
Flume启动时报错Caused by: java.lang.InterruptedException: Timed out before HDFS call was made. Your hdfs.callTimeout might be set too low or HDFS calls are taking too long.解决办法(图文详解)
前期博客
Flume自定义拦截器(Interceptors)或自带拦截器时的一些经验技巧总结(图文详解)
问题详情
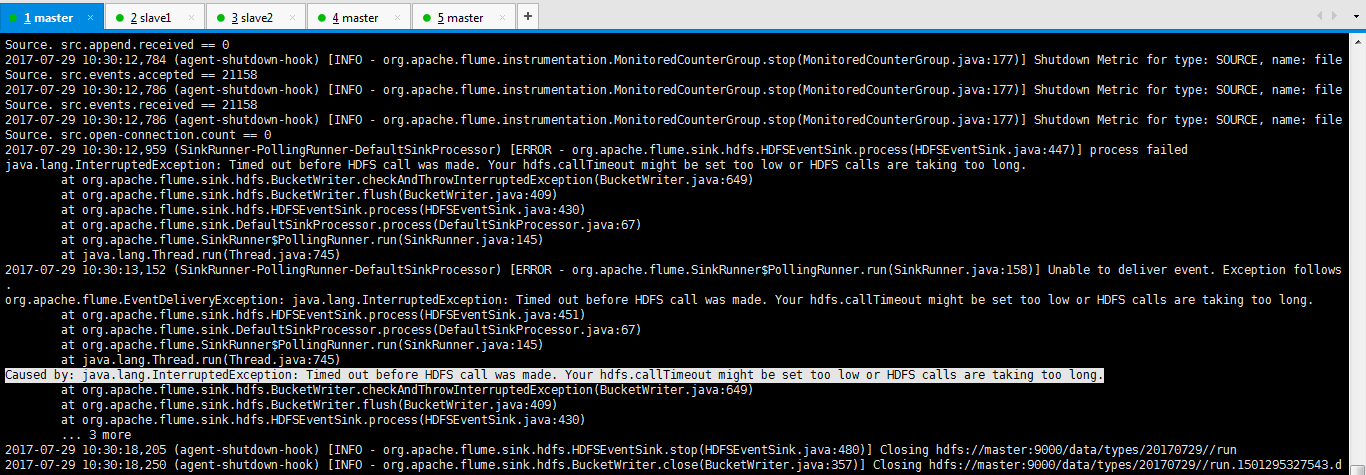

2017-07-29 10:30:12,784 (agent-shutdown-hook) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.stop(MonitoredCounterGroup.java:177)] Shutdown Metric for type: SOURCE, name: fileSource. src.events.accepted == 21158 2017-07-29 10:30:12,786 (agent-shutdown-hook) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.stop(MonitoredCounterGroup.java:177)] Shutdown Metric for type: SOURCE, name: fileSource. src.events.received == 21158 2017-07-29 10:30:12,786 (agent-shutdown-hook) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.stop(MonitoredCounterGroup.java:177)] Shutdown Metric for type: SOURCE, name: fileSource. src.open-connection.count == 0 2017-07-29 10:30:12,959 (SinkRunner-PollingRunner-DefaultSinkProcessor) [ERROR - org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:447)] process failed java.lang.InterruptedException: Timed out before HDFS call was made. Your hdfs.callTimeout might be set too low or HDFS calls are taking too long. at org.apache.flume.sink.hdfs.BucketWriter.checkAndThrowInterruptedException(BucketWriter.java:649) at org.apache.flume.sink.hdfs.BucketWriter.flush(BucketWriter.java:409) at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:430) at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67) at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145) at java.lang.Thread.run(Thread.java:745) 2017-07-29 10:30:13,152 (SinkRunner-PollingRunner-DefaultSinkProcessor) [ERROR - org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:158)] Unable to deliver event. Exception follows. org.apache.flume.EventDeliveryException: java.lang.InterruptedException: Timed out before HDFS call was made. Your hdfs.callTimeout might be set too low or HDFS calls are taking too long. at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:451) at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67) at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145) at java.lang.Thread.run(Thread.java:745) Caused by: java.lang.InterruptedException: Timed out before HDFS call was made. Your hdfs.callTimeout might be set too low or HDFS calls are taking too long. at org.apache.flume.sink.hdfs.BucketWriter.checkAndThrowInterruptedException(BucketWriter.java:649) at org.apache.flume.sink.hdfs.BucketWriter.flush(BucketWriter.java:409) at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:430) ... 3 more
这句话,说的很明显。
你的hdfs.calltimeout可能设置得太低或HDFS需要花费太长的时间。
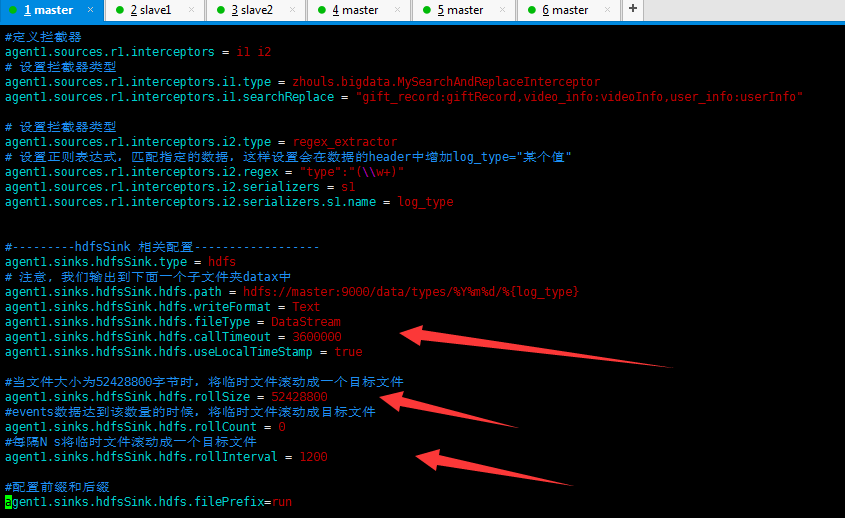
我的是
#---------hdfsSink 相关配置------------------ agent1.sinks.hdfsSink.type = hdfs # 注意, 我们输出到下面一个子文件夹datax中 agent1.sinks.hdfsSink.hdfs.path = hdfs://master:9000/data/types/%Y%m%d/%{log_type} agent1.sinks.hdfsSink.hdfs.writeFormat = Text agent1.sinks.hdfsSink.hdfs.fileType = DataStream agent1.sinks.hdfsSink.hdfs.callTimeout = 3600000 agent1.sinks.hdfsSink.hdfs.useLocalTimeStamp = true #当文件大小为52428800字节时,将临时文件滚动成一个目标文件 agent1.sinks.hdfsSink.hdfs.rollSize = 52428800 #events数据达到该数量的时候,将临时文件滚动成目标文件 agent1.sinks.hdfsSink.hdfs.rollCount = 0 #每隔N s将临时文件滚动成一个目标文件 agent1.sinks.hdfsSink.hdfs.rollInterval = 1200 #配置前缀和后缀 agent1.sinks.hdfsSink.hdfs.filePrefix=run
这个大家,可以还改大些。
agent1.sinks.hdfsSink.hdfs.callTimeout = 7200000
hdfs.sinks.fs.hdfs.rollInterval=21600
hdfs.sinks.fs.hdfs.rollSize=8589934592
为何这两个设置这么大。超时出现问题正常的设置小一点,根据情况自己调试下。
建议初始值:
hdfs.sinks.fs.hdfs.rollInterval=10
hdfs.sinks.fs.hdfs.rollSize=0
依次:
20
40
80
200
等值。
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步