是什么编码,与此无关

 浙公网安备 33010602011771号
浙公网安备 33010602011771号