

一、Redis-NoSQL数据库
转载:【https://blog.csdn.net/aaronthon/article/details/81714528 】
【https://www.cnblogs.com/StanleyBlogs/p/10522254.html 】
一、首先在学习redis之间要解释一个概念,NoSQL
1、非关系型数据库《NoSQL》:
NoSQL,简单通俗一点来说就是菲关系型数据库,所谓的非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等,

优点:
1、格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
2、速度快:NoSQL可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘;
3、高扩展性;
4、成本低:NoSQL数据库部署简单,基本都是开源软件。
缺点:
1、不提供sql支持,学习和使用成本较高;
2、数据结构相对复杂,复杂查询方面稍欠。
2、关系型数据库:
系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织

优点:
1、易于维护:都是使用表结构,格式一致;
2、使用方便:SQL语言通用,可用于复杂查询;
3、复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询。
缺点:
1、读写性能比较差,尤其是海量数据的高效率读写;
2、固定的表结构,灵活度稍欠;
3、高并发读写需求,传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
二、为什么要使用NoSQL
随着互联网web2.0网站的兴起,传统的关系数据库在应对web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站以及显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展NoSQL数据库的产生就是为了解决大规模数据集合,多重复数据种类带来的挑战,尤其是大数据应用难题,包括大规模数据的存储(例如谷歌或Facebook每天为澳门的用户手机万亿比特的数据),这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展;
在最早的项目研发时期,是单机MySQL的美好年代,无非就是三层架构,dao层直接访问数据库获取数据后响应给客户即可,非常简单,但是随着时代的改变,以及互联网用户越来越多,大规模的互联网公司兴起,数据量急剧增加,再用最早的开发模式,已经完全满足不了现在时代的需求了;
所以就NoSQL(非关系型数据库)横空出世,来解决大数据量情况下提高数据库读取效率,从而提升系统性能以及客户体验;
在早期的系统,dao层直接访问数据库获取数据,但是现在时代的变迁,这样的方式在数据量大的情况下,效率非常非常的查,你无论怎么优化都是徒劳;
NoSQL出现后,犹如在数据库前面加了一堵墙,dao层先访问Redis,Redis再访问数据库;
数据库读出来的数据先存入Redis,获取数据的时候,直接从Redis中获取即可,不用再通过数据库从内存中读写;
三、选择redis的好处:
1、免费开源:
2、数据存储:数据保存在内存中,读取速率高,并且可以不定期的持久化,保证了数据的安全。
3、支持类型:相比较memcached(支持支String字符串和二进制码)支持的类型多,redis(支持String、List、set、zset、hash)
4、跨语言:支持各种语言客户端访问,如:Java、C/C++、C#、PHP、JavaScript.
5、扩展性:支持集群(主从同步)数据可以从主服务器向任意数量的从服务器同步,从服务器可以使关联其他从服务器的主服务器。
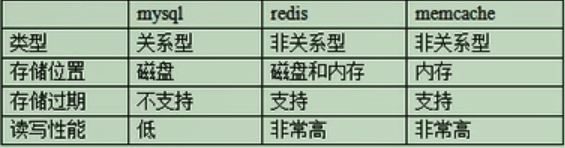
四、MySql、Memcached、Redis的比较
五、使用场景:
1、缓存:
经常查数据,发到读写速度很快的内存中,以便下次访问减少时间,减少压力,减少访问时间。
2、计数器的应用:
比如网站统计用户的点击数,两站的总浏览量等,QQ的点赞数、转发数。
3、实施防攻击系统:
例如,攻击——> 暴力破解用户密码,防——>记录IP访问次数,当次数达到一定量是锁定用户。
传统解决方案:
3.1 、存储进数据库(存在问题,登录访问量巨大高并发。)
3.2、定义一个 static Map<Object> map ; 集合,将登陆信息放入内存中(存在问题是,Map空间有限大批量就不再适用,且断电后数据丢失。)
问题:
3.3、每次查询数据慢,解决方案《多次写内存》。
3.4、断电后数据丢失,多个节点不能共用,解决方案《redis集群,容量无限大,可以共享数据,且支持过期》
4、排行榜:
营销活动的排行榜,如:总分榜、消费榜,积分榜。
5、设置应用有效期:
设置数据的有效期,到指定时间失效、解锁。
六、单机MySQL的时代:
在最早的javaweb开发应用程序中,无非就是JSP跳JSP,一个JSP处理用户并且响应,另外一个JSP发出请求,请求别的JSP,再往后,JSP跳Serclet,Serclet掉业务逻辑层的方法,业务逻辑掉数据访问层,数据访问层去请求数据库发起事物;
在90年代,一个网站的访问量都不大,用单个数据库完全可以轻松应付;
在那个时候,更多的都是静态网页,动态交互类型的网站不多;
在那个时候程序的划分也非常简单:

随着时代的变迁,数据的总量总有一天会撑破这个机器,数据库读取也就是查询效率讲会变得非常非常低;
建立索引也是会占用磁盘空间的,数据量越大,你索引越多,时间久了机器就是受不了你这样折腾了;
还有一个访问量(读写混合)一个数据库是受不了的,你读取跟插入数据都是在同一个数据库,这样数据库也是承受不了的(数据量大的情况下);
所以,问题已经列出来了,我们就要解决,要去优化这些问题,提高性能;
七、Redis + MySQL + 垂直分布:
随着数据量大,读写都是在同一台机器上,扛不住了以后呢,项目架构也就进行了改变:
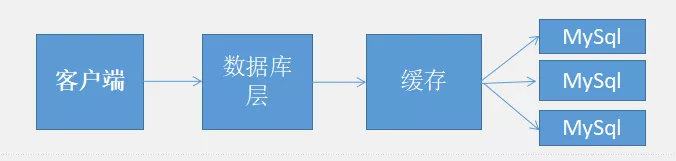
跟上一张图标对比,是只有一个MySQL数据库,并且现在我们还在MySQL前面档了一层Cache(这里理解成Redis【缓存】),换句话说,之前是DAO层直接去访问数据库,现在DAO层直接去Redis里面是不是有点像替数据库挡了一层,大家都指定,对数据库伤害比较大的就是频繁的查询,如果频繁查询的刚好还是一些固定的顺序,我们是不是可以把他摘出来放到缓存里面(Redis);
七、MySQL主从读写分离:
举个例子,现在是一台机器一个数据库,我现在要求一台机器变成五个数据库,那么,其中的一台数据库作为主库,另外四台作为从库,我插入一条数据是给主库,主库这个时候需要同步另外四个从库,比如我主库里面有 a b c,这个时候我向里面查一个d,这个时候主库就需要向另外四个从库也添加一个d来保持同步;
也可以理解为主从复制,主表里面有什么东西,我从表需要迅速的复制粘贴进来;
读写分离,顾名思义,读就是查询,写就是增 删 改,在我们自己做练习的时候,增删改查一直都是同一台机器或同一个数据库,但是在实际开发当中,这种情况是不允许的,因为非常影响效率;
所以又有一个数据库是只做查询,另外一个数据库是只做增 删 改,这就是读写分离,所以就造成了下面这张图:
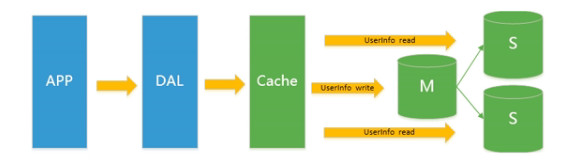
由于数据库的写入压力增加,Redis只能缓解数据库的读取压力,读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从赋值技术来达到读写分离,提高读写性能和读库的可扩展性;
之前是光在mysql前面档了一个缓存,现在,在缓存背后又出现了数据库的拆分,变成了读写分离了,M代表主表,S代表从表;
就是,对于一个数据库的信息,写的操作都放到M(主)库了,读的操作都去从库去度,这样的话,存载的数据被分割以后,就可以大大的缓解数据库的压力;
八、分库分表 + 水平拆分 + MySQL集群:
经过前几次的拆分,改变,读写分离,往后发现又扛不住了,这个时候,集群就出来了;
在Redis的高速缓存,MySQL的主从复制,读写分离的基础上,这时,MySQL主库的读写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁,在高并发下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB引擎代替MyISAM;
同时,开始流行使用分表分库来缓解写压力和数据库增长的扩展问题,这个时候,分表分库就成了一个热门的技术,是面试的热门问题也是业界讨论的热门技术问题;
也就是在这个时候MySQL推出了还不太稳定的表分区,这也给技术实力一般的公司带来了希望,虽然MySQL推出MySQL Cluster集群,但性能也不能很好满足互联网的需求,只是在高可靠性上提供非常大的保障;

我们可以发现,以上图就用了数据库的集群,三个数据库各司其职,每个数据库存放的是整个项目数据的3分之1,频繁查询的数据库单独列出一个库,经常不用的数据也独立出来放在一个数据库中;
九、Redis为何会这么快
1、Redis是纯内存操作,需要的时候需要我们手动持久化到硬盘中
2、Redis是单线程,从而避开了多线程中上下文频繁切换的操作。
3、Redis数据结构简单、对数据的操作也比较简单
4、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求
5、使用多路I/O复用模型,非阻塞I/O

