
Hadoop学习笔记—10.Shuffle过程那点事儿
一、回顾Reduce阶段三大步骤
在第四篇博文《初识MapReduce》中,我们认识了MapReduce的八大步骤,其中在Reduce阶段总共三个步骤,如下图所示:
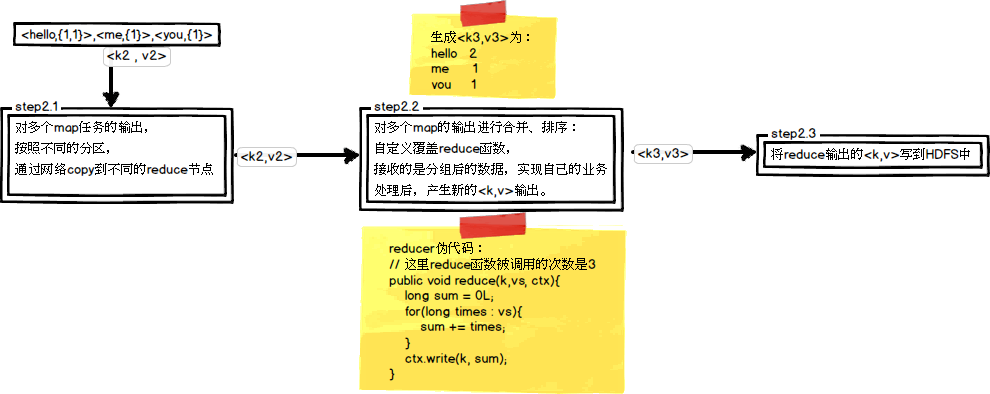
其中,Step2.1就是一个Shuffle操作,它针对多个map任务的输出按照不同的分区(Partition)通过网络复制到不同的reduce任务节点上,这个过程就称作为Shuffle。
PS:Hadoop的shuffle过程就是从map端输出到reduce端输入之间的过程,这一段应该是Hadoop中最核心的部分,因为涉及到Hadoop中最珍贵的网络资源,所以shuffle过程中会有很多可以调节的参数,也有很多策略可以研究,这方面可以看看大神董西成的相关文章或他写的MapReduce相关书籍。
二、Shuffle过程浅析
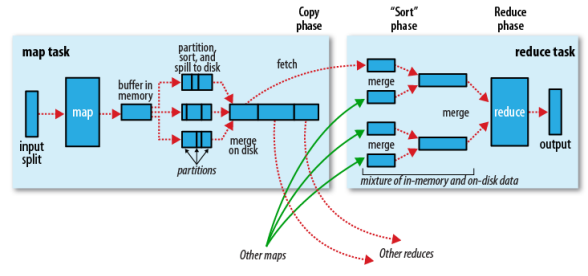
上图中分为Map任务和Reduce任务两个阶段,从map端输出到reduce端的红色和绿色的线表示数据流的一个过程,也我们所要了解的Shuffle过程。
2.1 Map端
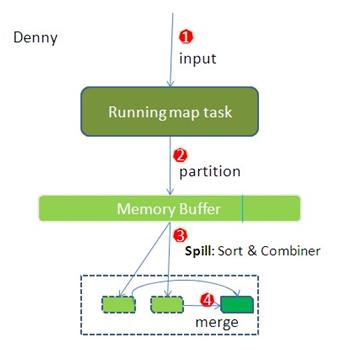
(1)在map端首先接触的是InputSplit,在InputSplit中含有DataNode中的数据,每一个InputSplit都会分配一个Mapper任务,Mapper任务结束后产生<K2,V2>的输出,这些输出先存放在缓存中,每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spil l.percent),一个后台线程就把内容写到(spill)Linux本地磁盘中的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
总结:map过程的输出是写入本地磁盘而不是HDFS,但是一开始数据并不是直接写入磁盘而是缓冲在内存中,缓存的好处就是减少磁盘I/O的开销,提高合并和排序的速度。又因为默认的内存缓冲大小是100M(当然这个是可以配置的),所以在编写map函数的时候要尽量减少内存的使用,为shuffle过程预留更多的内存,因为该过程是最耗时的过程。
(2)写磁盘前,要进行partition、sort和combine等操作。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。
(3)最后将磁盘中的数据送到Reduce中,从图中可以看出Map输出有三个分区,有一个分区数据被送到图示的Reduce任务中,剩下的两个分区被送到其他Reducer任务中。而图示的Reducer任务的其他的三个输入则来自其他节点的Map输出。
补充:在写磁盘的时候采用压缩的方式将map的输出结果进行压缩是一个减少网络开销很有效的方法!关于如何使用压缩,在本文第三部分会有介绍。
2.2 Reduce端
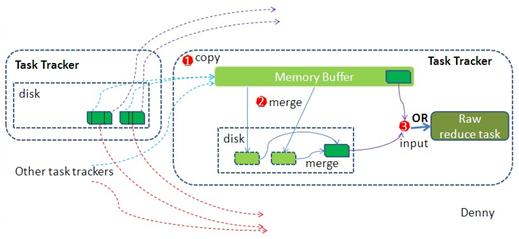
(1)Copy阶段:Reducer通过Http方式得到输出文件的分区。
reduce端可能从n个map的结果中获取数据,而这些map的执行速度不尽相同,当其中一个map运行结束时,reduce就会从JobTracker中获取该信息。map运行结束后TaskTracker会得到消息,进而将消息汇报给JobTracker,reduce定时从JobTracker获取该信息,reduce端默认有5个数据复制线程从map端复制数据。
(2)Merge阶段:如果形成多个磁盘文件会进行合并
从map端复制来的数据首先写到reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,同样会进行partition、combine、排序等过程。如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为reduce的输入而不是写入到磁盘中。
(3)Reducer的参数:最后将合并后的结果作为输入传入Reduce任务中。
总结:当Reducer的输入文件确定后,整个Shuffle操作才最终结束。之后就是Reducer的执行了,最后Reducer会把结果存到HDFS上。
三、Hadoop中的压缩
刚刚我们在了解Shuffle过程中看到,map端在写磁盘的时候采用压缩的方式将map的输出结果进行压缩是一个减少网络开销很有效的方法。其实,在Hadoop中早已为我们提供了一些压缩算法的实现,我们不用重复造轮子了。
3.1 解压缩算法的实现:Codec
Codec是Hadoop中关于压缩,解压缩的算法的实现,在Hadoop中,codec由CompressionCode的实现来表示。下面是一些常见压缩算法实现,如下图所示:

3.2 MapReduce的输出进行压缩
(1)MapReduce的输出属性如下所示

(2)在Java中如何针对输出设置压缩 ★★★

上图中在reduce端输出压缩使用了刚刚Codec中的Gzip算法,当然你也可以使用bzip2算法;
参考资料
(1)董西成,《Hadoop中shuffle阶段流程分析》:http://dongxicheng.org/mapreduce/hadoop-shuffle-phase/ (该文对Shuffle阶段的一些不足做出了分析,并给出了几个目前流行的解决办法)
(2)左坚,《Hadoop计算中的shuffle过程》:http://www.wnt.com.cn/html/news/tophome/top_xytd/top_xytd_jswz/bbs_service/20130711/111140562.html
(3)皮皮家的程序猿,《Hadoop中的shuffle过程》:http://www.cnblogs.com/zhangcm/archive/2012/11/23/2784495.html
(4)Suddenly,《MapReduce排序和分组》:http://www.cnblogs.com/sunddenly/p/4009751.html

