
SQL Server 主库DML操作慢故障处理过程
从某个时间开始,Cat监控到的数据发现,正式环境的Insert 表很慢,数据库用了AlwasON高可用(1个备库做了实时同步),特别是每天早上9:00--11:00,做活动的时候,下单的insert需要1秒,有些有3秒的,而且是大量出现
很多简单的insert也有。从8月份就一直就有问题,严重影响业务 ,当时还记录了: https://www.cnblogs.com/zping/p/9510485.html
自己还特意问了同行,有没有遇到这样的情况,结果说是同步改成异步。

查看数据库监控SQL:

大量HADR_SYNC_COMMIT这样的等待事件, 网上找到的解决办法:https://www.sqlshack.com/sql-server-wait-type-hadr-sync-commit/
1,AlwasON环境下,从实时同步改成异步
2,提示网络带宽
3,将大的事务改成小事务
4,减少索引和修改的数据量
5,拆分数据库
这些解决办法 1,第一改成异步,业务部门不同意,因为有些业务是读的这个库,需要实时同步,
2,直接网络带宽,局域网的带宽限制没有用完
3,将大的事务改成小事务,业务上没有具体的操作性
4,减少索引,后来的确删除了4个觉得不太重要的索引,但是还没变化
5,拆分库,就是把表拆到其他库里
这5个办法,当前面4个办法没多大操作空间,最后只能拆分出表,让程序去修改。根据监控,有4个表拆出来后,这4个表的写入是好了,但是下单还是慢。后来说只有把下单的表独立出来就会好
也想找其他原因,也咨询了其他的同行,有没有出现HADR_SYNC_COMMIT的解决办法,结果他们没出现这样的问题。
对应比较官方的建议,我一直没有怀疑, 而且后来还怀疑是否: 1,Cat数据不准 2,网络是否不稳定 3,接的数据库insert方法有性能问题等待
怀疑这个怀疑那个引起的性能问题。
因为主库一直有监控他的性能差的sql,一旦出现性能sql,就会立马修改。主库不会有什么性能问题。对比了一下2017年8月份的监控数据,发现当时HADR_SYNC_COMMIT 的等待事件很少,
没有现在这么频繁。
是因为数据量增长的原因?
和去年的订单表数据对比,数据量增长了50%左右,有个表达到了8千万条数据,是数据量增长的原因?
如果是数据量增长的原因,那为何是在做活动的高峰才出现问题。
后来查询备库的错误日志,大量发现下列错误:

网上查:https://blogs.msdn.microsoft.com/joaol/2008/11/20/sql-server-checkpoint-problems/
是 checkpoint problem问题,这里的提交是0.18MB的速度, 这么慢。是硬盘慢,用CrystalDiskMark 6.0 工具测试了一下硬盘性能,没有特别的问题,也让人看了服务器的硬盘,都没有问题
这个文章也介绍: https://www.sqlservercentral.com/Forums/Topic1363610-2799-1.aspx
To resolve this issue, you have several options:
1. dirty fewer
pages (drop extra indexes, use compression, tune queries, etc). Fewer
dirty pages means less work each checkpoint.
2. reduce IO load overall (Add memory to reduce reads/sec, move busy tempdb to different drive, tune queries, etc)
3. increase IO write capacity (extra spindles in SAN, add SSD's, switch from Raid-5 to Raid-10, etc)
4.
smooth out checkpoint's IO load (set a really high recovery interval
and perform manual checkpoints. Don't go here until you've got a really
good handle on the perfmon counters above and can prove that this
helps.)
上面的解决办法: 就是减少IO,提示硬盘的IO能力,换成SSD的。 但根据实用的没有。因为也不可能备库换服务器。
没办法查了一下备库的监控的SQL:
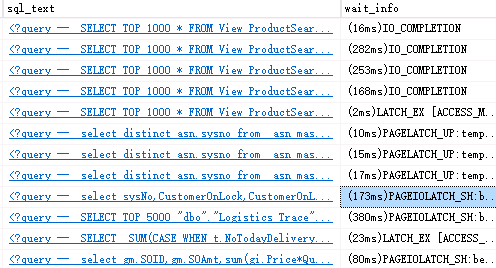
大量的: IO_COMPLETION,PAGEIOLATCH_SH,PAGEIOLATCH_EX,其中PAGEIOLATCH_SH的事件出现最多,
PAGEIOLATCH_SH: 经常发生在用户正想要去访问一个数据页面,而同时SQL Server却要把这个页面从磁盘读往内存。
PAGEIOLATCH_EX:经常发生在用户对数据页面做了修改。SQL Server要向磁盘回写的时候,意味着写的速度跟不上。
IO_COMPLETION: 这种等待类型表示数据文件中的各种同步读和写操作,这些操作与表无关,并且从事务日志中读取。
pageiolatch是为了数据的异步访问。比如说我们想读取一个page,但是它不内存中,那么sql server会首先在内存中为这个page空出一块空间,并且加上ex_latch,然后在这个page真正从disk读取到内存当中之前,其他线程不能对这片内存进行操作。因为异步操作,所以这个线程会去访问这个page,此时申请sh_latch,但是与之前的ex_latch,最终导致自己被自己阻塞了。这就是pageiolatch_sh。
这一切说明,备库的IO性能有问题。
是什么导致备库的IO性能异常?
特意查了备库的查询的SQL,有大量的查询慢的SQL,很耗CPU的:

这些SQL有些查询特别大的表,很耗CPU,直觉告诉我,这些sql有问题,后来发现这些sql也是从8点左右开始查询,是为了监控业务数据的,咨询了一下,可以停掉,还有一些有性能的sql优化了一下,有些查询如果
不读这个实时备库,就迁移到异步读库。修改了一圈后,有问题的SQL少了很多。 今天早上9;00开始的活动抢购,insert慢的问题没有出现,自己都觉得不可思议,困扰我们近1年的DML操作慢的问题解决了。
总结:
1,太教条,就依据等待事件的解决办法。
2,只关注主库的性能差SQL,未监控实时备库的性能差的SQL,实时备库有时会拖主库的后腿
3,SQL Server的错误日志的信息要时常看看。

