

转:https://www.cnblogs.com/fariver/p/7446921.html
结论:
(1) 速度更快(实时):yolo(24 convs) -> 45 fps,fast_yolo(9 convs) -> 150 fps
(2) 全图为范围进行检测(而非在建议框内检测),带来更大的context信息,使得相对于Fast-RCNN误检率更低,但定位精度欠佳。
YOLO损失函数
Loss = 坐标预测误差(1) + 含object的box confidence预测误差 (2)+ 不含object的box confidence预测误差(3) + 每个格子中类别预测误差(4)

根据这个损失函数,迭代训练网络。
(1) 整个损失函数针对边界框损失(图中1, 2, 3部分)与格子(4部分)主体进行讨论。
(2) 部分1为边界框位置与大小的损失函数,式中对宽高都进行开根是为了使用大小差别比较大的边界框差别减小。例如,一个同样将一个100x100的目标与一个10x10的目标都预测大了10个像素,预测框为110 x 110与20 x 20。显然第一种情况我们还可以失道接受,但第二种情况相当于把边界框预测大了一倍,但如果不使用根号函数,那么损失相同,都为200。但把宽高都增加根号时:
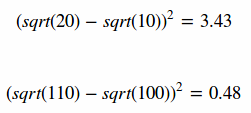
显然,对小框预测偏差10个像素带来了更高的损失。通过增加根号,使得预测相同偏差与更小的框产生更大的损失。但根据YOLOv2的实验证明,还有更好的方法解决这个问题。
(3) 若有物体落入边界框中,则计算预测边界框含有物体的置信度C
和真实物体与边界框IoUC
的损失,我们希望两差值越小损失越低。
(4) 若没有任何物体中心落入边界框中,则C
为0,此时我们希望预测含有物体的置信度C越小越好。然而,大部分边界框都没有物体,积少成多,造成loss的第3部分与第4部分的不平衡,因此,作才在loss的三部分增加权重。
(5) 对于每个格子而言,作者设计只能包含同种物体。若格子中包含物体,我们希望希望预测正确的类别的概率越接近于1越好,而错误类别的概率越接近于0越好。loss第4部分中,若pi(c)ˆ中c为正确类别,则值为1,若非正确类别,则值为0。
