崩溃恢复与组提交
Ⅰ、binlog与redo的一致性(原子)
由内部分布式事务保证
我们先来了解下,当一个commit敲下后,内部会发生什么?
| 步骤 | 操作 |
|---|---|
| step1 | InnoDB做prepare redo log(fsync) |
| step2 | Sever层写binlog(fsync) |
| step3 | InnoDB层commit redo log(fsync) |
第一步写的redo file,写入的是trxid而不是page的变化(show binlog events in 'xxx'),准确的说写在undo页上
第三步写的也是redo file
以上说的写入指的的成功落盘
这里的原理是一个内部的分布式事务,相关参数:innodb_support_xa=on
tips:
5.6默认开启分布式事务(binlog和redo log同步),5.7你设置off也没用,保证强一致性
Ⅱ、crash分析
服务crash,一个事务可能面对的状态如下:
- 1成功,2失败,那3肯定失败,重启则rollback(利用undo,一个事务的undo在active list(活跃事务列表)中就表示没提交,redo完后从active list中找没提交的事务去回滚)
- 1成功,2成功,3失败,重启则commit
- 1,2,3都成功,重启commit(将这个事务对应的undo从active list中移走,移到history list中,不能直接清理,其他事务可能还需要引用,mvcc机制要看,真正清理是后台purge thread做)
tips:
①不谈高可用的情况下,如果两个日志都写成功,其实commit和rollback都没有问题,用户并不知道他commit会不会成功,他只知道数据库断了,这种事务叫partial transaction,可提交可不提交
②mysql这里做commit是为了复制数据同步
③写重做日志oracle一次fsync,mysql要三次?
第一步或者第二步失败,自然没有第三次,前两步成功的话,其实第三步不用写到磁盘持久化,只要写到操作系统缓存就可以,不管是否有没有commit的日志,都会提交,所以其实是两次,但是有组提交加持,可能2次fsync提交了10个事务都有可能
Ⅲ、怎么个恢复法子?
3.1 面对crash部分怎么处理?
在innodb层,prepare redo log中会记录一个trxid,宕机重新起来恢复时
-
step1
先scan binlog,把所有的trxid拿出来做一个hash table(扫最后一个binlog文件,一个事务的日志是不能跨文件的)
-
step2
去scan innodb redo log,扫cp开始往后的部分,也会产生trxid list
-
step3
这时候去上面那个hash table中search,如果这个trxid在上面的hash表中,就是两个步骤都没问题,就commit,如果不在里面(第二步写binlog没成功)就rollback
tips:
上面说的已经是在数据库层面了,也就是说用户commit之后数据库里面做的东西,用户是不可以rollback的,也就是说应用层表现为失败,并不代表是真正的失败
以上讨论是crash临界点地方处理
3.2 整个恢复过程是怎样的呢?
先回顾一下lsn
LSN
log sequenct number
重做日志写入的字节量
LSN存在于:
page
redo log block
checkpoint
看图说恢复
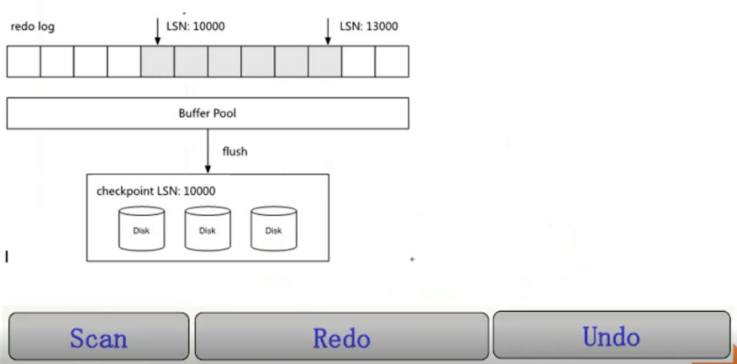
- 先scan redo log,从cp开始扫描,扫到最后一个日志块
- 接着就redo,将所有的page重做(看page中的lsn来判断到底要不要重做,如果page lsn已经比redo log lsn来的大,就说明先刷了,不用重做了)
- 最后接到前面的扫两个hash table,将没有提交的事务用undo进行rollback
Ⅳ、组提交
背景:commit的本质就是每次提交后执行下面的操作
由innodb_flush_log_at_trx_commit参数决定
- 1 fsync 写盘
- 2 fwrite 写缓存
hdd盘的iops是100,那一秒钟只能执行100次fsync,增删改的qps的最大就是100(每做一个增删改就提交一次)
所以我们经常批量导入数据
批量导数据,begin;插10条;commit 这样就只fsync了一次,这样qps就提升了10倍
就这样组提交诞生来了——一次fsync刷新一组事务(多线程)
性能提高10~100+倍,innodb存储引擎原生支持,事务响应不会变慢的,不用担心
看两个相关参数(5.7才有)
binlog_group_commit_sync_delay 组提交一定要等待多少微秒,时间越长一次性提交的事务越多,fsync次数越少,性能越好
binlog_group_commit_sync_no_delay_count 累积到多少个才组提交
千万不要调,你是调不好的呢,比如你调成5个事务,那你业务没五个线程,那你就被hang住了,数据库自身已经做的很好了
5.5有个bug,开启binlog,组提交就会失效,设置双1的话,性能会很差,那时候为了缓解这个问题把innodb_flush_log_at_trx_commit设置为2,crash可能最后一段事务丢失
tips:
-
5.6和5.5一起跑纯更新操作的sysbench测试,前者性能会比后者好8到10倍
-
5.6中设置为2,性能基本上没什么差别,在3%到5%之间
-
所以说5.6之前的版本就不要用了,就这么一个原因就够了
-
另外一个提升性能的参数
sync_binlog参数 5.7默认为1,之前默认为00表示事务提交后,binlog写到操作系统缓存,操作系统控制怎么写到文件 1表示事务提交时binlog写到磁盘 100表示100次事务提交刷一次磁盘5.5中设置为0是有提升,5.6之后就不会有这个问题了,而且0可能会有丢数据的风险
到这里传说中的innodb事务系统中的双1到这里就解释清楚了,到现在为止我们就不用把这两个值设为其他值了
附:官网的一句话:分布式事务就要用serializable,这时候串行才有意义,想不通
Ⅴ、补充redo和binlog区别
- binlog是server层的逻辑日志
- redo是innodb层的物理逻辑日志
- 两者写入的时间点不一样,binlog只有在事务提交时写入,redo会在好几种情况下写入,之前分析过
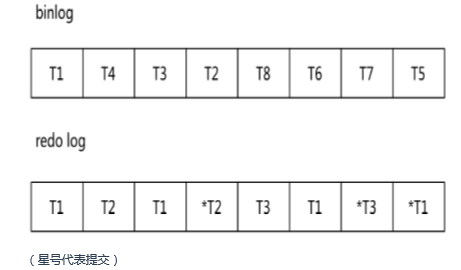
binlog 直接按事务提交顺序
redo log 按带星号的顺序提交,只要page发生修改就会记录到日志中,所以T2修改的日志可以和T1是对同一个page修改
虽然都是T1 T2 T3,但是binlog记录的是数据库的操作,类似sql语句的
redo log记录的是对page的修改,一个事务可以对多个page进行修改,事务是并行在运行的,所以可以有多个事务对多个不同的page在修改,所以提交顺序比较特殊
redo log里面一个事务的日志可以有很多,但binlog只有一个
redo log在事务提交过程中就开始写,binlog在事务提交最后才开始写
千万记住redo log里面没记录sql的
协助理解:
一个update操作,提交后写了一个binlog,但是可能update修改了很多page进而产生了很多redo log,然后根据事务提交顺序来写盘,比如T1事务先操作了page A没提交,T2事务跟着对page A做了修改提交了,这时候就会写redo,此时T1事务还没提交呢
tips:
- oracle中没有binlog,不管事务大小,提交的时间都是平均的,因为在事务执行的过程中日志就在刷盘了
- 在mysql中由于binlog是事务提交后才开始写,所以大事务提交时间很长,小事务提交时间比较短
- 大事务提交会影响到后面事务提交,会排队,不过排队是好事,后面排一起组提交

 浙公网安备 33010602011771号
浙公网安备 33010602011771号