

Spark SQL概念学习系列之Spark SQL概述
很多人一个误区,Spark SQL重点不是在SQL啊,而是在结构化数据处理!
Spark SQL结构化数据处理
概要:
01 Spark SQL概述
02 Spark SQL基本原理
03 Spark SQL编程
04 分布式SQL引擎
05 用户自定义函数
06 性能调优
Spark SQL概述
Spark SQL是什么?
Spark SQL is a Spark module for structured data processing
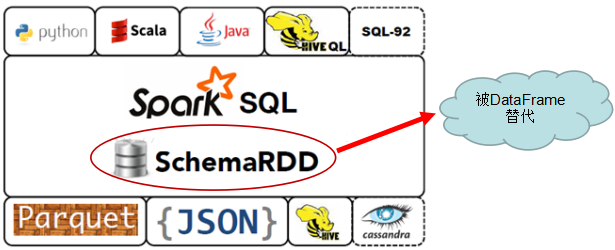
特别注意:1.3.0 及后续版本中,SchemaRDD 已经被DataFrame 所取代。所以,我们以后的重点是DataFrame,各位博友们!
何为结构化数据
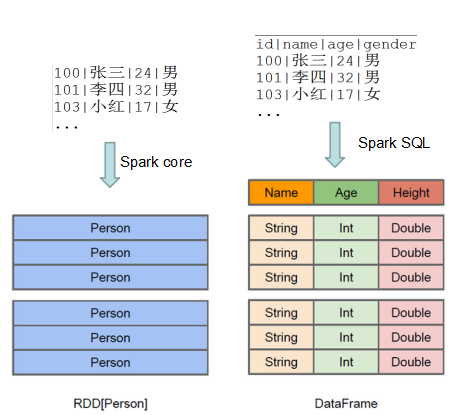
SparkSQL 与 Spark Core的关系
Spark SQL构建在Spark Core之上,专门用来处理结构化数据(不仅仅是SQL)。
Spark SQL在Spark Core的基础上针对结构化数据处理进行很多优化和改进,
简单来讲:
Spark SQL 支持很多种结构化数据源,可以让你跳过复杂的读取过程,轻松从各种数据源中读取数据
当你使用SQL查询这些数据源中的数据并且只用到了一部分字段时,SparkSQL可以智能地只扫描这些用到的字段,而不是像SparkContext.hadoopFile中那样简单粗暴地扫描全部数据.
Spark SQL前世今生:由Shark发展而来

Spark SQL前世今生:可以追溯到Hive
由facebook 开源, 最初用于解决海量结构化的日志数据统计问题的ETL(Extraction-Transformation-Loading) 工具
构建在Hadoop上的数据仓库平台,设计目标是使得可以用传统SQL操作Hadoop上的数据,让熟悉SQL编程的人员也能拥抱Hadoop。
1.使用HQL 作为查询接口
2.使用HDFS 作为底层存储
3.使用MapRed 作为执行层
现已成为Hadoop平台上的标配。
曾在一段时间之内成为SQL on Hadoop的唯一选择!
http://hive.apache.org/ https://cwiki.apache.org/confluence/display/Hive/Home https://cwiki.apache.org/confluence/display/Hive/LanguageManual
Spark SQL前世今生:Hive 到 Shark(在Hive上做改进)
背景:Spark出现之后,社区开始考虑基于Spark提供SQL解决方案,这就是诞生的背景
基于Hive的代码库,修改了Hive的后端引擎使其运行在Spark上(在Hive上做改进)。

导致社区放弃Shark的主要原因:
和Spark程序的集成有诸多限制
Hive的优化器不是为Spark而设计的,计算模型的不同,使得Hive的优化器来优化Spark程序遇到了瓶颈。
Spark SQL前世今生:Shark 到 Spark SQL(彻底摆脱但是兼容Hive)

Spark SQL前世今生:Hive 到 Hive on Spark
Spark SQL诞生的同时,Hive还在继续发展,一些深耕Hive的用户意识到迁移还是需要成本的,于是Hive社区提出了Hive on Spark的计划
从Hive 1.1+开始可用,还在发展过程中
Spark SQL前世今生

作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!
