
mahout-distribution-0.9.tar.gz的安装的与配置、启动与运行自带的mahout算法
不多说,直接上干货!
首先,别在windows下搭建什么,安装什么Cygwin啊!直接在linux,对于企业里推荐用CentOS6.5,在学校里用Ubuntu。
Mahout安装所需软件清单:
软件 版本 说明
操作系统 CentOS6.5 64位
JDK jdk1.7.0_79
Hadoop 2.6.0
Mahout mahout-distribution-0.8
为什么采用这个版本,而不是0.9及其以后的版本,是因为差别有点大,比如fpg关联规则算法。以及网上参考资料少
说在前面的话,
关于Mahout的安装配置,这里介绍两种方式:其一,下载源码(直接下载源码或者通过svn下载源码都可以),然后使用Maven进行编译;其二,下载完整包进行解压缩。这里我使用的是完整包进行解压缩安装。
一、 mahout-distribution-0.8.tar.gz的下载
http://archive.apache.org/dist/mahout/0.8/
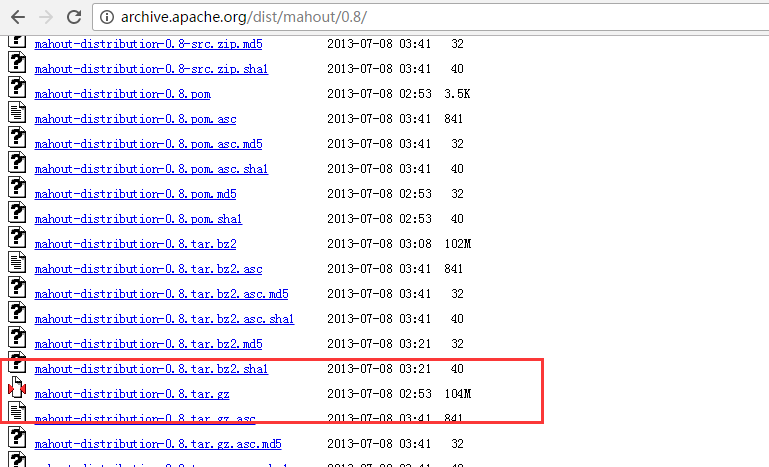
我这里,以稳定版本mahout-0.9为例
当然,这里也可以使用wget命令在线下载,很简单,不多说。
二、 mahout-distribution-0.8.tar.gz的安装
1、先新建好目录
我一般喜欢在/usr/loca/下新建
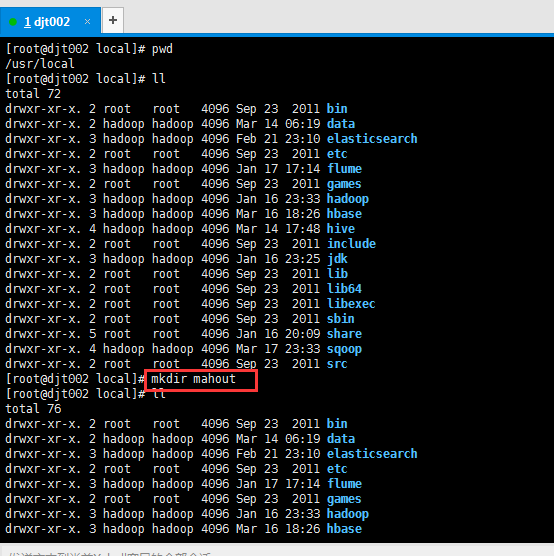

[root@djt002 local]# pwd /usr/local [root@djt002 local]# ll total 72 drwxr-xr-x. 2 root root 4096 Sep 23 2011 bin drwxr-xr-x. 2 hadoop hadoop 4096 Mar 14 06:19 data drwxr-xr-x. 3 hadoop hadoop 4096 Feb 21 23:10 elasticsearch drwxr-xr-x. 2 root root 4096 Sep 23 2011 etc drwxr-xr-x. 3 hadoop hadoop 4096 Jan 17 17:14 flume drwxr-xr-x. 2 root root 4096 Sep 23 2011 games drwxr-xr-x. 3 hadoop hadoop 4096 Jan 16 23:33 hadoop drwxr-xr-x. 3 hadoop hadoop 4096 Mar 16 18:26 hbase drwxr-xr-x. 4 hadoop hadoop 4096 Mar 14 17:48 hive drwxr-xr-x. 2 root root 4096 Sep 23 2011 include drwxr-xr-x. 3 hadoop hadoop 4096 Jan 16 23:25 jdk drwxr-xr-x. 2 root root 4096 Sep 23 2011 lib drwxr-xr-x. 2 root root 4096 Sep 23 2011 lib64 drwxr-xr-x. 2 root root 4096 Sep 23 2011 libexec drwxr-xr-x. 2 root root 4096 Sep 23 2011 sbin drwxr-xr-x. 5 root root 4096 Jan 16 20:09 share drwxr-xr-x. 4 hadoop hadoop 4096 Mar 17 23:33 sqoop drwxr-xr-x. 2 root root 4096 Sep 23 2011 src [root@djt002 local]# mkdir mahout [root@djt002 local]# ll total 76 drwxr-xr-x. 2 root root 4096 Sep 23 2011 bin drwxr-xr-x. 2 hadoop hadoop 4096 Mar 14 06:19 data drwxr-xr-x. 3 hadoop hadoop 4096 Feb 21 23:10 elasticsearch drwxr-xr-x. 2 root root 4096 Sep 23 2011 etc drwxr-xr-x. 3 hadoop hadoop 4096 Jan 17 17:14 flume drwxr-xr-x. 2 root root 4096 Sep 23 2011 games drwxr-xr-x. 3 hadoop hadoop 4096 Jan 16 23:33 hadoop drwxr-xr-x. 3 hadoop hadoop 4096 Mar 16 18:26 hbase drwxr-xr-x. 4 hadoop hadoop 4096 Mar 14 17:48 hive drwxr-xr-x. 2 root root 4096 Sep 23 2011 include drwxr-xr-x. 3 hadoop hadoop 4096 Jan 16 23:25 jdk drwxr-xr-x. 2 root root 4096 Sep 23 2011 lib drwxr-xr-x. 2 root root 4096 Sep 23 2011 lib64 drwxr-xr-x. 2 root root 4096 Sep 23 2011 libexec drwxr-xr-x 2 root root 4096 Apr 7 00:21 mahout drwxr-xr-x. 2 root root 4096 Sep 23 2011 sbin drwxr-xr-x. 5 root root 4096 Jan 16 20:09 share drwxr-xr-x. 4 hadoop hadoop 4096 Mar 17 23:33 sqoop drwxr-xr-x. 2 root root 4096 Sep 23 2011 src [root@djt002 local]# chown -R hadoop:hadoop mahout [root@djt002 local]# ll total 76 drwxr-xr-x. 2 root root 4096 Sep 23 2011 bin drwxr-xr-x. 2 hadoop hadoop 4096 Mar 14 06:19 data drwxr-xr-x. 3 hadoop hadoop 4096 Feb 21 23:10 elasticsearch drwxr-xr-x. 2 root root 4096 Sep 23 2011 etc drwxr-xr-x. 3 hadoop hadoop 4096 Jan 17 17:14 flume drwxr-xr-x. 2 root root 4096 Sep 23 2011 games drwxr-xr-x. 3 hadoop hadoop 4096 Jan 16 23:33 hadoop drwxr-xr-x. 3 hadoop hadoop 4096 Mar 16 18:26 hbase drwxr-xr-x. 4 hadoop hadoop 4096 Mar 14 17:48 hive drwxr-xr-x. 2 root root 4096 Sep 23 2011 include drwxr-xr-x. 3 hadoop hadoop 4096 Jan 16 23:25 jdk drwxr-xr-x. 2 root root 4096 Sep 23 2011 lib drwxr-xr-x. 2 root root 4096 Sep 23 2011 lib64 drwxr-xr-x. 2 root root 4096 Sep 23 2011 libexec drwxr-xr-x 2 hadoop hadoop 4096 Apr 7 00:21 mahout drwxr-xr-x. 2 root root 4096 Sep 23 2011 sbin drwxr-xr-x. 5 root root 4096 Jan 16 20:09 share drwxr-xr-x. 4 hadoop hadoop 4096 Mar 17 23:33 sqoop drwxr-xr-x. 2 root root 4096 Sep 23 2011 src [root@djt002 local]#
2、上传mahout压缩包

[root@djt002 local]# su hadoop [hadoop@djt002 local]$ cd mahout/ [hadoop@djt002 mahout]$ pwd /usr/local/mahout [hadoop@djt002 mahout]$ ll total 0 [hadoop@djt002 mahout]$ rz [hadoop@djt002 mahout]$ ll total 67628 -rw-r--r-- 1 hadoop hadoop 69248331 Apr 6 16:09 mahout-distribution-0.8.tar.gz [hadoop@djt002 mahout]$
3、解压
[hadoop@djt002 mahout]$ pwd /usr/local/mahout [hadoop@djt002 mahout]$ ll total 67628 -rw-r--r-- 1 hadoop hadoop 69248331 Apr 6 16:09 mahout-distribution-0.8.tar.gz [hadoop@djt002 mahout]$ tar -zxvf mahout-distribution-0.9.tar.gz
4、删除压缩包和赋予用户组
[hadoop@djt002 mahout]$ pwd /usr/local/mahout [hadoop@djt002 mahout]$ ll total 67632 drwxrwxr-x 7 hadoop hadoop 4096 Apr 7 00:25 mahout-distribution-0.8 -rw-r--r-- 1 hadoop hadoop 69248331 Apr 6 16:09 mahout-distribution-0.8.tar.gz [hadoop@djt002 mahout]$ rm mahout-distribution-0.9.tar.gz [hadoop@djt002 mahout]$ ll total 4 drwxrwxr-x 7 hadoop hadoop 4096 Apr 7 00:25 mahout-distribution-0.8 [hadoop@djt002 mahout]$
5、mahout的配置
[root@djt002 mahout-distribution-0.8]# pwd /usr/local/mahout/mahout-distribution-0.8 [root@djt002 mahout-distribution-0.8]# vim /etc/profile

#mahout export MAHOUT_HOME=/usr/local/mahout/mahout-distribution-0.8 export MAHOUT_HOME_CONF_DIR=/usr/local/mahout/mahout-distribution-0.8/conf export PATH=$PATH:$MAHOUT_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib:$MAHOUT_HOME/lib:$JRE_HOME/lib:$CLASSPATH
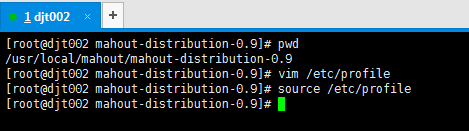
[root@djt002 mahout-distribution-0.9]# source /etc/profile
认识下mahout的目录结构
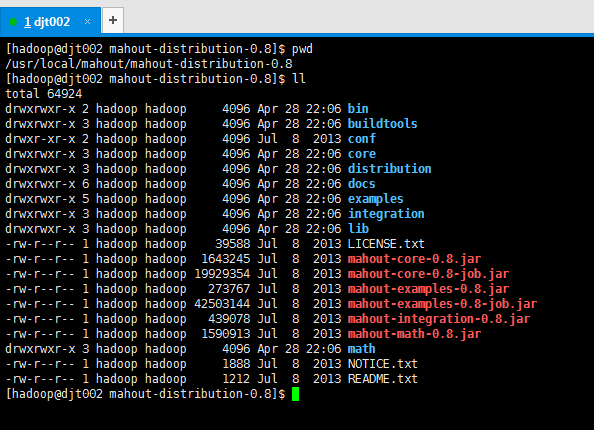
[hadoop@djt002 mahout-distribution-0.8]$ pwd /usr/local/mahout/mahout-distribution-0.8 [hadoop@djt002 mahout-distribution-0.8]$ ll total 64924 drwxrwxr-x 2 hadoop hadoop 4096 Apr 28 22:06 bin drwxrwxr-x 3 hadoop hadoop 4096 Apr 28 22:06 buildtools drwxr-xr-x 2 hadoop hadoop 4096 Jul 8 2013 conf drwxrwxr-x 3 hadoop hadoop 4096 Apr 28 22:06 core drwxrwxr-x 3 hadoop hadoop 4096 Apr 28 22:06 distribution drwxrwxr-x 6 hadoop hadoop 4096 Apr 28 22:06 docs drwxrwxr-x 5 hadoop hadoop 4096 Apr 28 22:06 examples drwxrwxr-x 3 hadoop hadoop 4096 Apr 28 22:06 integration drwxrwxr-x 3 hadoop hadoop 4096 Apr 28 22:06 lib -rw-r--r-- 1 hadoop hadoop 39588 Jul 8 2013 LICENSE.txt -rw-r--r-- 1 hadoop hadoop 1643245 Jul 8 2013 mahout-core-0.8.jar -rw-r--r-- 1 hadoop hadoop 19929354 Jul 8 2013 mahout-core-0.8-job.jar -rw-r--r-- 1 hadoop hadoop 273767 Jul 8 2013 mahout-examples-0.8.jar -rw-r--r-- 1 hadoop hadoop 42503144 Jul 8 2013 mahout-examples-0.8-job.jar -rw-r--r-- 1 hadoop hadoop 439078 Jul 8 2013 mahout-integration-0.8.jar -rw-r--r-- 1 hadoop hadoop 1590913 Jul 8 2013 mahout-math-0.8.jar drwxrwxr-x 3 hadoop hadoop 4096 Apr 28 22:06 math -rw-r--r-- 1 hadoop hadoop 1888 Jul 8 2013 NOTICE.txt -rw-r--r-- 1 hadoop hadoop 1212 Jul 8 2013 README.txt [hadoop@djt002 mahout-distribution-0.8]$
三、验证mahout是否安装成功
[hadoop@djt002 mahout-distribution-0.8]$ bin/mahout --help Running on hadoop, using /usr/local/hadoop/hadoop-2.6.0/bin/hadoop and HADOOP_CONF_DIR= MAHOUT-JOB: /usr/local/mahout/mahout-distribution-0.9/mahout-examples-0.9-job.jar Unknown program '--help' chosen. Valid program names are: arff.vector: : Generate Vectors from an ARFF file or directory baumwelch: : Baum-Welch algorithm for unsupervised HMM training canopy: : Canopy clustering cat: : Print a file or resource as the logistic regression models would see it cleansvd: : Cleanup and verification of SVD output clusterdump: : Dump cluster output to text clusterpp: : Groups Clustering Output In Clusters cmdump: : Dump confusion matrix in HTML or text formats concatmatrices: : Concatenates 2 matrices of same cardinality into a single matrix cvb: : LDA via Collapsed Variation Bayes (0th deriv. approx) cvb0_local: : LDA via Collapsed Variation Bayes, in memory locally. evaluateFactorization: : compute RMSE and MAE of a rating matrix factorization against probes fkmeans: : Fuzzy K-means clustering hmmpredict: : Generate random sequence of observations by given HMM itemsimilarity: : Compute the item-item-similarities for item-based collaborative filtering kmeans: : K-means clustering lucene.vector: : Generate Vectors from a Lucene index lucene2seq: : Generate Text SequenceFiles from a Lucene index matrixdump: : Dump matrix in CSV format matrixmult: : Take the product of two matrices parallelALS: : ALS-WR factorization of a rating matrix qualcluster: : Runs clustering experiments and summarizes results in a CSV recommendfactorized: : Compute recommendations using the factorization of a rating matrix recommenditembased: : Compute recommendations using item-based collaborative filtering regexconverter: : Convert text files on a per line basis based on regular expressions resplit: : Splits a set of SequenceFiles into a number of equal splits rowid: : Map SequenceFile<Text,VectorWritable> to {SequenceFile<IntWritable,VectorWritable>, SequenceFile<IntWritable,Text>} rowsimilarity: : Compute the pairwise similarities of the rows of a matrix runAdaptiveLogistic: : Score new production data using a probably trained and validated AdaptivelogisticRegression model runlogistic: : Run a logistic regression model against CSV data seq2encoded: : Encoded Sparse Vector generation from Text sequence files seq2sparse: : Sparse Vector generation from Text sequence files seqdirectory: : Generate sequence files (of Text) from a directory seqdumper: : Generic Sequence File dumper seqmailarchives: : Creates SequenceFile from a directory containing gzipped mail archives seqwiki: : Wikipedia xml dump to sequence file spectralkmeans: : Spectral k-means clustering split: : Split Input data into test and train sets splitDataset: : split a rating dataset into training and probe parts ssvd: : Stochastic SVD streamingkmeans: : Streaming k-means clustering svd: : Lanczos Singular Value Decomposition testnb: : Test the Vector-based Bayes classifier trainAdaptiveLogistic: : Train an AdaptivelogisticRegression model trainlogistic: : Train a logistic regression using stochastic gradient descent trainnb: : Train the Vector-based Bayes classifier transpose: : Take the transpose of a matrix validateAdaptiveLogistic: : Validate an AdaptivelogisticRegression model against hold-out data set vecdist: : Compute the distances between a set of Vectors (or Cluster or Canopy, they must fit in memory) and a list of Vectors vectordump: : Dump vectors from a sequence file to text viterbi: : Viterbi decoding of hidden states from given output states sequence [hadoop@djt002 mahout-distribution-0.9]$
出现上述的界面,说明mahout安装成功,因为,自动列出mahout已经实现的所有命令。
运行mahout自带的示例(确保hadoop集群已开启)
mahout中的算法大致可以分为三大类:
聚类,协同过滤和分类
其中
常用聚类算法有:canopy聚类,k均值算法(kmeans),模糊k均值,层次聚类,LDA聚类等
常用分类算法有:贝叶斯,逻辑回归,支持向量机,感知器,神经网络等
因为,我的版本是mahout-0.8,所以mahout-examples-0.8-job.jar。
以下是运行mahout自带的keans算法
$HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
或者
以下是运行mahout自带的cnopy算法
$HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.canopy.Job

[hadoop@djt002 mahout-distribution-0.9]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.9/mahout-examples-0.9-job.jar org.apache.mahout.clustering.syntheticcontrol.canopy.Job 17/04/28 06:42:49 INFO canopy.Job: Running with default arguments 17/04/28 06:42:54 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 17/04/28 06:42:55 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 17/04/28 06:42:58 INFO mapreduce.JobSubmitter: Cleaning up the staging area /tmp/hadoop-yarn/staging/hadoop/.staging/job_1493332712225_0001 Exception in thread "main" org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: hdfs://djt002:9000/user/hadoop/testdata at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:321) at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:264) at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:385) at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:597) at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:614) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:492) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1296) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1293) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1293) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1314) at org.apache.mahout.clustering.conversion.InputDriver.runJob(InputDriver.java:108) at org.apache.mahout.clustering.syntheticcontrol.canopy.Job.run(Job.java:85) at org.apache.mahout.clustering.syntheticcontrol.canopy.Job.main(Job.java:55) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136) [hadoop@djt002 mahout-distribution-0.9]$
准备测试数据
练习数据下载地址:
http://download.csdn.net/detail/qq1010885678/8582941
上面的练习数据是用来检测kmeans聚类算法的数据。
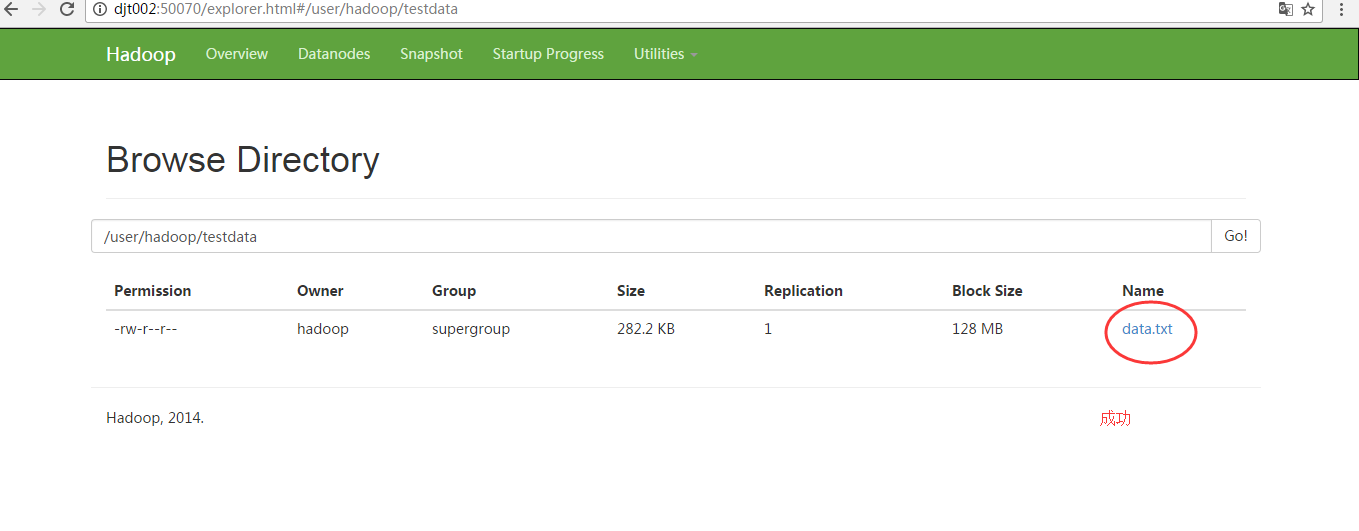
将练习数据(data.txt)上传到hdfs中对应的hdfs://djt002:9000/user/hadoop/testdata目录下即可。(这是样本数据集,可以适用各种算法)
我这里,上传测试数据。到我本地linux自己写的一个路径。(这里为了自己所需哈)
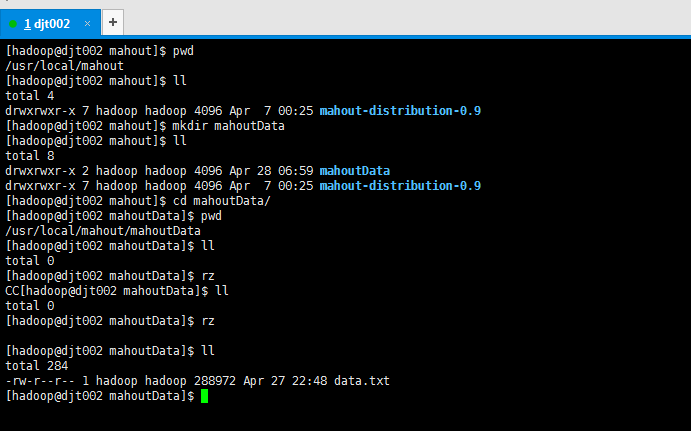
[hadoop@djt002 mahout]$ pwd /usr/local/mahout [hadoop@djt002 mahout]$ ll total 4 drwxrwxr-x 7 hadoop hadoop 4096 Apr 7 00:25 mahout-distribution-0.8 [hadoop@djt002 mahout]$ mkdir mahoutData [hadoop@djt002 mahout]$ ll total 8 drwxrwxr-x 2 hadoop hadoop 4096 Apr 28 06:59 mahoutData drwxrwxr-x 7 hadoop hadoop 4096 Apr 7 00:25 mahout-distribution-0.8 [hadoop@djt002 mahout]$ cd mahoutData/ [hadoop@djt002 mahoutData]$ pwd /usr/local/mahout/mahoutData [hadoop@djt002 mahoutData]$ ll total 0 [hadoop@djt002 mahoutData]$ rz CC[hadoop@djt002 mahoutData]$ ll total 0 [hadoop@djt002 mahoutData]$ rz [hadoop@djt002 mahoutData]$ ll total 284 -rw-r--r-- 1 hadoop hadoop 288972 Apr 27 22:48 data.txt [hadoop@djt002 mahoutData]$
然后,将/usr/local/mahout/mahoutData/下的测试数据,上传到hdfs://djt002:9000/user/hadoop/testdata下

[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -put /usr/local/mahout/mahoutData/data.txt hdfs://djt002:9000/user/hadoop/testdata
或者
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -copyFromLocal /usr/local/mahout/mahoutData/data.txt hdfs://djt002:9000/user/hadoop/testdata/
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -ls hdfs://djt002:9000/user/hadoop/testdata/ -rw-r--r-- 1 hadoop supergroup 288972 2017-04-28 07:02 hdfs://djt002:9000/user/hadoop/testdata
也许中间会出现,这个数据集,你会上传不了。解决方案如下

[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -put /usr/local/mahout/mahoutData/data.txt hdfs://djt002:9000/user/hadoop/testdata/ put: `hdfs://djt002:9000/user/hadoop/testdata': File exists [hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -rm hdfs://djt002:9000/user/hadoop/testdata/ 17/04/28 07:16:58 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted hdfs://djt002:9000/user/hadoop/testdata [hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -mkdir hdfs://djt002:9000/user/hadoop/testdata/ [hadoop@djt002 mahoutData]$


[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -put /usr/local/mahout/mahoutData/data.txt hdfs://djt002:9000/user/hadoop/testdata/ [hadoop@djt002 mahoutData]$
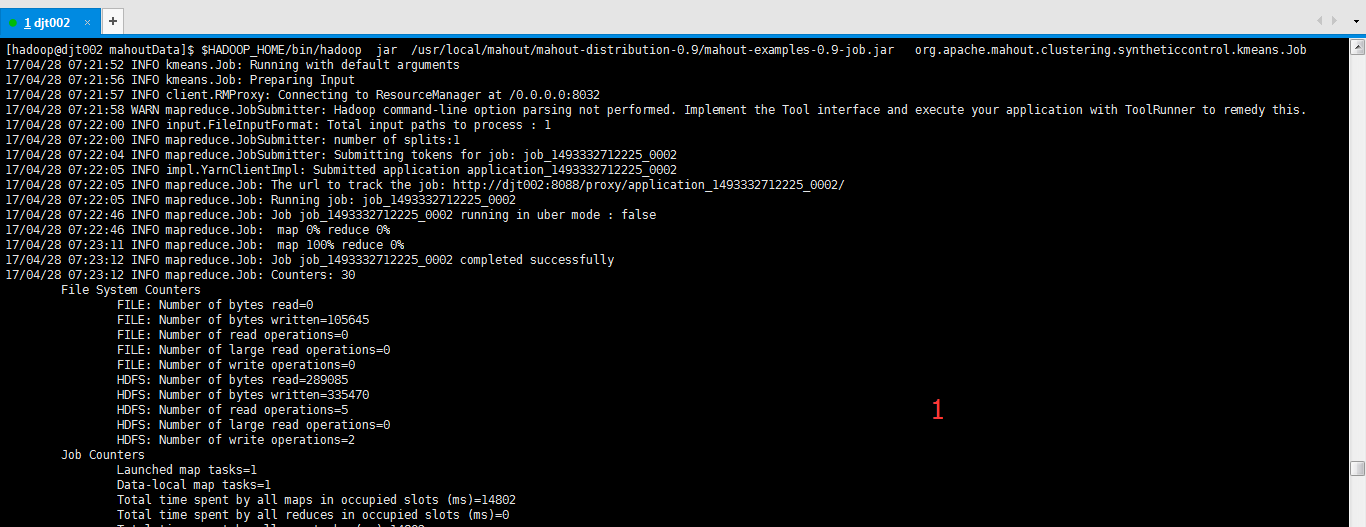
使用kmeans算法
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
注意,是不需输入路径和输出路径的啊!(自带的jar包里都已经写死了的)
(注意:如果你是选择用mahout压缩包里自带的kmeans算法的话,则它的输入路径是testdata是固定死的,
即hdfs:djt002://9000/user/hadoop/testdata/ )
并且每次运行hadoop都要删掉原来的output目录!
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -rm -r hdfs://djt002:9000/user/hadoop/output/*

....
由于聚类算法是一种迭代的过程(之后会讲解)
所以,它会一直重复的执行mr任务到符合要求(这其中的过程可能有点久。。。)

Kmeans运行结果如下:
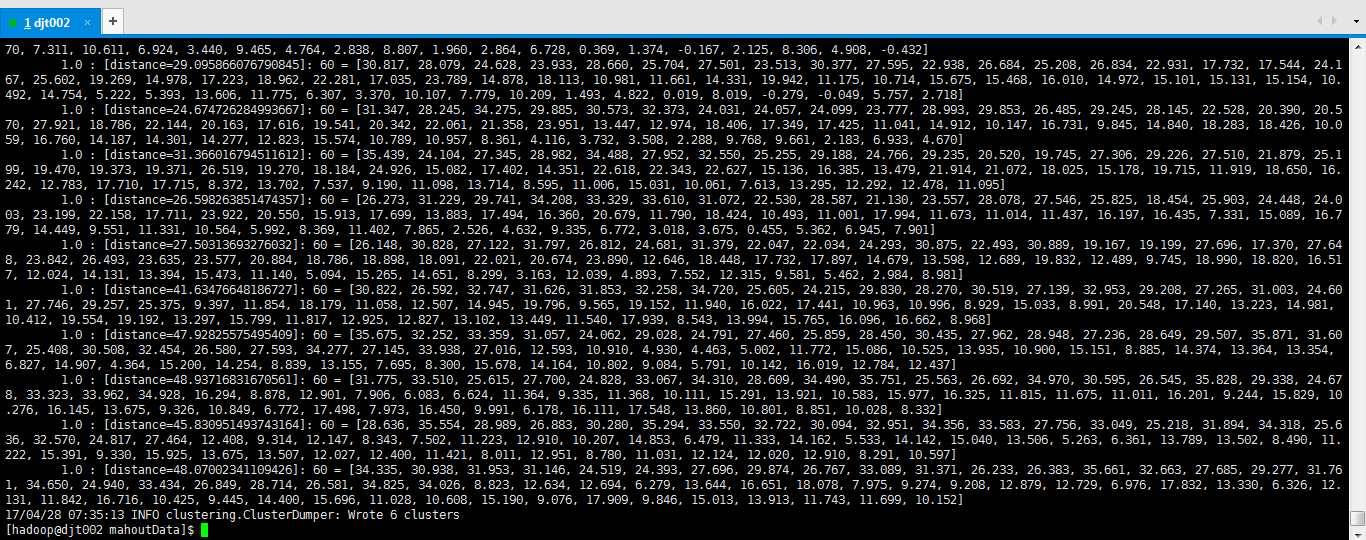
70, 7.311, 10.611, 6.924, 3.440, 9.465, 4.764, 2.838, 8.807, 1.960, 2.864, 6.728, 0.369, 1.374, -0.167, 2.125, 8.306, 4.908, -0.432] 1.0 : [distance=29.095866076790845]: 60 = [30.817, 28.079, 24.628, 23.933, 28.660, 25.704, 27.501, 23.513, 30.377, 27.595, 22.938, 26.684, 25.208, 26.834, 22.931, 17.732, 17.544, 24.167, 25.602, 19.269, 14.978, 17.223, 18.962, 22.281, 17.035, 23.789, 14.878, 18.113, 10.981, 11.661, 14.331, 19.942, 11.175, 10.714, 15.675, 15.468, 16.010, 14.972, 15.101, 15.131, 15.154, 10.492, 14.754, 5.222, 5.393, 13.606, 11.775, 6.307, 3.370, 10.107, 7.779, 10.209, 1.493, 4.822, 0.019, 8.019, -0.279, -0.049, 5.757, 2.718] 1.0 : [distance=24.674726284993667]: 60 = [31.347, 28.245, 34.275, 29.885, 30.573, 32.373, 24.031, 24.057, 24.099, 23.777, 28.993, 29.853, 26.485, 29.245, 28.145, 22.528, 20.390, 20.570, 27.921, 18.786, 22.144, 20.163, 17.616, 19.541, 20.342, 22.061, 21.358, 23.951, 13.447, 12.974, 18.406, 17.349, 17.425, 11.041, 14.912, 10.147, 16.731, 9.845, 14.840, 18.283, 18.426, 10.059, 16.760, 14.187, 14.301, 14.277, 12.823, 15.574, 10.789, 10.957, 8.361, 4.116, 3.732, 3.508, 2.288, 9.768, 9.661, 2.183, 6.933, 4.670] 1.0 : [distance=31.366016794511612]: 60 = [35.439, 24.104, 27.345, 28.982, 34.488, 27.952, 32.550, 25.255, 29.188, 24.766, 29.235, 20.520, 19.745, 27.306, 29.226, 27.510, 21.879, 25.199, 19.470, 19.373, 19.371, 26.519, 19.270, 18.184, 24.926, 15.082, 17.402, 14.351, 22.618, 22.343, 22.627, 15.136, 16.385, 13.479, 21.914, 21.072, 18.025, 15.178, 19.715, 11.919, 18.650, 16.242, 12.783, 17.710, 17.715, 8.372, 13.702, 7.537, 9.190, 11.098, 13.714, 8.595, 11.006, 15.031, 10.061, 7.613, 13.295, 12.292, 12.478, 11.095] 1.0 : [distance=26.598263851474357]: 60 = [26.273, 31.229, 29.741, 34.208, 33.329, 33.610, 31.072, 22.530, 28.587, 21.130, 23.557, 28.078, 27.546, 25.825, 18.454, 25.903, 24.448, 24.003, 23.199, 22.158, 17.711, 23.922, 20.550, 15.913, 17.699, 13.883, 17.494, 16.360, 20.679, 11.790, 18.424, 10.493, 11.001, 17.994, 11.673, 11.014, 11.437, 16.197, 16.435, 7.331, 15.089, 16.779, 14.449, 9.551, 11.331, 10.564, 5.992, 8.369, 11.402, 7.865, 2.526, 4.632, 9.335, 6.772, 3.018, 3.675, 0.455, 5.362, 6.945, 7.901] 1.0 : [distance=27.50313693276032]: 60 = [26.148, 30.828, 27.122, 31.797, 26.812, 24.681, 31.379, 22.047, 22.034, 24.293, 30.875, 22.493, 30.889, 19.167, 19.199, 27.696, 17.370, 27.648, 23.842, 26.493, 23.635, 23.577, 20.884, 18.786, 18.898, 18.091, 22.021, 20.674, 23.890, 12.646, 18.448, 17.732, 17.897, 14.679, 13.598, 12.689, 19.832, 12.489, 9.745, 18.990, 18.820, 16.517, 12.024, 14.131, 13.394, 15.473, 11.140, 5.094, 15.265, 14.651, 8.299, 3.163, 12.039, 4.893, 7.552, 12.315, 9.581, 5.462, 2.984, 8.981] 1.0 : [distance=41.63476648186727]: 60 = [30.822, 26.592, 32.747, 31.626, 31.853, 32.258, 34.720, 25.605, 24.215, 29.830, 28.270, 30.519, 27.139, 32.953, 29.208, 27.265, 31.003, 24.601, 27.746, 29.257, 25.375, 9.397, 11.854, 18.179, 11.058, 12.507, 14.945, 19.796, 9.565, 19.152, 11.940, 16.022, 17.441, 10.963, 10.996, 8.929, 15.033, 8.991, 20.548, 17.140, 13.223, 14.981, 10.412, 19.554, 19.192, 13.297, 15.799, 11.817, 12.925, 12.827, 13.102, 13.449, 11.540, 17.939, 8.543, 13.994, 15.765, 16.096, 16.662, 8.968] 1.0 : [distance=47.92825575495409]: 60 = [35.675, 32.252, 33.359, 31.057, 24.062, 29.028, 24.791, 27.460, 25.859, 28.450, 30.435, 27.962, 28.948, 27.236, 28.649, 29.507, 35.871, 31.607, 25.408, 30.508, 32.454, 26.580, 27.593, 34.277, 27.145, 33.938, 27.016, 12.593, 10.910, 4.930, 4.463, 5.002, 11.772, 15.086, 10.525, 13.935, 10.900, 15.151, 8.885, 14.374, 13.364, 13.354, 6.827, 14.907, 4.364, 15.200, 14.254, 8.839, 13.155, 7.695, 8.300, 15.678, 14.164, 10.802, 9.084, 5.791, 10.142, 16.019, 12.784, 12.437] 1.0 : [distance=48.93716831670561]: 60 = [31.775, 33.510, 25.615, 27.700, 24.828, 33.067, 34.310, 28.609, 34.490, 35.751, 25.563, 26.692, 34.970, 30.595, 26.545, 35.828, 29.338, 24.678, 33.323, 33.962, 34.928, 16.294, 8.878, 12.901, 7.906, 6.083, 6.624, 11.364, 9.335, 11.368, 10.111, 15.291, 13.921, 10.583, 15.977, 16.325, 11.815, 11.675, 11.011, 16.201, 9.244, 15.829, 10.276, 16.145, 13.675, 9.326, 10.849, 6.772, 17.498, 7.973, 16.450, 9.991, 6.178, 16.111, 17.548, 13.860, 10.801, 8.851, 10.028, 8.332] 1.0 : [distance=45.830951493743164]: 60 = [28.636, 35.554, 28.989, 26.883, 30.280, 35.294, 33.550, 32.722, 30.094, 32.951, 34.356, 33.583, 27.756, 33.049, 25.218, 31.894, 34.318, 25.636, 32.570, 24.817, 27.464, 12.408, 9.314, 12.147, 8.343, 7.502, 11.223, 12.910, 10.207, 14.853, 6.479, 11.333, 14.162, 5.533, 14.142, 15.040, 13.506, 5.263, 6.361, 13.789, 13.502, 8.490, 11.222, 15.391, 9.330, 15.925, 13.675, 13.507, 12.027, 12.400, 11.421, 8.011, 12.951, 8.780, 11.031, 12.124, 12.020, 12.910, 8.291, 10.597] 1.0 : [distance=48.07002341109426]: 60 = [34.335, 30.938, 31.953, 31.146, 24.519, 24.393, 27.696, 29.874, 26.767, 33.089, 31.371, 26.233, 26.383, 35.661, 32.663, 27.685, 29.277, 31.761, 34.650, 24.940, 33.434, 26.849, 28.714, 26.581, 34.825, 34.026, 8.823, 12.634, 12.694, 6.279, 13.644, 16.651, 18.078, 7.975, 9.274, 9.208, 12.879, 12.729, 6.976, 17.832, 13.330, 6.326, 12.131, 11.842, 16.716, 10.425, 9.445, 14.400, 15.696, 11.028, 10.608, 15.190, 9.076, 17.909, 9.846, 15.013, 13.913, 11.743, 11.699, 10.152] 17/04/28 07:35:13 INFO clustering.ClusterDumper: Wrote 6 clusters [hadoop@djt002 mahoutData]$
mahout无异常!!!
注意:执行完这个kmeans算法之后产生的文件按普通方式是查看不了的,看到的只是一堆莫名其妙的数据!!!
查看聚类分析的结果:
需要用mahout的seqdumper命令来下载到本地linux上才能查看正常结果。
[hadoop@djt002 ~]$ $MAHOUT_HOME/bin/mahout seqdumper -i /user/hadoop/output/data/part-m-00000 -o ~/res.txt
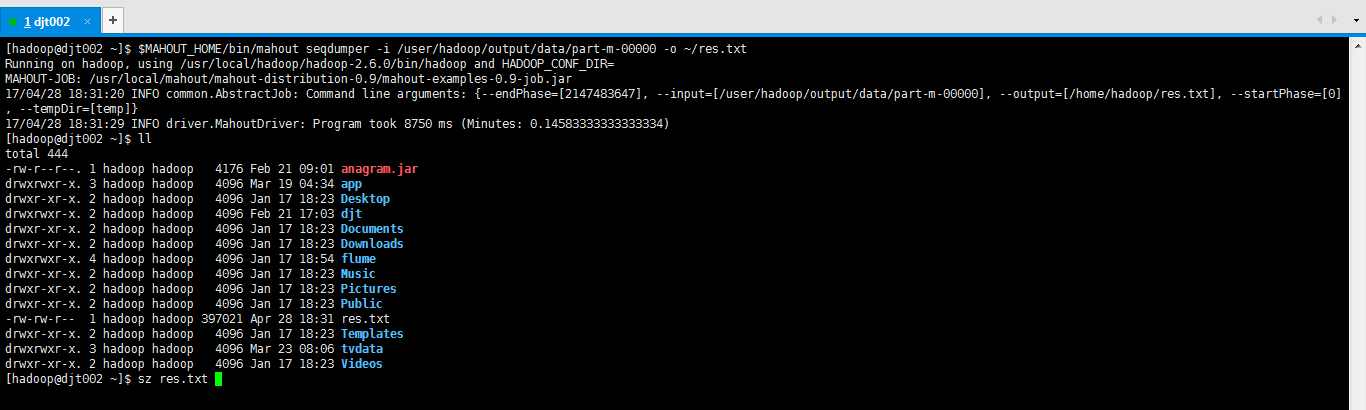
[hadoop@djt002 ~]$ $MAHOUT_HOME/bin/mahout seqdumper -i /user/hadoop/output/data/part-m-00000 -o ~/res.txt Running on hadoop, using /usr/local/hadoop/hadoop-2.6.0/bin/hadoop and HADOOP_CONF_DIR= MAHOUT-JOB: /usr/local/mahout/mahout-distribution-0.9/mahout-examples-0.9-job.jar 17/04/28 18:31:20 INFO common.AbstractJob: Command line arguments: {--endPhase=[2147483647], --input=[/user/hadoop/output/data/part-m-00000], --output=[/home/hadoop/res.txt], --startPhase=[0], --tempDir=[temp]} 17/04/28 18:31:29 INFO driver.MahoutDriver: Program took 8750 ms (Minutes: 0.14583333333333334) [hadoop@djt002 ~]$ ll total 444 -rw-r--r--. 1 hadoop hadoop 4176 Feb 21 09:01 anagram.jar drwxrwxr-x. 3 hadoop hadoop 4096 Mar 19 04:34 app drwxr-xr-x. 2 hadoop hadoop 4096 Jan 17 18:23 Desktop drwxrwxr-x. 2 hadoop hadoop 4096 Feb 21 17:03 djt drwxr-xr-x. 2 hadoop hadoop 4096 Jan 17 18:23 Documents drwxr-xr-x. 2 hadoop hadoop 4096 Jan 17 18:23 Downloads drwxrwxr-x. 4 hadoop hadoop 4096 Jan 17 18:54 flume drwxr-xr-x. 2 hadoop hadoop 4096 Jan 17 18:23 Music drwxr-xr-x. 2 hadoop hadoop 4096 Jan 17 18:23 Pictures drwxr-xr-x. 2 hadoop hadoop 4096 Jan 17 18:23 Public -rw-rw-r-- 1 hadoop hadoop 397021 Apr 28 18:31 res.txt drwxr-xr-x. 2 hadoop hadoop 4096 Jan 17 18:23 Templates drwxrwxr-x. 3 hadoop hadoop 4096 Mar 23 08:06 tvdata drwxr-xr-x. 2 hadoop hadoop 4096 Jan 17 18:23 Videos [hadoop@djt002 ~]$ sz res.txt
Input Path: /user/hadoop/output/data/part-m-00000 Key class: class org.apache.hadoop.io.Text Value Class: class org.apache.mahout.math.VectorWritable Key: 60: Value: {0:28.7812,31:26.6311,34:29.1495,4:28.9207,32:35.6541,5:33.7596,8:35.2479,6:25.3969,30:25.0293,24:33.0292,29:34.9424,17:26.5235,51:24.5556,36:26.1927,12:36.0253,23:29.5054,58:25.4652,21:29.27,11:29.2171,10:32.8717,15:32.8717,7:27.7849,28:26.1203,46:28.0721,33:28.4353,55:34.9879,54:34.9318,25:25.04,3:31.2834,49:29.747,41:26.2353,1:34.4632,26:28.9167,44:31.0558,37:33.3182,56:32.4721,42:28.9964,27:24.3437,50:31.4333,16:34.1173,40:35.5344,48:35.4973,39:27.0443,9:27.1159,52:33.7431,13:32.337,43:32.0036,19:26.3693,59:25.8717,2:31.3381,20:25.7744,18:27.6623,22:30.7326,35:28.1584,57:33.3759,45:34.2553,38:30.9772,47:28.9402,14:34.5249,53:25.0466} Key: 60: Value: {0:24.8923,31:32.5981,34:26.9414,4:27.8789,32:28.3038,5:31.5926,8:27.9516,6:31.4861,30:34.0765,24:31.9874,29:25.0701,17:35.6273,51:31.0205,36:33.1089,12:27.4867,23:30.4719,58:32.1005,21:24.1311,11:31.1887,10:27.5415,15:24.488,7:35.5469,28:33.6472,46:26.3458,33:26.1471,55:26.4244,54:33.6564,25:33.6615,3:32.8217,49:29.4047,41:26.5301,1:25.741,26:25.5511,44:32.8357,37:24.1491,56:28.4661,42:24.8578,27:30.4686,50:32.5577,16:27.5918,40:35.9519,48:28.9861,39:25.7906,9:31.6595,52:26.6418,13:31.391,43:25.9562,19:31.4167,59:26.691,2:27.5532,20:30.7447,18:35.4102,22:35.1422,35:31.5203,57:34.2484,45:28.5322,38:28.5157,47:30.6213,14:27.811,53:28.4331} Key: 60: Value: {0:31.3987,31:24.246,34:31.6114,4:27.8613,32:26.9631,5:28.5491,8:25.2239,6:24.9717,30:27.3086,24:24.3323,29:28.8778,17:32.5614,51:26.5966,36:27.4809,12:28.2572,23:32.3851,58:29.5446,21:31.4781,11:27.2587,10:31.8387,15:35.0625,7:32.4358,28:31.5137,46:29.6082,33:25.2919,55:29.9897,54:25.5772,25:30.2001,3:24.2905,49:27.1717,41:31.0561,1:30.6316,26:31.2452,44:31.4391,37:24.2075,56:31.351,42:26.3583,27:26.6814,50:33.6318,16:31.5717,40:32.6293,48:34.1444,39:35.1253,9:27.3068,52:25.5387,13:26.5819,43:28.0861,19:34.1202,59:29.343,2:26.3983,20:26.9337,18:31.0308,22:35.0173,35:24.7131,57:33.9002,45:27.3057,38:26.8059,47:35.9725,14:24.0455,53:32.5434} Key: 60: Value: {0:25.774,31:28.3714,34:35.9346,4:27.97,32:32.3667,5:25.2702,8:31.4549,6:28.132,30:27.5587,24:29.2806,29:24.824,17:35.0966,51:28.7261,36:24.3749,12:29.9578,23:31.6264,58:27.3659,21:25.0102,11:28.9916,10:28.9564,15:24.3037,7:29.4268,28:25.5265,46:35.769,33:26.9752,55:32.5492,54:34.6156,25:34.2021,3:25.6033,49:31.156,41:26.8908,1:30.5262,26:26.5077,44:34.3336,37:27.6083,56:30.9827,42:31.3209,27:32.2279,50:34.6292,16:24.314,40:32.4185,48:34.2054,39:29.8557,9:27.32,52:28.2979,13:30.2773,43:29.3849,19:32.0968,59:25.3069,2:35.4209,20:33.3303,18:25.3679,22:35.3155,35:35.1146,57:24.8938,45:24.7381,38:27.8433,47:31.8725,14:30.4447,53:31.5787} Key: 60: Value: {0:27.1798,31:33.4129,34:29.6526,4:24.6555,32:26.9245,5:28.9446,8:24.5596,6:35.798,30:33.1247,24:24.6081,29:28.0295,17:31.1274,51:27.9601,36:24.5119,12:35.4154,23:33.0321,58:31.1057,21:31.6565,11:25.3216,10:27.9634,15:29.4686,7:34.9446,28:35.8773,46:29.1348,33:30.2123,55:29.9993,54:35.3375,25:33.2025,3:25.6264,49:34.9244,41:27.9072,1:29.2498,26:27.4335,44:33.833,37:33.9931,56:34.2149,42:35.111,27:32.6355,50:27.7218,16:33.1739,40:31.2651,48:32.3223,39:33.204,9:34.2366,52:35.7198,13:34.862,43:35.0757,19:26.5173,59:31.0179,2:33.6928,20:28.6486,18:31.3701,22:35.9497,35:30.8644,57:33.1276,45:25.9481,38:33.3094,47:24.2875,14:25.1472,53:27.576} .... ....


当然,你可以去看输出目录下/user/hadoop/output的其他的,比如clusters-0、clusters-1等,我这里仅仅是
看的是/user/hadoop/output/data/下的。
使用canopy算法
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.canopy.Job
这里不多赘述。
使用dirichlet 算法
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.dirichlet.Job
这里不多赘述。
使用meanshift算法
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.meanshift.Job
这里不多赘述。
总结
mahout压缩包,给我们的默认输入路径是/user/hadoop/testdata 和 输出路径是 /user/hadoop/output
其实,我们是自己可以跟上自定义的输入路径和自定义输出路径的。
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.8/mahout-examples-0.8-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job -i /user/hadoop/mahoutData/data.txt -o /user/hadoop/output
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

