armv8 memory system
在armv8中,由于processor的预取,流水线, 以及多线程并行的执行方式,而且armv8-a中,使用的是一种weakly-ordered memory model,
不保证program order和execute order一致。
所以有时需要显式的执行一些指令,来order自己的代码。
armv8涉及到的优化包括:
1) multiple issue of instructions,超流水线技术,每个cycle,都会有多个issue和execute,保证不了各个指令的执行order。
2) out-of-order execution,很多processor,都会对non-dependent的指令,做out-of-order的执行,
3) Speculation,分组预测,在遇到conditional instruction时,判断condition之前,就会执行之后的instruction。
4) Speculative loads,预取,在执行上一条指令的同时,将下一条指令的数据,预取到cache中。
5) Load and Store optimizations,由于写主存的latency很大,processor可以做很多优化,write-merge,write-buffer等。
6) External memory systems,某些外部device,像DRAM,可以同时接受不同master的req,Transaction可能会被buffered,reordered。
7) Cache coherent multi-core,一个cluster中的各个core,对同一个cache的update,看到的顺序不会是一致的。
8) Optimizing compilers,编译器在编译时的性能优化,可能打乱program order。
armv8支持的memory types:Normal memory和Device memory
Normal memory,主要指RAM,ROM,FLASH等memory,这类memory,processor以及compiler都可以对program做优化,
processor还可以增加repeate,reorder,merge的操作。
在需要固定memory order的情况下,需要显式调用barrier operations,
还有一些存在address dependence的情况,processor必须能够正确处理这些情况。
Device memory,通常都是peripheral对应的memory mapped。对于该memory type,processor的约束会很多;
1) write的次数,processor内部必须与program中的相同;
2) 不能将两次的writes,reads,等效为一个;
3) 但是对于不同的device之间的memory access是不限制order的;
4) speculative是不允许的,对device的memory;
5) 在device memory中execute,也是不允许的;
Device memory的几个attribute:
1) Gather或者non-Gather,多个memory access merge为同一个single transaction,如两个byte write merge为一个halfword write
2) Reordering,同一个block中的access是否能够reorder。
3) Early Write Ack,write不写入device,通过中间buffer之后,即 return ack,是否可以。
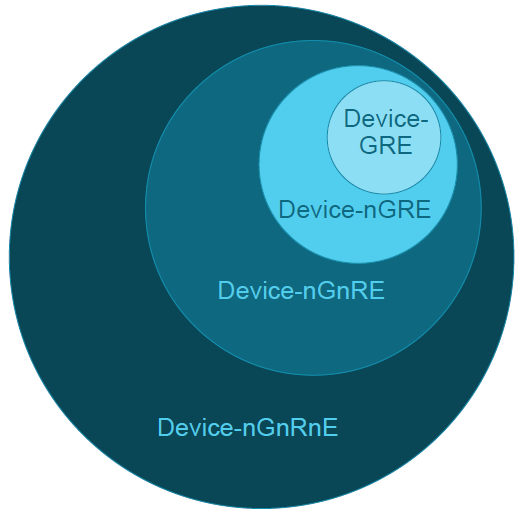
四种device memory:
1) Device nGnRnE,最严的约束;
2) Device nGnRE,允许early
3) Device nGRE,允许reorder,early
4) Device GRE,允许gather,reorder,early
Memory attribute,arm系统中,memory都被分为各个region,每个region都有自己的privilege level,memory type,cache policy;
这部分的管理是由MMU,来实现的,各个region都对应其中的一个或几个block、page。
对于normal memory,有shareable和cache property;
对于device memory,总是non-cacheable,outer-shareable,
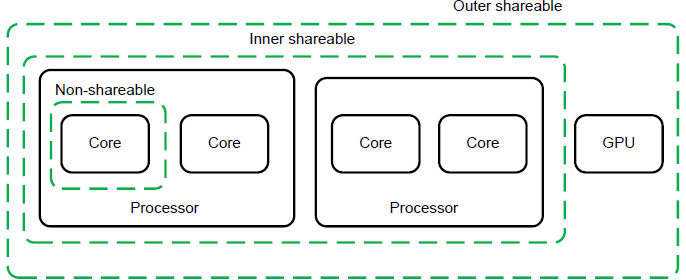
shareable,用来指定这个location是否是与其他的core,共用的,share的。share的core之间需要保证coherency。
non-shareable,典型应用在AMP,有自己的独自cache,
inner,主要指processor自己的cache,在big-little中,表现为一个cluster,(还是取决于具体实现)
outer,主要指processor外的cache,在big-little中,表现为两个cluster,(还是取决于具体实现)
system,整个system的master,可能会包含GPU等
ARM架构中,包括几个barrier instruction,用来force一定的memory order,但是这样的指令,会减小一些软件的优化性能;
所以最好在需要的时候,再加这样的指令。
1) Instruction Synchronization Barrier(ISB),保证当前的pipeline中没有数据,ISB指令之前的指令都已经执行结束;
多用在context-switching code,cache control等。
2) Data Memory Barrier(DMB),保证所有data access的指令,load,store,在DMB指令之前都已经执行结束。
并不妨碍instruction的fetch。
3) Data Synchronization Barrier(DSB),等待某一类的指令结束,包括data access,instruction fetch。还会等待所有的
由该processor发起的cache,tlb,BP maintenance操作都已经完成,
DSB指令会直接stall processor,DMB不会,instruction仍然是可以执行的。
DMB和DSB,都可以加params,指定某些domain,load/store,

store-store,load-load,any-any指相应的乱序类型。
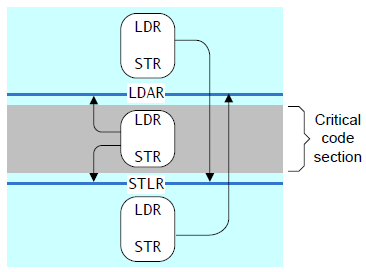
one-way barriers,AARCH64提供了一组显式指定before、after的指令,Load-Acquire,Store-Rlease,
Load-Acquire(LDAR),所有的load,store,完成之后,才开始执行,LDAR之后的指令开始执行。
Store-Release(STLR),所有的load,store,在STLR执行之后,才开始执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号