
Flume Source官网剖析(博主推荐)
不多说,直接上干货!

一切来源于flume官网
http://flume.apache.org/FlumeUserGuide.html

- Avro Source
- Thrift Source
- Exec Source
- JMS Source
- Spooling Directory Source
- Taildir Source
- Twitter 1% firehose Source (experimental)
- Kafka Source
- NetCat Source
- Sequence Generator Source
- Syslog Sources
- HTTP Source
- Stress Source
- Legacy Sources
- Custom Source
- Scribe Source
Avro Source

官网给的例子是
a1.sources = r1 a1.channels = c1 a1.sources.r1.type = avro a1.sources.r1.channels = c1 a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 4141
而我们常用的一般是,
agent1.sources = avro-source1
agent1.channels = ch1
#Define and configure an Spool directory source
agent1.sources.avro-source1.channels=ch1
agent1.sources.avro-source1.type=avro
agent1.sources.avro-source1.bind=0.0.0.0
agent1.sources.avro-source1.port=4141
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.djt.flume.interceptor.BehaviorIterceptor$BehaviorIterceptorBuilder
Thrift Source

Exec Source

JMS Source

Spooling Directory Source(常用)
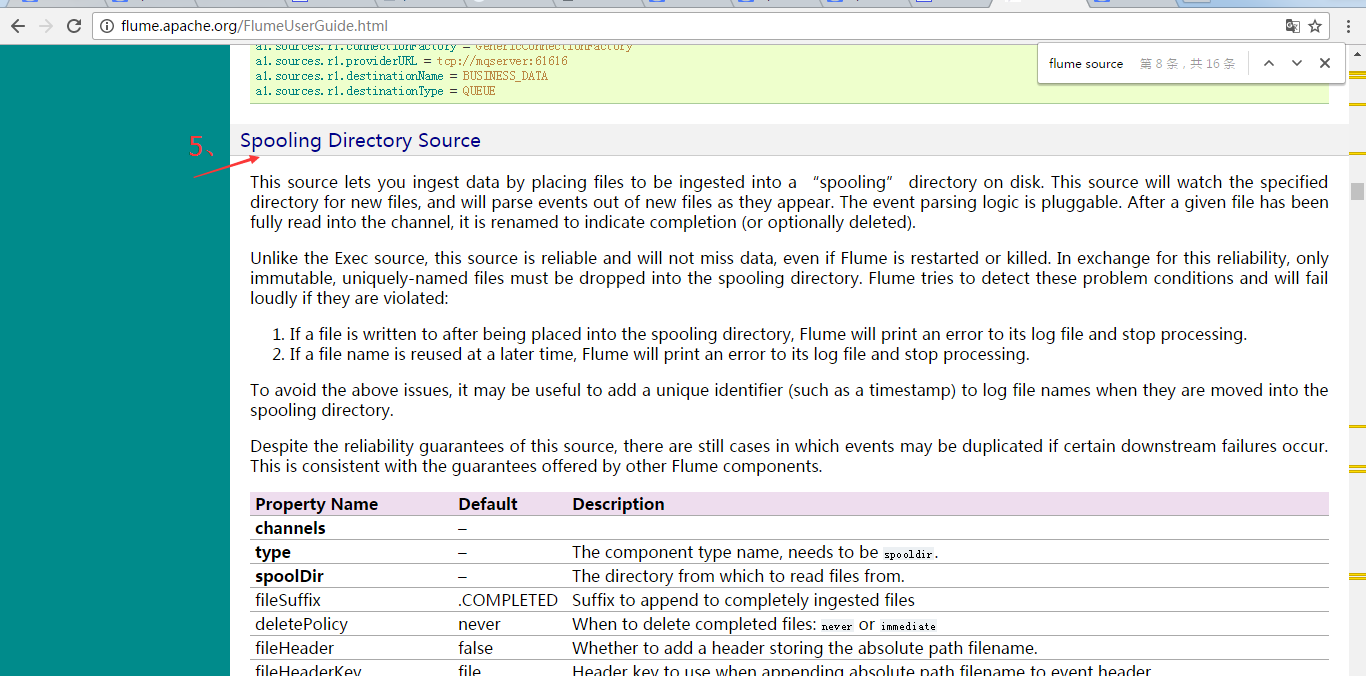
官网上给的参考例子是
a1.channels = ch-1 a1.sources = src-1 a1.sources.src-1.type = spooldir a1.sources.src-1.channels = ch-1 a1.sources.src-1.spoolDir = /var/log/apache/flumeSpool a1.sources.src-1.fileHeader = true
而我们常用的一般是,
agent1.sources = spool-source1 agent1.channels = ch1 #Define and configure an Spool directory source agent1.sources.spool-source1.channels=ch1 agent1.sources.spool-source1.type=spooldir agent1.sources.spool-source1.spoolDir=/home/hadoop/data/flume/sqooldir agent1.sources.spool-source1.ignorePattern=event(_\d{4}\-d{2}\-d{2}\_d{2}\_d{2})?\.log(\.COMPLETED)? agent1.sources.spool-source1.deserializer.maxLineLength=10240
Taildir Source

Twitter 1% firehose Source

Kafka Source(常用)

官网给的例子是
Example for topic subscription by comma-separated topic list.
tier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource tier1.sources.source1.channels = channel1 tier1.sources.source1.batchSize = 5000 tier1.sources.source1.batchDurationMillis = 2000 tier1.sources.source1.kafka.bootstrap.servers = localhost:9092 tier1.sources.source1.kafka.topics = test1, test2 tier1.sources.source1.kafka.consumer.group.id = custom.g.id
Example for topic subscription by regex
tier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource tier1.sources.source1.channels = channel1 tier1.sources.source1.kafka.bootstrap.servers = localhost:9092 tier1.sources.source1.kafka.topics.regex = ^topic[0-9]$ # the default kafka.consumer.group.id=flume is used
具体官网里,还给了Security and Kafka Source、TLS and Kafka Source、Kerberos and Kafka Source。自行去看吧
NetCat Source

Sequence Generator Source

Syslog Sources

Syslog TCP Source

Multiport Syslog TCP Source

Syslog UDP Source

HTTP Source

官网还提供了JSONHandler、BlobHandler。这里不多说,自行去看吧
Stress Source

Legacy Sources

Avro Legacy Source

Thrift Legacy Source

Custom Source

Scribe Source

大家自己去看,罗列出来,是让大家,不要局限于博客本身,眼光要放宽和多看官网,一切来源于官网。
对于大数据无论是各种开源项目,看官网是学习的最好办法,再加上他人的中文博客。不要觉得英文恐惧,专业英语也就那样!变成高手和大牛,加油吧,zhouls!
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

