浅谈KMP
给你一个文本串和一个模式串,问在文本串中模式串在什么时候出现过。
显然存在一种暴力写法(万能暴力):
从文本串和模式串的开头进行匹配,直到失配,则从模式串开头进行重新匹配。 显然这种写法是很慢的,失配后它只能一格一格地从头开始找。
看下面的例子:

当匹配到以下情况:

那么按照我们的暴力写法,应该是这个样:
它显然是匹配不上的嘛,只能一步步接着跑了,我们当然希望程序能聪明一点.
我们显然是希望程序避免一些无用功,最好能跳到一个最有可能匹配成功的位置,比如:

这不就比之前笨笨的暴力写法强多了吗?
但这仿佛是不可能的,谁能直接告诉程序应该跳到哪里呢?
其实这个算法早有人想了出来(%%%),这就是传说中的: Knuth–Morris–Pratt algorithm(克努斯——莫里斯——普拉特算法)
也就是KMP算法……
它的核心思路就是能告诉程序失配后该从哪里重新匹配。
接下来正式讲一下KMP吧。
观察我们要跳多远:
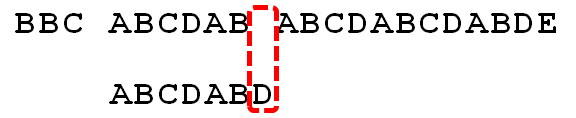 --->
--->

我们发现,如果设从k开始失配,那么我们可以保证在k之前都是一一对应的。
在这个例子中我们发现结尾(匹配上的)有个AB,开头也有个AB。
AB和AB是一样的,而结尾的AB与失配前文本串中匹配,所以开头的AB一定也是匹配的。
我们考虑将模式串当前位置移到2(从0开始),那就有可能匹配上了。
我们总结经验:失配前如果模式串开头和结尾相同,那我们就可以跳到重复子串的下一位,而不是从头匹配了。
所以我们设k失配后应移动到next[k],则next[k]等价于在k之前(不含k)的子串中前缀和后缀相同部分的长度。
如之前的例子就是开头结尾均有个AB长度为2,所以next[k]=2; k就应跳回位置2重新匹配。
next数组是KMP的精髓,许多人之所以不懂KMP就是看不懂next,
这里希望大家能结合例子搞懂next的含义。
 (良心题干)
(良心题干)
实现:
第一步---求next: 就是找模式串中前缀后缀相同的长度。
当然我们可以用现成的next来找接下来的next而不一定暴力找。
这代码就是自己和自己匹配,k找的是之前的匹配长度,如果这两位相同,显然当前前缀后缀的匹配长度就是k+1.否则就要从头匹配了(k初值为0)
cin>>s1>>s2; len1=s1.size(); len2=s2.size(); for(int i=1;i<len2;i++) { while(k&&s2[i]!=s2[k])k=next[k]; if(s2[i]==s2[k])k++; next[i+1]=k; }
第二步,匹配:
之前求next嘛,你要保证i比k靠后,所以从1开始匹配,现在就是逐位匹配了。
为啥输出i-len2+2 ?
首先我们知道第i位和第k位是匹配位置结尾,所以由:
首项=(末项-项数)*公差+1 可得初始位置为i-len2+1,而因为是从0开始计数,所以再加1.
for(int i=0;i<len1;i++) { while(k&&s1[i]!=s2[k])k=next[k]; if(s1[i]==s2[k])k++; if(k==len2)printf("%d\n",i-len2+2); }
板子题:
#include<iostream> #include<cstdio> #include<algorithm> #include<string> using namespace std; string s1,s2; int k,next[1000010],len1,len2; int main() { cin>>s1>>s2; len1=s1.size(); len2=s2.size(); for(int i=1;i<len2;i++) { while(k&&s2[i]!=s2[k])k=next[k]; if(s2[i]==s2[k])k++; next[i+1]=k; } k=0; for(int i=0;i<len1;i++) { while(k&&s1[i]!=s2[k])k=next[k]; if(s1[i]==s2[k])k++; if(k==len2)printf("%d\n",i-len2+2); } for(int i=1;i<=len2;i++)printf("%d ",next[i]); }
总结:
1.KMP的关键在于next数组,理解KMP的关键就是处理和应用next
2.KMP的思路也可以用来做别的事情,比如找前缀后缀重合长度。
3.KMP考试应用并不多,基本被人遗忘,QYF大佬有立下NOIP考KMP就吃*的flag,也是因为这一点。
引言:
现在哪有人用KMP做字符串匹配啊,顶多在next上跑DP什么的。
—— rqy
没办法,KMP就是这么冷门,但是又引申出了它的扩展算法及改进算法(毕竟KMP是个不错的模型) 至于这些嘛......且听下回分解。
