堆表与索引组织表
Ⅰ、堆表
数据存放在数据里面,索引存放在索引里
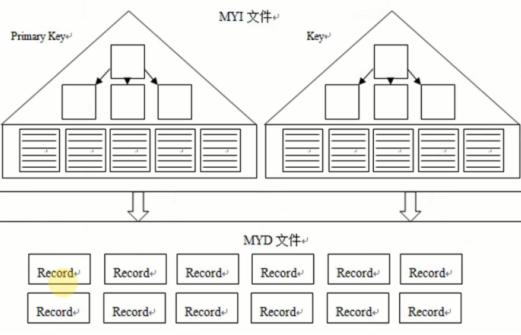
- 堆就是无序数据的集合,索引就是将数据变得有序,在索引中键值有序,数据还是无序的
- 堆表中,主键索引和普通索引一样的,叶子节点存放的是指向堆表中数据的指针(可以是一个页编号加偏移量),指向物理地址,没有回表的说法
- 堆表中,主键和普通索引基本上没区别,和非空的唯一索引没区别
myisam就是用的这个堆表的存储方式,oracle支持堆表,pg只支持堆表
Ⅱ、索引组织表
我们现在都玩innodb,所以堆表一带而过,重点关注索引组织表
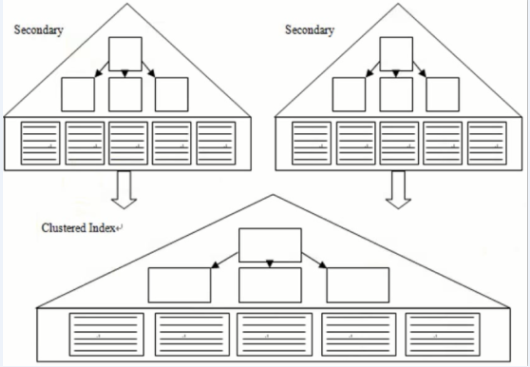
- 对于主键的索引,页子节点存放了一整行所有数据,其他索引称为辅助索引(二级索引),它的页子节点只是存放了键值和主键值
- 主键包含了一张表的所有数据,因为主键索引的页子节点中保存了每一行的完整记录,包括所有列。如果没有主键,MySQL会自动帮你加一个主键,但是对用户不可见
- innodb中数据存放在聚集索引中,换言之,按照主键的方式来组织数据的
- 其他索引(唯一索引,普通索引)的页子节点存放该索引列的键值和主键值
- 不管是什么索引非页子节点存放的存放的就是键值和指针,不存数据,这个指针在innodb中是6个bit,键值就看数据大小了
Ⅲ、两个重点问题
3.1、一个表A,主键值8个字节,每条记录300个字节,每个page16k,求这张表B+ tree高度为1 能存放多少记录,2呢? 3?
首先,一个页能存放16k/300个记录
- h为1,即root page 就是 leaf节点,就是大约五十条记录
- h为2,每个页还是不变的大约50条记录,就看页的上层扇出一共最多能有多少指针,非页子节点存放的就是指针和主键值,所以16k/(8+6) 差不多是1000,所以是50*1000条记录
- h为3,上面有两层非页节点,所以50 * 1000 * 1000
也就是说5000w的记录中找一个主键,只要找三个页,一亿和五百亿都是找四次,所以表变大,查询速度不会有变化,最差的hdd盘,一秒钟能查100次,实际生产中,B+ tree 高度4层差不多了,5层很少,高度越低性能越好
DML操作,先找到页,把这个页读到内存中,然后再去操作,只要你内存够大,页全放内存中,快的很
B+ tree的好处:查某个范围内,或者某几条数据,或者根据主键来查,很快,但是要把几千万数据查一下还要join那肯定慢了,当然也可以做定型、做hash join
缺点:插入比较慢
3.2、为什么主键查询比二级索引查询来的快
主键索引里面包含了每一行完整的数据,只要找到那个主键就是找到那个记录,二级索引,如果查询的列不是索引列,走那个列的索引找到后还要去根据索引里保存的主键去找查询列的内容,这里多了一步,这种查找叫书签查找或者回表,如果一个高度为3的树,本来查只要查三个页,走二级索引就要查六个页
a b c 三个列,a是主键,b是普通索引
select c from tb;
如果走b列的普通索引,会先找到对应的a,再通过a找到对应的c
①select c where b=?
②select c where a = ?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号