
Hadoop学习笔记—5.自定义类型处理手机上网日志
一、测试数据:手机上网日志
1.1 关于这个日志
假设我们如下一个日志文件,这个文件的内容是来自某个电信运营商的手机上网日志,文件的内容已经经过了优化,格式比较规整,便于学习研究。
该文件的内容如下(这里我只截取了三行):
1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站 15 12 1527 2106 200
1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 信息安全 20 203156 2936 200
1363157982040 13502468823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 综合门户 57 102 7335 110349 200
每一行不同的字段有有不同的含义,具体的含义如下图所示:
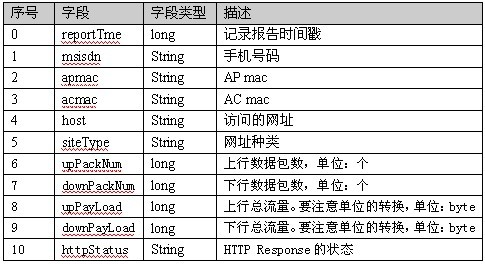
1.2 要实现的目标
有了上面的测试数据—手机上网日志,那么问题来了,如何通过map-reduce实现统计不同手机号用户的上网流量信息?通过上表可知,第6~9个字段是关于流量的信息,也就是说我们需要为每个用户统计其upPackNum、downPackNum、upPayLoad以及downPayLoad这个四个字段的数量和,达到以下的显示结果:
13480253104 3 3 180 180
13502468823 57 102 7335 110349
二、解决思路:封装手机流量
2.1 Writable接口
经过上一篇的学习,我们知道了在Hadoop中操作所有的数据类型都需要实现一个叫Writable的接口,实现了该接口才能够支持序列化,才能方便地在Hadoop中进行读取和写入。

public interface Writable {
/**
* Serialize the fields of this object to <code>out</code>.
*/
void write(DataOutput out) throws IOException;
/**
* Deserialize the fields of this object from <code>in</code>.
*/
void readFields(DataInput in) throws IOException;
}
从上面的代码中可以看到Writable 接口只有两个方法的定义,一个是write 方法,一个是readFields 方法。前者是把对象的属性序列化到DataOutput 中去,后者是从DataInput 把数据反序列化到对象的属性中。(简称“读进来”,“写出去”)
java 中的基本类型有char、byte、boolean、short、int、float、double 共7 中基本类型,除了char,都有对应的Writable 类型。但是,没有我们需要的对应类型。于是,我们需要仿照现有的对应Writable 类型封装一个自定义的数据类型,以供本次试验使用。
2.2 封装KpiWritable类型
我们需要为每个用户统计其upPackNum、downPackNum、upPayLoad以及downPayLoad这个四个字段的数量和,而这个四个字段又都是long 类型,于是我们可以封装以下代码:
/*
* 自定义数据类型KpiWritable
*/
public class KpiWritable implements Writable {
long upPackNum; // 上行数据包数,单位:个
long downPackNum; // 下行数据包数,单位:个
long upPayLoad; // 上行总流量,单位:byte
long downPayLoad; // 下行总流量,单位:byte
public KpiWritable() {
}
public KpiWritable(String upPack, String downPack, String upPay,
String downPay) {
upPackNum = Long.parseLong(upPack);
downPackNum = Long.parseLong(downPack);
upPayLoad = Long.parseLong(upPay);
downPayLoad = Long.parseLong(downPay);
}
@Override
public String toString() {
String result = upPackNum + "\t" + downPackNum + "\t" + upPayLoad
+ "\t" + downPayLoad;
return result;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
}
@Override
public void readFields(DataInput in) throws IOException {
upPackNum = in.readLong();
downPackNum = in.readLong();
upPayLoad = in.readLong();
downPayLoad = in.readLong();
}
}
通过实现Writable接口的两个方法,就封装好了KpiWritable类型。
三、编程实现:依然MapReduce
3.1 自定义Mapper类
/*
* 自定义Mapper类,重写了map方法
*/
public static class MyMapper extends
Mapper<LongWritable, Text, Text, KpiWritable> {
protected void map(
LongWritable k1,
Text v1,
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, KpiWritable>.Context context)
throws IOException, InterruptedException {
String[] spilted = v1.toString().split("\t");
String msisdn = spilted[1]; // 获取手机号码
Text k2 = new Text(msisdn); // 转换为Hadoop数据类型并作为k2
KpiWritable v2 = new KpiWritable(spilted[6], spilted[7],
spilted[8], spilted[9]);
context.write(k2, v2);
};
}
这里将第6~9个字段的数据都封装到KpiWritable类型中,并将手机号和KpiWritable作为<k2,v2>传入下一阶段;
3.2 自定义Reducer类
/*
* 自定义Reducer类,重写了reduce方法
*/
public static class MyReducer extends
Reducer<Text, KpiWritable, Text, KpiWritable> {
protected void reduce(
Text k2,
java.lang.Iterable<KpiWritable> v2s,
org.apache.hadoop.mapreduce.Reducer<Text, KpiWritable, Text, KpiWritable>.Context context)
throws IOException, InterruptedException {
long upPackNum = 0L;
long downPackNum = 0L;
long upPayLoad = 0L;
long downPayLoad = 0L;
for (KpiWritable kpiWritable : v2s) {
upPackNum += kpiWritable.upPackNum;
downPackNum += kpiWritable.downPackNum;
upPayLoad += kpiWritable.upPayLoad;
downPayLoad += kpiWritable.downPayLoad;
}
KpiWritable v3 = new KpiWritable(upPackNum + "", downPackNum + "",
upPayLoad + "", downPayLoad + "");
context.write(k2, v3);
};
}
这里将Map阶段每个手机号所对应的流量记录都一一进行相加求和,最后生成一个新的KpiWritable类型对象与手机号作为新的<k3,v3>返回;
3.3 完整代码实现
完整的代码如下所示:

public class MyKpiJob extends Configured implements Tool {
/*
* 自定义数据类型KpiWritable
*/
public static class KpiWritable implements Writable {
long upPackNum; // 上行数据包数,单位:个
long downPackNum; // 下行数据包数,单位:个
long upPayLoad; // 上行总流量,单位:byte
long downPayLoad; // 下行总流量,单位:byte
public KpiWritable() {
}
public KpiWritable(String upPack, String downPack, String upPay,
String downPay) {
upPackNum = Long.parseLong(upPack);
downPackNum = Long.parseLong(downPack);
upPayLoad = Long.parseLong(upPay);
downPayLoad = Long.parseLong(downPay);
}
@Override
public String toString() {
String result = upPackNum + "\t" + downPackNum + "\t" + upPayLoad
+ "\t" + downPayLoad;
return result;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
}
@Override
public void readFields(DataInput in) throws IOException {
upPackNum = in.readLong();
downPackNum = in.readLong();
upPayLoad = in.readLong();
downPayLoad = in.readLong();
}
}
/*
* 自定义Mapper类,重写了map方法
*/
public static class MyMapper extends
Mapper<LongWritable, Text, Text, KpiWritable> {
protected void map(
LongWritable k1,
Text v1,
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, KpiWritable>.Context context)
throws IOException, InterruptedException {
String[] spilted = v1.toString().split("\t");
String msisdn = spilted[1]; // 获取手机号码
Text k2 = new Text(msisdn); // 转换为Hadoop数据类型并作为k2
KpiWritable v2 = new KpiWritable(spilted[6], spilted[7],
spilted[8], spilted[9]);
context.write(k2, v2);
};
}
/*
* 自定义Reducer类,重写了reduce方法
*/
public static class MyReducer extends
Reducer<Text, KpiWritable, Text, KpiWritable> {
protected void reduce(
Text k2,
java.lang.Iterable<KpiWritable> v2s,
org.apache.hadoop.mapreduce.Reducer<Text, KpiWritable, Text, KpiWritable>.Context context)
throws IOException, InterruptedException {
long upPackNum = 0L;
long downPackNum = 0L;
long upPayLoad = 0L;
long downPayLoad = 0L;
for (KpiWritable kpiWritable : v2s) {
upPackNum += kpiWritable.upPackNum;
downPackNum += kpiWritable.downPackNum;
upPayLoad += kpiWritable.upPayLoad;
downPayLoad += kpiWritable.downPayLoad;
}
KpiWritable v3 = new KpiWritable(upPackNum + "", downPackNum + "",
upPayLoad + "", downPayLoad + "");
context.write(k2, v3);
};
}
// 输入文件目录
public static final String INPUT_PATH = "hdfs://hadoop-master:9000/testdir/input/HTTP_20130313143750.dat";
// 输出文件目录
public static final String OUTPUT_PATH = "hdfs://hadoop-master:9000/testdir/output/mobilelog";
@Override
public int run(String[] args) throws Exception {
// 首先删除输出目录已生成的文件
FileSystem fs = FileSystem.get(new URI(INPUT_PATH), getConf());
Path outPath = new Path(OUTPUT_PATH);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
// 定义一个作业
Job job = new Job(getConf(), "MyKpiJob");
// 设置输入目录
FileInputFormat.setInputPaths(job, new Path(INPUT_PATH));
// 设置自定义Mapper类
job.setMapperClass(MyMapper.class);
// 指定<k2,v2>的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(KpiWritable.class);
// 设置自定义Reducer类
job.setReducerClass(MyReducer.class);
// 指定<k3,v3>的类型
job.setOutputKeyClass(Text.class);
job.setOutputKeyClass(KpiWritable.class);
// 设置输出目录
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
// 提交作业
Boolean res = job.waitForCompletion(true);
if(res){
System.out.println("Process success!");
System.exit(0);
}
else{
System.out.println("Process failed!");
System.exit(1);
}
return 0;
}
public static void main(String[] args) {
Configuration conf = new Configuration();
try {
int res = ToolRunner.run(conf, new MyKpiJob(), args);
System.exit(res);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.4 调试运行效果

附件下载
(1)本次用到的手机上网日志(部分版):http://pan.baidu.com/s/1dDzqHWX

