python语法
python是一种解释性的语言,执行过程会先进行编译在解释,但是python的编译不像java一样是必须执行的。
python中import的包,默认会被编译为pyc文件,如果py文件没有被修改,该import的pkg就不会在进行编译。
(这样实现了编译型语言的共享模块的加载速度快,解释性语言的跨平台移植性强)
python的运行有三种方式:
1) 交互式解释器,解释性语言的特性;直接在linux中,输入python;
2) 执行python脚本,python script.py;
3) 在IDE继承开发环境中开发,可以下载PyCharm;
Python默认的编码格式是ASCII编码,在没有修改编码格式时,是不能读写中文的,
python3.0之后,默认encoding是utf-8。
/usr/bin/python 与 /usr/bin/env python的区别:在python .py调用的时候没区别,
但是通过chmod a+x *.py,之后./py执行的时候,会有不同,env python会寻找path中的第一个python安装目录。
Python中的标识符,不能以数字开头,由字母,数字,下划线组成。所有的标识符都是大小写敏感的。
以下划线,开头的标识符,表示不能直接被class外部访问到的属性,不能用import导入,_foo;
以双下划线开头的标识符,表示class内部的私有变量,__foo;可以通过对象名._类名__私有属性名,来访问
前后都是双下划线的标识符,表示python中的特殊方法,构造函数__init__;
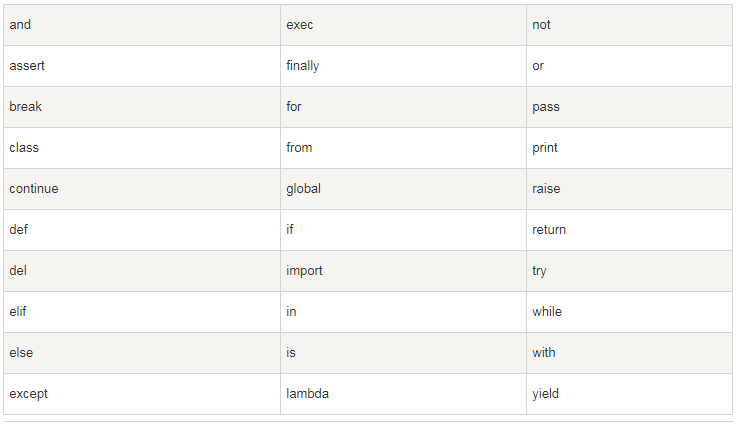
python中的保留字符,都是小写:
python中的所有代码块的缩进数量必须相同,可以是单个制表符,2个空格或4个空格等。
以缩进表示代码块,而不是{}
python中的package和module机制,
python中的模块,module,一般指一个py文件,其中包含了变量,常量,函数,class等数据。
python中的包,package,一般指一个目录结构,目录下边包括很多模块文件或者子包。都包含一个__init__.py的文件
__init__.py一般为空,引用package的时候,也是引用该模块,也可以在此文件中,引用其他的package,控制包的导入行为。
如果想用from package import *这种写法,需要在__init__.py中初始化__all__,__all__=['file1', 'file2'] #package下有file1和file2两个文件。
import X,表示将一个module或者package,引用到当前的namespace,但是访问attri和method,必须提供完整的路径。
from X import *,表示引入一个module或者package,将所有的public object引用到当前的namespace,访问时,提供相对的路径。
import subpackage1.a 将模块subpackage.a引入该namespace,访问时,仍然需要全路径,subpackage1.a.attr
from subpackage1 import a 将模块a导入该namespace,访问a中属性的时候,用a.attr
from subpackage1.a import attr 可以直接使用attr的表示。
python中的空行一般来表示模块的边界,
python中,可以使用斜杠"\",来将一长行代码转变为多行代码;[],(),{}中可以任意分为多行代码;
python中的字符串,可以在单引号''中,或者双引号""中,或者三引号''' ''''中,三引号中方便放很多包括'“”的特殊字符的字符串。
python中同一行写多行代码时,必须加分号;
python中的注释,#注释单行,“””注释多行“””;
python中的print默认输出换行符的,可以在后加逗号","来,避免print输出换行符。
像if,while,def,class这样的复合语句中,首行以关键字开始,冒号":"结束,之后是自己的子句。
if expression :
suite
elif expression :
suit
else :
suit
Python中的变量类型:
python中的变量不需要声明,直接在赋值的时候,将指针赋值给标识符,
1) Number(数值),存储数值,当指定一个值时,Number对象会被创建;
var1 = 1;
del语句,删除一些对象的引用,del var_a,var_b
数值类型的几种实例:int----10,long(用L表示)----10L,float------0.0,complex----(a+bj表示)或者complex(a,b)
2) String(字符串),可以由数字,字母,下划线组成。
索引:从左到右,默认从0开始;
从右到左,默认从-1开始;
截取:变量[头下标:尾下标]
+表示字符串的连接运算符,*表示字符串的重复操作。int类型的数据不能直接级联,需要str()转换一下
打印字符串,print str
3) List(列表),可以由数字,字符,字符串,列表(嵌套)组成。用[]来表示,有序的对象集合。
list = ['runoob', 786, 2.33]
索引:
截取:
+号和*号类似。
打印列表,print list
list.reverse(l),直接修改list,并没有返回值。
4) Tuple(元组),用()来表示。内部元素由逗号隔开,相当于只读列表。每个元素的地址不变,但是值是可以变的,比如其中有一个list,list是可以改变的。
tuple = ('runoob', 786, 2.33)
元组可以进行连接组合:tup3 = tup1+tup2, 返回tup1和tup2的连接组成一个新的元组。
只有一个元素的元组,a = tuple(1,) 必须加, 表示是一个元组,否则该运算符中的优先级处理。
无关闭分隔符,-------任何无符号的对象,以逗号隔开,默认为元组。
x, y = 1, 2; xy默认为一个元组赋值。
元组的内置函数:cmp(tuple1, tuple2),比较两个元组;
len(tuple),返回元组中的元素个数;
max/min(tuple),返回元组中的最大的值和最小的值。
5) Dictionary(字典),无序的对象集合,用{}来标识,由索引和value组成。
dist = {'name':'join', 'code':6734}
打印字典,print dist;print dist.keys();print dist.values()
python中的类型转换,返回的是一个新的对象:
数值类型:1) int(x);2) long(x); 3) float(x); 4) complex(real)
5) chr(x)整数转换为字符, 6) unichr(x) 整数转换为unicode,
7) ord(x)字符转换为整数值; 8) hex(x) 整数转换为16进制字符串;9) oct(x) 整数转换为8进制字符串;
字符串类型:1) str(x);转换为字符串,2) repr(x);转换为表达式字符串,3)eval(str),计算字符串中的有效表达式,返回一个对象;
元组类型:1) tuple(s),将s转换为一个元组;
列表类型:1) list(x),将序列s转换为一个列表;
字典类型:1) list(s),s必须是一个序列元组;
python所有的数据类型都是class,变量都是实例对象,可以通过type()查看该变量的数据类型,
n = 1; type(n); 返回’int‘
a = 111; isinstance(a, int); 返回true
isinstance(),可以包含子父类关系进行判断,type(),只负责该class的对象判断。
python中所有的空对象都是None,但是空字符,用null或者‘’来表示;
判断一个字符是否为空。
if str.strip() == '':
python中自定义class 函数,可以直接重载python builtin的默认的function,这些function以__开始,结束。
这一类的function有:如dir(int) __add__,__sub__,等。
dir(str) __lt__,__gt__,等。
通用的function有:__str__,__repr__,等,这两个function都是方便打印的。
__delattr__,__setattr__,__getattribute__等function,关于attr管理。
__hash__,存放对象的hash值,主要用在哈希值的查找中。
object的打印,默认都是打印的内存地址,__str__,面向用户,一般用在print中。
__repr__,面向开发者,应用在所有其他的场景打印中。
在python2.0中,print还是一个系统调用函数,在python3.0中,print已经是一个内置函数,打印的object需要在括号中;
python2.0:print "Hello. world"
python3.0:print("Hello, world")
python3.0中的print函数,可以指定,分隔符,以及行尾符,以及句柄,
print ("i","am","hym",sep=";",sed='\n',file=sys.stdout,flush=False)
默认的分隔符是空格,默认的行尾符是换行,默认的输出是stdout,不立即进行flush;
python3中,没有了xrange,只有range,功能上与xrange是相同的。
range和xrange的区别:
range(start, end, step),在某个范围之内,按某个步值,产生一个list,需要将list完全存放下来;
xrange,在功能上与range完全相同,但是返回的是一个生成器,在需要产生一个很大的list时,xrange的性能比range高很多。
几种list的遍历方式:
a = ['a', 'b', 'c', 'd']
1) for i in a: print i
2) for i in xrange(len(a)): print a[i]
3) for i, var in enumerate(a): print a[i],var
python内部提供的函数,enumerate(iterable, start),可以指定开始的节点
几种dict的遍历方式:
a = {'a':1, 'c':2,‘d’:3}
1) for k in d: print k,d[k]
2) for k,v in d.iteritems(): print k,v
iteritems(),dict内部的方法,实现对key和value的遍历;
类似的还有iterkeys()和itervalues()来分别实现对key和value的遍历
类似的还有view系列,与range一样,返回的是完整的dict,不是iterable的对象。
直接调用keys()和values()也可以
3) for k, v in d.viewitems():print k,v
构造dict的方法:
1) 两个list合并为一个dict, d = dict(zip('a', 'b', 'c'), (1, 2, 3)) 产生一个dict对象,{‘a’:1,‘b’:2,‘c’:3}
python中的map函数,对指定的序列做函数映射:
map(function, iterable);
def square(x):
return x**2;
map(square, [1,2,3,4,5]) 返回1,4,9,16,25
map(lambda x: x**2, [1,2,3,4,5]) 返回1,4,9,16,25
lambda,定义一个匿名的函数映射,
map(lambda x,y:x+y, [1,3,5,7,9], [2,4,6,8,10]) 返回两个list中元素的和,[3,7,11,15,19]
其他的全局函数还有,filter(过滤掉不符合条件的list中的元素),reduce(对列表等中的元素做累加),
def is_odd(n):
return n%2 == 1
newlist = filter(is_odd, [1,2,3,4,5,6,7,8,910])
python的debug模式:
运行:Python -m python.script
设置断点:break/b
单行执行:next/n
打印变量的值:pp
查看当前行的代码段:list/l
进入函数:step/s
执行到函数返回:return/r
python中的attr管理,obejct内中自建的function:
1) hasattr(object, name),判断一个对象中是否有某个属性或者方法,返回bool值;
t = test()
hasattr(t,"name") name是t中的属性
hasattr(t,“run”) run是t中方法
2) getattr(object, name, default),拿到某个实例中的方法,返回内存地址,如果需要执行,在之后加(),属性,拿到属性值,
t = test()
getattr(t, "name") 返回"xiaohua"
getattr(t, "age", "18") 不存在age时,可以自己指定一个返回的默认值
3) setattr(object, name, default),给属性赋值,如果不存在就先创建,在赋值
t = test()
setattr(t,“age”,“18”) 先在t中创建一个age的属性,之后赋值18
getattr(t, "run")() 如果t中有run方法,就执行。
python中的@property,属性装饰器。在给属性赋值的过程中,可以增加set get的判断操作。
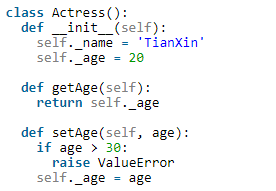
为了方便操作,使用property装饰器,age = property(getAge, setAge, None, ‘age property’) (该none表示没有del的function)
这样对age的操作,就可以直接赋值,但是也会调用set的判断。

也可以使用@property来实现上边的功能:

python2在使用property的时候,class必须继承object,是新式类,python3无影响。
装饰器,将对属性的操作,转变为了function的调用,更方便代码的重构。
pyc文件,python编译之后的文件,是一种byte code,py文件变为pyc之后,加载的速度会有所提高。不同版本之间的pyc文件是不通用的。
python -m python.script 产生pyc文件。
pyo文件,python优化编译之后的文件, python -O python.script 产生pyo文件。
pyc文件也可以防止商业软件的盗用。
python中的全局变量,是指在该模块,一个py文件中的全局变量。如果在一个def中需要使用某个全局变量x,
global x,显示指向def外的global变量。
如果在def中,使用了与global相同名字的变量又没有声明global,之后又对变量做赋值,python会直接报错。
在def中,声明global变量,最好放在第一行,避免产生warning。
python中的每个模块都有自己的__name__属性,而且这个属性是随时变化的,
如果该模块被import,该模块的__name__为该模块的名字;
如果该模块直接运行,该模块的__name__是__main__;
python的异常,通过raise Exception来触发,
def functionName(level):
if level < 1:
raise Exception(Invalid level!, level)
对于可能出现异常的代码,代码结构:
try:
fh = open()
except:
finally:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号