
Hadoop学习笔记—1.基本介绍与环境配置
一、Hadoop的发展历史

说到Hadoop的起源,不得不说到一个传奇的IT公司—全球IT技术的引领者Google。Google(自称)为云计算概念的提出者,在自身多年的搜索引擎业务中构建了突破性的GFS(Google File System),从此文件系统进入分布式时代。除此之外,Google在GFS上如何快速分析和处理数据方面开创了MapReduce并行计算框架,让以往的高端服务器计算变为廉价的x86集群计算,也让许多互联网公司能够从IOE(IBM小型机、Oracle数据库以及EMC存储)中解脱出来,例如:淘宝早就开始了去IOE化的道路。然而,Google之所以伟大就在于独享技术不如共享技术,在2002-2004年间以三大论文的发布向世界推送了其云计算的核心组成部分GFS、MapReduce以及BigTable。Google虽然没有将其核心技术开源,但是这三篇论文已经向开源社区的大牛们指明了方向,一位大牛:Doug Cutting使用Java语言对Google的云计算核心技术(主要是GFS和MapReduce)做了开源的实现。后来,Apache基金会整合Doug Cutting以及其他IT公司(如Facebook等)的贡献成果,开发并推出了Hadoop生态系统。Hadoop是一个搭建在廉价PC上的分布式集群系统架构,它具有高可用性、高容错性和高可扩展性等优点。由于它提供了一个开放式的平台,用户可以在完全不了解底层实现细节的情形下,开发适合自身应用的分布式程序。
二、Hadoop的整体框架
Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成,其中最基础最重要的两种组成元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop Distributed File System)和上层用来执行MapReduce程序的MapReduce引擎。


三、Hadoop的核心设计

3.1 HDFS
HDFS是一个高度容错性的分布式文件系统,可以被广泛的部署于廉价的PC之上。它以流式访问模式访问应用程序的数据,这大大提高了整个系统的数据吞吐量,因而非常适合用于具有超大数据集的应用程序中。
HDFS的架构如下图所示。HDFS架构采用主从架构(master/slave)。一个典型的HDFS集群包含一个NameNode节点和多个DataNode节点。NameNode节点负责整个HDFS文件系统中的文件的元数据保管和管理,集群中通常只有一台机器上运行NameNode实例,DataNode节点保存文件中的数据,集群中的机器分别运行一个DataNode实例。在HDFS中,NameNode节点被称为名称节点,DataNode节点被称为数据节点。DataNode节点通过心跳机制与NameNode节点进行定时的通信。

可以看作是分布式文件系统中的管理者,存储文件系统的meta-data,主要负责管理文件系统的命名空间,集群配置信息,存储块的复制。
是文件存储的基本单元。它存储文件块在本地文件系统中,保存了文件块的meta-data,同时周期性的发送所有存在的文件块的报告给NameNode。
就是需要获取分布式文件系统文件的应用程序。
下面来看看在HDFS上如何进行文件的读/写操作:

文件写入:
1. Client向NameNode发起文件写入的请求
2. NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
3. Client将文件划分为多个文件块,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。

文件读取:
1. Client向NameNode发起文件读取的请求
2. NameNode返回文件存储的DataNode的信息。
3. Client读取文件信息。
3.2 MapReduce
MapReduce是一种编程模型,用于大规模数据集的并行运算。Map(映射)和Reduce(化简),采用分而治之思想,先把任务分发到集群多个节点上,并行计算,然后再把计算结果合并,从而得到最终计算结果。多节点计算,所涉及的任务调度、负载均衡、容错处理等,都由MapReduce框架完成,不需要编程人员关心这些内容。
下图是一个MapReduce的处理过程:

用户提交任务给JobTracer,JobTracer把对应的用户程序中的Map操作和Reduce操作映射至TaskTracer节点中;输入模块负责把输入数据分成小数据块,然后把它们传给Map节点;Map节点得到每一个key/value对,处理后产生一个或多个key/value对,然后写入文件;Reduce节点获取临时文件中的数据,对带有相同key的数据进行迭代计算,然后把终结果写入文件。
如果这样解释还是太抽象,可以通过下面一个具体的处理过程来理解:(WordCount实例) Hadoop的核心是MapReduce,而MapReduce的核心又在于map和reduce函数。它们是交给用户实现的,这两个函数定义了任务本身。
Hadoop的核心是MapReduce,而MapReduce的核心又在于map和reduce函数。它们是交给用户实现的,这两个函数定义了任务本身。
- map函数:接受一个键值对(key-value pair)(例如上图中的Splitting结果),产生一组中间键值对(例如上图中Mapping后的结果)。Map/Reduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。
- reduce函数:接受一个键,以及相关的一组值(例如上图中Shuffling后的结果),将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)(例如上图中Reduce后的结果)
但是,Map/Reduce并不是万能的,适用于Map/Reduce计算有先提条件:
①待处理的数据集可以分解成许多小的数据集;
②而且每一个小数据集都可以完全并行地进行处理;
若不满足以上两条中的任意一条,则不适合使用Map/Reduce模式;
四、Hadoop的安装配置
Hadoop共有三种部署方式:本地模式,伪分布模式及集群模式;本次安装配置以伪分布模式为主,即在一台服务器上运行Hadoop(如果是分布式模式,则首先要配置Master主节点,其次配置Slave从节点)。以下说明如无特殊说明,默认使用root用户登录主节点,进行以下的一系列配置。
安装配置前请先准备好以下软件:
- vmware workstation 8.0或以上版本
- redhat server 6.x版本或centos 6.x版本
- jdk-6u24-linux-xxx.bin
- hadoop-1.1.2.tar.gz
4.1 设置静态IP地址
命令模式下可以执行setup命令进入设置界面配置静态IP地址;x-window界面下可以右击网络图标配置;
配置完成后执行service network restart重新启动网络服务;
验证:执行命令ifconfig
4.2 修改主机名
<1>修改当前会话中的主机名(这里我的主机名设为hadoop-master),执行命令hostname hadoop-master
<2>修改配置文件中的主机名,执行命令vi /etc/sysconfig/network
验证:重启系统reboot
4.3 DNS绑定
执行命令vi /etc/hosts,增加一行内容,如下(这里我的Master节点IP设置的为192.168.80.100):
192.168.80.100 hadoop-master
保存后退出
验证:ping hadoop-master
4.4 关闭防火墙及其自动运行
<1>执行关闭防火墙命令:service iptables stop
验证:service iptables stauts
<2>执行关闭防火墙自动运行命令:chkconfig iptables off
验证:chkconfig --list | grep iptables
4.5 SSH(Secure Shell)的免密码登录
<1>执行产生密钥命令:ssh-keygen –t rsa,位于用户目录下的.ssh文件中(.ssh为隐藏文件,可以通过ls –a查看)
<2>执行产生命令:cp id_rsa.pub authorized_keys
验证:ssh localhost
4.6 复制JDK和Hadoop-1.1.2.tar.gz至Linux中
<1>使用WinScp或CuteFTP等工具将jdk和hadoop.tar.gz复制到Linux中(假设复制到了Downloads文件夹中);
<2>执行命令:rm –rf /usr/local/* 删除该文件夹下所有文件
<3>执行命令:cp /root/Downloads/* /usr/local/ 将其复制到/usr/local/文件夹中
4.7 安装JDK
<1>在/usr/local下解压jdk安装文件:./jdk-6u24-linux-i586.bin(如果报权限不足的提示,请先为当前用户对此jdk增加执行权限:chmod u+x jdk-6u24-linux-i586.bin)
<2>重命名解压后的jdk文件夹:mv jdk1.6.0_24 jdk(此步凑非必要,只是建议)
<3>配置Linux环境变量:vi /etc/profile,在其中增加几行:
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
<4>生效环境变量配置:source /etc/profile
验证:java –version
4.8 安装Hadoop
<1>在/usr/local下解压hadoop安装文件:tar –zvxf hadoop-1.1.2.tar.gz
<2>解压后重命名hadoop-1.1.2文件夹:mv hadoop-1.1.2 hadoop(此步凑非必要,只是建议)
<3>配置Hadoop相关环境变量:vi /etc/profile,在其中增加一行:
export HADOOP_HOME=/usr/local/hadoop
然后修改一行:
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME:$PATH
<4>生效环境变量:source /etc/profile
<5>修改Hadoop的配置文件,它们位于$HADOOP_HOME/conf目录下。
分别修改四个配置文件:hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml;
具体下修改内容如下:(由于修改内容较多,建议使用WinScp进入相关目录下进行编辑和保存,可以节省较多时间和精力)
5.1【hadoop-env.sh】 修改第九行:
export JAVA_HOME=/usr/local/jdk/
如果虚拟机内存低于1G,还需要修改HADOOP_HEAPSIZE(默认为1000)的值:
export HADOOP_HEAPSIZE=100
5.2【core-site.xml】 在configuration中增加以下内容(其中的hadoop-master为你配置的主机名):
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master:9000</value>
<description>change your own hostname</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
5.3 【hdfs-site.xml】 在configuration中增加以下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
5.4 【mapred-site.xml】 在configuration中增加以下内容(其中的hadoop-master为你配置的主机名):
<property>
<name>mapred.job.tracker</name>
<value>hadoop-master:9001</value>
<description>change your own hostname</description>
</property>
<6>执行命令对Hadoop进行初始格式化:hadoop namenode –format

<7>执行命令启动Hadoop:start-all.sh(一次性启动所有进程)

第二种方式:通过执行如下方式命令单独启动HDFS和MapReduce:start-dfs.sh和start-mapred.sh启动,stop-dfs.sh和stop-mapred.sh关闭;
第三种方式:通过执行如下方式命令分别启动各个进程:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
hadoop-daemon.sh start secondarynamenode
hadoop-daemon.sh start jobtracker
hadoop-daemon.sh start tasktracker
这种方式的执行命令是hadoop-daemon.sh start [进程名称],这种启动方式适合于单独增加、删除节点的情况,在安装集群环境的时候会看到。
验证:
① 执行jps命令查看java进程信息,如果是start-all.sh则一共显示5个java进程。
②在浏览器中浏览Hadoop,输入URL:hadoop-master:50070和hadoop-master:50030。如果想在宿主机Windows中浏览,可以直接通过ip地址加端口号访问,也可以配置C盘中System32/drivers/etc/中的hosts文件,增加DNS主机名映射,例如:192.168.80.100 hadoop-master。
访问效果如下图:
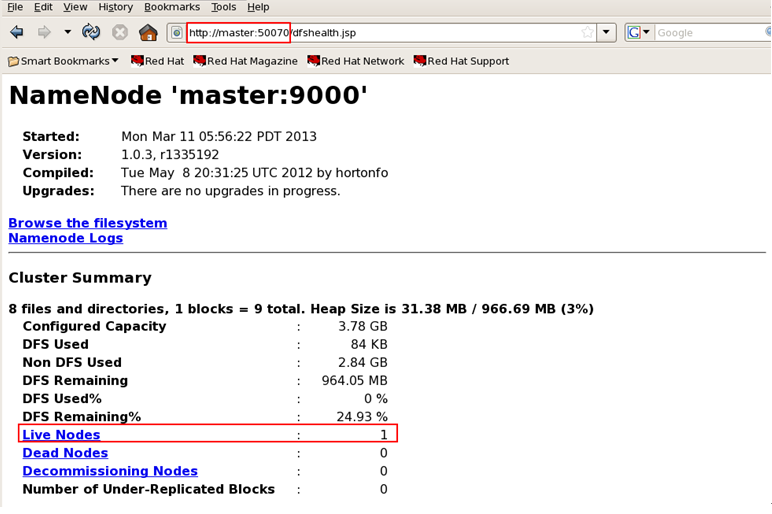 namenode
namenode

jobtracker
<8>NameNode进程没有启动成功?可以从以下几个方面检查:
没有对NameNode进行格式化操作:hadoop namenode –format(PS:多次格式化也会出错,保险操作是先删除/usr/local/hadoop/tmp文件夹再重新格式化)
Hadoop配置文件只复制没修改: 修改四个配置文件需要改的参数
DNS没有设置IP和hostname的绑定:vi /etc/hosts
SSH的免密码登录没有配置成功:重新生成rsa密钥
<9>Hadoop启动过程中出现以下警告?

可以通过以下步凑去除该警告信息:
①首先执行命令查看shell脚本:vi start-all.sh(在bin目录下执行),可以看到如下图所示的脚本
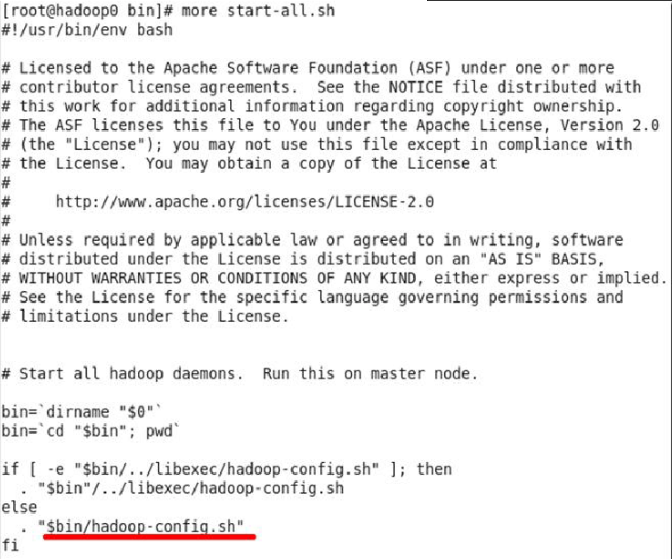
虽然我们看不懂shell脚本的语法,但是可以猜到可能和文件hadoop-config.sh有关,我们再看一下这个文件的源码。执行命令:vi hadoop-config.sh(在bin目录下执行),由于该文件特大,我们只截取最后一部分,见下图。
从图中的红色框框中可以看到,脚本判断环境变量HADOOP_HOME和HADOOP_HOME_WARN_SUPPRESS的值,如果前者为空,后者不为空,则显示警告信息“Warning„„”。
我们在前面的安装过程中已经配置了HADOOP_HOME这个环境变量,因此,只需要给HADOOP_HOME_WARN_SUPPRESS配置一个值就可以了。所以,执行命令:vi /etc/profile,增加一行内容(值随便设置一个即可,这里设为0):
export HADOOP_HOME_WARN_SUPPRESS=0
保存退出后执行重新生效命令:source /etc/profile,生效后重新启动hadoop进程则不会提示警告信息了。
至此,一个Hadoop的Master节点的安装配置结束,接下来我们要进行从节点的配置。
--------------------------------------------------------------------------------------------------------------------------
上面就是一个典型的伪分布模式的安装过程,如果想要尝试分布式模式安装,可以参考下面这个文档:
附件请猛击这个链接:Hadoop安装和配置文档v0.3

