

Spark on YARN简介与运行wordcount(master、slave1和slave2)(博主推荐)
前期博客
Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
Spark On YARN模式
这是一种很有前景的部署模式。但限于YARN自身的发展,目前仅支持粗粒度模式(Coarse-grained Mode)。这是由于YARN上的Container资源是不可以动态伸缩的,一旦Container启动之后,可使用的资源不能再发生变化,不过这个已经在YARN计划中了。
spark on yarn 的支持两种模式:
1) yarn-cluster:适用于生产环境;
2) yarn-client:适用于交互、调试,希望立即看到app的输出
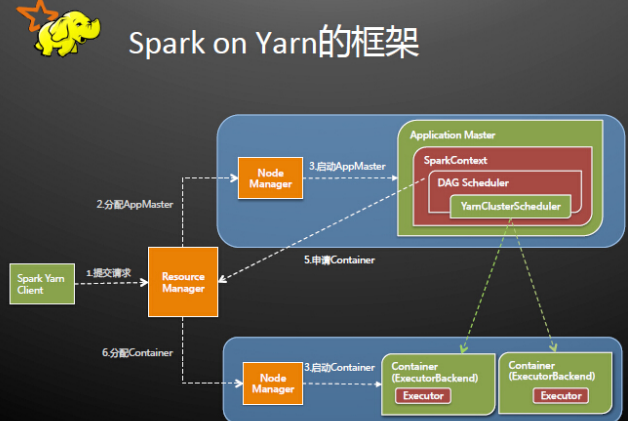
yarn-cluster和yarn-client的区别在于yarn appMaster,每个yarn app实例有一个appMaster进程,是为app启动的第一个container;负责从ResourceManager请求资源,获取到资源后,告诉NodeManager为其启动container。yarn-cluster和yarn-client模式内部实现还是有很大的区别。如果你需要用于生产环境,那么请选择yarn-cluster;而如果你仅仅是Debug程序,可以选择yarn-client。
YARN概述
YARN是什么
Apache Hadoop YARN(Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
YARN在Hadoop生态系统中的位置
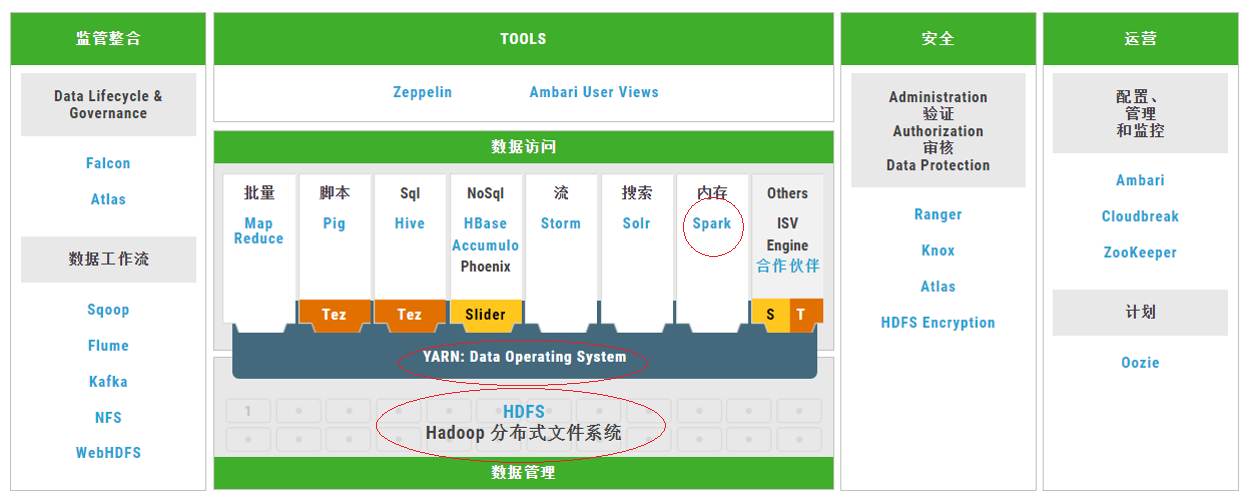
YARN产生的背景
随着互联网高速发展导致数据量剧增,MapReduce 这种基于磁盘的离线计算框架已经不能满足应用要求,从而出现了一些新的计算框架以应对各种场景,包括内存计算框架、流式计算框架和迭代式计算框架等,而MRv1 不能支持多种计算框架并存。
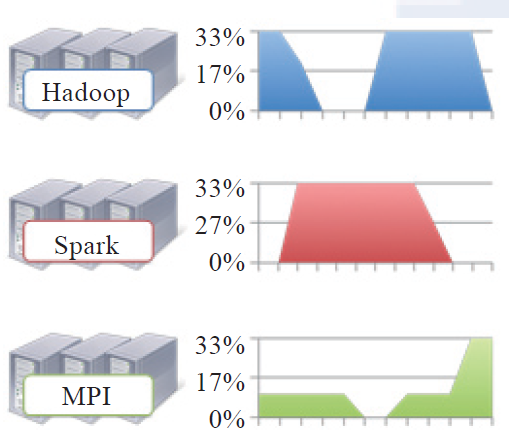
YARN基本架构
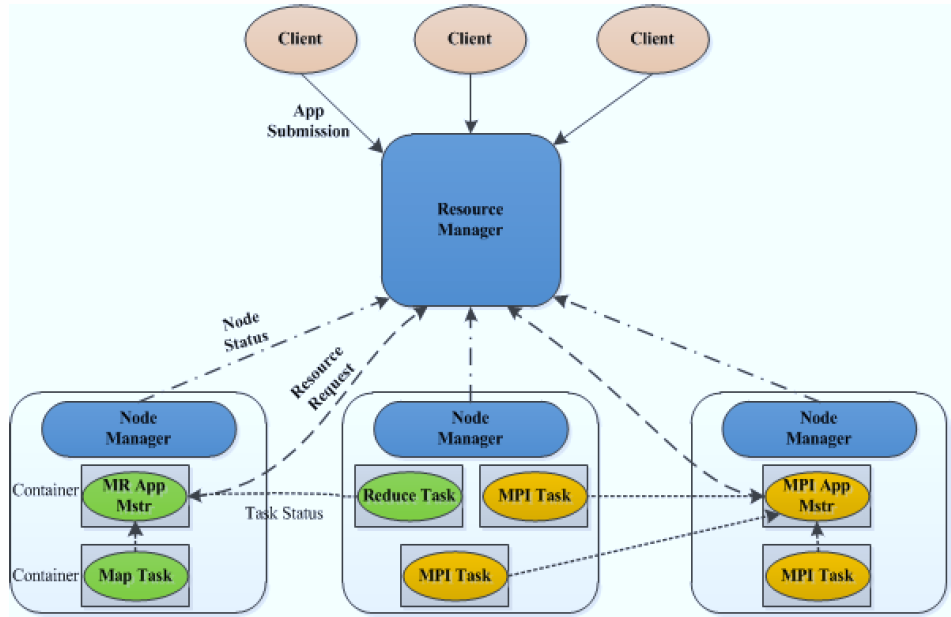
ResourceManager(RM)
ResourceManager负责集群资源的统一管理和调度,承担了 JobTracker 的角色,整个集群只有“一个”,总的来说,RM有以下作用:
1.处理客户端请求
2.启动或监控ApplicationMaster
3.监控NodeManager
4.资源的分配与调度
NodeManager(NM)
NodeManager管理YARN集群中的每个节点。NodeManager 提供针对集群中每个节点的服务,从监督对一个容器的终生管理到监视资源和跟踪节点健康。MRv1 通过slot管理 Map 和 Reduce 任务的执行,而 NodeManager 管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。NM有以下作用。
1.管理单个节点上的资源
2.处理来自ResourceManager的命令
3.处理来自ApplicationMaster的命令
ApplicationMaster(AM)
每个应用有一个,负责应用程序的管理 。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配)。请注意,尽管目前的资源更加传统(CPU 核心、内存),但未来会支持新资源类型(比如图形处理单元或专用处理设备)。AM有以下作用:
1.负责数据的切分
2.为应用程序申请资源并分配给内部的任务
3.任务的监控与容错
Container
Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
Container有以下作用:
对任务运行环境进行抽象,封装CPU、内存等多维度的资源以及环境变量、启动命令等任务运行相关的信息
Spark on YARN运行架构解析
回顾Spark基本工作流程
以SparkContext为程序运行的总入口,在SparkContext的初始化过程中,Spark会分别创建DAGScheduler作业调度和TaskScheduler任务调度两级调度模块。其中作业调度模块是基于任务阶段的高层调度模块,它为每个Spark作业计算具有依赖关系的多个调度阶段(通常根据shuffle来划分),然后为每个阶段构建出一组具体的任务(通常会考虑数据的本地性等),然后以TaskSets(任务组)的形式提交给任务调度模块来具体执行。而任务调度模块则负责具体启动任务、监控和汇报任务运行情况。
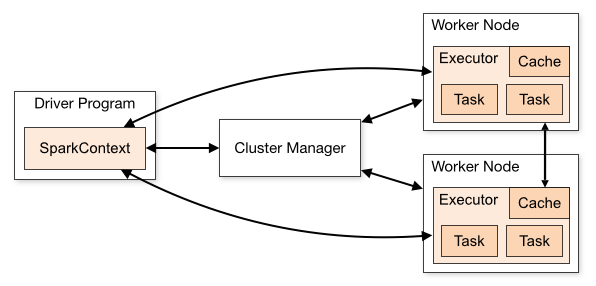
YARN standalone/YARN cluster
YARN standalone是0.9及之前版本的叫法,1.0开始更名为YARN cluster
yarn-cluster(YarnClusterScheduler),是Driver和AM运行在一起,Client单独的。
./bin/spark-submit --class path.to.your.Class --master yarn --deploy-mode cluster [options] [app options]
YARN standalone/YARN cluster
Spark Driver首选作为一个ApplicationMaster在Yarn集群中启动,客户端提交给ResourceManager的每一个job都会在集群的worker节点上分配一个唯一的ApplicationMaster,由该ApplicationMaster管理全生命周期的应用。因为Driver程序在YARN中运行,所以事先不用启动Spark Master/Client,应用的运行结果不能再客户端显示(可以在history server中查看)。
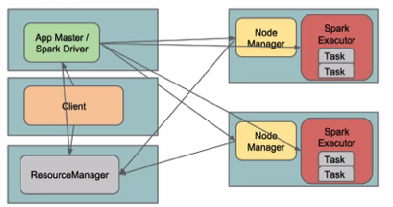
YARN standalone/YARN cluster
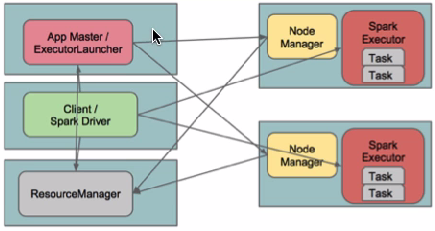
YARN client
yarn-client(YarnClientClusterScheduler)
Client和Driver运行在一起(运行在本地),AM只用来管理资源
./bin/spark-submit --class path.to.your.Class --master yarn --deploy-mode client [options] [app options]
YARN client
在Yarn-client模式下,Driver运行在Client上,通过ApplicationMaster向RM获取资源。本地Driver负责与所有的executor container进行交互,并将最后的结果汇总。结束掉终端,相当于kill掉这个spark应用。一般来说,如果运行的结果仅仅返回到terminal上时需要配置这个。
如何选择
如果需要返回数据到client就用YARN client模式。
数据存储到hdfs的建议用YARN cluster模式。
其他配置和注意事项
如何更改默认配置
spark_home/conf/spark-defaults.conf,每个app提交时都会使用他里面的配置
--conf PROP=VALUE,为单独的app指定个性化参数
环境变量
spark_home/conf/spark-defaults.conf,每个app提交时都会使用他里面的配置
spark.yarn.appMasterEnv.[EnvironmentVariableName]
相关配置
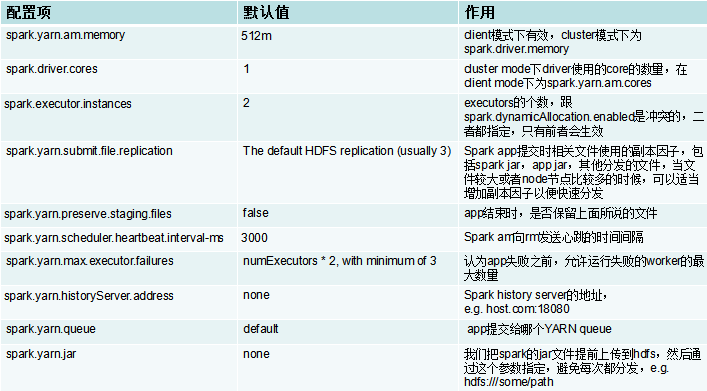

特别注意
在cluster mode下,yarn.nodemanager.local-dirs对?Spark executors 和Spark driver都管用, spark.local.dir将被忽略
在client mode下, Spark executors 使用yarn.nodemanager.local-dirs, Spark driver使用spark.local.dir
--files and –archives支持用#映射到hdfs
--jars
spark-shell运行在YARN上(这是Spark on YARN模式)
(包含YARN client和YARN cluster)(作为补充)
登陆安装Spark那台机器
bin/spark-shell --master yarn-client
或者
bin/spark-shell --master yarn
包括可以加上其他的,比如控制内存啊等。这很简单,不多赘述。

[spark@master spark-1.6.1-bin-hadoop2.6]$ bin/spark-shell --master yarn-client
17/03/29 22:40:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/03/29 22:40:04 INFO spark.SecurityManager: Changing view acls to: spark
17/03/29 22:40:04 INFO spark.SecurityManager: Changing modify acls to: spark
17/03/29 22:40:04 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); users with modify permissions: Set(spark)
17/03/29 22:40:05 INFO spark.HttpServer: Starting HTTP Server
17/03/29 22:40:06 INFO server.Server: jetty-8.y.z-SNAPSHOT
17/03/29 22:40:06 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:35692
17/03/29 22:40:06 INFO util.Utils: Successfully started service 'HTTP class server' on port 35692.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.1
/_/
Using Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_60)
提交spark作业
1、用yarn-client模式提交spark作业
在/usr/local/spark目录下创建文件夹
vi spark_pi.sh$SPARK_HOME/bin/spark-submit \
--class org.apache.spark.examples.JavaSparkPi \
--master yarn-client \
--num-executors 1 \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
$SPARK_HOME/lib/spark-examples-1.6.1-hadoop2.6.0.jar \
chmod 777 spark_pi.sh
./spark_pi.sh
或者
2、用yarn-cluster模式提交spark作业
在/usr/local/spark目录下创建文件夹
vi spark_pi.sh$SPARK_HOME/bin/spark-submit \
--class org.apache.spark.examples.JavaSparkPi \
--master yarn-cluster \
--num-executors 1 \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
$SPARK_HOME/lib/spark-examples-1.6.1-hadoop2.6.0.jar
chmod 777 spark_pi.sh
./spark_pi.sh
或者
[spark@master ~]$ $SPARK_HOME/bin/spark-submit \
> --class org.apache.spark.examples.JavaSparkPi \
> --master yarn-cluster \
> --num-executors 1 \
> --driver-memory 1g \
> --executor-memory 1g \
> --executor-cores 1 \
> $SPARK_HOME/lib/spark-examples-1.6.1-hadoop2.6.0.jar
1、Spark on YARN下运行wordcount
具体,请移步
Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版的WordCount)(博主强烈推荐)
● wordcount代码
● mvn 项目打包上传至Spark集群。
● Spark 集群提交作业
[spark@master hadoop-2.6.0]$ $HADOOP_HOME/bin/hadoop fs -mkdir -p hdfs://master:9000/testspark/inputData/wordcount
[spark@master ~]$ mkdir -p /home/spark/testspark/inputData/wordcount
[spark@master hadoop-2.6.0]$ $HADOOP_HOME/bin/hadoop fs -copyFromLocal /home/spark/testspark/inputData/wordcount/wc.txt hdfs://master:9000/testspark/inputData/wordcount/
这里在/home/spark/testspark下上传mySpark-1.0-SNAPSHOT.jar省略
[spark@master spark-1.6.1-bin-hadoop2.6]$ $SPARK_HOME/bin/spark-submit \
--master yarn-client \
--name scalawordcount \ --num-executors 1 \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 \
--class zhouls.bigdata.MyScalaWordCount \
/home/spark/testspark/mySpark-1.0-SNAPSHOT.jar \
hdfs://master:9000/testspark/inputData/wordcount/wc.txt \
hdfs://master:9000/testspark/outData/MyScalaWordCount
或者
[spark@master spark-1.6.1-bin-hadoop2.6]$ $SPARK_HOME/bin/spark-submit \
--master yarn\
--deploy-mode client \
--name scalawordcount \ --num-executors 1 \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 \
--class zhouls.bigdata.MyScalaWordCount \
/home/spark/testspark/mySpark-1.0-SNAPSHOT.jar \
hdfs://master:9000/testspark/inputData/wordcount/wc.txt \
hdfs://master:9000/testspark/outData/MyScalaWordCount
[spark@master spark-1.6.1-bin-hadoop2.6]$ $SPARK_HOME/bin/spark-submit \
--master yarn-cluster\
--name scalawordcount \ --num-executors 1 \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 \
--class zhouls.bigdata.MyScalaWordCount \
/home/spark/testspark/mySpark-1.0-SNAPSHOT.jar \
hdfs://master:9000/testspark/inputData/wordcount/wc.txt \
hdfs://master:9000/testspark/outData/MyScalaWordCount
或者
[spark@master spark-1.6.1-bin-hadoop2.6]$ $SPARK_HOME/bin/spark-submit \
--master yarn\
--deploy-mode cluster \
--name scalawordcount \ --num-executors 1 \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 \
--class zhouls.bigdata.MyScalaWordCount \
/home/spark/testspark/mySpark-1.0-SNAPSHOT.jar \
hdfs://master:9000/testspark/inputData/wordcount/wc.txt \
hdfs://master:9000/testspark/outData/MyScalaWordCount
[spark@master spark-1.6.1-bin-hadoop2.6]$ $SPARK_HOME/bin/spark-submit \
--master yarn-client \
--name javawordcount \ --num-executors 1 \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 \
--class zhouls.bigdata.MyJavaWordCount \
/home/spark/testspark/mySpark-1.0-SNAPSHOT.jar \
hdfs://master:9000/testspark/inputData/wordcount/wc.txt \
hdfs://master:9000/testspark/outData/MyJavaWordCount
或者
[spark@master spark-1.6.1-bin-hadoop2.6]$ $SPARK_HOME/bin/spark-submit \
--master yarn\
--deploy-mode client \
--name javawordcount \ --num-executors 1 \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 \
--class zhouls.bigdata.MyJavaWordCount \
/home/spark/testspark/mySpark-1.0-SNAPSHOT.jar \
hdfs://master:9000/testspark/inputData/wordcount/wc.txt \
hdfs://master:9000/testspark/outData/MyJavaWordCount
[spark@master spark-1.6.1-bin-hadoop2.6]$ $SPARK_HOME/bin/spark-submit \
--master yarn-cluster\
--name javawordcount \ --num-executors 1 \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 \
--class zhouls.bigdata.MyJavaWordCount \
/home/spark/testspark/mySpark-1.0-SNAPSHOT.jar \
hdfs://master:9000/testspark/inputData/wordcount/wc.txt \
hdfs://master:9000/testspark/outData/MyJavaWordCount
或者
[spark@master spark-1.6.1-bin-hadoop2.6]$ $SPARK_HOME/bin/spark-submit \
--master yarn\
--deploy-mode cluster \
--name javawordcount \ --num-executors 1 \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 \
--class zhouls.bigdata.MyJavaWordCount \
/home/spark/testspark/mySpark-1.0-SNAPSHOT.jar \
hdfs://master:9000/testspark/inputData/wordcount/wc.txt \
hdfs://master:9000/testspark/outData/MyJavaWordCount
2、Spark Standalone 下运行wordcount
具体,请移步
Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版的WordCount)(博主强烈推荐)
● wordcount代码
● mvn 项目打包上传至Spark集群。
● Spark 集群提交作业
$SPARK_HOME/bin/spark-submit \
--master spark://master:7077 \
--class zhouls.bigdata.MyScalaWordCount \
/home/spark/testspark/mySpark-1.0-SNAPSHOT.jar \
hdfs://master:9000/testspark/inputData/wordcount/wc.txt \
hdfs://master:9000/testspark/outData/MyScalaWordCount
或者
$SPARK_HOME/bin/spark-submit \
--master spark://master:7077 \
--class zhouls.bigdata.MyJavaWordCount \
/home/spark/testspark/mySpark-1.0-SNAPSHOT.jar \
hdfs://master:9000/testspark/inputData/wordcount/wc.txt \
hdfs://master:9000/testspark/outData/MyJavaWordCount
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

