
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
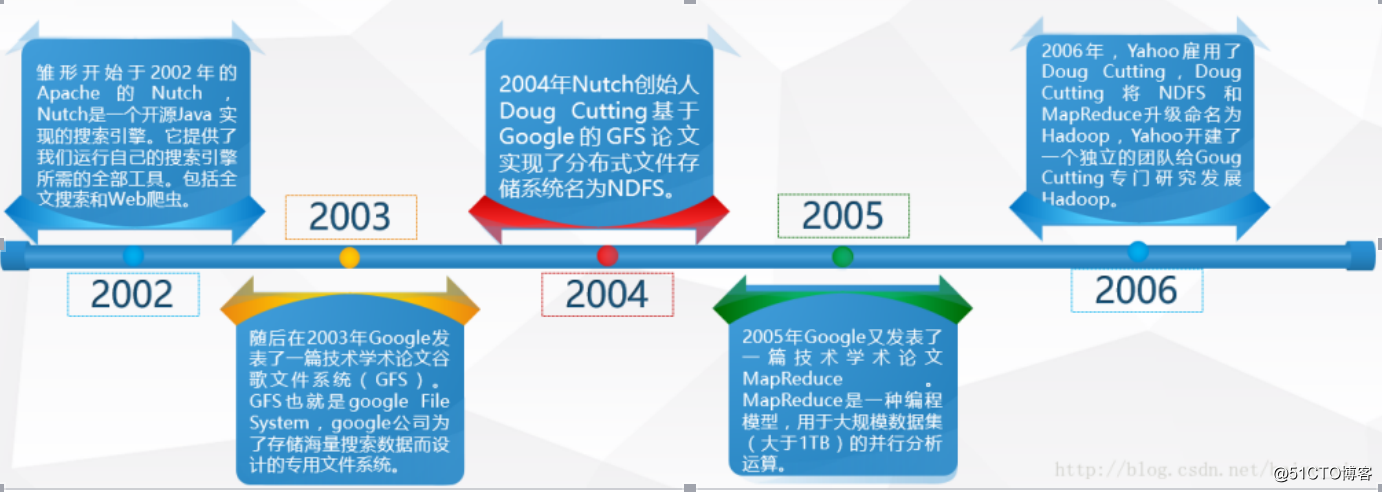
1)Lucene 是 Doug Cutting 开创的开源软件,实现与 Google 类似的全文搜索功能,它提供了全文检索引擎的架构,包括完整的查询引擎和索引引擎
2)2001 年年底成为 Apache 基金会的一个子项目
3)Google的三篇论文是 hadoop 的思想之源(Google 在大数据方面的三篇论文)
GFS --->HDFS
Map-Reduce --->MR
BigTable --->Hbase
4)2003-2004 年,Google 公开了部分 GFS 和 Mapreduce 思想的细节,以此为基础 Doug Cutting等人用了 2 年业余时间实现了 DFS 和 Mapreduce 机制
5)2006 年3 月份,Map-Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中
6)名字来源于 Doug Cutting 儿子的玩具大象,Hadoop由此诞生
2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系
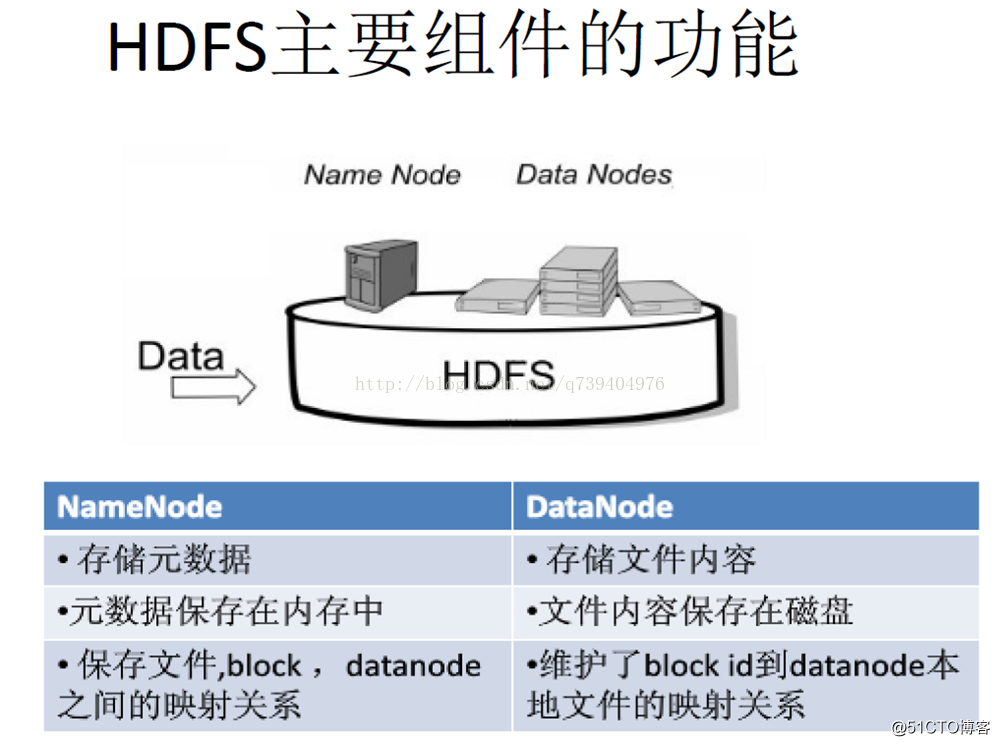

在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog
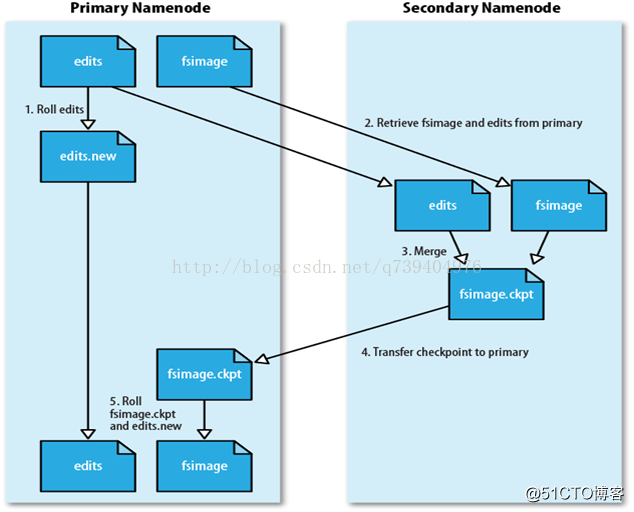
第二名称节点(SecondaryNameNode)
:是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。
SecondaryNameNode一般是单独运行在一台机器上
SecondaryNameNode让EditLog变小的工作流程:
(1)SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;
(2)SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下;
(3)SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新;这个过程就是EditLog和FsImage文件合并;
(4)SecondaryNameNode执行完(3)操作之后,会通过post方式将新的FsImage文件发送到NameNode节点上
数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表
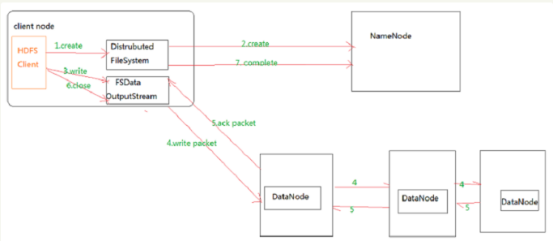
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
- 数据错误与恢复


 浙公网安备 33010602011771号
浙公网安备 33010602011771号