
Spark MLlib编程API入门系列之特征选择之向量选择(VectorSlicer)
不多说,直接上干货!
特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择)。
VectorSlicer用于从原来的特征向量中切割一部分,形成新的特征向量,比如,原来的特征向量长度为10,我们希望切割其中的5~10作为新的特征向量,使用VectorSlicer可以快速实现。
理论,见
机器学习概念之特征选择(Feature selection)之VectorSlicer算法介绍
完整代码
VectorSlicer .scala
package zhouls.bigdata.DataFeatureSelection import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.ml.attribute.{Attribute, AttributeGroup, NumericAttribute} import org.apache.spark.ml.feature.VectorSlicer//引入ml里的特征选择的VectorSlicer import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.sql.Row import org.apache.spark.sql.types.StructType /** * By zhouls */ object VectorSlicer extends App { val conf = new SparkConf().setMaster("local").setAppName("VectorSlicer") val sc = new SparkContext(conf) val sqlContext = new org.apache.spark.sql.SQLContext(sc) import sqlContext.implicits._ //构造特征数组 val data = Array(Row(Vectors.dense(-2.0, 2.3, 0.0))) //为特征数组设置属性名(字段名),分别为f1 f2 f3 val defaultAttr = NumericAttribute.defaultAttr val attrs = Array("f1", "f2", "f3").map(defaultAttr.withName) val attrGroup = new AttributeGroup("userFeatures", attrs.asInstanceOf[Array[Attribute]]) //构造DataFrame val dataRDD = sc.parallelize(data) val dataset = sqlContext.createDataFrame(dataRDD, StructType(Array(attrGroup.toStructField()))) print("原始特征:") dataset.take(1).foreach(println) //构造切割器 var slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features") //根据索引号,截取原始特征向量的第1列和第3列 slicer.setIndices(Array(0,2)) print("output1: ") slicer.transform(dataset).select("userFeatures", "features").first() //根据字段名,截取原始特征向量的f2和f3 slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features") slicer.setNames(Array("f2","f3")) print("output2: ") slicer.transform(dataset).select("userFeatures", "features").first() //索引号和字段名也可以组合使用,截取原始特征向量的第1列和f2 slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features") slicer.setIndices(Array(0)).setNames(Array("f2")) print("output3: ") slicer.transform(dataset).select("userFeatures", "features").first() }
输出结果是
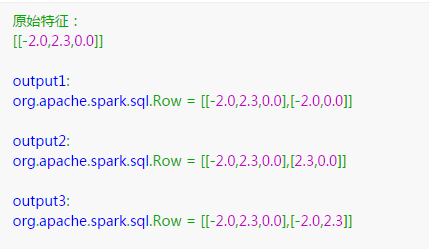
python语言来编写
from pyspark.ml.feature import VectorSlicer from pyspark.ml.linalg import Vectors from pyspark.sql.types import Row df = spark.createDataFrame([ Row(userFeatures=Vectors.sparse(3, {0: -2.0, 1: 2.3}),), Row(userFeatures=Vectors.dense([-2.0, 2.3, 0.0]),)]) slicer = VectorSlicer(inputCol="userFeatures", outputCol="features", indices=[1]) output = slicer.transform(df) output.select("userFeatures", "features").show()
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

