
Hadoop平台搭建(VMware、CentOS)
1、硬件平台
- Intel(R) Xeon(R) CPU E7-4850 v3 @ 2.20GHz 2.19GHz(4处理器)
- 安装内存384GB
2、软件平台
- Windows Server 2012 R2 Standard Edition, 64-bit (Build 9600) 6.3.9600
- VMware Workstation 10.0.1 build-1379776
3、虚拟平台(基于硬件自由配置)
- 虚拟CPU-Intel(R) Xeon(R) CPU E7-4850 v3 @ 2.20GHz(双芯八核)
- 虚拟内存-8GB
- 镜像文件-CentOS-6.5-x86_64-bin-DVD1.iso
4、虚拟集群(均默认安装、IP地址由VMware分配)
| IP地址 | 计算机名 | root密码 | 用户名 | 密码 |
| 192.168.222.134 | Master.Hadoop | master | Administrator | admin |
| 192.168.222.135 | Slave1.Hadoop | slave1 | Administrator | admin |
| 192.168.222.136 | Slave2.Hadoop | slave2 | Administrator | admin |
| 192.168.222.137 | Slave3.Hadoop | slave3 | Administrator | admin |
=======================此后所有操作均以root用户权限执行且需网络访问正常========================
5、 配置JDK(于所有主机)
该镜像中自带有openjdk的最小化版本(/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.45.x86_64/),该版本只有运行时环境(jre),无法满足Hadoop开发要求,需要更新。
①卸载自带版本
yum -y remove java-1.7.0-openjdk*
yum -y remove tzdata-java.noarch
②确认卸载完毕
yum list installed | grep java
③安装新版本jdk
yum list java* //先查看所有可用版本
yum -y install java-1.7.0-openjdk*
④查看已安装版本
java -version
⑤安装完毕
位置:/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.131.x86_64/
⑥配置JAVA环境变量
vi /etc/profile
追加以下:
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.131.x86_64
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
⑦使配置生效
source /etc/profile
⑧查看是否生效
env //查看所有环境变量
6、配置SSH无密码登录(①、②于所有主机,③-⑤于Master)
①开启SSH登录
vi /etc/ssh/sshd_config
找到并去掉以下两行的注释
#RSAAuthentication yes
#PubkeyAuthentication yes
②生成公钥RSA key
ssh-keygen -t rsa //不输入密码,一直回车
③合并公钥到authorized_keys文件
cd /root/.ssh
cat id_rsa.pub >> authorized_keys
ssh root@192.168.222.135 cat ~/.ssh/id_rsa.pub >> authorized_keys //会要求输入root密码
ssh root@192.168.222.136 cat ~/.ssh/id_rsa.pub >> authorized_keys //会要求输入root密码
ssh root@192.168.222.137 cat ~/.ssh/id_rsa.pub >> authorized_keys //会要求输入root密码
④将Master上的authorized_keys、known_hosts复制到Slave服务器的/root/.ssh目录中
scp authorized_keys root@192.168.222.135:/root/.ssh
scp known_hosts root@192.168.222.135:/root/.ssh
scp authorized_keys root@192.168.222.136:/root/.ssh
scp known_hosts root@192.168.222.136:/root/.ssh
scp authorized_keys root@192.168.222.137:/root/.ssh
scp known_hosts root@192.168.222.137:/root/.ssh
⑤配置成功,ssh登录测试
ssh root@192.168.222.135
7、安装Hadoop 2.7.3(于Master主机)
②在/home/下建立hadoop文件夹
mkdir /home/hadoop
③解压文件
tar -zxvf hadoop-2.7.3.tar.gz
④在hadoop-2.7.3目录下建立子目录
cd /home/hadoop/hadoop-2.7.3
mkdir hdfs
cd hdfs
mkdir data
mkdir name
mkdir temp
8、配置Hadoop(于Master主机)
操作目录:/home/hadoop/hadoop-2.7.3/etc/hadoop
①配置core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.222.134:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/hadoop-2.7.3/hdfs/temp</value> </property> <property> <name>io.file.buffer.size</name> <value>131702</value> </property> </configuration>
②配置hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/hadoop-2.7.3/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/hadoop-2.7.3/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.222.134:9001</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property>
<!--下一项可能非必要 --> <property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>false</value> </property> </configuration>
③配置mapred-site.xml(先依照mapred-site.xml.template创建mapred-site.xml,再进行修改)
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.222.134:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>192.168.222.134:19888</value> </property> </configuration>
④配置yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>192.168.222.134:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>192.168.222.134:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>192.168.222.134:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>192.168.222.134:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>192.168.222.134:8088</value> </property> <!-- <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>768</value> </property> --> <!-- Site specific YARN configuration properties --> </configuration>
⑤配置slaves文件
vi /home/hadoop/hadoop-2.7.3/etc/hadoop/slaves
清空并添加:
192.168.222.135
192.168.222.136
192.168.222.137
⑥将Hadoop配置到Slave集群中
scp -r /home/hadoop root@192.168.222.135:/home
scp -r /home/hadoop root@192.168.222.136:/home
scp -r /home/hadoop root@192.168.222.137:/home
⑦配置Hadoop环境变量(于所有主机)
vi /etc/profile
追加以下:
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
保存退出后执行:
source /etc/profile
可查看环境变量是否生效:
env
9、配置hosts(于所有主机)
vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 192.168.222.134 Master.Hadoop 192.168.222.135 Slave1.Hadoop 192.168.222.136 Slave2.Hadoop 192.168.222.137 Slave3.Hadoop ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10、防火墙配置(于所有主机)
service iptables status //查看防火墙状态
service iptables stop //关闭防火墙
Hadoop启动前保证集群所有主机防火墙为关闭状态
11、启动Hadoop(于Master主机)
操作目录为:/home/hadoop/hadoop-2.7.3
①重置namenode
bin/hdfs namenode -format
②启动Hadoop
sbin/start-all.sh
③查看进程启动情况
jps //Master上的结果

jps //Slave上的结果
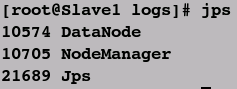
④查看hdfs虚拟磁盘信息(确认Hadoop是否正常启动)
bin/./hadoop dfsadmin -report
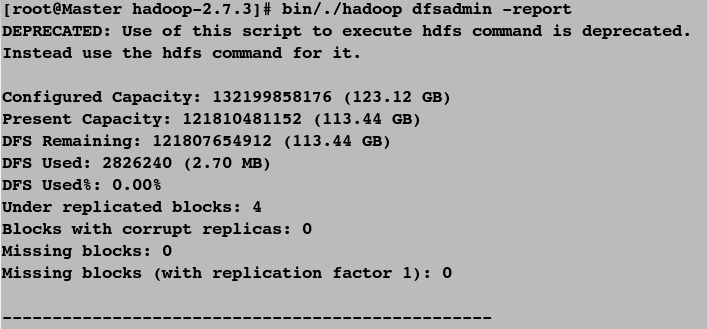
还有更多信息未截图...
⑤在浏览器中查看启动情况
http://192.168.222.134:50070
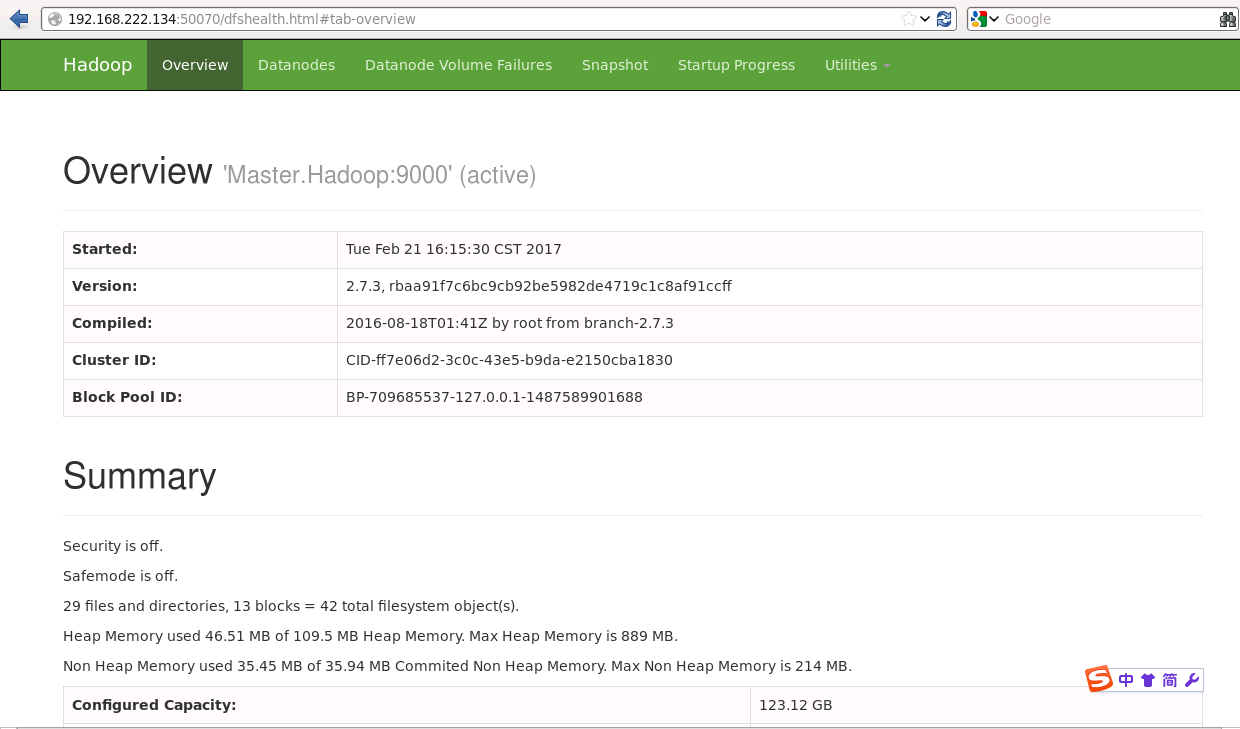
还有更多信息未截图...
⑥关闭hadoop
sbin/stop-all.sh
12、第一个mapreduce任务——wordcount
操作目录为:Master:/home/hadoop/hadoop-2.7.3
①在hdfs上建立测试目录
bin/hdfs dfs -mkdir -p /data/input
②添加测试文本(README.txt)
hdfs dfs -put README.txt /data/input
③确认测试文本存在
bin/hdfs dfs -ls /data/input

④执行wordcount任务
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /data/input /data/output/result
⑤查看执行结果
hdfs dfs -cat /data/output/result/part-r-00000
也可以转移到本地文件中查看结果:
hdfs dfs -cat /data/output/result/part-r-00000 >> result.txt
gedit result.txt
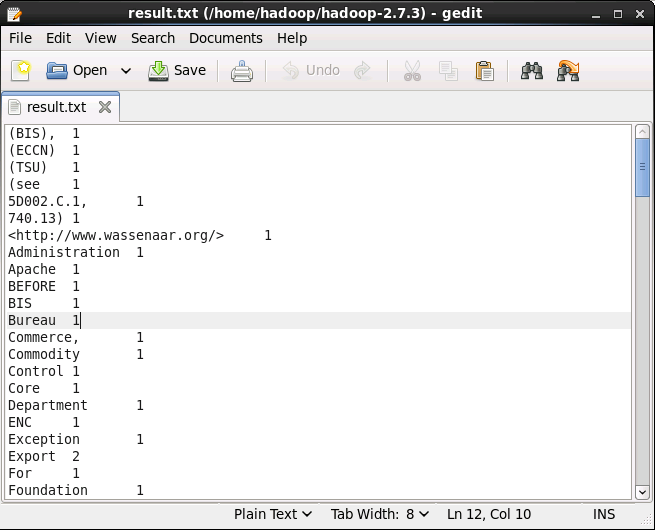
还有更多信息未截图...
⑥在浏览器中查看mapreduce任务
http://192.168.222.134:8088/cluster


******************************************************************************************************
******************************************************************************************************
异常处理:
1、出了异常一定要记得看日志,可以在浏览器上看(http://192.168.222.134:50070),也可以直接去找日志文件(/home/hadoop/hadoop-2.7.3/logs)
2、启动后jps查看进程,发现Slave上datanode启动失败(或者显示有datanode进程但实际上日志已记录错误)。这种情况一般是由于多次执行11-①的指令导致Master和Slave的clusterID版本不一致。可以分别在Master:/home/hadoop/hadoop-2.7.3/hdfs/name/current/VERSION和Slave:/home/hadoop/hadoop-2.7.3/hdfs/data/current/VERSION中找到clusterID信息,确认是否不一致。解决方案是,关闭hadoop后,将所有Slave:/home/hadoop/hadoop-2.7.3/hdfs/data下的文件删除,之后重新启动hadoop。
3、执行11-④指令查看HDFS信息时,发现Configured Capacity: 0 (0 KB) Present Capacity: 0 (0 KB) DFS Remaining: 0,类似以下:

此时需要检查每台主机的/etc/hosts文件是否配置正确,因为通常是由于主机间无法识别hostname而导致通信错误。只要按照步骤10配置应该不会出现这类错误。
参考链接Top 5(排名分先后):
1、搭建hadoop环境,CentOS6.5安装Hadoop2.7.3完整流程 - u014019693的博客 - 博客频道 - CSDN.NET
2、Hadoop2.7.3完全分布式集群搭建和测试 - 如果一切重来 - 博客频道 - CSDN.NET
3、hadoop 2.7.3 启动Hadoop HDFS时的“Incompatible clusterIDs” - kamereon的博客 - 博客频道 - CSDN.NET
5、ubuntu - Hadoop: java.net.UnknownHostException: hadoop-slave-2 - Stack Overflow

