
SQL 大数据量的优化例子讨论
今天在itput上看了一篇文章,是讨论一个语句的优化:
原贴地址: http://www.itpub.net/viewthread.php?tid=1015964&extra=&page=1
一,发现问题
优化的语句:
CREATE TABLE aa_001
( ip VARCHAR2(28),
name VARCHAR2(10),
password VARCHAR2(30) )
select * from aa_001 where ip in (1,2,3) order by name desc;
--目前表中记录有一千多万条左右,而且in中的值个数是不确定的。
以上就是优化的需要优化的语句和情况。
不少人在后面跟帖:有的说没办法优化,有的说将IN该为EXISTS,有的说在ip上建立索引复合索引(ip,name)等等。
二,提出问题
那这样的情况,能优化吗,如何优化?今天就来讨论这个问题。
三,分析问题
1,数据量1千万多条。
2,in中的值个数是不确定
3.1 分析数据分布
这里作者没有提到ip列的数据的分布情况,目前ip列的数据分布可能有以下几种:
1,ip列(数据唯一,或者数据重复的概率很小)
2,ip列 (数据不均匀,可能有些数据重复多,有些重复少)
3,ip列 (数据分布比较均匀,数据大量重复,主要就是一些同样的数据(可能只有上万级别不同的ip数据等)
解决问题:
1,对于第一种数据分布情况,只要在ip列建立一个索引即可。这时不管表有多少行, in个数是不确定的情况下,都很快。
2,对应第二中数据分布情况,在ip列建立索引,效果不好。因为数据分布不均匀,可能有些快,有些慢
3,对应第三种数据分布情况,在ip列建立索引,速度肯定慢。
注意:这里的 order by name desc 是在取出数据后再排序的。而不是取数据前排序
对于2,3两个情况,因为都是可能需要取出大量的数据,优化器就采用表扫描(table scan),而不是索引查找(index seek) ,速度很慢,因为这时表扫描效率要优于索引查找,特别是高并发情况下,效率很低。
那对应2,3中情况,如何处理。是将in改成exists。其实在sql server 2005和oracle里的优化器在in后面数据少时,效率是一样的。这时采用一般的索引效率很低。这时如果在ip列上建立聚集索引,效率会比较高。我们在SQL server 2005中做个测试。
表:[dbo].[[zping.com]]]中有约200万条数据。包含列Userid, id, Ruleid等列。按照上面的情况查询一下类似语句:
userid in ('402881410ca47925010cb329c7670ffb','402881ba0d5dc94e010d5dced05a0008'
,'4028814111a735e90111a77fa8e30384') order by Ruleid desc
我们先看userid的数据分布情况,执行下面语句:
这时我们看看数据分布:总共有379条数据,数据两从1到15万都有,数据分布倾斜严重。下图是其中一部分。

这时如果在ip上建立非聚集索引,效率很低,而且就是强行索引扫描,效率也很低,会发现IO次数比表扫描还高。这时只能在ip上建立聚集索引。这时看看结果。
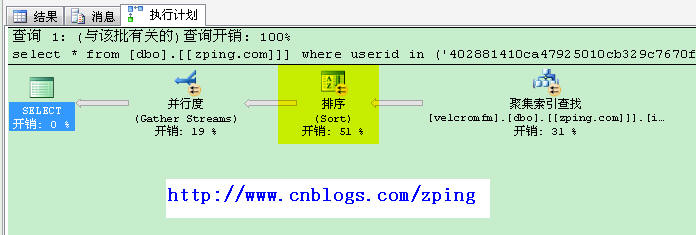
这时发现,搜索采用了(clustered index seek)聚集搜索扫描。
在看看查询返回的结果:
表 '[zping.com]'。扫描计数 8,逻辑读取 5877 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
返回15万行,才不到6千次IO。效率较高,因为这15万行要排序,查询成本里排序占了51%。当然可以建立(userid,Ruleid)复合聚集索引,提高性能,但这样做DML维护成本较高。建议不采用。
从上面的测试例子可以看出, 优化的解决办法:
数据分布为1:建立ip索引即可
数据分布为2,3:在ip列建立聚集索引。

