
Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
说白了
Spark on YARN模式的安装,它是非常的简单,只需要下载编译好Spark安装包,在一台带有Hadoop YARN客户端的的机器上运行即可。
Spark on YARN简介与运行wordcount(master、slave1和slave2)(博主推荐)
Spark on YARN分为两种: YARN cluster(YARN standalone,0.9版本以前)和 YARN client。
如果需要返回数据到client就用YARN client模式。
如果数据存储到hdfs就用YARN cluster模式。(我一般是用这个)
开篇要明白
(1)spark-env.sh 是环境变量配置文件
(2)spark-defaults.conf
(3)slaves 是从节点机器配置文件
(4)metrics.properties 是 监控
(5)log4j.properties 是配置日志
(5)fairscheduler.xml是公平调度
(6)docker.properties 是 docker
(7)我这里的Spark on YARN模式的安装,是master、slave1和slave2。
(8)Spark on YARN模式的安装,其实,是必须要安装hadoop的。
(9)为了管理,安装zookeeper,(即管理master、slave1和slave2)
首先,说下我这篇博客的Spark on YARN模式的安装情况
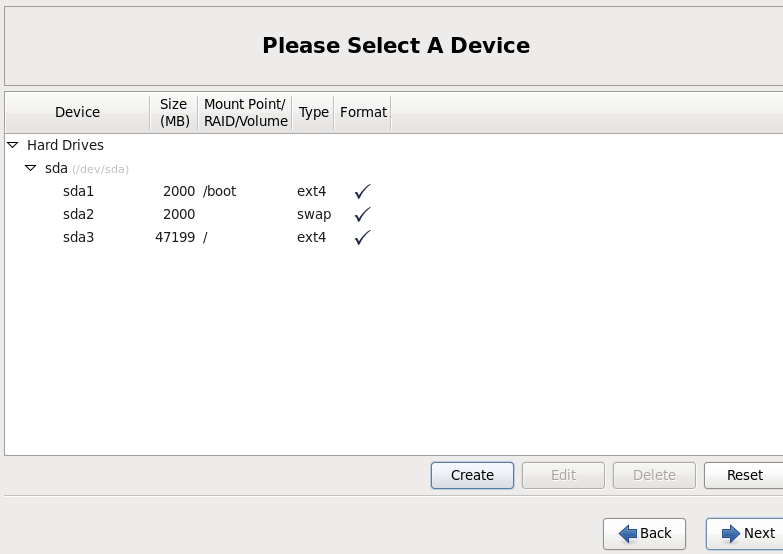
我的安装分区如下,3台都一样。
关于如何关闭防火墙
我这里不多说,请移步
hadoop 50070 无法访问问题解决汇总
关于如何配置静态ip和联网
我这里不多说,我的是如下,请移步
CentOS 6.5静态IP的设置(NAT和桥接联网方式都适用)
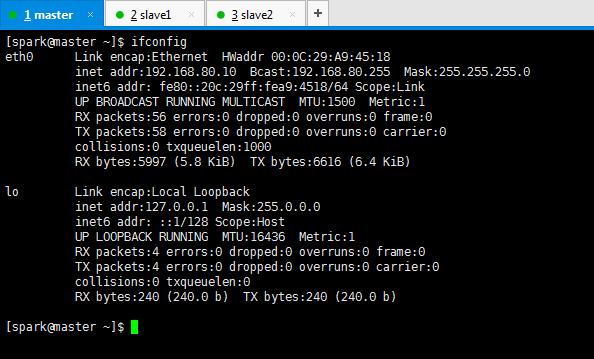
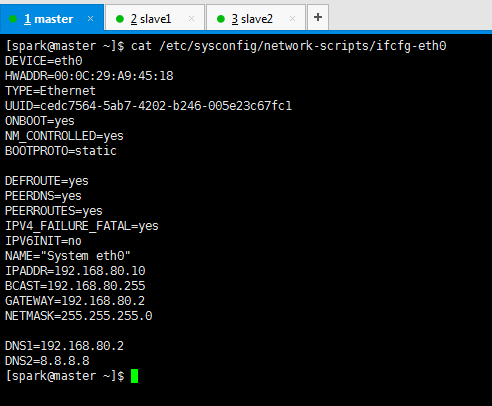

DEVICE=eth0 HWADDR=00:0C:29:A9:45:18 TYPE=Ethernet UUID=50fc177a-f282-4c83-bfbc-cb0f00b92507 ONBOOT=yes NM_CONTROLLED=yes BOOTPROTO=static DEFROUTE=yes PEERDNS=yes PEERROUTES=yes IPV4_FAILURE_FATAL=yes IPV6INIT=no NAME="System eth0" IPADDR=192.168.80.10 BCAST=192.168.80.255 GATEWAY=192.168.80.2 NETMASK=255.255.255.0 DNS1=192.168.80.2 DNS2=8.8.8.8

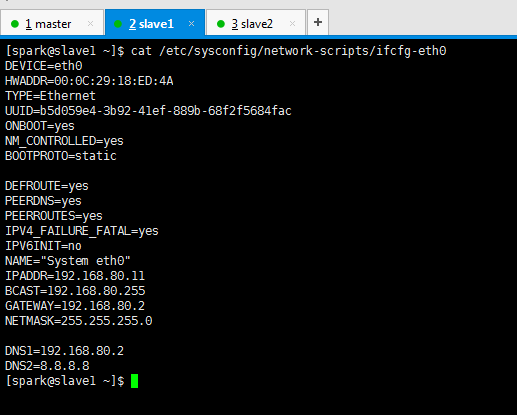
DEVICE=eth0 HWADDR=00:0C:29:18:ED:4A TYPE=Ethernet UUID=b5d059e4-3b92-41ef-889b-68f2f5684fac ONBOOT=yes NM_CONTROLLED=yes BOOTPROTO=static DEFROUTE=yes PEERDNS=yes PEERROUTES=yes IPV4_FAILURE_FATAL=yes IPV6INIT=no NAME="System eth0" IPADDR=192.168.80.11 BCAST=192.168.80.255 GATEWAY=192.168.80.2 NETMASK=255.255.255.0 DNS1=192.168.80.2 DNS2=8.8.8.8
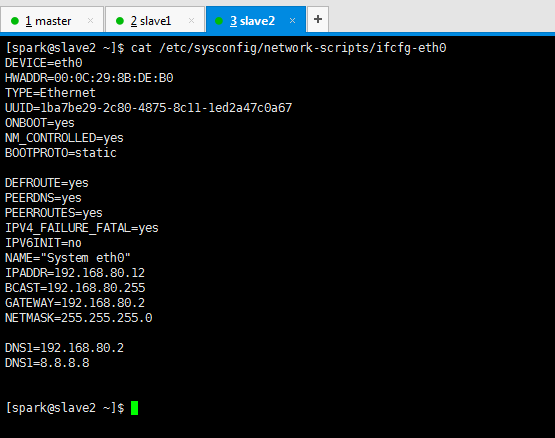
DEVICE=eth0 HWADDR=00:0C:29:8B:DE:B0 TYPE=Ethernet UUID=1ba7be29-2c80-4875-8c11-1ed2a47c0a67 ONBOOT=yes NM_CONTROLLED=yes BOOTPROTO=static DEFROUTE=yes PEERDNS=yes PEERROUTES=yes IPV4_FAILURE_FATAL=yes IPV6INIT=no NAME="System eth0" IPADDR=192.168.80.12 BCAST=192.168.80.255 GATEWAY=192.168.80.2 NETMASK=255.255.255.0 DNS1=192.168.80.2 DNS1=8.8.8.8
关于新建用户组和用户
我这里不多说,我是spark,请移步
新建用户组、用户、用户密码、删除用户组、用户(适合CentOS、Ubuntu)
关于安装ssh、机器本身、机器之间进行免密码通信和时间同步
我这里不多说,具体,请移步。在这一步,本人深有感受,有经验。最好建议拍快照。否则很容易出错!
机器本身,即master与master、slave1与slave1、slave2与slave2。
机器之间,即master与slave1、master与slave2。
slave1与slave2。
hadoop-2.6.0.tar.gz + spark-1.5.2-bin-hadoop2.6.tgz 的集群搭建(3节点和5节点皆适用)
关于如何先卸载自带的openjdk,再安装
我这里不多说,我是jdk-8u60-linux-x64.tar.gz,请移步
我的jdk是安装在/usr/local/jdk下,记得赋予权限组,chown -R spark:spark jdk
Centos 6.5下的OPENJDK卸载和SUN的JDK安装、环境变量配置
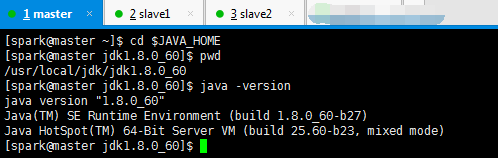
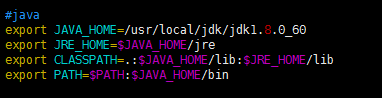
#java export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin
关于如何安装scala
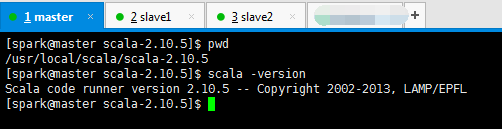
不多说,我这里是scala-2.10.5.tgz,请移步
我的scala安装在/usr/local/scala,记得赋予用户组,chown -R spark:spark scala
hadoop-2.6.0.tar.gz + spark-1.6.1-bin-hadoop2.6.tgz的集群搭建(单节点)(CentOS系统)

#scala export SCALA_HOME=/usr/local/scala/scala-2.10.5 export PATH=$PATH:$SCALA_HOME/bin
关于如何安装hadoop
我这里不多说,请移步见
我的spark安装目录是在/usr/local/hadoop/,记得赋予用户组,chown -R spark:spark hadoop
去看如何安装就好,至于hadoop的怎么配置。请见下面的hadoop on yarn模式的配置文件讲解。

#hadoop export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
关于如何安装spark
我这里不多说,请移步见
我的spark安装目录是在/usr/local/spark/,记得赋予用户组,chown -R spark:spark spark
只需去下面的博客,去看如何安装就好,至于spark的怎么配置。请见下面的spark standalone模式的配置文件讲解。
hadoop-2.6.0.tar.gz + spark-1.6.1-bin-hadoop2.6.tgz的集群搭建(单节点)(CentOS系统)

#spark export SPARK_HOME=/usr/local/spark/spark-1.6.1-bin-hadoop2.6 export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
关于zookeeper的安装
我这里不多说,请移步
hadoop-2.6.0-cdh5.4.5.tar.gz(CDH)的3节点集群搭建(含zookeeper集群安装)
以及,之后,在spark 里怎么配置zookeeper。
这里,我带大家来看官网
http://spark.apache.org/docs/latest
http://spark.apache.org/docs/latest/running-on-yarn.html
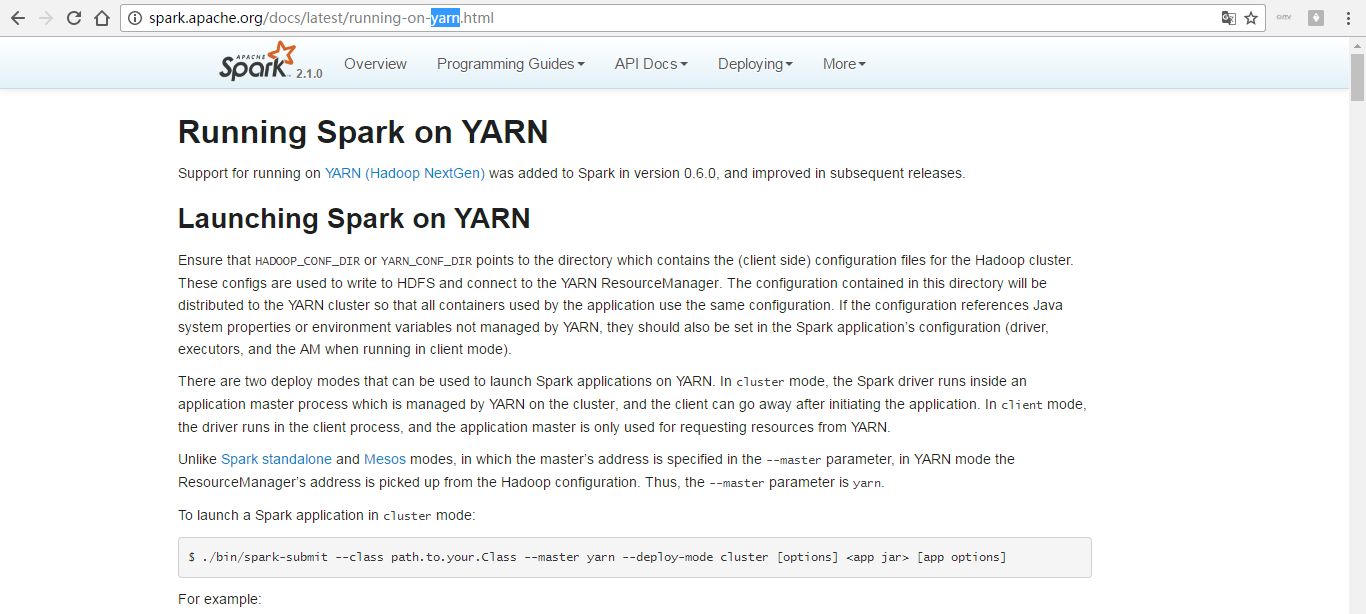

这里,不多说,很简单,自行去看官网。多看官网!
Hadoop on YARN配置与部署
这里,不多说,请移步
hadoop-2.6.0.tar.gz的集群搭建(3节点)(不含zookeeper集群安装)
hadoop-2.6.0-cdh5.4.5.tar.gz(CDH)的3节点集群搭建(含zookeeper集群安装)
hadoop-2.6.0.tar.gz + spark-1.5.2-bin-hadoop2.6.tgz 的集群搭建(3节点和5节点皆适用)
我这里,只贴出我最后的配置文件和启动界面
注意:3台都是一样的配置,master、slave1和slave2,我这里不多赘述。
hadoop-env.sh
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-2.6.0/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hadoop-2.6.0/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hadoop-2.6.0/dfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
yarn-site.xml
<configuration> <property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
slaves
slave1
slave2
masters
master
然后,新建目录
mkdir -p /usr/local/hadoop/hadoop-2.6.0/dfs/name mkdir -p /usr/local/hadoop/hadoop-2.6.0/dfs/data
mkdir -p /usr/local/hadoop/hadoop-2.6.0/tmp
在master节点上,格式化
$HADOOP_HOME/bin/hadoop namenode -format
启动hadoop进程
$HADOOP_HOME/sbin/start-all.sh
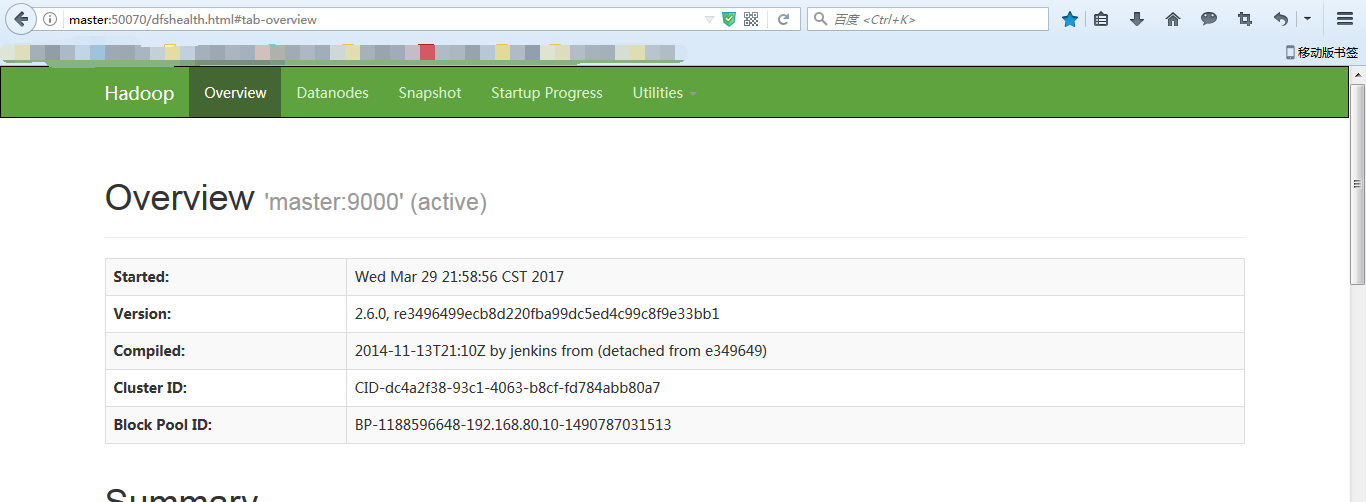
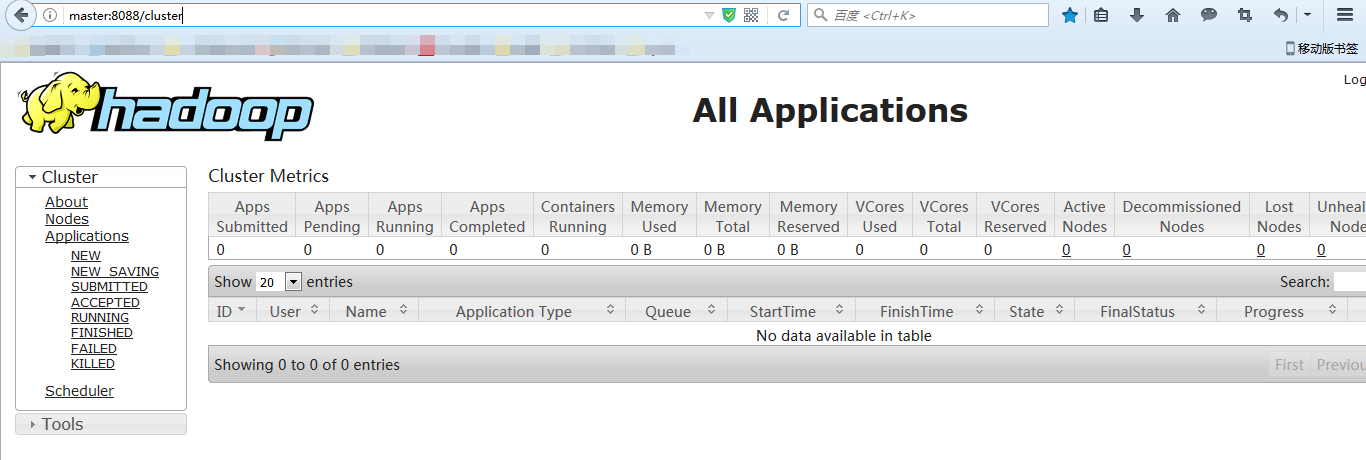
输入
http://master:50070
http://master:8088
Spark on YARN配置与部署(这里,作为补充)
编译时包含YARN
mvn -Pyarn -Phadoop-2.6 -Dhadoop.version=2.7.1 -Phive -Phive-thriftserver -Psparkr -DskipTests clean package /make-distribution.sh --name hadoop2.7.1 --tgz -Psparkr -Phadoop-2.6 -Dhadoop.version=2.7.1 -Phive -Phive-thriftserver –Pyarn
注意:
hadoop的版本跟你使用的hadoop要对应,建议使用CDH或者HDP的hadoop发行版,对应关系已经处理好了。
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
Spark on YARN的配置(这里,本博文的重点)
Spark On YARN安装非常简单,只需要下载编译好的Spark安装包,在一台带有Hadoop Yarn客户端的机器上解压即可。
Spark on YARN分为两种: YARN cluster(YARN standalone,0.9版本以前)和 YARN client。
YARN cluster是...我是用这种。
YARN client是将Client和Driver运行在一起(运行在本地),AM只用来管理资源。
如果需要返回数据到client就用YARN client模式。
如果数据存储到hdfs就用YARN cluster模式。
注意:3台都是一样的配置,master、slave1和slave2,我这里不多赘述。
Spark on YARN基本配置
配置HADOOP_CONF_DIR或者YARN_CONF_DIR环境变量。让Spark知道YARN的配置信息。
这句话是从哪里来的,其实,你若没有在spark-env.sh配置任何东西的话,直接去执行$SPARK_HOME/bin/spark-shell --master yarn就可以看到,它提示你去做。

有三种方式
(1)配置在spark-env.sh中 (我一般是用这种)(本博文也是这种)
(2)在提交spark应用之前export
(3) 配在到操作系统的环境变量中
注意:在yarn-site.xml,配上hostname
如果使用的是HDP,请在spark-defaults.conf中加入:(这里,作为补充)
spark.driver.extraJavaOptions -Dhdp.version=current
spark.yarn.am.extraJavaOptions -Dhdp.version=current
修改如下配置:
● slaves--指定在哪些节点上运行worker。
# # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # # A Spark Worker will be started on each of the machines listed below. slave1 slave2
● spark-defaults.conf---spark提交job时的默认配置
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# Default system properties included when running spark-submit.
# This is useful for setting default environmental settings.
# Example:
# spark.master spark://master:7077
# spark.eventLog.enabled true
# spark.eventLog.dir hdfs://namenode:8021/directory
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
大家,可以在这个配置文件里指定好,以后每次不需在命令行下指定了。当然咯,也可以不配置啦!(我一般是这里不配置,即这个文件不动它)
spark-defaults.conf (这个作为可选可不选)(是因为或者是在spark-submit里也是可以加入的)(一般不选,不然固定死了)(我一般是这里不配置,即这个文件不动它)
spark.master spark://master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/sparkHistoryLogs
spark.eventLog.compress true
spark.history.fs.update.interval 5
spark.history.ui.port 7777
spark.history.fs.logDirectory hdfs://master:9000/sparkHistoryLogs
● spark-env.sh—spark的环境变量
spark-shell运行在YARN上(这是Spark on YARN模式)
(包含YARN client和YARN cluster)(作为补充)
登陆安装Spark那台机器
bin/spark-shell --master yarn-client
或者
bin/spark-shell --master yarn-cluster
包括可以加上其他的,比如控制内存啊等。这很简单,不多赘述。
我这里就以YARN Client演示了。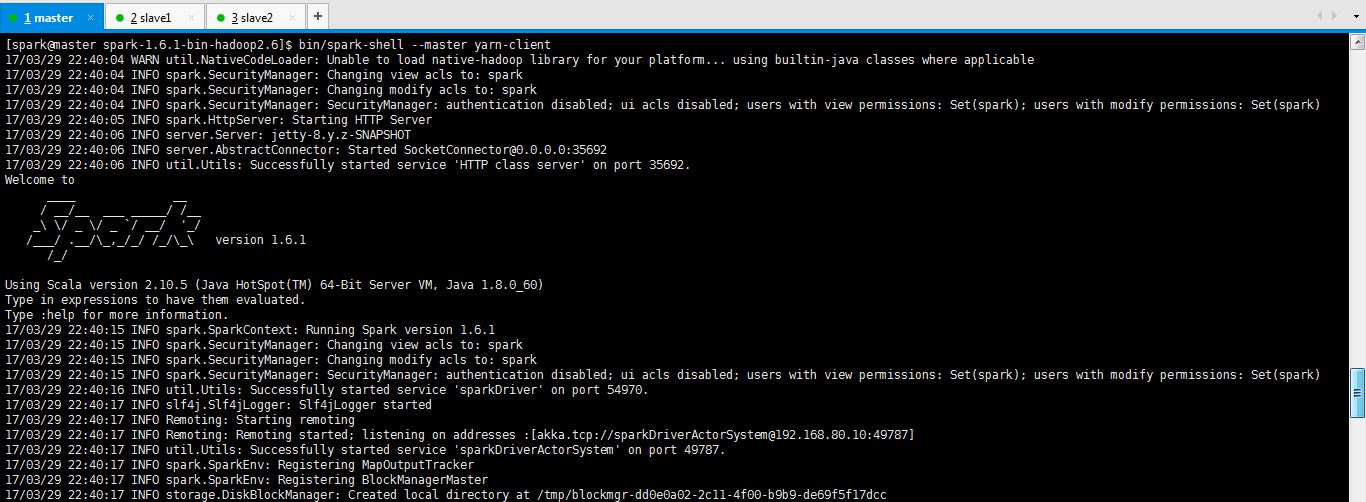
[spark@master spark-1.6.1-bin-hadoop2.6]$ bin/spark-shell --master yarn-client 17/03/29 22:40:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 17/03/29 22:40:04 INFO spark.SecurityManager: Changing view acls to: spark 17/03/29 22:40:04 INFO spark.SecurityManager: Changing modify acls to: spark 17/03/29 22:40:04 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); users with modify permissions: Set(spark) 17/03/29 22:40:05 INFO spark.HttpServer: Starting HTTP Server 17/03/29 22:40:06 INFO server.Server: jetty-8.y.z-SNAPSHOT 17/03/29 22:40:06 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:35692 17/03/29 22:40:06 INFO util.Utils: Successfully started service 'HTTP class server' on port 35692. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 1.6.1 /_/ Using Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_60)
注意,这里的--master是固定参数,不是说主机名是master。
Spark Shell启动时遇到<console>:14: error: not found: value spark import spark.implicits._ <console>:14: error: not found: value spark import spark.sql错误的解决办法(图文详解)
提交spark作业
为了出现问题,还是先看我写的这篇博客吧!
spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)
1、用yarn-client模式提交spark作业
在/usr/local/spark目录下创建文件夹
vi spark_pi.sh$SPARK_HOME/bin/spark-submit \ --class org.apache.spark.examples.JavaSparkPi \ --master yarn-client \ --num-executors 1 \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 \
$SPARK_HOME/lib/spark-examples-1.6.1-hadoop2.6.0.jar \
driver-memory不指定也可以,默认使用512M
executor-memory不指定的化, 默认是1G
chmod 777 spark_pi.sh ./spark_pi.sh
或者
[spark@master ~]$ $SPARK_HOME/bin/spark-submit \ > --class org.apache.spark.examples.JavaSparkPi \ > --master yarn-cluster \ > --num-executors 1 \ > --driver-memory 1g \ > --executor-memory 1g \ > --executor-cores 1 \ > $SPARK_HOME/lib/spark-examples-1.6.1-hadoop2.6.0.jar
driver-memory不指定也可以,默认使用512M
executor-memory不指定的化, 默认是1G
2、用yarn-cluster模式提交spark作业
在/usr/local/spark目录下创建文件夹
vi spark_pi.sh$SPARK_HOME/bin/spark-submit \ --class org.apache.spark.examples.JavaSparkPi \ --master yarn-cluster \ --num-executors 1 \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 1 \
$SPARK_HOME/lib/spark-examples-1.6.1-hadoop2.6.0.jar \
driver-memory不指定也可以,默认使用512M
executor-memory不指定的化, 默认是1G
chmod 777 spark_pi.sh
./spark_pi.sh
或者
[spark@master ~]$ $SPARK_HOME/bin/spark-submit \ > --class org.apache.spark.examples.JavaSparkPi \ > --master yarn-cluster \ > --num-executors 1 \ > --driver-memory 1g \ > --executor-memory 1g \ > --executor-cores 1 \ > $SPARK_HOME/lib/spark-examples-1.6.1-hadoop2.6.0.jar
driver-memory不指定也可以,默认使用512M
executor-memory不指定的化, 默认是1G
注意,这里的--master是固定参数
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号