博物识植——多源异构数据采集与融合应用综合实践
| 这个项目属于哪个课程 | 2024数据采集与融合技术实践 |
|---|---|
| 组名 | 从你的全世界爬过 团队logo:  |
| 项目简介 | 项目名称:博物识植 项目logo:  项目介绍:在探索自然奥秘的旅途中,我们常与动植物相伴而行,却无法准确识别它们,更难以深入了解他们的特征。为了更好地理解和欣赏自然界的多样性,提升我们对动植物的认识和保护意识,我们需要一个智能系统。该系统能够根据用户拍摄的动植物照片,智能识别并匹配相应的信息,同时为用户提供丰富的学习资源,帮助人们更深入地了解和学习动植物知识。通过这样的方式,我们不仅能够更准确地识别和欣赏周围的生命,还能够在日常生活中,随时随地增长见识,体验探索自然的乐趣。 项目背景:人类的生活离不开动植物的支持,动植物的多样性是一切地球生物的依赖。在生活中随处可见很多动植物,动植物是人类生活必不可少的一部分。 保护大自然保护动植物就是在保护人类自己。在保护动植物的过程中,首先要解决的是动植物识别的问题。 项目意义:提供了一种我们与自然界互动的方式。其应用场景广泛,渗透到了教育、旅游等多个领域。在学校,它可以是生物课程的辅助工具,通过实践学习生物多样性;在旅游行业,它可以帮助游客更好地了解他们所参观的自然景观,提升旅行体验 |
| 团队成员学号 | 042201401陈高菲、102202107王勤琛、102202108王露洁、102202115孙佳会、102202123张铭心、102202130林烨、102202138徐婉瑜、102202140郭心怡 |
| 项目目标 | 本系统旨在实现以下功能: a.图片识别功能:用户上传动植物图片,系统通过图像识别技术自动识别物种,返回准确的物种名称。 b.物种详细信息:识别后,用户将获取该物种的详细信息,包括外形特点、生长环境、分布区域等相关数据。 c.物种图片展示:系统将提供该物种的高质量图片,帮助用户更直观地了解物种特征。 d.名称搜索功能:用户可以手动输入动植物的名称,系统将返回该物种的相关信息,方便快速查询。 e.网站部署上线:通过华为云的弹性计算服务部署网站,确保系统高可用和稳定运行,实现网站上线。 |
| 其他参考文献 | 1.yanjingang/pigimgclassification: 图像分类 2.基于改进SE-MnasNet骨干网络YOLOv5的动植物树木识别系统_开源 树木识别 |
| gitee链接 | 2024学年数据采集与融合技术大作业——博物识植 团队:从你的全世界爬过 |
一、系统总体技术概述
1.1 系统架构概述
系统分为前端、后端、数据库、AI接口、爬虫模块、部署等多个层级。前后端之间通过RESTful API进行通信。具体分为以下几个部分:
- 前端:使用HTML、CSS和JavaScript进行界面设计,实现用户与系统的交互。用户可以上传文本、图片等文件。
- 后端:使用Python语言和Flask框架实现,处理图像识别、查询请求、调用AI接口和爬虫数据存储等业务逻辑。
- 数据库:存储动植物物种的详细信息,包括图像、分布、特点等。存储物种识别的历史记录信息。
- 图像识别与AI接口:利用图像识别模型或调用第三方AI服务(如百度AI、Google Vision等)识别图片并返回结果。
- 爬虫:提前爬取动植物相关网站数据,补充物种数据库。使用Selenium框架进行实时图片爬取。
- 部署平台:使用华为云平台部署系统,保证系统的高可用和稳定性。
1.2 各模块技术实现
1.2.1 图像识别模块
- 目标:用户上传图片,系统通过图像识别技术返回物种名称。
- 技术方案:
使用深度学习模型:基于改进SE-MnasNet骨干网络YOLOv5和卷积神经网络cnn opencv进行图像分类和识别。
基于识别精确度的考虑调用第三方云服务百度智能云的动植物识别API提供快速而准确的图像识别。 - 流程:
用户上传图片,前端将图片通过API发送至后端。
后端调用模型或AI图像识别API分析图片,获取可能的物种标签。
后端将物种名称返回给前端,前端展示识别结果。
1.2.2 物种信息查询功能
- 目标:根据识别后的物种名称或用户输入的名称,返回该物种的详细信息。
- 技术方案:
利用selenium技术和scrapy框架爬取信息网站所有物种信息(如外形特点生长环境、分布区域等)存储在csv表导入数据库并定期更新。
利用查询语句在数据库中进行查找并返回详细信息。
若数据库中没有相关信息,则调用百度智能云的千帆大模型识别物种名称,查询物种相关信息。 - 流程:
后端识别出物种名称时,系统首先查询数据库,若没有该物种的信息,再调用AI接口获取。
1.2.3 相似图片展示
- 目标:根据用户上传的图片,返回物种的相似图片,帮助用户直观了解物种。
- 技术方案:
运用selenium爬虫技术实时爬取百度识图返回的相似图片 - 流程:
后端接收前端传入的图片后,将图片作为输入文件传入百度识图网站实时爬取相似图片,在系统返回物种详细信息时,将图片URL一并返回。
1.2.4 保存历史记录
- 目标:将用户的历史搜索记录保存至数据库,方便用户在“我的图鉴”页面查看并跳转至物种详情页,随时查看过去的搜索记录。
- 技术方案:
创建一个数据库表专门用来保存用户的搜索记录,包括用户上传的图片、识别出来的物种名称、物种的详细信息(如描述、分布、图片URL等) - 流程:
当用户获取识别结果时,后端系统会将物种信息保存至数据库中。在点击我的图鉴中的物种名称时,后端调取数据库信息展示在前端界面。
1.2.5 部署与部署架构
- 目标:将整个系统部署到华为云服务器上,让非本地用户可以访问。
- 技术方案:
使用华为云ECS(Elastic Cloud Server)部署后端服务。
使用华为云OBS 存储图片等静态资源。
使用RDS(Relational Database Service)存储物种信息数据库。
前端可以使用 Nginx 进行负载均衡和反向代理 - 流程:
前后端文件上传部署完成后即可实现非本地用户的访问。
1.3 源码运行步骤
- gitee仓库下载源码
- 启动文件中的ai.py与database.py文件
- 运行index.html文件
(!注意在本地主机运行代码时请更换代码中的路径名)
二、个人分工
| 学号姓名 | 个人分工 |
|---|---|
| 102202115孙佳会 | 前端页面设计开发(植物识别部分),以及与后端连接 |
前端部分使用HBuilderX工具,通过HTML、CSS和JavaScript进行界面设计,实现用户与系统的交互。
2.1 前期调研以及idea的完善
2.1.1 前期调研
在确立初步想法后,我们对市面上同类型的应用、小程序及网站进行了调研,涵盖了“形色”、“iPlant植物智”、“懂鸟”、“晓虫”等平台。调研结果如下:
- 功能单一:大多数软件只能单独识别植物、动物或特定物种(如鸟类、昆虫等),缺乏一款综合识别动植物的应用。
- 技术落后:多数应用未引入先进的大模型技术,导致识别准确度不足。
- 专业性强:部分软件(如iPlant植物智)的识别结果偏向专业,适合专业人士使用,对于普通用户而言,门槛较高。
2.1.2 Idea 完善
基于前期调研和第一次汇报中导师的反馈意见,我们对初步想法进行了完善和优化,具体改进如下:
-
增加“我的图鉴”功能
通过该功能,用户可以保存以往的搜索历史,方便随时查看和管理图鉴,满足用户收集和回顾的需求,提升应用的用户粘性。 -
引入实时相似图片爬取功能
用户上传图片后,系统将实时爬取相似图片并展示在详情页,便于用户进行对比分析。
初步设想:根据图片识别结果爬取对应图片。
调整后:与后端团队讨论后,优化为爬取相似图片,提高识别的相关性和用户体验。 -
添加文本搜索功能
除了图片识别,用户还可以通过文本搜索进行查询。
初步设想:实现三种搜索模式——图片、文本、图片+文本补充。
通过描述植物特征或生长环境等信息进行文本搜索。
调整后:但发现条件区分过多且接口调用频繁,导致响应速度极慢,最终放弃该方案。简化为单一的图片或文本搜索。
但考虑到大多数用户难以准确描述植物信息,最终调整为简单的植物名称搜索,提升搜索效率和用户体验。 -
丰富前端展示内容
在前端页面中展示部分植物图片及相关信息,并定期更新内容,帮助用户认识更多植物,增强应用的知识普及功能。
2.2 植物识别页面效果
使用工具:HBuilderX(HTML、CSS和JavaScript)
后端连接:通过在plants_get.html文件的script部分添加与后端API连接的代码。
主要设计了四大页面
- 拍拍园地(首页:项目及其团队的特色介绍)
- 植物百科(植物识别页面:识别图片/搜索物种并返回结果 注:结果也是一个details页面)
- 动物绘本(动物识别页面:同上)
- 我的图鉴(将搜索的结果通过点击“记录”键存入小识图鉴)
整体采用符合项目主题的绿色清新风,干净整洁的ui设计是让生物爱好者在此停留品味自然的关键。
本人主要完成页面为植物百科以及识别详情页。
2.2.1 页面及功能展示
植物百科



页面大体可以分为两部分:
- 上半部分:进行上传图片识别或输入文字搜索。
- 下半部分:展示一些植物的介绍。
植物图片识别

启动 app.py 后,点击上传图片,上传后点击“识别植物”按钮,进行识别。
识别详情页
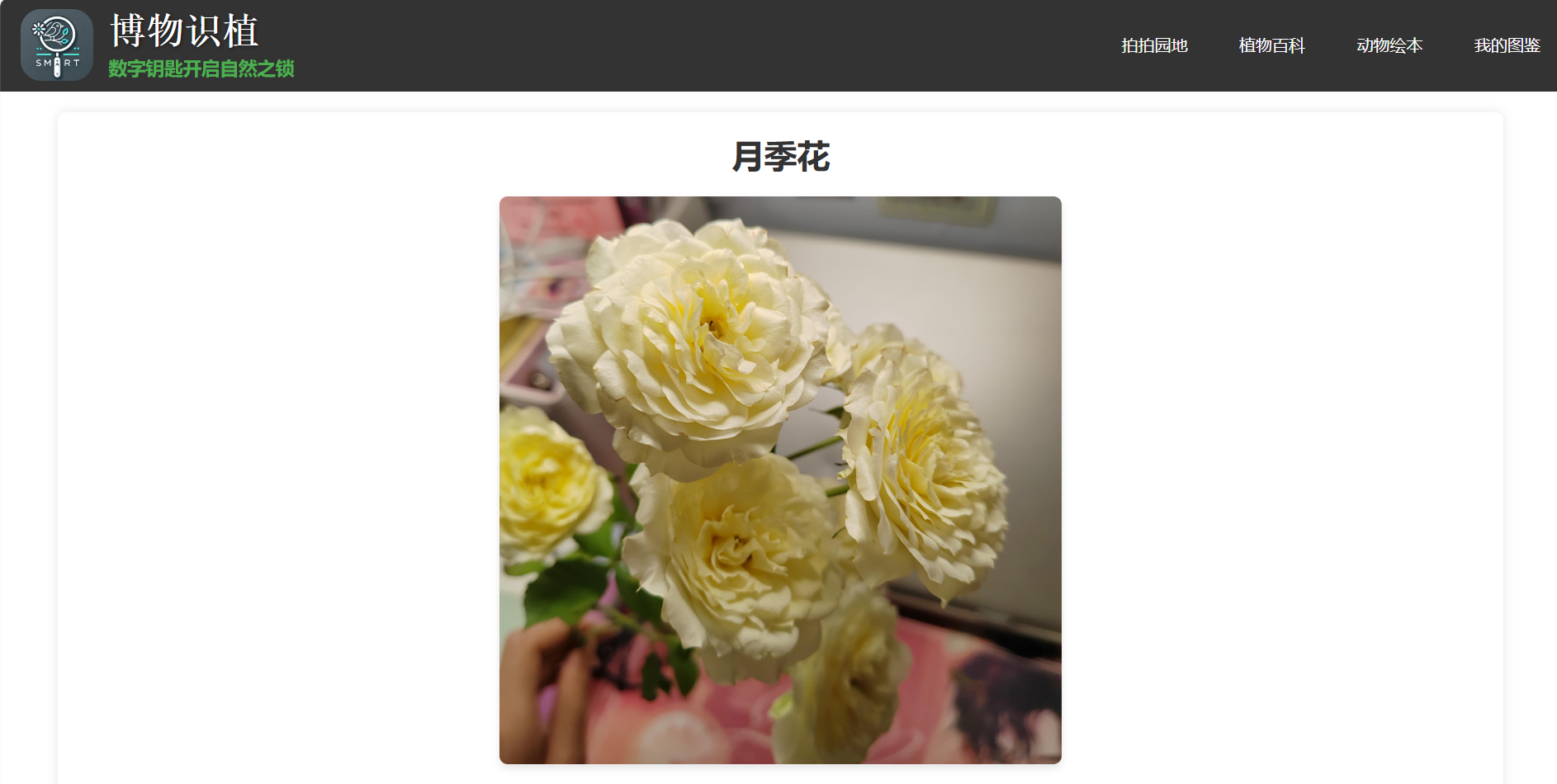

在识别后,详情页展示了上传植物图片的识别结果。页面中包括:
- 植物名称:识别到的植物名称会在页面显著位置显示。
- 上传图片:展示用户上传的植物图片,便于用户确认识别结果。
- 相似图片:通过上传的图片实时爬取相似图片,供用户参考和对比分析。
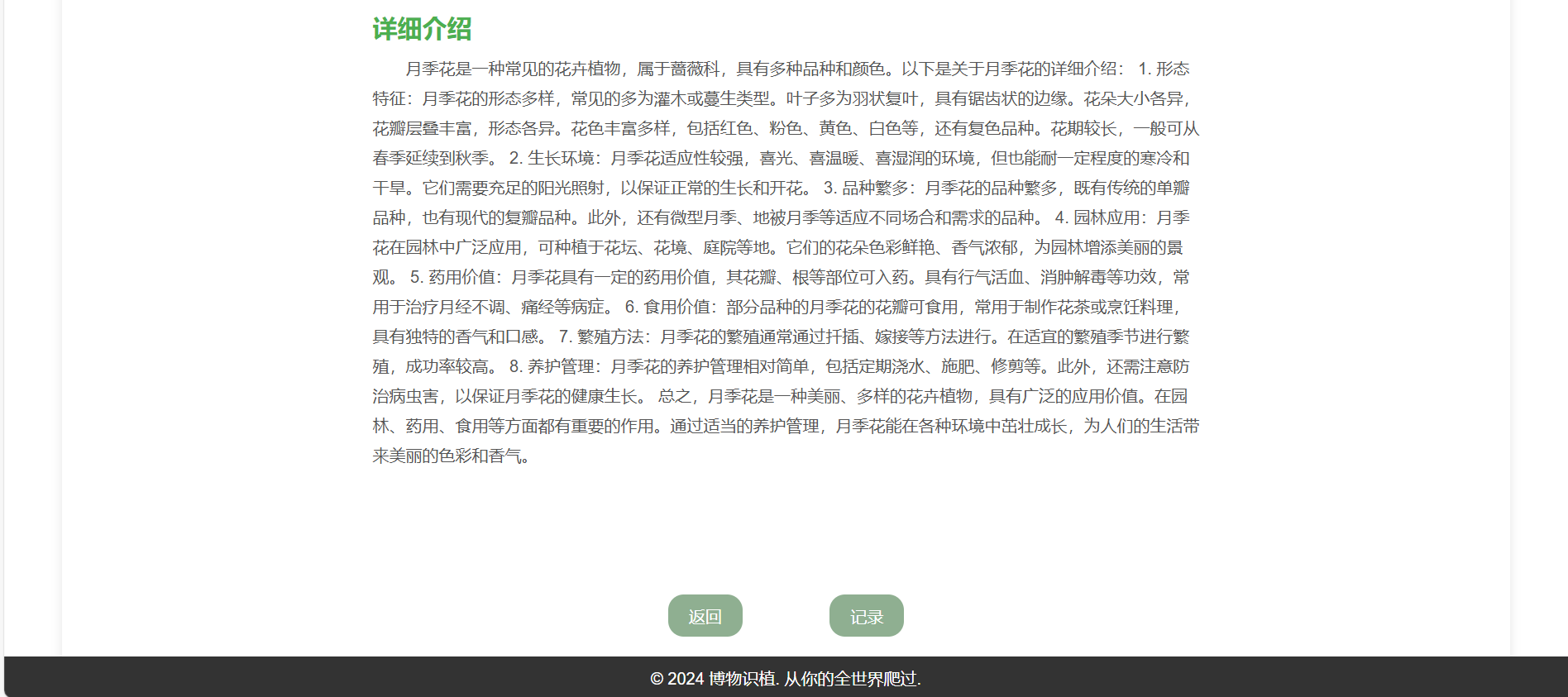
此外,页面还提供了植物的详细介绍,包括但不限于:
- 基本信息:植物的科属、原产地等基本数据。
- 形态特征:包括叶片、花朵、根系等的描述,帮助用户更好地理解该植物。
- 生长环境:植物适宜的生长环境、气候条件等信息,满足用户对植物识别的需求。
注:以上内容仅为示例,具体展示内容可能因识别结果而异,并非所有识别结果都会包含这些部分。
文本搜索
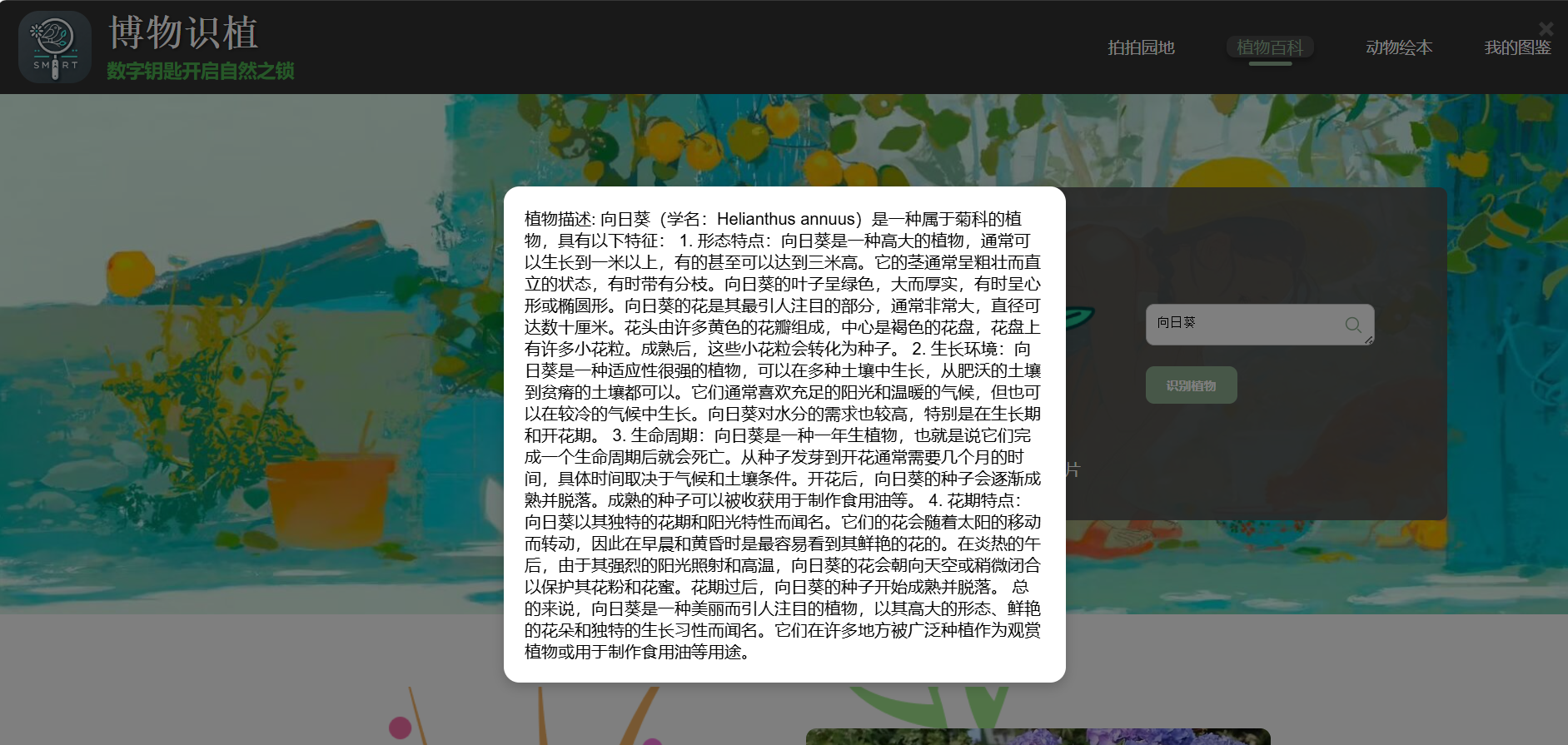
除了图片识别,页面还提供了文字搜索功能。当用户在搜索框中输入植物名称时,系统会弹出介绍该植物的基本信息,帮助用户快速了解植物的特征和背景。
这种设计让用户不仅可以通过图片进行识别,也能通过文字进行搜索,增加了应用的灵活性和可用性。
2.2.2 与后端连接
在plants_get.html文件的script部分添加与后端api连接的代码。
图片识别功能实现
-
使用
fetch API向后端发送 POST 请求,调用classify_plants接口进行植物分类,返回植物名称、百科信息等数据。若成功,继续调用upload_and_crawl接口,获取与上传图片相似的植物图片,进行数据采集。 -
在成功获取
classify_plants和upload_and_crawl接口的数据后,将两个接口返回的数据合并为一个对象。这个对象包含植物的基本信息、相似图片以及其他相关内容,确保用户获得全面的识别结果。 -
将合并后的数据存储到
localStorage中,确保用户可以在不同的页面间持续访问识别结果。这样既提高了数据访问速度,也方便了用户查看历史记录和识别结果。 -
使用
FileReader将上传的图片转换为 DataURL 格式,并将其存储在localStorage中。这确保了上传的图片可以在页面上即时展示,且无需再次从服务器加载。
文本搜索功能实现
- 使用
fetch API发送 POST 请求,将包含用户输入描述的FormData对象作为请求体发送到后端服务器,接口地址为http://localhost:5000/api/submit_description_plant。 - 请求成功后,使用
response.json()方法将返回的 JSON 数据解析为 JavaScript 对象。 - 根据返回的
data.success判断是否成功。如果成功,展示相关的植物信息或错误提示。
图片识别代码详情
// 识别植物按钮的点击事件处理
document.getElementById('search-button').addEventListener('click', function () {
var fileInput = document.getElementById('file-upload');
if (fileInput.files && fileInput.files[0]) {
var file = fileInput.files[0];
// 创建 FormData 对象
var formData = new FormData();
formData.append('image', file);
console.log("Uploading image:", file.name);
// 首先调用 classify_plants 接口
fetch('http://localhost:5000/api/classify_plants', {
method: 'POST',
body: formData
})
.then(response => response.json())
.then(data1 => {
if (data1.success) {
// 然后调用 upload_and_crawl 接口
return fetch('http://localhost:5000/api/upload_and_crawl', {
method: 'POST',
body: formData
})
.then(response => response.json())
.then(data2 => {
if (data2.success) {
// 合并两个接口返回的数据
var combinedData = {
plant_name: data1.plant_name,
baike_info: data1.baike_info,
details: data1.details,
similar_images: data2.similar_images
};
console.log("Combined Data:", combinedData);
// 存储到 localStorage
localStorage.setItem('plantDetails', JSON.stringify(combinedData));
// 存储上传的图片DataURL到 localStorage(用于详情页展示)
var reader = new FileReader();
reader.onload = function(e) {
localStorage.setItem('uploadedImage', e.target.result);
console.log("Uploaded Image DataURL stored.");
};
reader.readAsDataURL(file);
// 跳转到 details.html 页面
window.location.href = 'details.html';
} else {
document.getElementById('search-results').innerHTML = `<p>Error: ${data2.error}</p>`;
console.error("upload_and_crawl error:", data2.error);
}
});
} else {
document.getElementById('search-results').innerHTML = `<p>Error: ${data1.error}</p>`;
console.error("classify_plants error:", data1.error);
}
})
.catch(error => {
console.error('Error:', error);
document.getElementById('search-results').innerHTML = `<p>Error: ${error.message}</p>`;
});
} else {
alert('请先上传植物图片。');
}
});
});
文本搜索代码详情
// 确保弹窗初始状态为隐藏
document.getElementById('popup').style.display = 'none';
document.getElementById('search-icon').addEventListener('click', function() {
var descriptionInput = document.getElementById('description-input');
// 确保输入框有值
if (descriptionInput.value.trim() !== '') {
var description = descriptionInput.value;
var formData = new FormData();
formData.append('description', description);
// 发送POST请求
fetch('http://localhost:5000/api/submit_description_plant', {
method: 'POST',
body: formData
})
.then(response => response.json())
.then(data => {
if (data.success) {
// 如果请求成功,显示植物描述
document.getElementById('popup-content').innerHTML = `<p>植物描述: ${data.details}</p>`;
openPopup(); // 使用封装的 openPopup 函数来显示弹窗
} else {
// 如果请求失败,显示错误信息
document.getElementById('popup-content').innerHTML = `<p>Error: ${data.error}</p>`;
openPopup(); // 使用封装的 openPopup 函数来显示弹窗
}
})
.catch(error => {
// 捕获并显示请求错误
console.error('Error:', error);
document.getElementById('popup-content').innerHTML = `<p>Error: ${error.message}</p>`;
openPopup(); // 使用封装的 openPopup 函数来显示弹窗
});
}
});
2.3 个人收获
这次大作业给我带来了很多收获,不仅是在技术上的提升,还有团队协作中一些宝贵的经验。我们前端小组在设计页面时一直比较注重用户体验,力求做到界面简洁、功能完备。随着需求的变化,页面效果也不断调整,真的是不断在摸索和试错中前进。最初因为前后端分离的沟通不到位,导致在实现功能和连接后端时遇到了不少问题。但最终大家齐心协力,一起讨论、调整,慢慢理清了思路。
通过这次合作,我也更清楚地意识到前后端对接的重要性。特别是在使用 fetch API 和后端交互时,不仅要考虑接口是否稳定,还要注意数据格式的一致性,异常情况的处理也不能忽视。幸运的是,随着接口设计逐渐清晰,我们前端和后端同学配合得越来越好,数据传递变得顺畅,页面功能实现也更加一致。
总的来说,这次项目让我不仅学到了更多技能,更让我体会到团队合作的力量,尤其是在遇到困难时,大家共同探讨和解决问题的过程,让我受益匪浅。这种集思广益的方式,真的能让我们做得更好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号