第九节,改善深层神经网络:超参数调试、正则化及梯度下降算法(下)
一 批标准化 (batch normalization)
1.1 批标准化
- Batch Normalization是Google2015年在论文:http://jmlr.org/proceedings/papers/v37/ioffe15.pdf中提出来的
- 训练深层的神经网络很复杂,因为训练时每一层输入的分布都在变化,导致训练过程中的饱和,称这种现象为:internal covariate shift。
- 我们为了缓解这种现象,一般需要降低学习率Learning Rate和注意权重偏置参数的初始化。
而论文中提出的对于每一个小的训练batch都进行标准化(正态化)的方法:
- 允许使用较大的学习率。
- 不必太关心初始化的问题。
- 同时一些例子中不需要使用Dropout方法避免过拟合。
- 此方法在ImageNet classification比赛中获得4.82% top-5的测试错误率。
批标准化通俗来说就是对每一层神经网络进行标准化 (normalize) 处理, 我们知道对输入数据进行标准化能让机器学习有效率地学习,如果把每一层都看成这种接受输入数据的模式。
关于在激活函数之前将值$z$进行标准化或者在激活函数后将$a$进行标准化在深度学习中存在争议,实践中,经常做的是标准化$z$ 。
我们先来看看下面的两个动图, 了解下在每层神经网络有无 batch normalization 的区别。
其中PreAct表示加权输出值z,BN PreAct表示经过批标准化之后的输出$z$。Act表示激活函数输出a,BN Act表示BN PreAct经过激活函数的输出a。
第一幅图片激活函数选择的是ReLU,第二幅图片选择的激活函数是Sigmoid函数。
第一幅图中,我们可以看到在L2层之后,PreAct,以及Act输出基本都为0了,说明神经网络已经不起任何作用了。而经过BN处理后,我们可以看到神经网络可以正常工作。详细内容参考这里。


1.2 BN算法
如果输入数据是白化的(whitened),网络会更快的收敛。白化目的是降低数据的冗余性和特征的相关性,例如通过线性变换使数据为0均值和单位方差。
并非直接标准化每一层那么简单,如果不考虑归一化的影响,可能会降低梯度下降的影响。
标准化与某个样本和所有样本都有关系 ,解决上面的问题,我们希望对于任何参数值,都要满足想要的分布;$$\hat{x} =Norm(x,\chi)$$
对于反向传播,需要计算$\frac {\partial Norm(x,\chi)}{\partial x}$和$\frac {\partial Norm(x,\chi)}{\partial \chi}$
这样做的计算代价是非常大的,因为需要计算$x$的协方差矩阵
然后白化操作:$\frac {x - E(x)}{\sqrt{Cov[x]}}$
既然白化每一层的输入代价非常大,我们可以进行简化。
1.3 简化1 (整个训练集)
- 标准化特征的每一个维度而不是去标准化所有的特征,这样就不用求协方差矩阵了。
- 例如$d$维的输入:$x=(x^{(1)},x^{(2)},...,x^{(d)})$
- 标准化操作:$\hat{x} ^{k}=\frac{x^{(k)}-E[x^{(k)}]}{\sqrt{Var[x^{(k)}]}}$
需要注意的是标准化操作可能会降低数据的表达能力,例如我们之前提到的Sigmoid函数: 
标准化之后均值为0,方差为1,数据就会落在近似线性的函数区域内,这样激活函数的意义就不明显。
但是我们不想让隐藏单元总是含有平均值 0 和方差 1,也许隐藏单元有了不同的分布才会有意义,所以我们要做的就是计算$y^{(k)}=\gamma ^{(k)}\hat{x}^{(k)} +\beta^{(k)}$ ,$\gamma ^{(k)}$, $\beta^{(k)}$是你模型学习的参数。使用梯度下降或者一些其他类似梯度下降的算法,比如 momentum 或者 Nseterov, Adam,你会更新,$\gamma ^{(k)}$, $\beta^{(k)}$,正如神经网络的权重一样。 $\gamma ^{(k)}$, $\beta^{(k)}$ 的作用是可以随意设置$y^{(k)}$的方差和均值。
从式子来看就是对标准化的数据进行缩放和平移,不至于使数据落在线性区域内,增加数据的表达能力(式子中如果:$\gamma ^{(k)}=\sqrt{Var[x^{(k)}]}$, $\beta^{(k)}=E[x^{(k)}]$ ,就会使恢复到原来的值了)。
但是这里还是使用的全部的数据集,但是如果使用随机梯度下降,可以选取一个batch进行训练。
1.4 简化2(mini batch)
第二种简化就是使用mini-batch进行随机梯度下降。
注意这里使用mini-batch也是标准化每一个维度上的特征,而不是所有的特征一起,因为如果mini-batch中的数据量小于特征的维度时,会产生奇异协方差矩阵, 对应的行列式的值为0,非满秩。
假设mini-batch 大小为$m$的$B$:$B=\{x_{1...m}\}$,对应的变换操作为:$BN_{\gamma,\beta}:x_{1...m} \to y_{1...m}$
作者给出的批标准化的算法如下: 
1.5 反向传播求梯度
因为:$y^{(k)}=\gamma ^{(k)}\hat{x}^{(k)} +\beta^{(k)}$
所以:$\frac{\partial l}{\partial \hat{x}_i } = \frac{\partial l}{\partial y_i } \gamma$
因为:$\hat{x}_i = \frac{x_i-\mu_B }{\sqrt{\sigma^2_B+\xi } } $
所以:
$\frac{\partial l}{ \partial \sigma^2_B }=\sum_{i=1}^{m} \frac{\partial l}{ \partial \hat{x}}(x_i-\mu_B)\frac{-1}{2} (\sigma ^2_B + \xi )^{-\frac{3}{2}}$
$\frac{\partial l}{ \partial \mu_B }=\sum_{i=1}^{m} \frac{\partial l}{ \partial \hat{x}_i}\frac{-1}{\sqrt{\sigma ^2_B+\xi } }$
因为:$\mu _B=\frac{1}{m} \sum_{i=1}^{m} x_i$和$\sigma ^2_B =\frac{1}{m} \sum_{i=1}^{m} (x_i-\mu _B)^2$
所以:$\frac{\partial l}{\partial x_i} =\frac{\partial l}{\partial {\hat{x}_i}} \frac{1}{\sqrt{\sigma ^2_B+\xi }} + \frac{\partial l}{\partial {\sigma ^2_B}} \frac{2(x_i-\mu_B)}{m} + \frac{\partial l}{\partial \mu _B} \frac{1}{m} $
所以:$\frac {\partial l}{\partial \gamma }=\sum_{i=1}^{m}\frac{\partial l}{\partial y_i}\hat{x}_i$、$\frac {\partial l}{\partial \beta}=\sum_{i=1}^{m}\frac{\partial l}{\partial y_i}$
对于BN变换是可微分的,随着网络的训练,网络层可以持续学到输入的分布。
1.6 BN网络的训练和测试
按照BN方法,输入数据$x$会经过变化得到$BN(x)$,然后可以通过随机梯度下降进行训练,标准化是在mini-batch上所以是非常高效的。
但是对于测试我们希望输出只取决于输入,而对于输入只有一个实例数据,无法得到mini-batch的其它实例,就无法求对应的均值和方差了。
可以通过从所有训练实例中获得的统计量来代替mini-batch中$m$个训练实例获得统计量均值和方差。
我们对每个mini-batch做标准化,可以对记住每个mini-batch的均值和方差,然后得到全局统计量。
$E[x] \leftarrow {E_B}[{\mu _B}]$
$Var[x] \leftarrow {m \over {m - 1}}{E_B}[\sigma _B^2]$(这里方差采用的是无偏方差估计)
所以测试采用BN的方式为:
$y=\gamma \frac{x-E(x)}{\sqrt{Var[x]+\xi } } + \beta=\frac{\gamma }{\sqrt{Var[x]+\xi } }x + (\beta - \frac{\gamma E(x)}{\sqrt{Var[x]+\xi } })$
作者给出的完整算法:

实际上,为了让你的神经网络运用于测试,需要单独计算 μ和σ ,除了上面说的求整个训练集均值和方差的全局平均值,在典型的 batch 归一化运用中,我们也可以用一个指数加权平均来估算平均数,这个平均数涵盖了所有 mini-batch。

$μ$和$σ$ 是在整个 mini-batch 上计算出来的,但是在测试时,你需要逐一处理样本,方法是根据你的训练集估算μ和σ ,估算的方式有很多种,理论上你可以在最终的网络中运行整个训练集来得到$μ$和$σ$,但在实际操作中,我们通常运用指数加权平均法,来追踪在训练过程中你看到的$μ$和$σ$的值,还可以用指数加权平均,有时也叫作流动平均, 来粗略估算 $μ$和$σ$,然后用测试中的μ和σ的值,来进行你所需的隐藏单元 $z$ 值的调整 。
算法中的$\xi$是一个常量,为了保证数值的稳定性
1.7 实验
最后给出的实验可以看出使用BN的方式训练精准度很高而且很稳定。

这节讲了标准化输入特征 $X$ 是怎么样有助于神经网络中的学习 batch 归一化的作用,batch 标准化的作用 是它使用的标准化过程不只是输入层,甚至同样适用于神经网络中的深度隐藏层,你应该标准化一些隐藏单元值中的平均值和方差,不过训练输入和这些隐藏单元值的一个区别是,你也许不想 隐藏单元值必须是平均值 0 和方差 1,比如你有 sigmoid 激活函数,你不想让你的值全部集中在 $x=0$ 的附近,你想使他有更大的方差,或者不是 0 的平均值,以便更好的利用非线性的 sigmoid 函数,而不是使所有值都集中在这个线性版本中,这就是为什么有了$\gamma^{(k)}$,$\beta^{(k)}$ 两个参数后,你可以确保所有的$y^{(k)}$ 值可以是你想赋予的任意值,或者它的作用是保证隐藏的单元均值和方差标准化,即$y^{(k)}$ 有固定的均值和方差,均值和方差可以是 0 和 1,也可以是其它值,它是由$\gamma^{(k)}$,$\beta^{(k)}$ 两参数控制的 。
二 softmax回归
2.1 softmax
我们之前讲解的分类例子都使用了二分类,这种分类只有两种可能的标记0 或 1,如果有多类别的怎么办?
有一种 logistic 回归的一般形式叫做Softmax 回归,能让你在试图识别某一分类时做出预测,或者说是多种分类中的一个,不只是识别两个分类。
有时候我们想把输出层第$j$个神经元的输出看做一种概率估计,也可以使用柔性最大值(softmax),第$j$个神经元的激活值是:
$a^L_j=\frac{e^{z^L_j}}{\sum_{k}e^{z^L_k}}$
并定义对数代价函数:
$C=-\frac{1}{n}\sum_{x}ylna^L$
其中$y$为训练输入$x$对应的目标输出,$a^L$为神经网络输出。
如果我们训练的是MNIST图像,输入为7的图像,那么对应的对数代价就是$-lna^L_7$,当神经网络输出就是7的时候,它会估计一个对应的概率$a^L_7$和1很接近,所以代价就会很小,反之,神经网络表现的很糟,$a^L_7$就变的很小,代价就随之增大,所以对数代价函数也是满足我们期望的代价函数的条件的。
我们也可以把对数代价函数写成如下形式:
$C=-\frac{1}{n}\sum_{x}\sum_{j}y_jloga^L_j$
这里的$y = {\begin{vmatrix} y_1 & y_2 & ... & y_n\end{vmatrix}}^T$表示训练输入$x$对应的目标输出的向量化二值化值。当网络输出时7的时候 $y= {\begin{vmatrix} 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0\end{vmatrix}}^T$。
损失函数所做的就是找到你的训练集中的真实类别,然后试图使该类别相应的概率尽可能地高,这其实是最大似然估计得一种形式。 在反向传播的时候我们计算每一个实例的输出误差 $δ^L=∂C/∂z^L=a^L-y$,即:
$\begin{vmatrix} \frac {e^{z^1}}{\sum_{k}e^{z^k}}-y_1\\ \frac {e^{z^2}}{\sum_{k}e^{z^k}}-y_2\\ ...\\\frac {e^{z^n}}{\sum_{k}e^{z^k}}-y_n\end{vmatrix}$
三 超参数调节
参考文献:[DeeplearningAI笔记]02_3.1-3.2超参数搜索技巧与对数标尺
超参数的调整一般有两张基本方法:手动选择和自动选择。
3.1. 手动调节超参数
手动调节超参数,我们必须了解超参数,训练误差,泛化误差和计算资源(内存和运行时间)之间的关系,这需要切实了解一个学习算法有效容量的基础概念。手动搜素超参数的目标通常是最小化受限于运行时间和内存预算的泛化误差,我们不去探讨如何确定各种超参数对运行时间和内存的影响,因为这高度依赖于平台。
手动搜索超参数的主要目标是调整模型的有效容量以匹配任务的复杂性。有效容量受限于三个因素:模型的表示容量,学习算法成功最小化训练模型代价函数的能力,以及代价函数和训练过程正则化模型的程度。
学习调整的参数:
- 级别一
- α:学习率可能是最重要的超参数,如果你只有时间调整一个超参数,那就调整学习率。
- 级别二
- Momentum参数,β加权值等于0.9是个很好的默认值
- mini-batch size,以确保最优算法运行有效
- 隐藏单元数量
- 级别三
- 层数 , 层数有时会产生很大的影响.
- learning rate decay 学习率衰减
- 级别四:
- 在使用Adam算法时几乎不会调整,指数衰减系数$β1$,$β2$,($β1$ 常用缺省值为 0.9, $β2$ 常用缺省值为 0.999),$ε$ 的选择则没那么重要,通常设置为$10^{-8}$ .
3.2 如何选择超参数
当有3个或更少的超参数时,常见的超参数搜索方法就是网格搜索(grid search)。对于每个超参数,使用者选择一个较小的有限值集去搜索。然后,这些超参数笛卡尔乘机得到一组组超参数,网格搜索使用每组超参数训练模型。通常网格搜索大约会在对数尺度下挑选合适的值。
在早期的机器学习算法中,如果你有两个需要选择的超参数,超参一和超参二,常见的做法是在网格中取样点,然后系统的研究这些数值。
在参数较少的时候,此方法的确很实用,但是对于参数较多的深度学习领域,我们常做的是随机选择点.这个方法是因为对于你要解决的问题而言,你很难提前知道那个超参数最重要.
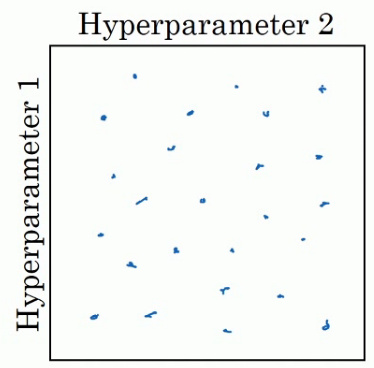
这个问题,我们可以这样来理解.假设超参数一指的是学习率α,超参数二是Adam算法中的ε,这种情况下,我们知道α很重要,但是ε的取值却无关紧要,如果你在网格中取点,接着你试验ε的5个取值,那你会发现无论ϵ如何取值,结果基本上都是一样的.所以即使你考虑了25个值,但进行实验的α值只有5个,对比而言,如果你随机取值,你会试验25个独立的α值,所以你似乎会更可能发现效果更好的取值.
对于高维参数,例如如果你有三个参数,你搜索的不是一个平面,而是一个立方体.超参数三代表第三维,接着在这个三维空间中取值,你会试验大量的更多的值。
从上面我们可以看到网格搜索带来一个明显的问题是,计算代价会随着超参数数量呈指数增长。因此,实际中,你通常会在一个更高维的空间中寻找超参数,随机取值,代表了你探究了更多超参数的潜在值。
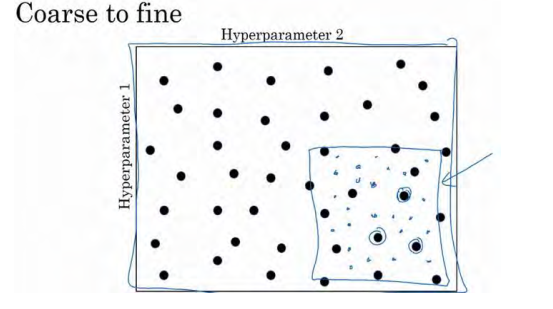
比如在二维的那个例子中,你进行了取值,也许你会发现效果最好的某个点,也许这个点周围的其他一些点效果也很好,那在接下来要做的是放大这块小区域(小蓝色方框内),然后在其中更密集得取值或随机取值,聚集更多的资源,在这个蓝色的方格中搜索,如果你怀疑这些超参数在这个区域的最优结果,那在整个的方格中进行粗略搜索后,你会知道接下来应该聚焦到更小的方格中。在更小的方格中,你可以更密集得取点。所以这种从粗到细的搜索也经常使用。
3.3. 为超参数选择合适范围
用对数标尺搜索超参数空间:在超参数范围中,随机取值可以提升你的搜索效率,但是随机取值并不是在有效值的范围内的随机均匀取值,而是选择合适的标尺,这对于探究这些超参数很重要。
整数范围:假设你要选取的隐藏单元的数量的值的数值范围是50 ~ 100中的某点,或者是层数20 ~ 40,只需要平均的随机从20 ~ 40的范围中选取数字即可。
超参数学习率:假设你要搜索的学习率的范围在0.0001 ~ 1的范围中。如果使用随机均匀取值(即数字出现在0.0001 ~ 1的范围内的概率相等,出现概率均匀)那么使用上述方法,90%的数值会落在0.1 ~ 1之间,结果就是0.1 ~ 1之间,应用了90% 的资源,而在0.0001到1之间,只有10%的搜索资源使用对数标尺搜索超参数的空间更加合理。在对数轴上均匀随机取点,这样在0.0001到0.001之间,会有更多的搜索资源可以使用。
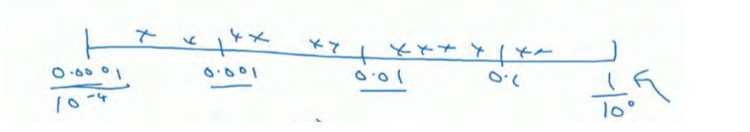
所以在 Python 中,你可以这样做,使 r=-4*np.random.rand(),然后a随机取值,a=10r,所以第一行可以得到r€[-4,0],那么a€[10-4,100],所以最左边的数字是10-4,最右边的是100.在对数坐标下取值,取最小值的对数就得到a的值,去最大值的对数就得到b的值,所以现在你在对数轴上的10a,10b区间取值,在a,b间随意均匀的选取r值,将超参数设置为10r,这就是在对数轴上取值的过程。
β指数加权平均值:假设β=0.9-0.999,对于指数加权平均值,,若β=0.9即是取10天中的平均值,若β取0.999,即是在1000个值中取指数加权平均值.。对于β=0.9-0.999,考虑1-β=0.001-0.1,所以r€[-3,1],则这是超参数的随机取值。
对于公式1/(1-β),当β接近1时,β就会对细微的变化很敏感,β=0.9000-0.905,无论β具体取什么值,对于1/(1-β)都没有很大的影响。但是当β=0.999-0.9995,1/(1-0.999)=1000表示在1000个数据中取平均,1/(1-0.9995)=2000表示在2000个数据中取平均,很接近1时看似微小的改动都会带来巨大的差异。
参考文章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号