一、矩阵
所有元素的数据类型必须一致
构建矩阵的两种方法:行数和列数的分配必须满足分配条件
方法一
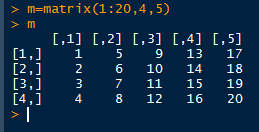
方法二
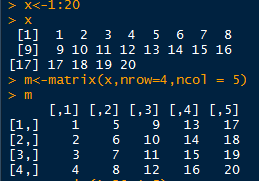
创建矩阵时,省略行或者列参数,系统会自动分配矩阵
省略列参数
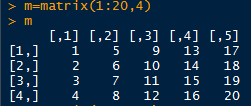
省略行参数
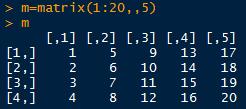
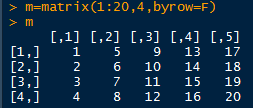
矩阵按行排列
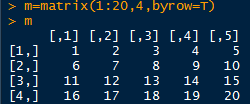
按列排列
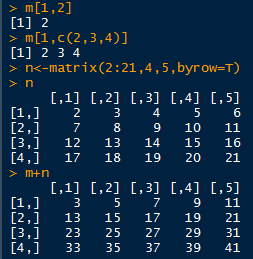
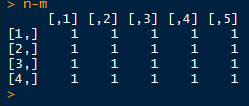
矩阵加法:对应数字相加、减、乘、除
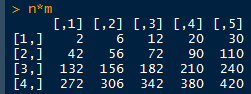
diag函数:矩阵取对角线数字

t()将矩阵进行转置

二、列表
用list定义列表
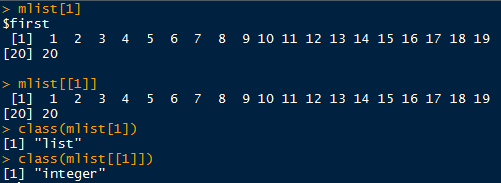
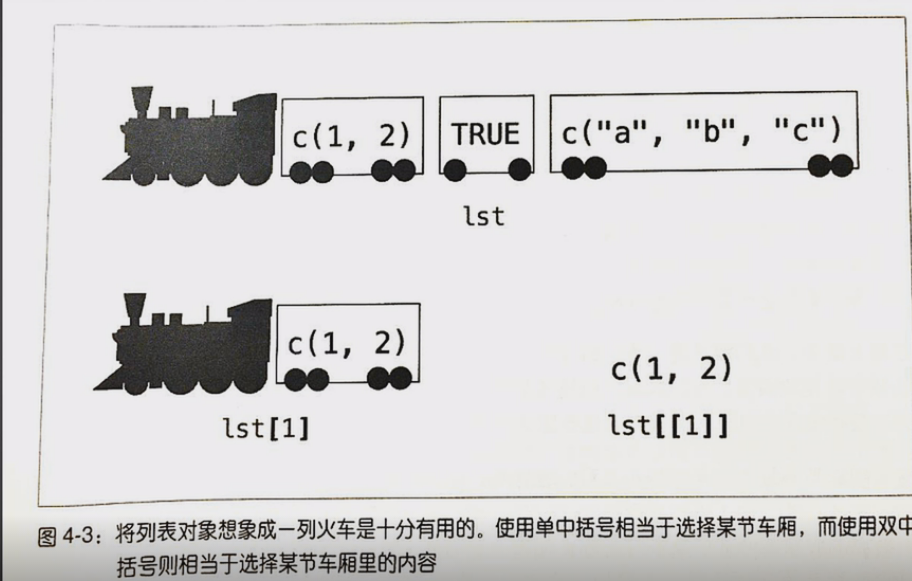
列表里含多个元素时,用list[1]和list$first得到的结果是一样的


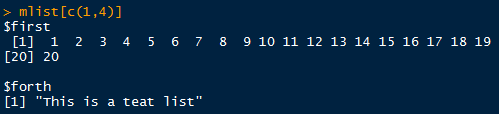
用list[]语句查看多个列表元素时,必须写成list[c(1,2)]
用list[]和list[[]]访问列表时得到的结果相同,但是数据类型不同
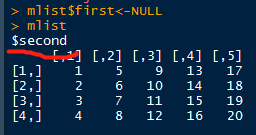
删除列表元素
将列表元素赋值为null即可
三、数据框
数据框实际上是一个列表。列表总的元素是向量,这些向量构成数据框的列,每一列必须具有
相同的长度,所以数据框是矩形结构,而且数据框的列必须命名。
1、数据框形状上很像矩阵
2、数据框是比较规则的列表
3、矩阵必须为同一数据类型
4、数据框每一列必须同一类型,每一行可以不同
创建数据框
data.frame
利用data.frame可对多个矩阵进行合并,中间用逗号隔开即可
通过索引访问数据框:
state[1] 访问数据框第一列
state[c(1,2)]访问数据框前两列
state[]和state$访问的结果一致

单、双中括号的区别
四、因子
因子,在R中名义型变量和有序型变量成为因子,factor。这些分类变量的可能值称为一个水平
level,例如good,better,best,都称为一个level,由这些水平值构成的向量称为因子。因子可理解为excel表的每一列
mtcars可视为一个数据表,cyl为mtcars的其中一列
通过R查看mtcars的cyl因子:mtcars$cyl

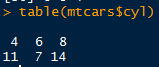
table函数进行频数统计:
table(mtcars$cyl)
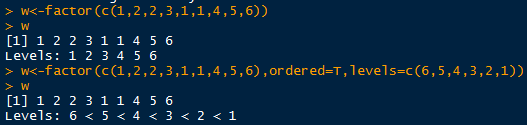
定义一个因子:
level是因子去重后的元素的集合

通过ordered和levels对因子进行设置并排序
五、缺失数据
na.rm=TRUE 是在计算的时候跳过空值,对存在空值的向量进行计算时,向量个数为向量总数-元素为空的个数

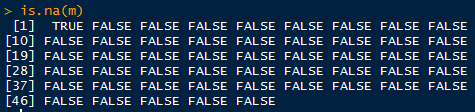
is.na函数可识别向量中的空值,空值的返回值为TRUE,其他为FALSE
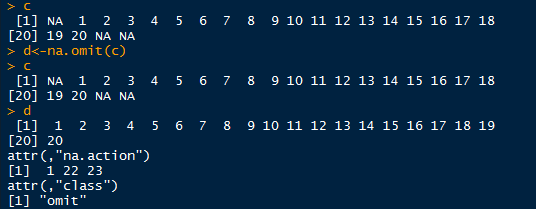
na.omit函数去空值,去空值后可进行计算
na.omit用于数据框时,将数据框中带有空值的行进行删除
除了NA(存在的值,但是不知道多少),R中还有NAN,代表不可能的值,inf代表无穷
通过is.nan和is.inf 分别识别不可能的值和无穷值
六、字符串
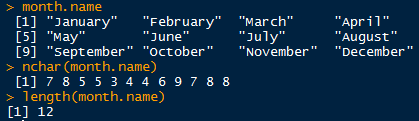
nchar('hello world') 统计字符个数,空格算一个字符

length函数统计字符串个数
paste用于连接两个字符串


用paste连接一个字符串向量和其他元素时,字符串的每一个元素和其他元素进行连接


substr字符串截取函数
三个参数分别是要截取的字符串,开始位置,结束位置

toupper函数,将字符串的字母全部改为大写

tolower全部字母小写

在全部字母小写或大写的前提下将字符串的首字母改为大写:需要熟悉正则表达式

字符串的分割
strsplit(a,b)
第一个参数为要分割的字符串,第二个参数为分割的符号
