MVCC&PURGE&分布式事务
Ⅰ、MVCC介绍
consistent non-locking read,通过行多版本控制的方式读取当前执行时间点的记录
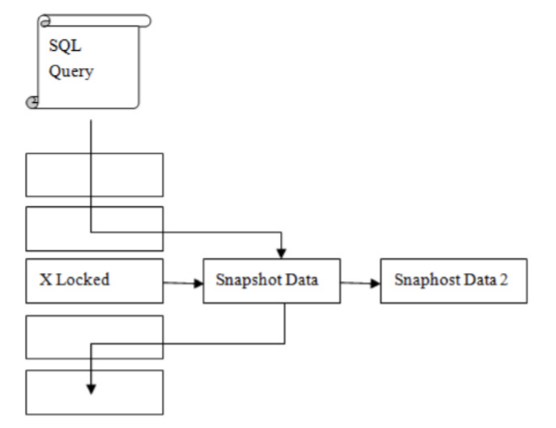
默认情况下innodb select没有任何锁,读到的记录在更新就通过undo读之前版本,serializable时候读会被阻塞,因为它默认加一个lock in share mode
--->like oracle
原理
undo && read_view
通过read_view判断一条记录是否可见,不可见(在更新被锁住)就通过undo回滚到之前版本,之前的版本再读trx_id,还不可见再回滚,rc只要回滚一个版本,rr可能要回滚很多版本,最大trx_id是持久化的,保存在共享表空间中
其实理解下就是事务在不在活跃列表中,在的话这个事务对记录做的动作就不可见需要找记录的前镜像(rc总是读最新的非锁定版本,rr总是读最老的非锁定版本,后续会有专门的文章说明)
举个栗子
session1:
(root@localhost) [test]> select * from t;
+------+
| a |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
(root@localhost) [test]> begin;
Query OK, 0 rows affected (0.00 sec)
(root@localhost) [test]> update t set a = a + 1 where a = 1;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
(root@localhost) [test]> select * from t;
+------+
| a |
+------+
| 2 |
+------+
1 row in set (0.00 sec)
session2:
(root@localhost) [test]> begin;
Query OK, 0 rows affected (0.00 sec)
(root@localhost) [test]> select * from t;
+------+
| a |
+------+
| 1 |
+------+
1 row in set (0.00 sec)
第一个会话开启事务更新记录,不提交,此时记录是被锁住的
新开一个会话去select 这条记录,并不会因为有锁而阻塞,读到的是原来的记录
此时commit之后,之前版本的undo是不能被马上回收的,因为其他线程可能还在引用之前版本的undo,真正的回收undo是purge线程做的
Ⅱ、purge线程
2.1 purge介绍
purge的作用是删除undo,真正删除一条记录(完成update和delete)
delete from table where pk=1;
在page中只是标记为删除,page上并没有真正的删除
相关参数:innodb_purge_threads 默认是1,5.7中设大一点,4或者8,都是ssd性能比较好
-
5.5之前所有的purge操作都是master thread做的
默认只有一个purge thread
innodb_purge_threads=
-
5.6
N purge thread
innodb_purge_threads=
2.2 purge具体过程
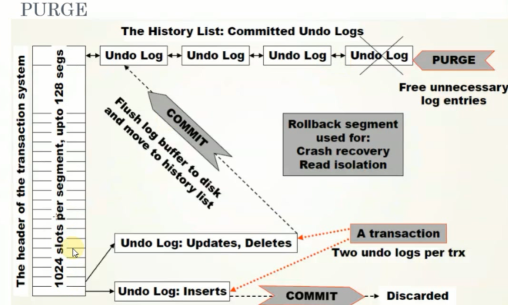
1024个槽------1024个undo回滚段,每个槽对应不同的undo日志
一旦事务提交,undo就放到hitory list中
tips:
因为记录不是有序的,所以purge操作需要大量离散读取操作
2.3 线上常见问题
undo不断增大,不能有效回收,导致系统空间不断增大,
最主要的原因有两个:
-
索引没有添加
检查slow log
-
存在大事务
拆大为小
其实就一点,一个事务执行时间很长,那对应的undo就不能回收,至少要commit完成后才能回收
另外回滚比提交慢非常多,commit很快,rollback需要的时间就是事务执行的时间,逻辑回滚
tips:
目前MySQL已经支持在线回收undo,详见阿里数据库内核月报
Ⅲ、分布式事务
之前我们谈到binlog和redo的一致性是通过一个内部的xa事务保证的,这里简单聊下外部的分布式事务
3.1 看下简单语法
(root@localhost) [test]> xa start 'a'; -- 开启一个分布式事务
Query OK, 0 rows affected (0.00 sec)
(root@localhost) [test]> insert into t values(2000);
Query OK, 1 row affected (0.09 sec)
(root@localhost) [test]> insert into t values(3000);
Query OK, 1 row affected (0.00 sec)
(root@localhost) [test]> xa end 'a'; -- 结束
Query OK, 0 rows affected (0.00 sec)
(root@localhost) [test]> xa prepare 'a'; -- 写prepare
Query OK, 0 rows affected (0.03 sec)
(root@localhost) [test]> xa recover; -- 看一眼,有一个分布式事务
+----------+--------------+--------------+------+
| formatID | gtrid_length | bqual_length | data |
+----------+--------------+--------------+------+
| 1 | 1 | 0 | a |
+----------+--------------+--------------+------+
1 row in set (0.00 sec)
(root@localhost) [test]> xa rollback 'a'; -- 回滚
Query OK, 0 rows affected (0.01 sec)
(root@localhost) [test]> xa recover; -- 再看下,没了
Empty set (0.00 sec)
这是再单实例上模拟的,意义不大
真正应用程序中两个实例做分布式事务,需要两边的prepare都成功才能最终提交
3.2 分布式事务的不完美
- client退出导致prepare成功事务丢失
- MySQL Server宕机导致binlog丢失
- 外部XA prepare成功不写日志
Ⅳ、事务编程
4.1 不好的事务习惯
- 在循环中提交事务,(fsync次数太多)
- 使用自动提交
- 使用自动回滚
create procedure load1(count int unsigned)
begin
declare s int unsigned default 1;
declare c char(80) default repeat('a',80);
while s <= count do
insert into t1 select NULL,c;
set s = s+1;
end while;
end
call load1(1000)
上面这个存储过程的调用,auto commit导致了insert会处罚一千次fsync
正确姿势:
begin;
call load1(1000)
commit;
- 错误的那种如果中间失败回滚都回不了,做不到原子性
- 将事务写到存储过程里面也不好,出错了就不好弄,不能自动回滚,所以存储过程只写逻辑,事务控制应用程序来做
4.2 大事务
事务拆大为小,原因就是binlog在搞鬼,其实不一定是大事务,大的操作都要拆吧
计算利息,拆了批量执行
update account
set account_total = account_total + (1 + interest_rate)
为什么要拆?老生常谈的、
- 写binlog成本大,导致主从延迟
- 避免过大的undo
题外话:
binlog是有点讨厌不像oracle用redo,历史原因,不好说
也有好处,做大数据平台集成非常简单,把MySQL的的数据实时推到大数据平台上太简单,github上一搜一大把项目直接用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号