Lecture 4: Model-Free Prediction
1.Monte-Carlo Reinforcement Learning
a)MC方法直接从经历中的episodes中学习
b)MC方法是无模型的,
c)从完整的episodes中学习:而不是走一步学学一步(bootstrapping)
d)注意:只能将MC方法应用到episodic MDPs,而且所有的episodes必须终止。
2.Temporal-Di↵erence Learning
a)TD方法直接从经历中的episodes中学习
b)MC方法是无模型的
c) 从不完整的episodes中学习,by bootstrapping
d) TD从一个猜测中更新猜测
3.TD能在获知最终结果前学习
a) TD能在每步中在线学习
b) MC必须等到一个episode结束才能获知最终结果
TD能够在没有最终输出的过程中学习
a) TD能够从不完整的雪猎中学习
b) MC只能从完整的序列中学习
c) TD 在连续的环境中工作
d)MC只能在有终结序列的环境中工作
4.  是
是 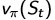 的无偏估计,
的无偏估计,


5.TD利用了Markov属性,通常在Markov环境中更为有效
MC没有利用Markov属性,通常在非Markov环境中更加有效
6. TD( λ ) 与MC都只能用于完整的episodes

 浙公网安备 33010602011771号
浙公网安备 33010602011771号