

正则表达式总结1
正则表达式(Regular Expression)
概念:通过使用一个特定字符串来匹配所有满足这个特定字符串规则的字符串,具有强大的搜索和匹配功能,在搜索文本具体内容时十分简洁方便,应用也十分广泛,许多编程语言都支持正则表达式,虽然在一些细节上略有不同但都吸收了正则表达式的精髓。
具体应用:
- 字符串验证:可以用于验证某个字符串是否满足规则,如表单验证,某些网站注册账号时会强调密码必须包含特殊字符和字母,这时就需要用一个正则表达式来匹配。
- 字符串查找:可以快速查找一段文章中满足正则表达式的字符串,如在一篇HTML源代码中快速查找所有的URL,在某些编程语言中,可以给查找到的字符串定位,便于全部替换。
基本匹配语法:
正则表达式分为普通字符和元字符,普通字符即匹配自身的字符,不带有特殊含义,即123456abc等,而元字符除了能够匹配自身(需要转义)外还能够根据一定规则进行模糊匹配。
1.匹配单字符:
|
语法 |
含义 |
举例 |
|
. |
用于匹配任意单个字符 |
如a,c,4,%等 |
|
[....] |
一个字符集合,可以匹配其中任何一个字符,也可以通过加-表示范围 |
[a-z]表示能匹配所有小写字母,类似写法还有[0-9], [A-Z], [abcd]表示能匹配a,b,c,d |
|
\ |
转义字符,用于消除元字符特殊含义,表达字符本身含义 |
如a\*\*可以匹配a**这个本身带有元字符的字符串 |
|
[^...] |
与上面的[...]相反,加一个^表示匹配在[....]之外的一个字符 |
[^abc]匹配除了a,b,c之外的其他字符 |
注意:1.所有的特殊字符在[...]中都会失去特殊含义
例如:
在Linux中用grep匹配正则表达式 -E表示用正则表达式匹配 --color将匹配部分高亮显示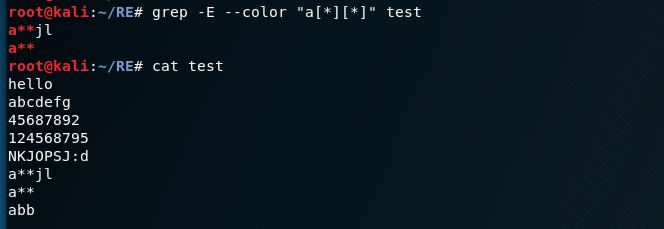
这里a[*][*]只匹配了a**而没有匹配abb
2. 在[...]中一些普通字符会变成特殊字符,如-, ^ 等。
3. 在[...]中要使用 - , ^,和 ] 需要用\转义(关于]转义仍有一些疑问),或把-, ]放在第一个字符位置,把^放在非第一个字符位置
例如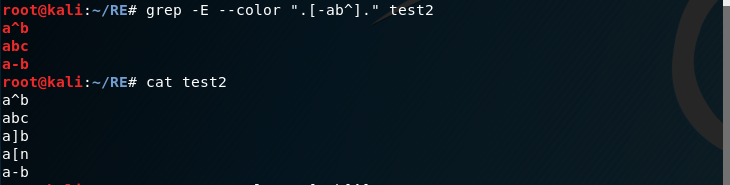
[...]中部分匹配到了^,b,和-

把[放在第一个字符位置也能匹配到 [ 这个字符了
一点疑问:
对-转义的话能够匹配到-,但是对]转义无法匹配到 ]
后面意外发现
如果不加“ ”的话是可以匹配到]的,关于这个问题我还不是很清楚,望明白者在评论中告知,十分感谢。
从这里我们可以得出,用grep匹配时有时可以不必添加双引号
另外如果要完全匹配一个字符串可以使用单引号(除去一些字符的特殊含义)

但是如果是-P选项的话,单引号和双引号没有区别
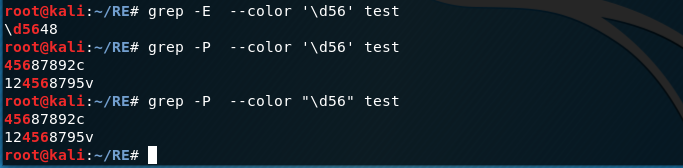
4.如果表示字母为什么是[A-Za-z]而不是[a-zA-Z]? 因为这个是根据ASCLL码来的A-Z的ASCLL是65-90,a-z的ASCLL码是97-122,所以A在前。
2.预定义字符集
| 语法 | 含义 | 举例 |
| \d | 等价于[0-9],匹配一个数字 | \d\d\d可以匹配789,456,123 |
| \D | 等价于[^0-9],匹配一个非数字 | \D\D可以匹配aa,ac |
| \s | 匹配空白字符,等价于[\t\n\r\f\v] | a\sa可以匹配a a |
| \S | 与\s相反,匹配一个非空白字符 | a\Sb可以匹配acb但不能匹配a b |
| \w | 等价于[0-9a-zA-Z] | \w\w\w可以匹配4ah,48Z |
| \W | 与\w相反 | \W\W可以匹配##,%*等 |
说明:1. 关于\s,\n是换行,\t是水平制表符,\r是回车,\v是垂直制表符,\f是换页符。
2.[\s\S]等价于. ,可以表示任意字符,同[\w\W],[\d\D]。
3.量词
| 语法 | 含义 |
举例 |
| * | 重复前一个字符至少0次 |
.*可以匹配任意字符串 aa*可以匹配a,aa,aaa,... |
| + | 重复前一个字符至少1次 | aa+可以匹配aa,aaa,... |
| ? | 重复前一个字符0次或1次 | ab?可以匹配ab,abb |
| {m,n} | 重复前一个字符m到n次 | ab{1,2}可以匹配abb,abbb |
| {n} | 精确重复前一个字符n次 | ab{3}匹配abbbb |
说明:1.关于{m,n},可以变成{m,}至少匹配m次,{,n}至多匹配n次。
2.量词是和前面的字符捆绑在一起的,如abb+最短是abb,量词+前面字符是b,所以(b+)重复b一次以上。
实例:
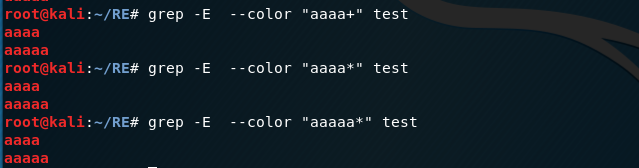
4.边界匹配
| 语法 | 含义 | 举例 |
| ^ | 匹配字符串开头 | ^abc.*匹配以abc开头的字符串 |
| $ | 匹配字符串结尾 | .*edf$匹配以edf结尾的字符串 |
| \A | 同^ | 类似^ |
| \Z | 同$ | 类似$ |
例子:
1.匹配以h开头的字符串

2.匹配以数字开头,以字母结尾的字符串

这里为什么要用-P呢?是因为在实践过程中发现-E不行查阅资料后发现grep有三种模式
- 标准正则表达式 不加选项
- 扩展正则表达式 -E
- Perl正则表达式 -P
而它们之间又有一些区别,有些语法在其他模式下不支持,比如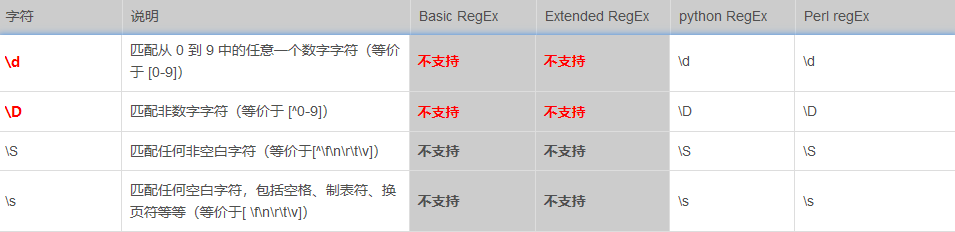
详细资料请见:https://blog.csdn.net/yufenghyc/article/details/51078107
疑问:
这里没有添加“”却无法匹配,与上面的]相反
3.匹配5-8个字母的字符串

4.匹配空白行

5.匹配最后一个小写字母结尾前没有小写字母的字符串

参考:https://www.cnblogs.com/yyds/p/6913550.html
