磁盘相关知识点入门
Ⅰ、磁盘的访问模式
磁盘性能和磁盘的访问模式有关
-
Sequential access
![]()
-
Random access
![]()
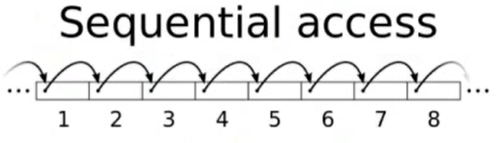
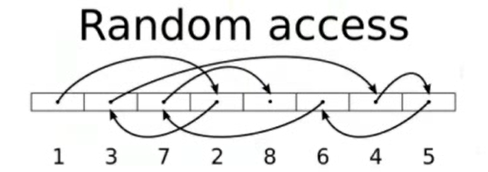
上面说的顺序和随机是逻辑上的,大多时候做不到完全顺序
数据库不是连续块的申请空间,是一次申请固定块大小的空间,在这一个块里面的数据是连续的
Ⅱ、HDD VS SSD
随机访问的性能叫IOPS,顺序访问的性能叫吞吐率
2.1 简单了解HDD
- 机械磁盘,通过磁头旋转定位,单块盘一般100IOPS
- 数据库的优化都是根据机械磁盘特性,随机转顺序,通过磁头旋转进行数据定位
- 常见转速,笔记本5400r/min,台式机7200r/min,服务器硬盘1w/min,1.5w/min
- 顺序访问性能较好,100M/s/~200M/s,这叫磁盘吞吐率,也叫带宽,可以通过做raid来提升磁盘带宽,可以做到一两个G
- 随机访问性能较差,需要磁头旋转定位,IOPS较低
为什么数据库比较多的是随机访问?
B+ tree索引定位数据是比较随机的,所以数据库最看重的就是随机IO,也就是IOPS,顺序的话通常就是扫描了,两张表做join的话比的就是顺序的性能,MySQL通常用在大并发,小事务的OLTP场景
知道转速,对应的IOPS也出来了
IOPS=转速/60
带宽怎么转换为IOPS
每做一次io操作,io的大小是不一定的,比如4k的操作,通常厂商都给的数据都是4k大小的io,注意,MySQL中每个IO的大小是16k,即每个页的大小,所以和厂商给的性能数据相比会有所下降
48M的宽带算IOPS就是,1M/4k*48=12288
如何提升HDD的IOPS性能
-
做raid
- 功耗非常高
-
通过购买共享存储
- 价格昂贵
- 共享存储,做高可用很方便,但是单点故障太坑爹,就像坐飞机,一般没问题,出了问题基本上就是死
然而提升都是非常有限的
tips:
通常来说数据库做raid10,性能和可靠性都要有保障
2.2 SSD
- 固态硬盘,无磁头,纯电设备,控制器和闪存组成。单块盘7~8wIOPS
- 读写速度非对称,一般来说写比读慢一半,高端ssd是对称的,机械盘也是对称的
- 性能下降,以前的ssd用一段时间性能会急剧下降,现在基本解决了,强烈推荐英特尔的盘
- 设备短命,性能抖动的问题现在也不用担心
- 用MySQL一定要用SSD
SSD与数据库优化
1、磁盘调度算法设置为deadline或者noop,在ssd上,这个调整性能至少提升百分之七十,甚至多倍,现在CentOS7默认磁盘调度算法已经是deadline了而不是cfq
cat /sys/block/vda/queue/scheduler
echo deadline > /sys/block/vda/queue/scheduler
上面这个可以作一个模板,规定,HDD也因该这么设置,只是性能提升没这么大
2、InnoDB参数调整
InnoDB存储引擎参数设置
innodb_flush_neighbors = 0 -- 默认1,平缓刷新的,默认只刷脏页,不会将脏页所在的整个区刷新,把这个设为0,重做日志大小足够大,数据库测试时性能比较平稳,还有一定的提升
innodb_log_file_size = 4G -- 默认128M,高端设备设置8G和16G都不为过,MySQL5.5最大只能设1.9G,无限接近于2G
innodb_io_capacity 设置为存储性能的一半
修改之后重启,等待时间比较长,是数据库在做扩展
上面两个配置不对性能抖动比较厉害,设置后性能平稳且提升百分之15
3、SSD的选择——PCIE or SATA/SAS?
SATA/SAS与PCIE的性能差距逐渐减小,PCIE快非常多,甚至达到50w,100wIOPS,没什么上限
PCIE的性能很少有应用可以完全使用,优先选择SATA/SAS接口的SSD
数据库的瓶颈已经不在磁盘上了
SSD品牌推荐:Intel、FusinIO、宝存
Ⅲ、磁盘调度算法介绍
3.1 CFQ
- CFQ把I/O请求按照进程分别放入进程对应的队列中,所以A进程和B进程发出的I/O请求会在两个队列中。而各个队列内部仍然采用 合并和排序 的方法,区别仅在于,每一个提交I/O请求的进程都有自己的I/O队列
- CFQ的“公平”是针对进程而言的,它以时间片算法为前提,轮转调度队列,默认从当前队列中取4个请求处理,然后处理下一个队列的4个请求。这样就可以确保每个进程享有的I/O资源是均衡的
- CFQ的缺点是先来的IO请求不一定能被及时满足,可能出现饥饿的情况
3.2 Deadline
- 同CFQ一样,除了维护一个拥有合并和排序功能的请求队列以外,还额外维护了两个队列,分别是读请求队列和写请求队列 ,它们都是带有超时的FIFO队列,当新来一个I/O请求时,会被同时插入普通队列和读/写队列,然后处理普通队列中的请求,当调度器发现读/写请求队列中的请求超时的时候,会优先处理这些请求,保证尽可能不产生请求饥饿
- 在DeadLine算法中,每个I/O请求都有一个超时时间,默认读请求是500ms,写请求是5s
3.3 Noop
- Noop做的事情非常简单,它不会对I/O请求排序也不会进行任何其它优化(除了合并),Noop除了对请求合并以外,不再进行任何处理,直接以类似FIFO的顺序提交I/O请求
- Noop面向的不是普通的块设备,而是随机访问设备(例如SSD),对于这种设备,不存在传统的寻道时间,那么就没有必要去做那些多余的为了减少寻道时间而采取的事情了
Ⅳ、存储结构对应关系
+-------------+-------------+-------------+
Database | 16K | 16K | 16K |
+------+------+-------------+-------------+
|
+------------------------------------------------------------------------+
|
+------+
|
+------+------v------+------+
Filesystem | 4K | 4K | 4K | 4K |
+---+--+------+------+------+
|
+------------------------------------------------------------------------+
|
+--+
|
v
+------+------+ +------+
Disk | 512B | 512B | ... ... | 512B |
+------+------+ +------+
SSD扇区的大小一般为4K或者8K,但是为了兼容HDD,SSD通过Flash Translation Layer(FTL)的方式转换成512B
4.1 一个参数——innodb_flush_method
- fwrite:把数据写入文件系统层(Filesystem)(可能有cache),并不能保证写入Disk
- fsync:保证把数据写入到Disk(数据落盘)
- O_DIRECT:系统直接将数据写入磁盘,跳过文件系统的缓存,等同于使用裸设备的效果
+-------------------+ +-------------------+ +-------------------+
| | fwrite | | fsync | |
| Buffer Pool +---------------> Filesystem Cache +--------------> Disk |
| | | | | |
+--------+----------+ +-------------------+ +---------+---------+
| ^
| |
| innodb_flush_method = O_DIRECT |
+-----------------------------------------------------------------------+
只通过fwrite写入数据特别快(因为有缓存),但随后调用fsync就会很慢,这个速度取决于磁盘的 IOPS
如果不手工执行fysnc,当Filesystem的cache小于10%时,操作系统才会将数据刷入磁盘,所以可能存在数据丢失的风险,比如掉电
4.2 写数据的过程
OS pagecache(操作系统层的)
filesystem 一个块一个块,每个块大小4k
DISK 一个4k由8个扇区(sector)组成,一个sector大小512字节
fwrite/fread,最底层的system core中用fopen打开文件:f=fopen('ibdata',wb)
打开之后对应一个文件句柄f,对文件句柄f操作:fwrite(f,offset,data,len)
offset就是偏移量,data是写入的数据,len是字节数
数据库都是16k一个块,对于数据库来说,它的offset=16k*N
fwrite(f,0,xxx,16384);
fwrite(f,16384,xxx,16384);
写就是覆盖操作,如果追加在最后就是占用空间,不会有碎片,数据库里会先申请空间全部填0,对于数据库来说,offset大小肯定和块大小对齐,offset必然是块大小的倍数
仅仅调用fwrite函数,表示数据只写入到了pagecache(操作系统缓存中),并没落地到磁盘,这时候服务器挂了,就有问题了,所以还要调用一个fsync函数刷新句柄,fsync表示直接刷新到磁盘
只通过fwrite写入数据特别快(因为有缓存),但随后调用fsync就会很慢,这个速度取决于磁盘的IOPS,如果不手工执行fysnc,当Filesystem的cache小于10%时,操作系统才会将数据刷入磁盘,所以可能存在数据丢失的风险,比如掉电
4.3 写的比较乱,做个小结
首先明确一点,不管走不走os缓存,对于数据库来说fsync肯定是要一直刷的
fsync非1的话,性能是会好一些,但是性能会有抖动(隔段时间刷新,或者设为0的时候不主动fsync,os会控制这个刷新频率),反正是不用嘛
linux内核2.4版本开始,api函数提供了一个叫o_direct函数,让fwrite直接写到磁盘而不经过pagecache,就是fopen的时候用o_direct参数
这种情况比走os缓存性能稍微要有点差别,但是为了保证数据库的安全我们肯定还是选择直接刷到盘上,而且这个走os缓存性能好的一个原因是用了额外的内存,我们可以把这部分内存分配给buffer pool
其实,如果不直接刷盘,对于数据库来说多做了一次额外的缓存,bp+pagecahe,完全没必要
综上所述:
innodb_flush_method = O_DIRECT
如果没这个参数,一开始MySQL跑出来性能非常好,但是这肯定是不对的
tips:
哪些写入是o_direct,哪些是pagecache
- 数据文件----o_direct
- 日志文件----pagecache,fsync,一个日志文件可能很大,只有一个事务完全提交才fsync一次,不用每次写都fsync
4.4 另一个参数——innodb_io_capacity
数据库每秒写入能用到的IOPS是多少
调整这个值,先观察线上业务数据库IOPS比例,然后测试用--file-rw-ratio 测出这个IOPS,通常来说设置为整个IOPS的一半
有人说互联网业务数据库读写比是10:1,所以这个参数设置为IOPS的十分之一,然而并不是,我们说的数据库的读写比例,是指数据库内部是10:1,很多操作被cache起来了,真实的发生在磁盘上的大多数读写比例是1:1,甚至很多场景写比读还多
现在写设2w,读用2w,单块ssd就能达到了,设置不好就是花钱买冤枉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号