数据采集与融合第四次作业
作业①
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:
东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:
MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
| 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 301522 | N上大 | 79.85 | 1060.61 | 72.97 | 595675 | 5031370784.78 | 582.56 | 102.00 | 61.92 | 61.92 | 6.88 |
爬取股票
🌱实现思路
1.初始化 WebDriver
设置Selenium WebDriver,选择Chrome WebDriver,并配置必要的选项,如无头模式,以在后台运行浏览器。
2.导航到目标网页
通过WebDriver访问东方财富网的特定板块URL,这个URL是带有股票数据的网页。
3.等待页面加载
使用WebDriverWait等待页面的特定元素加载完成,确保页面数据已完全加载,特别是对于动态加载的内容。
4.爬取数据
利用Selenium的元素选择功能,定位股票数据表格,根据HTML结构抓取所需的股票信息,例如股票代码、名称、最新价格、涨跌幅等。
5.数据存储
将抓取到的数据存储到MySQL数据库中,同时处理可能的数据更新和异常。
6.循环访问
需要从多个板块抓取数据,所以设置一个循环,遍历各个板块的URL,重复执行上述爬取和存储数据的过程。
🎨主要代码
1.启动 MySQL 数据库,使用以下语句创建一个数据库和数据表
CREATE DATABASE IF NOT EXISTS stock_data;
USE stock_data;
CREATE TABLE IF NOT EXISTS stocks (
id INT AUTO_INCREMENT PRIMARY KEY, -- 自增主键
bStockNo VARCHAR(20) NOT NULL, -- 股票代码
bStockName VARCHAR(100) NOT NULL, -- 股票名称
bLastPrice VARCHAR(20), -- 最新报价
bChangeRate VARCHAR(20), -- 涨跌幅(带%)
bChangeAmount VARCHAR(20), -- 涨跌额(带单位)
bVolume VARCHAR(20), -- 成交量(带单位)
bAmplitude VARCHAR(20), -- 振幅(带%)
bHigh VARCHAR(20), -- 最高价
bLow VARCHAR(20), -- 最低价
bOpen VARCHAR(20), -- 今开价
bPrevClose VARCHAR(20), -- 昨收价
board VARCHAR(20), -- 板块信息
timestamp DATETIME DEFAULT CURRENT_TIMESTAMP, -- 数据插入时间
UNIQUE KEY unique_stock_time (bStockNo, timestamp) -- 唯一键,防止重复插入相同时间的数据
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
为了区分不同板块的数据,在数据库表中添加一个board字段来记录板块信息。
2.根据题目要求构建所需目标网址
base_url = 'http://quote.eastmoney.com/center/gridlist.html'
url = f"{base_url}{board_hash}"
driver.get(url)
# 定义需要爬取的板块及其对应的 Hash Fragment
boards = [
{'name': '沪深 A 股', 'hash': '#hs_a_board'},
{'name': '上证 A 股', 'hash': '#sh_a_board'},
{'name': '深证 A 股', 'hash': '#sz_a_board'}
]
for board in boards:
print(f"正在爬取 {board['name']} 数据...")
stock_data = scrape_data(board['hash'])
if not stock_data:
print(f"未获取到 {board['name']} 的任何数据。")
continue
遍历需要爬取的板块,依次爬取所需信息。
3.等待页面动态加载完成
try:
# 根据实际情况调整等待条件
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'table#table_wrapper-table'))
)
except Exception as e:
print(f"页面加载超时 ({board_hash}):", e)
driver.quit()
return []
4.根据网页结构设计XPATH语句爬取目标信息
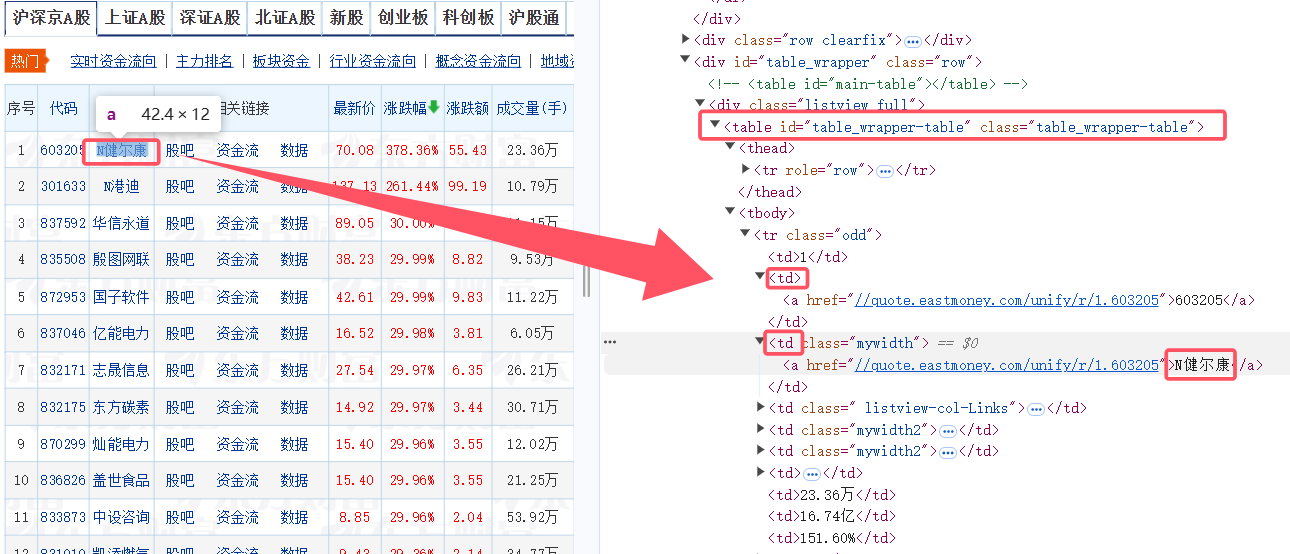
# 定位股票数据表格
try:
table = driver.find_element(By.CSS_SELECTOR, 'table#table_wrapper-table')
tbody = table.find_element(By.TAG_NAME, 'tbody')
rows = tbody.find_elements(By.TAG_NAME, 'tr')
except Exception as e:
print(f"无法定位表格或行 ({board_hash}):", e)
driver.quit()
return []
data = []
for row in rows:
try:
cols = row.find_elements(By.TAG_NAME, 'td')
# 根据页面结构提取数据,以下索引可能需要根据实际页面调整
bStockNo = cols[1].text.strip()
bStockName = cols[2].text.strip()
bLastPrice = cols[4].text.strip()
bChangeRate = cols[5].text.strip()
bChangeAmount = cols[6].text.strip()
bVolume = cols[7].text.strip()
bAmplitude = cols[9].text.strip()
bHigh = cols[10].text.strip()
bLow = cols[11].text.strip()
bOpen = cols[12].text.strip()
bPrevClose = cols[13].text.strip()
data.append((
bStockNo, bStockName, bLastPrice, bChangeRate, bChangeAmount,
bVolume, bAmplitude, bHigh, bLow, bOpen, bPrevClose,
board_hash # 添加板块信息
))
except Exception as e:
print("数据提取错误:", e)
continue
💡运行结果
终端输出:

数据库内容:
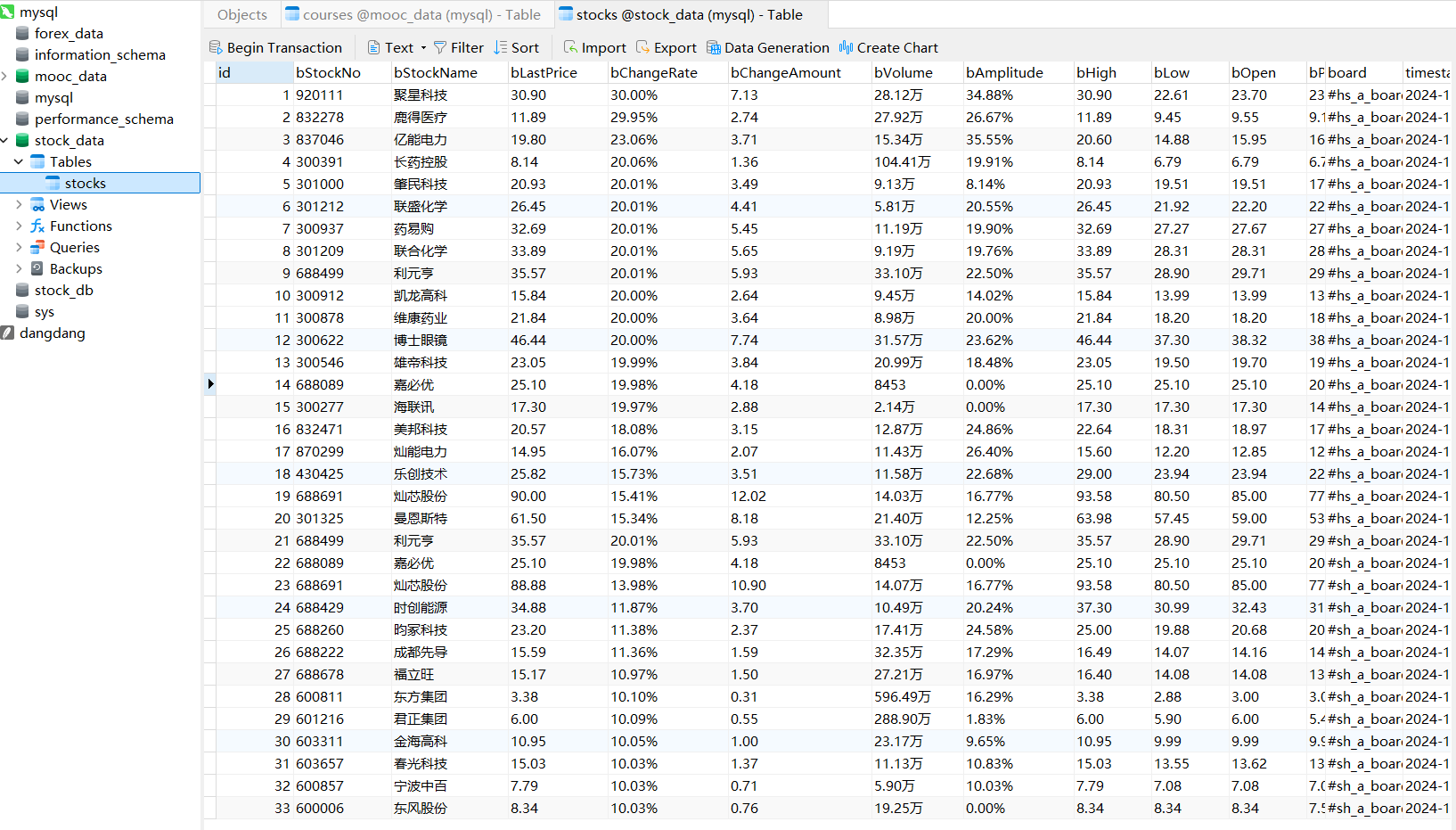
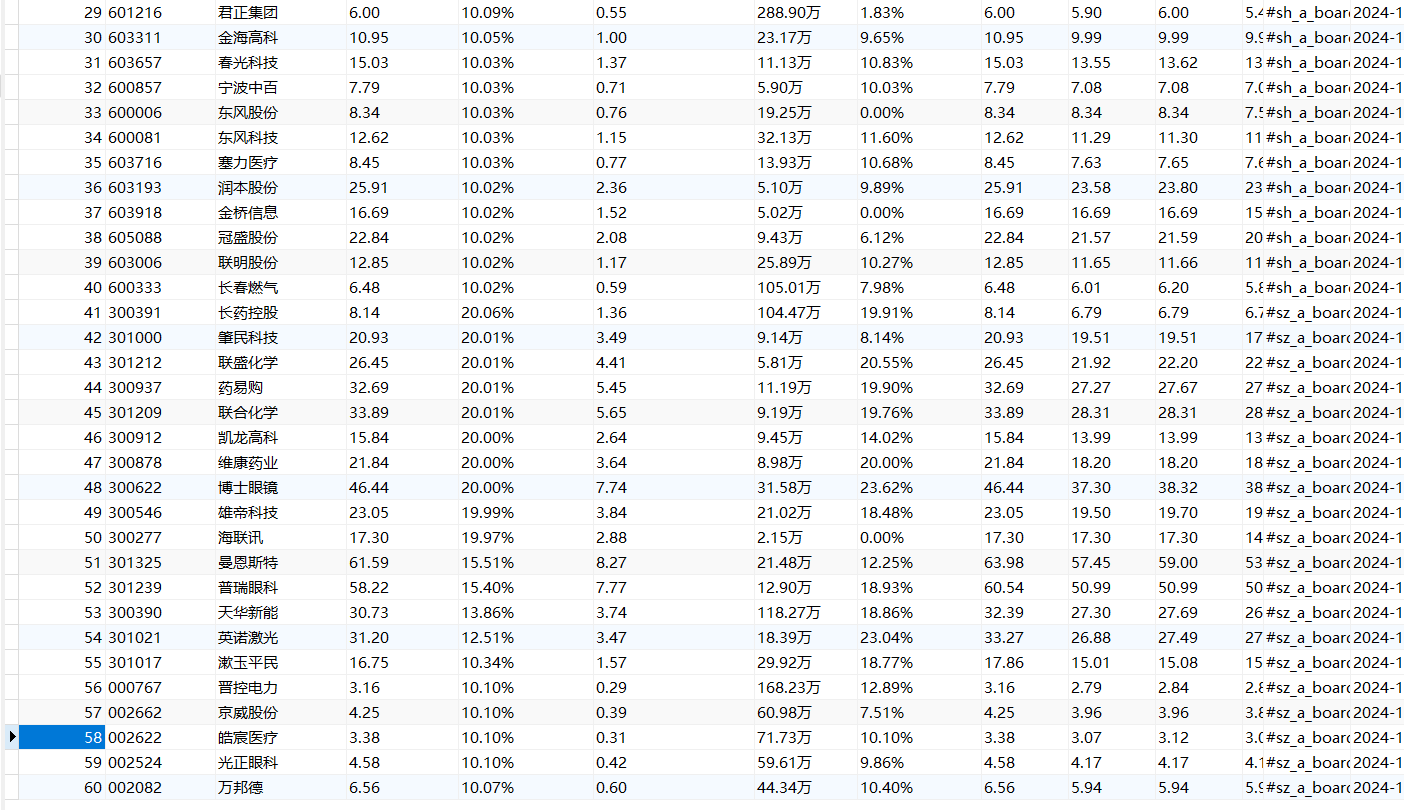
每个板块爬取20条数据,共60条。
遇到的问题及解决
-
问题1:为了实现同时爬取“沪深 A 股”、“上证 A 股”及“深证 A 股”三个板块的股票数据信息,最初采用Selenium模拟依次点击的方法,出错,只能爬取到“沪深 A 股”板块信息。
-
解决1:根据页面结构分别获取三个板块的URL,依次访问。
-
问题2:在创建数据库表结构时将很多字段类型设为float,后续插入时因为部分字段包含单位(如“万”)导致无法插入。
-
解决2:部分字段的数据类型需要从数值类型(如 INT、FLOAT)改为字符串类型(如 VARCHAR),保留包含“万”、“亿”及“%”的字符串。
心得体会
在爬取股票数据的过程中,遇到了很多挑战,也因此让我更加深刻地理解了现代网页技术如JavaScript和Ajax的工作原理,以及如何使用工具如Selenium来有效应对。
作业②
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:
中国mooc网:https://www.icourse163.org
输出信息:
MYSQL数据库存储和输出格式
Gitee文件夹链接
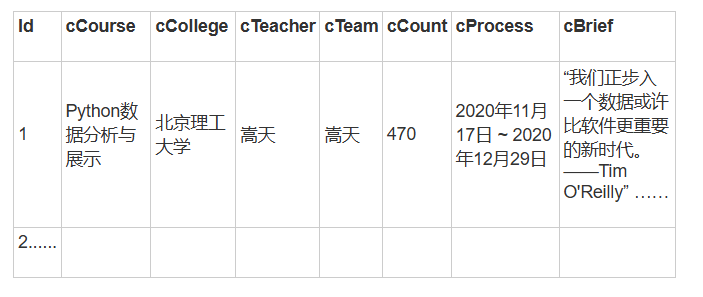
爬取mooc课程信息
🌱解析网页结构
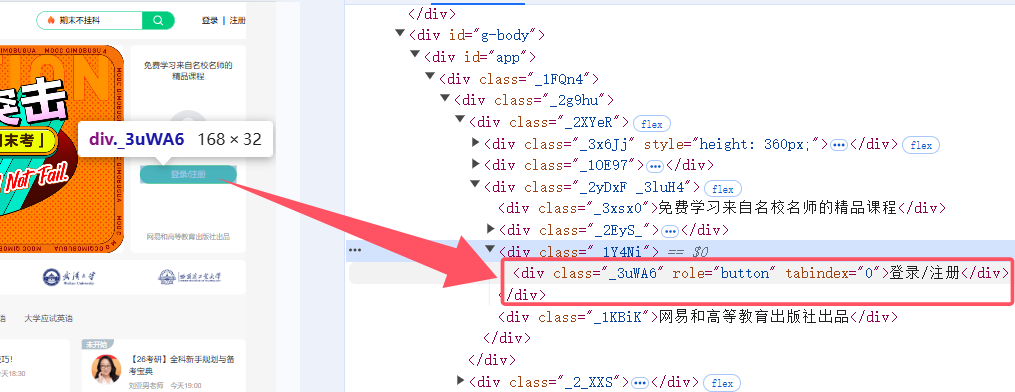
1.找到登录按钮,以便完成模拟登录
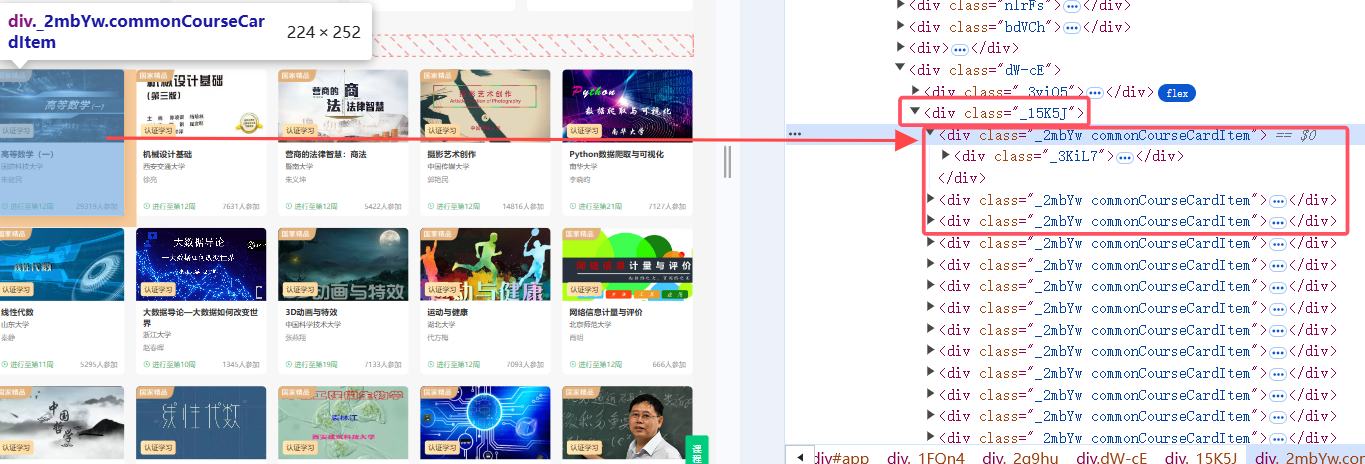
2.课程列表结构
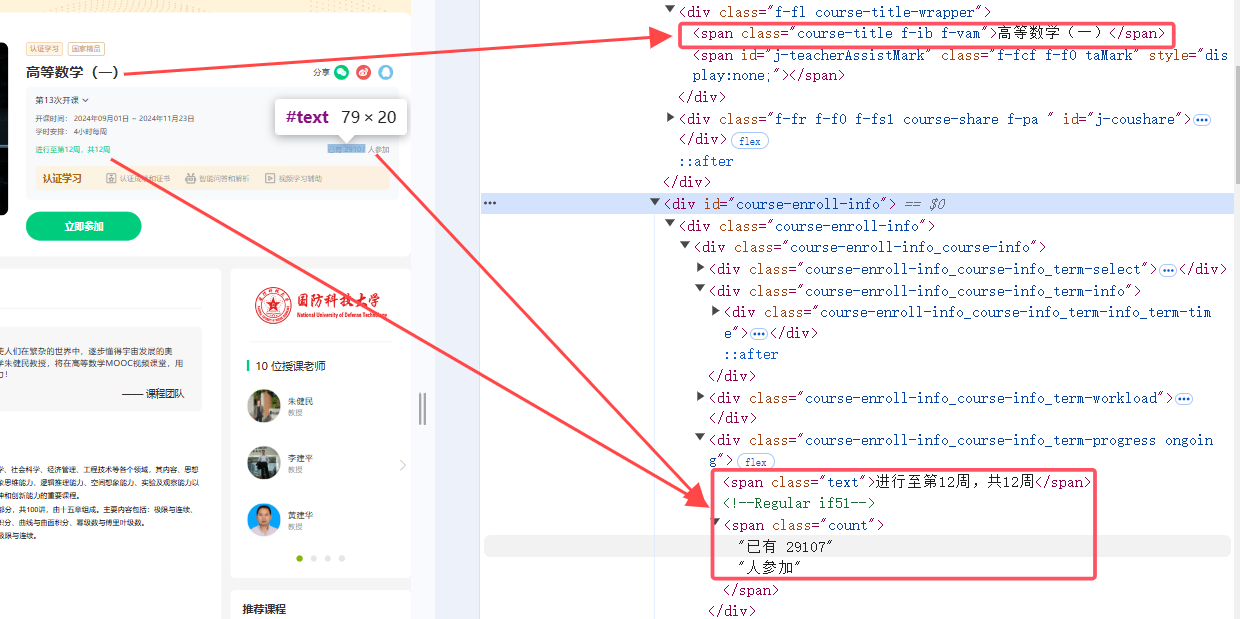
3.课程详情页信息结构
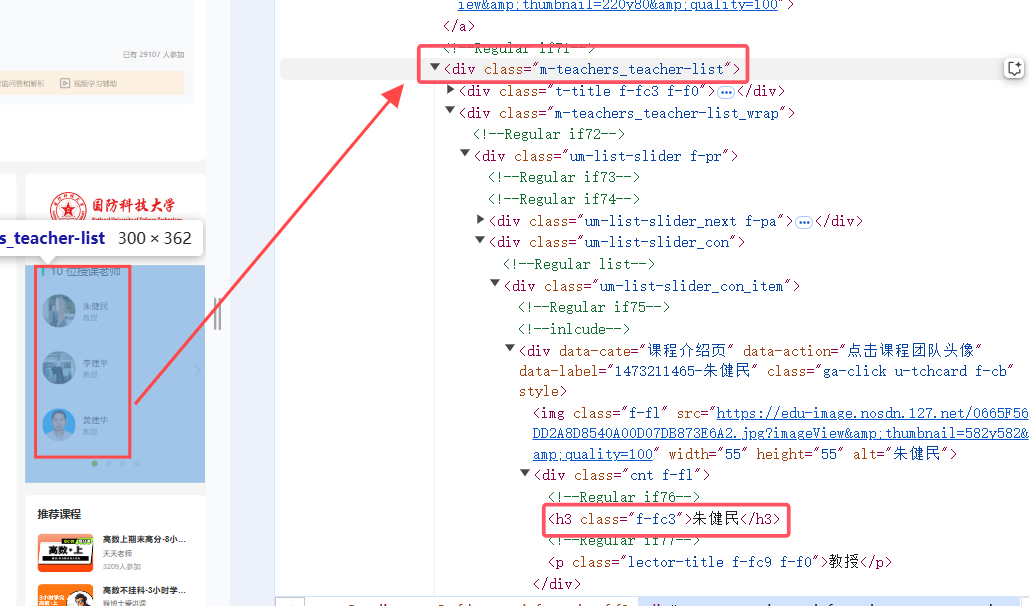
根据这些,设计XPATH爬取语句
🌱实现思路
1. 配置与初始化
- 引入必要的模块如Selenium,pymysql等。
- 数据库连接配置:定义数据库连接参数,如主机、用户、密码、数据库名称和字符集;创建一个函数 init_db 来初始化并返回数据库连接对象,同时处理连接错误。
- 配置浏览器选项。
2. 用户登录
- 导航至登录页面,使用 WebDriver 打开
https://www.icourse163.org/。 - 模拟点击登录按钮。
- 扫码登录,并设置足够的等待时间(例如 30 秒)以完成扫码过程。
3. 爬取所有课程
- 导航至主课程页面,确保已登录状态。
- 等待课程元素加载。
- 提取课程元素,使用正确的 XPath 选择器定位并提取所有课程元素,存储在一个列表中。
4. 遍历并处理每门课程
- 初始化数据库连接。
- 遍历课程列表。
- 等待新窗口/标签页打开,并切换到该窗口,以便操作课程详情页。
- 调用
scrape_course_details函数,从课程详情页中提取所需的信息,如课程名称、教师信息、学院、学生人数、课程进度、简介等。 - 将提取的数据通过
insert_data函数插入到数据库中。 - 关闭当前详情页窗口,切换回主课程页面窗口,准备处理下一个课程。
5. 数据库操作
- 使用
init_db函数建立与 MySQL 数据库的连接。 - 使用
insert_data函数,将爬取到的课程信息插入到数据库中的courses表。
🎨主要代码
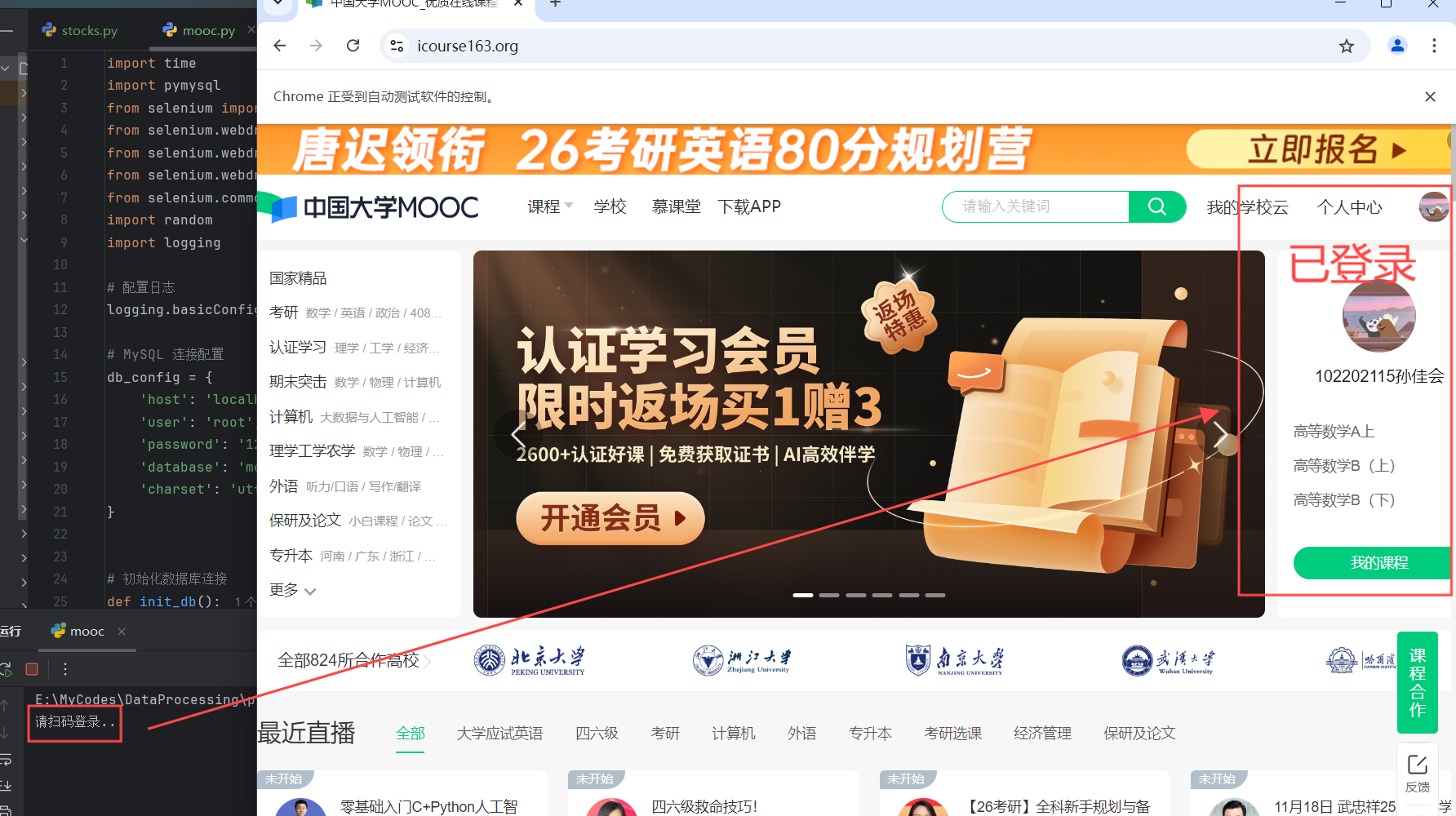
login_icourse163函数通过 Selenium 自动化工具,模拟用户在 icourse163.org 网站上的扫码登录过程,包括打开网站、定位并点击登录按钮、提示用户扫码并等待一段时间。
# 模拟用户扫码登录
def login_icourse163(driver):
try:
driver.get("https://www.icourse163.org/")
# 等待登录/注册按钮可点击
login_button = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="_3uWA6" and text()="登录/注册"]'))
)
login_button.click()
# 等待扫码登录,这里可以通过time.sleep调整扫码等待时间
print("请扫码登录...")
time.sleep(30) # 根据需要调整扫码时间
except Exception as e:
logging.error(f"登录过程中发生错误: {e}")
driver.quit()
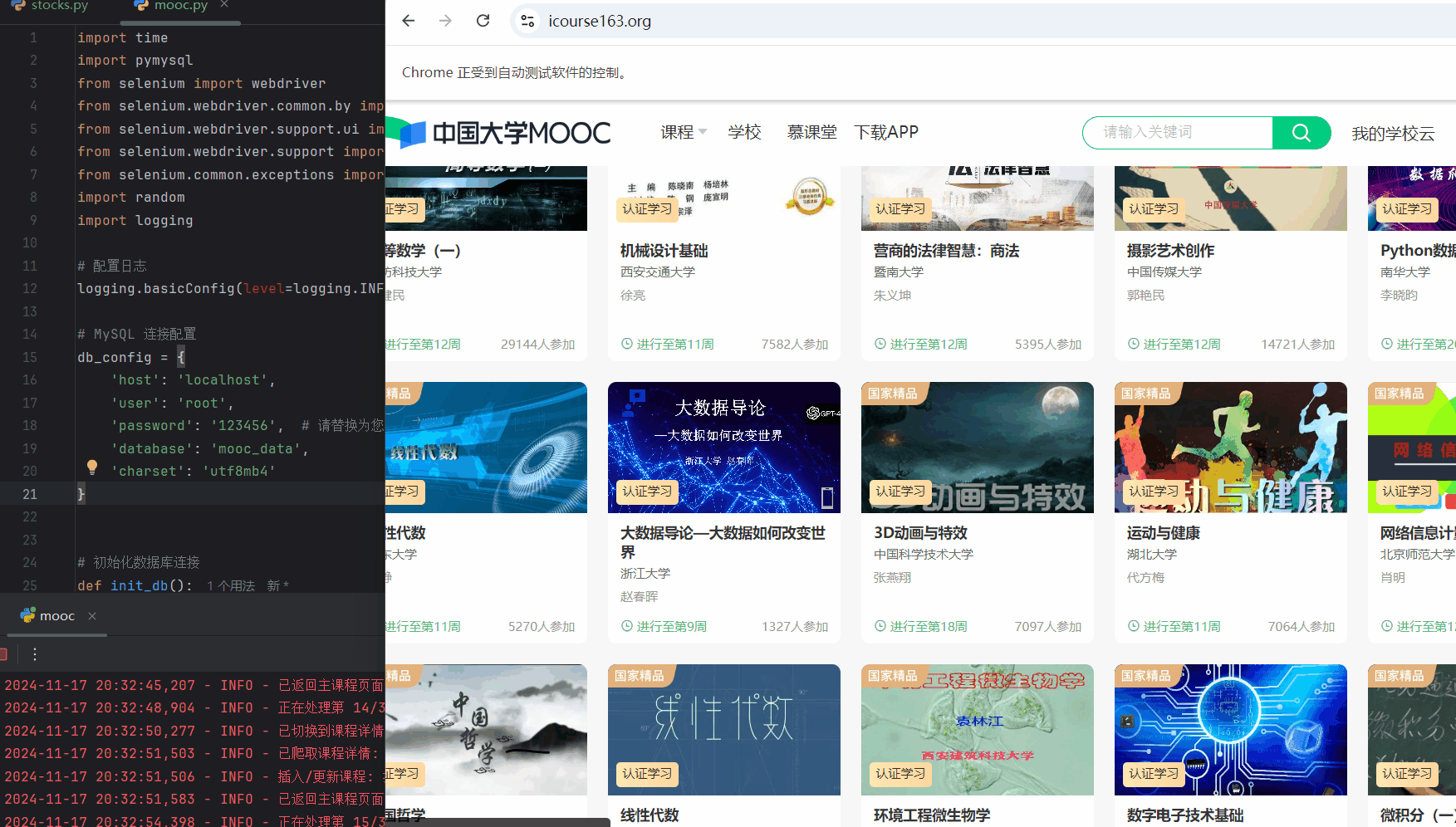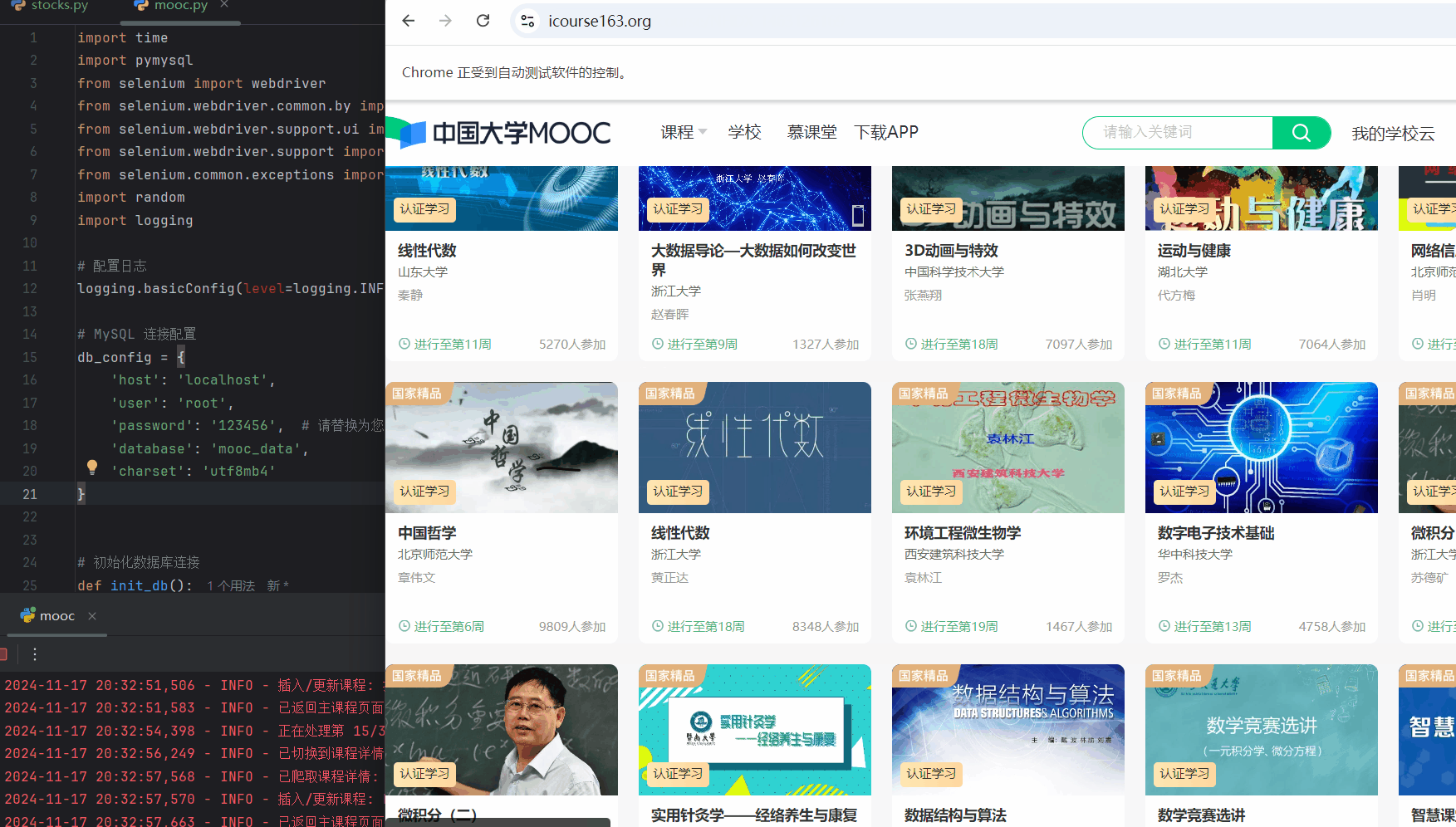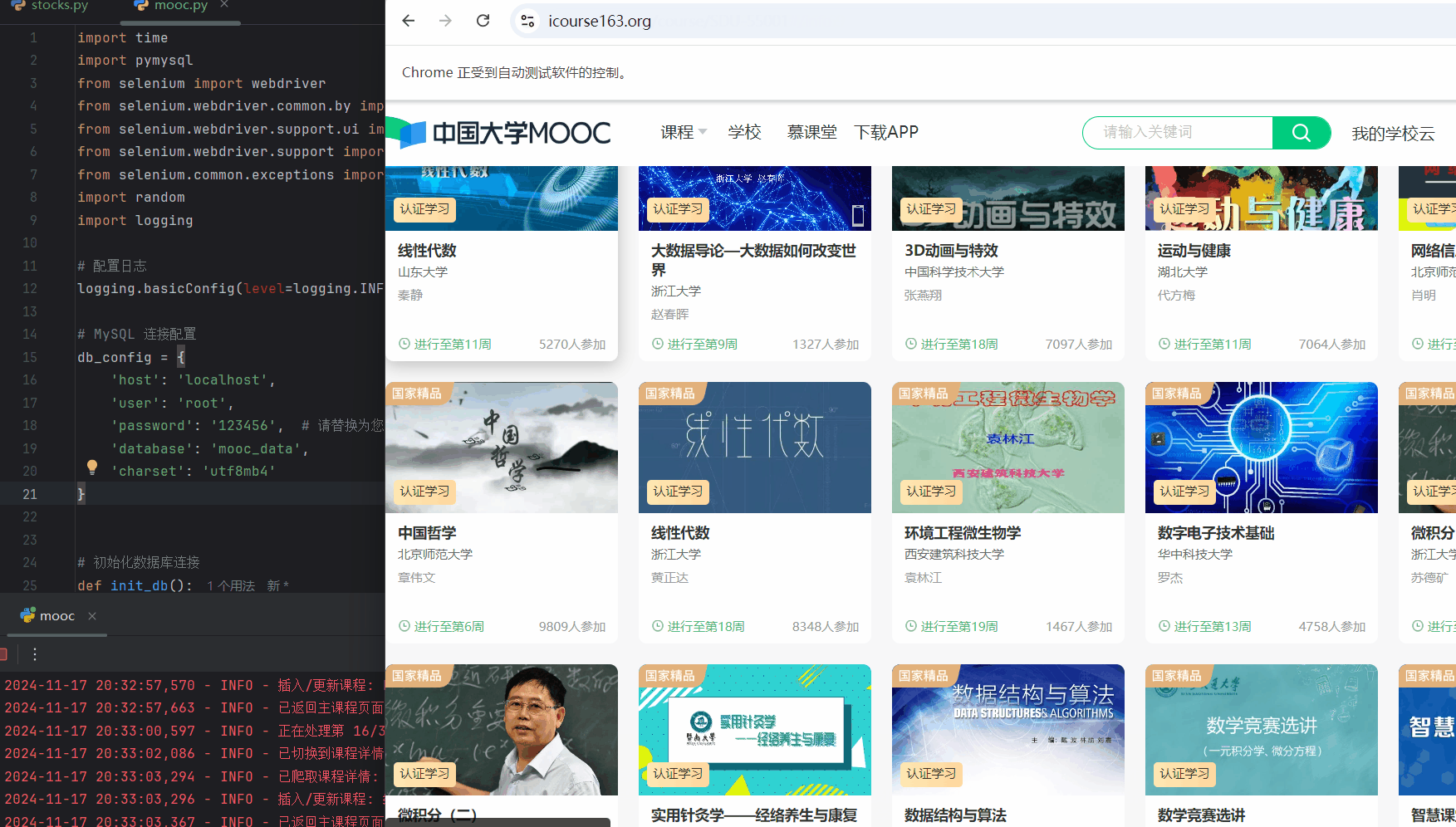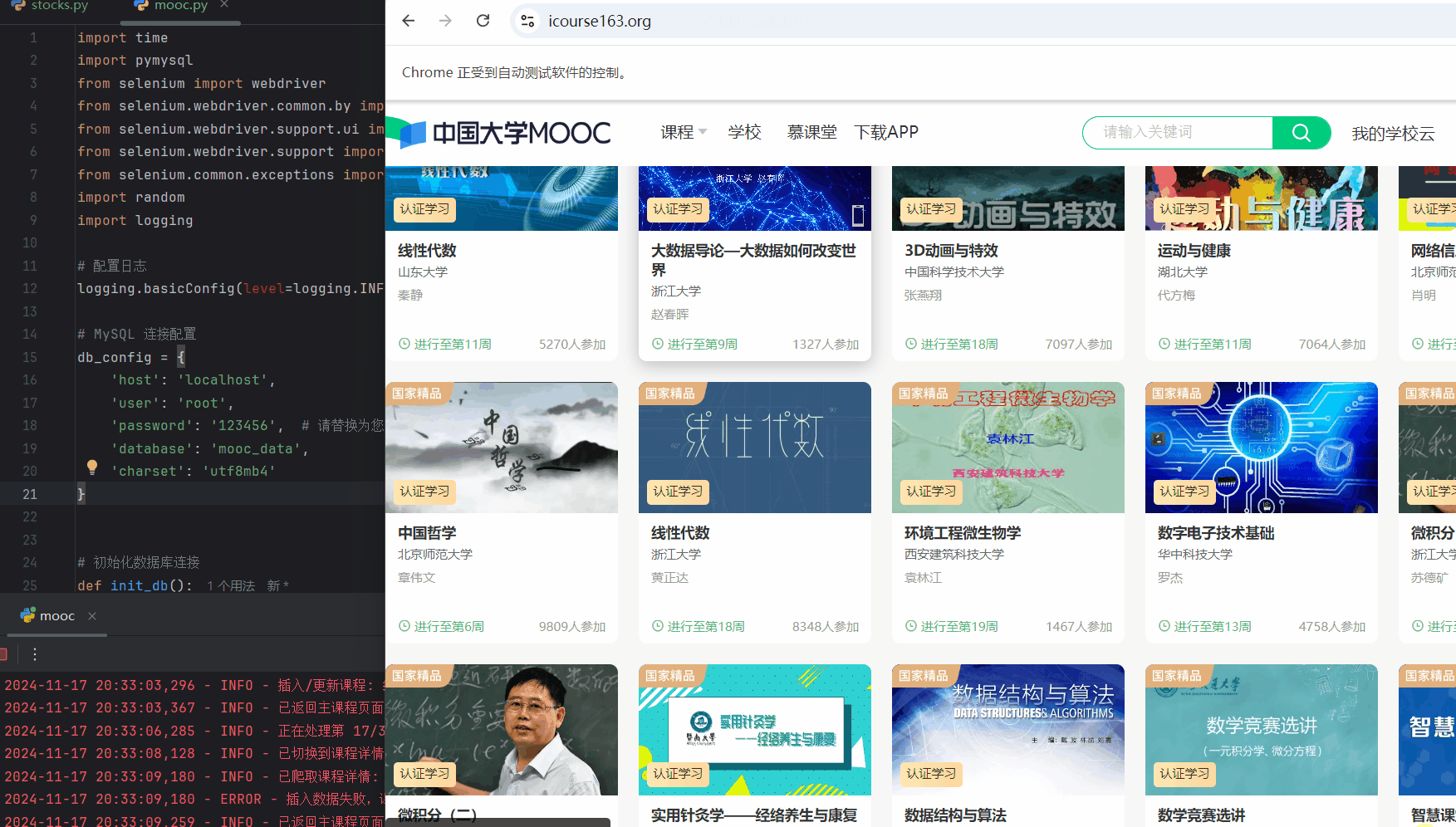
scrape_all_courses函数的主要目的是从 icourse163.org 的主页面上提取所有课程的元素,并返回这些课程的列表。
# 爬取所有课程
def scrape_all_courses(driver):
try:
driver.get("https://www.icourse163.org/")
logging.info("已导航到主课程页面。")
# 等待课程加载
WebDriverWait(driver, 20).until(
EC.visibility_of_element_located((By.XPATH, "//div[@class='_15K5J']"))
)
logging.info("课程已加载。")
# 获取所有课程元素
courses = driver.find_elements(By.XPATH, "//div[@class='_2mbYw commonCourseCardItem']")
logging.info(f"找到 {len(courses)} 门课程。")
return courses
except TimeoutException:
logging.error("加载课程时超时。")
return []
except Exception as e:
logging.error(f"爬取课程时发生错误: {e}")
return []
scrape_course_details函数根据网页结构使用 XPath 定位各个元素,提取课程名称、教师、学院、学生人数、课程进度、简介和团队等信息,从课程详情页中提取课程信息。
# 从课程详情页爬取课程信息
def scrape_course_details(driver):
try:
# 等待课程详情部分可见
WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.XPATH, "//div[@id='g-body']"))
)
# 提取课程信息
cCourse = driver.find_element(By.XPATH, "//span[@class='course-title f-ib f-vam']").text
cTeacher = driver.find_element(By.XPATH, "//div[@class='m-teachers_teacher-list']//h3[@class='f-fc3']").text
cCollege = driver.find_element(By.XPATH, "//div[@class='m-teachers']//img").get_attribute(
"alt")
cCount = driver.find_element(By.XPATH, "//span[@class='count']").text
cProcess = driver.find_element(By.XPATH, "//span[@class='text']").text
# 获取课程简介
cBrief = driver.find_element(By.XPATH, "//div[@class='course-heading-intro_intro']").text
# 获取课程团队(假设是单个元素,根据实际情况调整选择器)
cTeam = driver.find_element(By.XPATH, "//div[@class='t-title f-fc3 f-f0']").text
logging.info(f"已爬取课程详情: {cCourse}")
return (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
except NoSuchElementException as e:
logging.error(f"爬取过程中未找到元素: {e}")
return None
except Exception as e:
logging.error(f"爬取课程详情时发生错误: {e}")
return None
- 自动化地遍历所有课程,点击每个课程以获取详细信息,提取并存储这些信息到数据库中,同时通过随机延时和日志记录来模拟人类行为并确保过程的可追踪性和稳定性。
# 遍历每门课程并爬取详情
for index, course in enumerate(courses, start=1):
try:
logging.info(f"正在处理第 {index}/{len(courses)} 门课程。")
# 将课程滚动到可视区域并点击
driver.execute_script("arguments[0].scrollIntoView();", course)
random_sleep(1, 2)
course.click()
# 等待新窗口/标签页打开
WebDriverWait(driver, 10).until(EC.number_of_windows_to_be(2))
driver.switch_to.window(driver.window_handles[-1])
logging.info("已切换到课程详情页。")
# 爬取课程详情
course_data = scrape_course_details(driver)
if course_data:
insert_data(connection, course_data)
# 关闭详情页并返回主页面
driver.close()
driver.switch_to.window(driver.window_handles[0])
logging.info("已返回主课程页面。")
# 随机睡眠以模拟人类行为
random_sleep()
except Exception as e:
logging.error(f"处理课程时发生错误: {e}")
# 若发生错误,尝试关闭详情页并返回主页面
if len(driver.window_handles) > 1:
driver.close()
driver.switch_to.window(driver.window_handles[0])
logging.info("所有课程爬取完成。")
💡运行结果
运行过程中实现登录:
运行中爬取过程:
终端输出:
mysql数据库中内容:
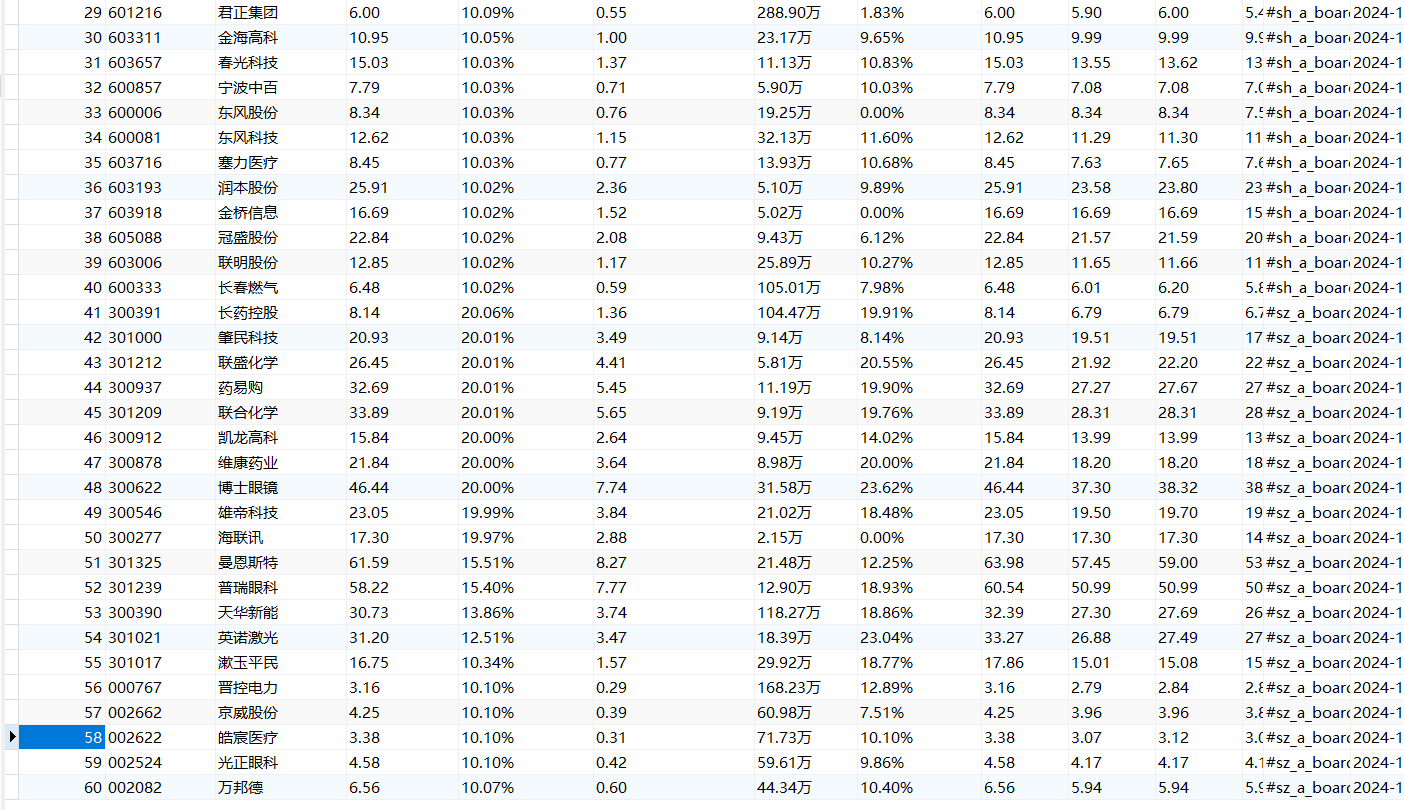
爬取到了所需课程信息。
遇到的问题及解决
登录流程的复杂性
困难
- 扫码登录:使用 Selenium 模拟用户扫码登录涉及等待用户手动操作,这增加了自动化的难度。
- 保持会话状态:确保登录后的会话状态在后续的页面导航中保持,避免因为会话丢失导致无法访问受保护的内容。
解决
- 等待用户扫码:在登录流程中使用固定的 time.sleep() 等待足够的时间(如 30 秒)让用户完成扫码操作。同时,添加日志记录提示用户扫码。
- 保持会话状态:确保在整个爬虫脚本中使用同一个 driver 实例,不要在登录后重新初始化 WebDriver。这样可以维持会话的持续性。
课程详情页与主页面之间的切换
困难
- 窗口管理复杂:点击课程后,课程详情页可能在新窗口或新标签页中打开,在多个窗口或标签页之间切换时,容易混淆窗口句柄,导致操作错误的窗口。
- 同步问题:新窗口打开后,课程详情页可能需要时间加载,若未正确等待,可能导致元素定位失败;关闭详情页后,需要确保切换回主页面窗口,避免 NoSuchWindowException。
- 元素引用失效:在窗口切换过程中,主页面上的课程元素引用可能失效,导致无法继续操作。
- 异常处理不足:未能正确关闭窗口或错误窗口切换。
解决
- 获取主窗口句柄,点击课程并获取新窗口句柄。
- 由于窗口切换可能导致主页面上的元素引用失效,建议在每次循环开始前,重新获取课程元素列表,或者使用索引来定位课程。
- 全面异常处理,确保窗口切换的稳定性,确保无论发生何种错误,都能正确关闭详情页窗口并切换回主窗口,避免后续操作受阻。
心得体会
-
在开始编写爬虫之前,需要深入分析目标网站的页面结构和动态加载机制。通过使用浏览器的开发者工具,准确定位需要抓取的元素,并设计出有效的 XPath选择器。
-
在项目中不仅使用了 Selenium 的基本功能如元素定位和点击操作,还深入学习了显式等待(WebDriverWait)和预期条件(ExpectedConditions),以确保页面元素完全加载后再进行操作。
-
通过记录主窗口的句柄,封装窗口切换和关闭的逻辑,我成功实现了在主页面与详情页之间的平稳切换。
通过这次实践,我对 Selenium 和网页爬虫有了更深入的理解,并积累了宝贵的实战经验。
作业③
要求:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
任务一:开通MapReduce服务
实时分析开发实战:
任务一:Python脚本生成测试数据
任务二:配置Kafka
任务三: 安装Flume客户端
任务四:配置Flume采集数据
输出信息:
实验关键步骤或结果截图。
Flume日志采集
🌱环境搭建
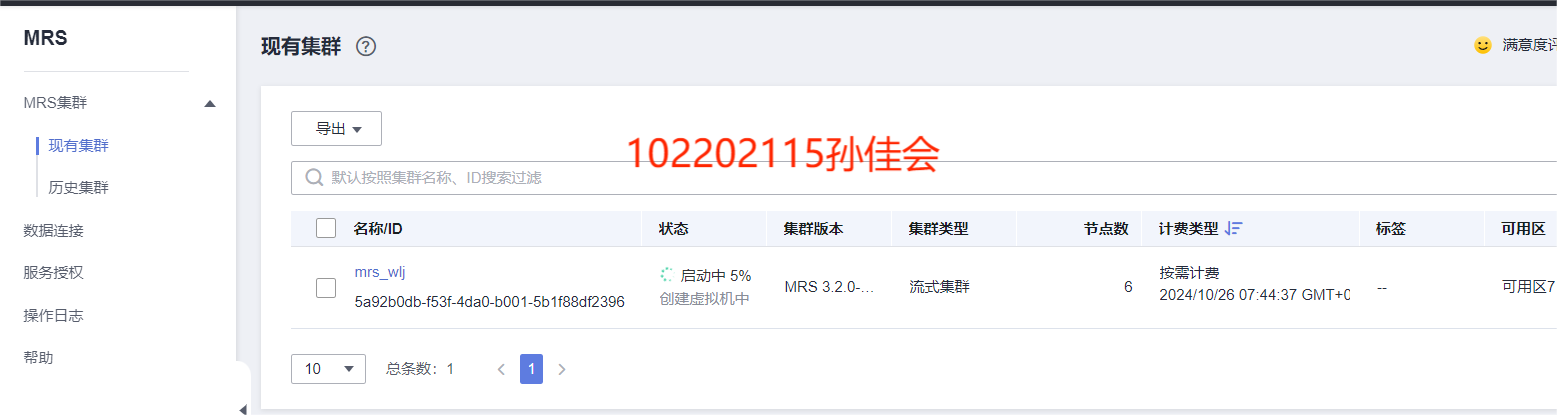
开通MapReduce服务
按要求配置购买MRS集群:
🎨实时分析开发实战
1.Python脚本生成测试数据
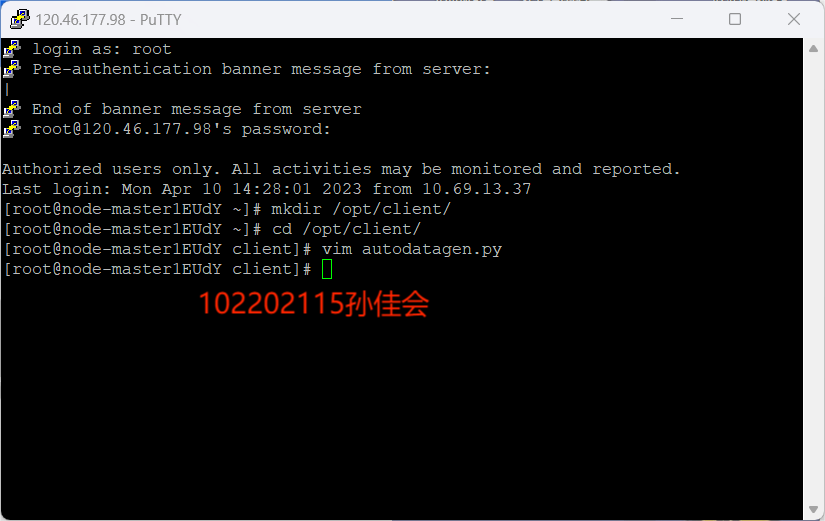
- 登录MRS的master节点服务器:输入用户名和密码进行登录
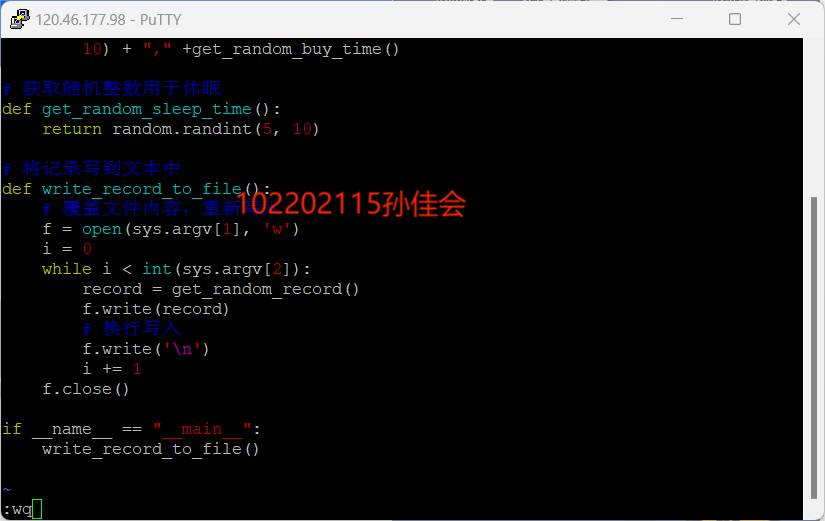
- 编写Python脚本
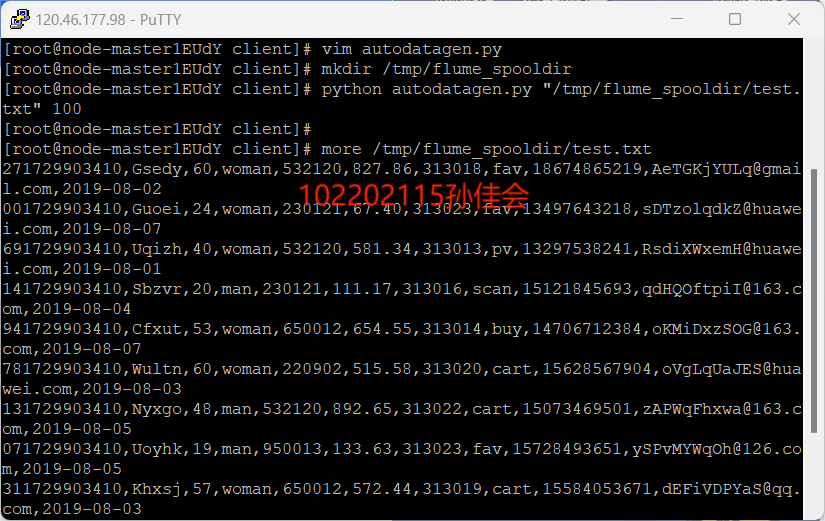
- 创建存放测试数据的目录
- 执行脚本测试:执行命令,并查看生成的数据
2.配置Kafka
- 进入MRS Manager集群管理。
- 下载Kafka客户端。
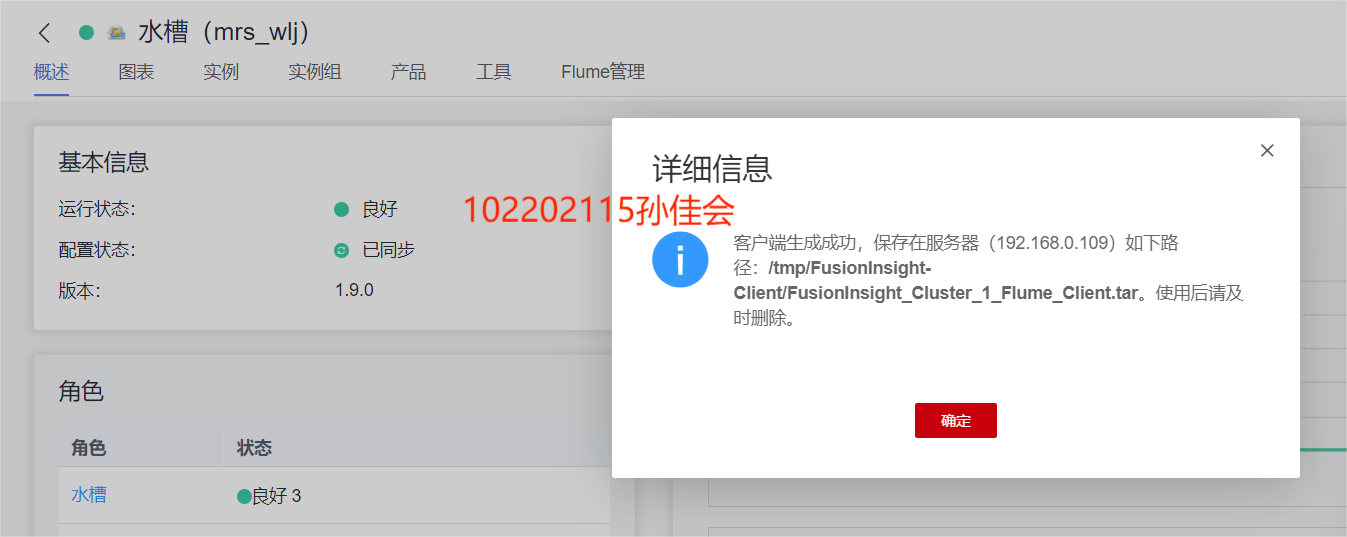
-
校验下载的客户端文件包
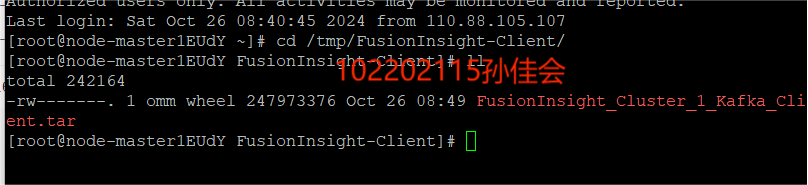
执行命令,解压,检验文件包
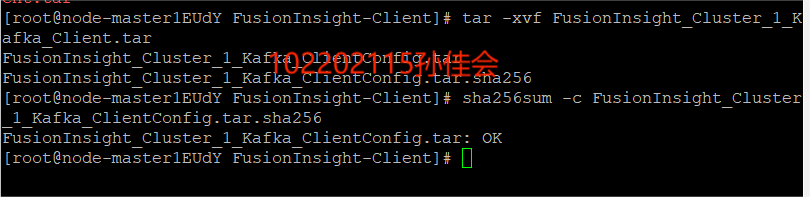
-
安装Kafka运行环境
解压“MRS_Flume_ClientConfig.tar”文件:
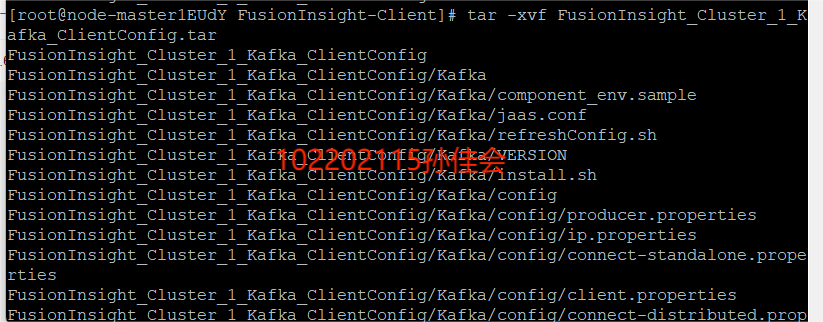
查看解压后的文件:
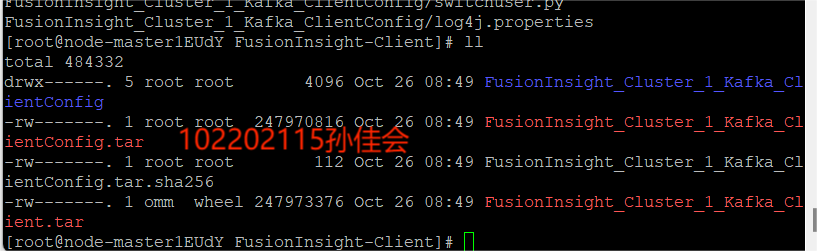
安装客户端运行环境:

执行命令配置环境变量:

-
安装Kafka客户端
安装Kafka到目录“/opt/KafkaClient”
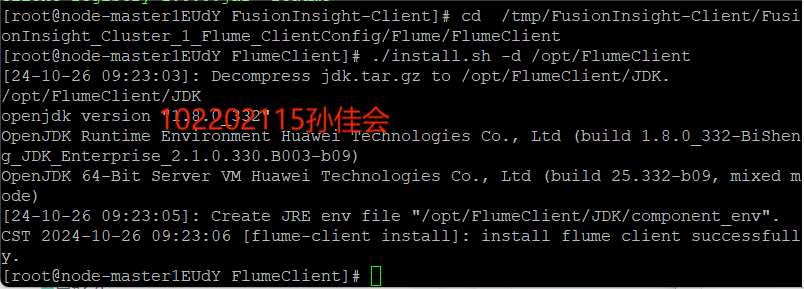
-
设置环境变量
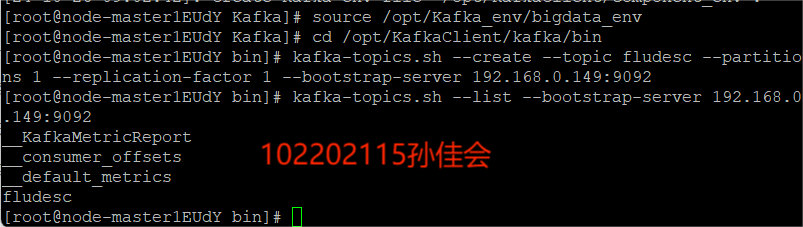
-
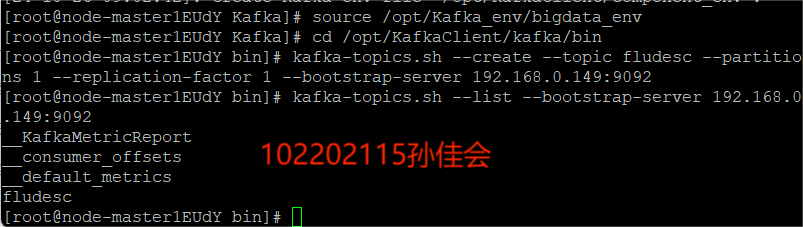
在kafka中创建topic
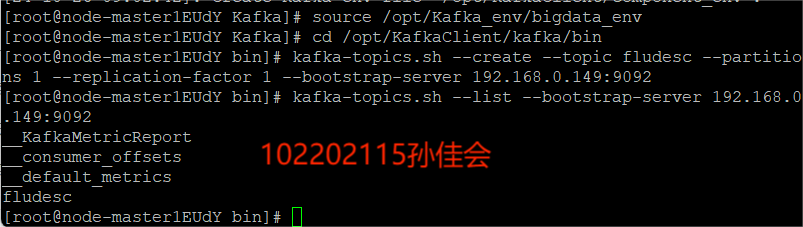
-
查看topic信息
3. 安装Flume客户端
-
进入MRS Manager集群管理
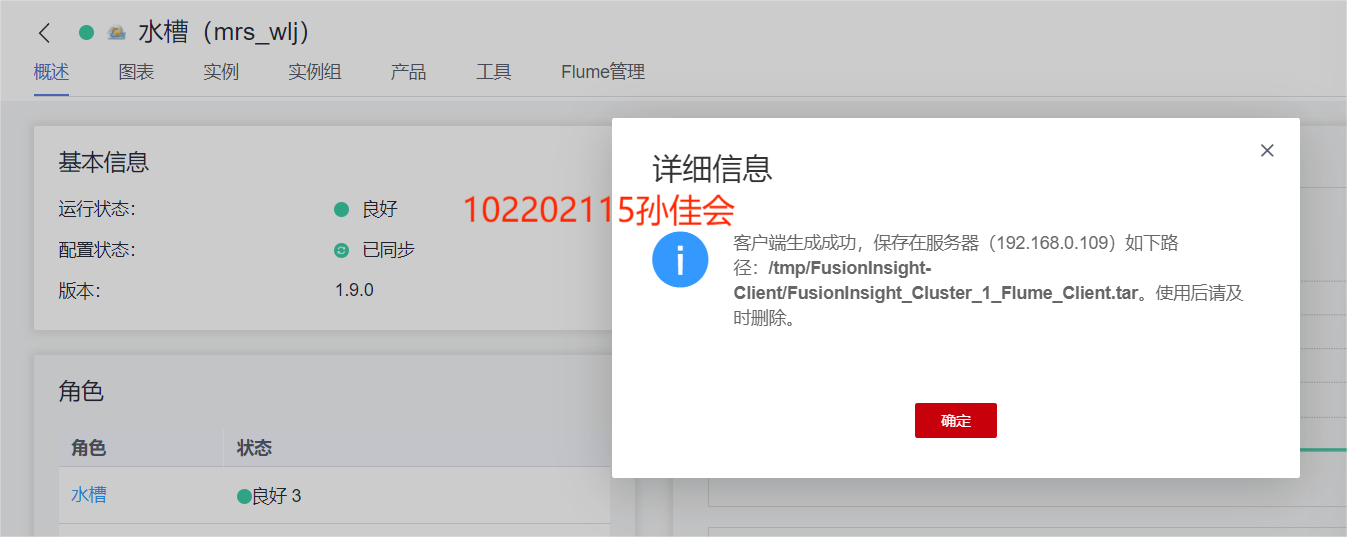
-
下载Flume客户端。
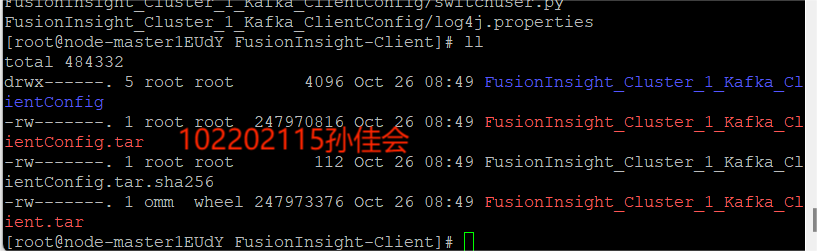
-
校验下载的客户端文件包。
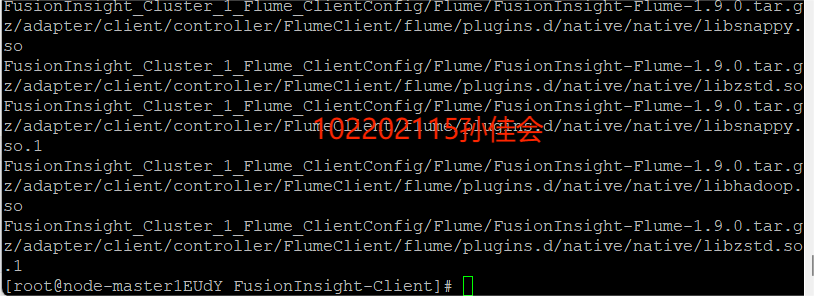
-
安装Flume运行环境。
-
安装Flume客户端。
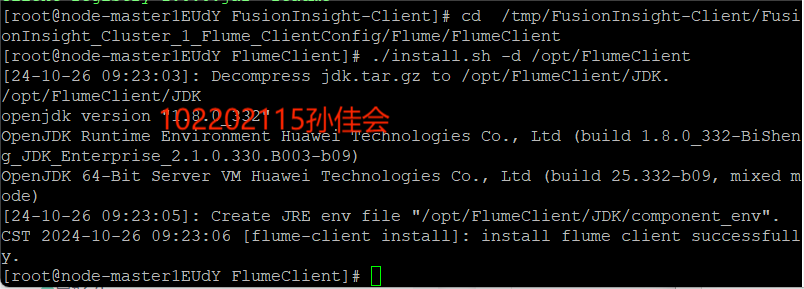
-
重启Flume服务
4. 配置Flume采集数据
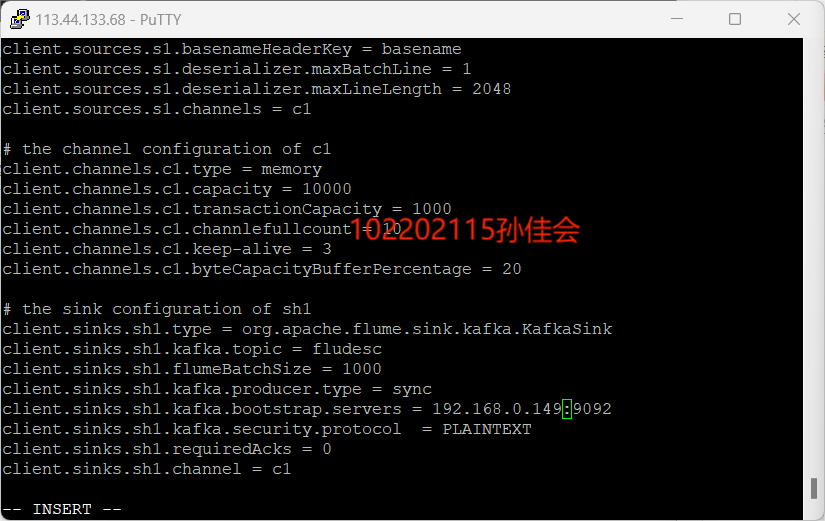
-
修改配置文件
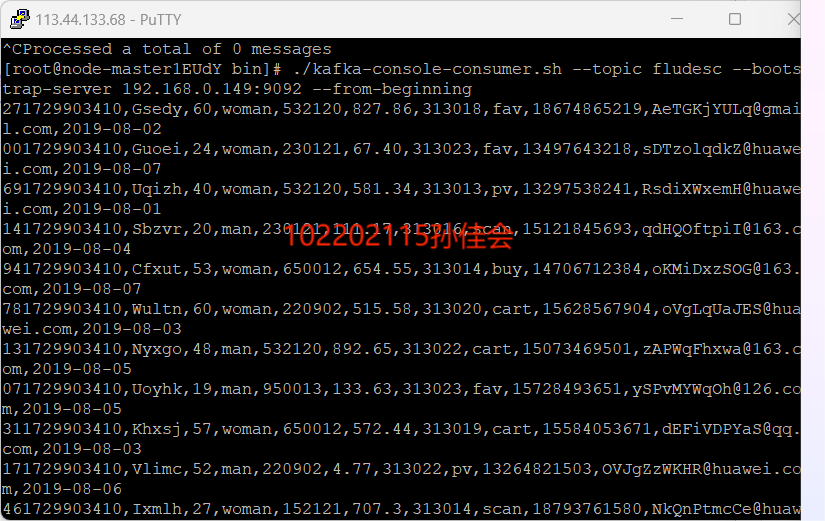
-
创建消费者消费kafka中的数据
心得体会
本次实验中,我使用Python脚本模拟了生产商品的实时销售数据,然后通过Flume和Kafka完成数据的采集和传输。这一过程中,我学会了如何通过流处理框架对海量数据进行快速分析和处理,并及时将分析结果存入RDS数据库。

