
Elasticsearch 编程API入门系列---入门2(matchQuery查询、matchAllQuery查询、multiMatchQuery查询、queryStringQuery查询、组合查询、termQuery精确查询、实现分页、升降序、分组求sum、多索引库多类型查询、统计、分组聚合统计、分片查询、极速查询)
前提
Elasticsearch 编程API入门系列---入门1(Java Client类型、连接es集群、添加json格式的数据、添加map格式的数据、添加bean格式的数据、添加helper格式的数据、通过id get查询数据、局部更新数据、通过id来删除数据、求数据行总数和批量 bulk 操作数据)(含带你看官网)

我们继续。
test13测试(查询类型searchType)
https://www.elastic.co/guide/en/elasticsearch/reference/2.4/search-request-search-type.html
Elasticsearch之四种查询类型和搜索原理(博主推荐)

1 package zhouls.bigdata.myElasticsearch; 2 3 import static org.junit.Assert.*; 4 5 import java.net.InetAddress; 6 import java.util.HashMap; 7 import java.util.List; 8 9 import org.elasticsearch.action.bulk.BulkItemResponse; 10 import org.elasticsearch.action.bulk.BulkRequestBuilder; 11 import org.elasticsearch.action.bulk.BulkResponse; 12 import org.elasticsearch.action.delete.DeleteRequest; 13 import org.elasticsearch.action.get.GetResponse; 14 import org.elasticsearch.action.index.IndexRequest; 15 import org.elasticsearch.action.index.IndexResponse; 16 import org.elasticsearch.action.search.SearchResponse; 17 import org.elasticsearch.action.search.SearchType; 18 import org.elasticsearch.action.update.UpdateResponse; 19 import org.elasticsearch.client.transport.TransportClient; 20 import org.elasticsearch.cluster.node.DiscoveryNode; 21 import org.elasticsearch.common.settings.Settings; 22 import org.elasticsearch.common.transport.InetSocketTransportAddress; 23 import org.elasticsearch.common.transport.TransportAddress; 24 import org.elasticsearch.common.xcontent.XContentBuilder; 25 import org.elasticsearch.common.xcontent.XContentFactory; 26 import org.elasticsearch.index.query.MatchQueryBuilder.Operator; 27 import org.elasticsearch.index.query.QueryBuilders; 28 import org.elasticsearch.search.SearchHit; 29 import org.elasticsearch.search.SearchHits; 30 import org.elasticsearch.search.aggregations.Aggregation; 31 import org.elasticsearch.search.aggregations.AggregationBuilders; 32 import org.elasticsearch.search.aggregations.bucket.terms.Terms; 33 import org.elasticsearch.search.aggregations.bucket.terms.Terms.Bucket; 34 import org.elasticsearch.search.aggregations.metrics.sum.Sum; 35 import org.elasticsearch.search.sort.SortOrder; 36 import org.junit.Before; 37 import org.junit.Test; 38 39 import com.fasterxml.jackson.databind.ObjectMapper; 40 import com.google.common.collect.ImmutableList; 41 42 public class TestEs { 43 44 //es和hadoop没关系啊,获取一个transportclient就可以操作es了 45 46 47 private TransportClient transportClient; 48 @Before//@Before和@Test的区别:每次执行都要先经过@Before,好比是,它是一个模板。 49 //before表示在执行每个test方法之前运行,常与@Test搭配使用 50 public void test0() throws Exception { 51 //获取TransportClient,来操作es 52 transportClient = TransportClient.builder().build(); 53 //需要使用9300端口 54 TransportAddress transportAddress = new InetSocketTransportAddress(InetAddress.getByName("192.168.80.10"), 9300); 55 //添加节点信息,最少指定集群内的某一个节点即可操作这个es集群 56 transportClient.addTransportAddress(transportAddress); 57 } 58 59 /** 60 * 用java代码测试的时候这样写是没有问题的,比较简单 61 * @throws Exception 62 */ 63 @Test 64 public void test1() throws Exception { 65 //获取TransportClient,来操作es 66 TransportClient transportClient = TransportClient.builder().build(); 67 //需要使用9300端口,指定es集群中的节点信息, 这个地方指定的端口是节点和节点之间的通信端口是9300,不是Http请求的端口9200. 68 TransportAddress transportAddress = new InetSocketTransportAddress(InetAddress.getByName("192.168.80.11"), 9300); 69 //添加节点信息,最少指定集群内的某一个节点即可操作这个es集群 70 transportClient.addTransportAddress(transportAddress); 71 System.out.println(transportClient.toString()); 72 } 73 74 /** 75 * 可以这样写,防止代码中指定的链接失效 76 * 但是写起来比较麻烦 77 * 在实际工作中这样写不是很靠谱,需要完善,做测试可以 78 * @throws Exception 79 */ 80 @Test 81 public void test2() throws Exception { 82 //获取TransportClient,来操作es,通过TransportClient可以和es集群交互 83 TransportClient transportClient = TransportClient.builder().build(); 84 //需要使用9300端口,指定es集群中的节点信息, 这个地方指定的端口是节点和节点之间的通信端口是9300,不是Http请求的端口9200. 85 TransportAddress transportAddress = new InetSocketTransportAddress(InetAddress.getByName("192.168.80.10"), 9300); 86 TransportAddress transportAddress1 = new InetSocketTransportAddress(InetAddress.getByName("192.168.80.11"), 9300); 87 TransportAddress transportAddress2 = new InetSocketTransportAddress(InetAddress.getByName("192.168.80.12"), 9300); 88 //添加节点信息,最少指定集群内的某一个节点即可操作这个es集群 89 transportClient.addTransportAddresses(transportAddress,transportAddress1,transportAddress2);//加入多个地址 90 System.out.println(transportClient.toString()); 91 } 92 93 /** 94 * 实际生产环境下面,建议这样用,加上下面这些配置信息 95 * @throws Exception 96 */ 97 @Test 98 public void test3() throws Exception { 99 //指定es的配置信息 100 Settings settings = Settings.settingsBuilder() 101 .put("cluster.name", "elasticsearch")//集群名称 102 //如果集群名称在配置文件中被修改了,那么在这需要显式定义一下 103 //es集群名称默认是 elasticsearch sniff嗅; 发现; 104 .put("client.transport.sniff", true)//开启集群的嗅探功能,只需要指定集群中一个节点信息即可获取到集群中的所有节点信息 105 //开启集群的嗅探功能,这样可以保证es会自动把集群中的其他节点信息添加到transportClient里面 106 //开启嗅探功能后 只要指定集群中的任意一个可用节点就可以了.当把代码运行之后TransportClient里面会把集群中所有节点的信息都拿到,能识别集群中的所有节点. 107 .build(); 108 109 //获取TransportClient,来操作es,//通过TransportClient可以和es集群交互 110 TransportClient transportClient = TransportClient.builder().settings(settings).build(); 111 //需要使用9300端口,指定es集群中的节点信息, 这个地方指定的端口是节点和节点之间的通信端口是9300,不是Http请求的端口9200. 112 TransportAddress transportAddress = new InetSocketTransportAddress(InetAddress.getByName("192.168.80.10"), 9300); 113 //添加节点信息,最少指定集群内的某一个节点即可操作这个es集群 114 transportClient.addTransportAddress(transportAddress); 115 116 //获取client链接到的节点信息, //获取当前transportClient连接到了集群多少个节点 117 List<DiscoveryNode> connectedNodes = transportClient.connectedNodes(); 118 for (DiscoveryNode discoveryNode : connectedNodes) {//for星型循环,将connectedNodes的值,一一传给DiscoveryNode discoveryNode 119 System.out.println(discoveryNode.getHostName());//打印192.168.80.10;192.168.80.11;192.168.80.12 120 //如果加入transportClient.addTransportAddresses(transportAddress) 只有一个ip,打印的就只有一个. 121 } 122 } 123 124 125 String index = "zhouls";//设置索引库 126 String type = "emp";//设置类型 127 128 //索引index(四种格式:json,map,bean,es helper) 129 130 /** 131 * index-1 json 132 * 实际工作中使用 133 * @throws Exception 134 */ 135 @Test 136 public void test4() throws Exception { 137 String jsonStr = "{\"name\":\"tom zhang\",\"age\":19}";//需要转义下 //向索引库中传入一个String字符串,还可以接受其他类型 138 IndexResponse indexResponse = transportClient.prepareIndex(index, type, "1")//添加一个id=1的数据 139 .setSource(jsonStr)//设值,这是json格式的 140 .get(); 141 //.execute().actionGet(); 这个和上面的get()方法是一样的,get()就是对.execute().actionGet() 进行了封装 142 System.out.println(indexResponse.getVersion()); 143 //得到这个数据的version,如果version=1代表是新添加的数据 144 } 145 146 147 148 /** 149 * index-2 hashmap 150 * 实际工作中使用 151 * @throws Exception 152 */ 153 @Test 154 public void test5() throws Exception {//把hashmap类型的数据放入index库 155 HashMap<String, Object> hashMap = new HashMap<String, Object>(); 156 //HashMap<String, Object> hashMap是迭代器变量 157 hashMap.put("name", "tom"); 158 hashMap.put("age", 15); 159 IndexResponse indexResponse = transportClient.prepareIndex(index, type, "2")//添加一个id=2的数据 160 .setSource(hashMap)//设值 161 .get(); 162 //.execute().actionGet(); 这个和上面的get()方法是一样的,get()就是对.execute().actionGet() 进行了封装 163 System.out.println(indexResponse.getVersion()); 164 } 165 166 167 168 169 /** 170 * index-3 bean 171 * 实际工作中使用 172 * 使用对象的时候需要把对象中的属性转化成json字符串 173 * @throws Exception 174 */ 175 176 // <dependency> 177 // <groupId>com.fasterxml.jackson.core</groupId> 178 // <artifactId>jackson-databind</artifactId> 179 // <version>2.1.3</version> 180 // </dependency> 181 182 183 @Test 184 public void test6() throws Exception {//传入一个对象到index索引库,这里是Person对象 185 Person person = new Person(); 186 person.setName("mack"); 187 person.setAge(20); 188 189 //如果直接传入一个person对象会报错,java.lang.IllegalArgumentException,必须把对象转换成一个Json字符串,使用jackson依赖 190 //IndexResponse indexResponse = transportClient.prepareIndex(index, type, "9").setSource(person).get(); 191 192 193 ObjectMapper objectMapper = new ObjectMapper(); 194 String writeValueAsString = objectMapper.writeValueAsString(person); 195 IndexResponse indexResponse = transportClient.prepareIndex(index, type, "3") 196 .setSource(writeValueAsString) 197 .get(); 198 // IndexResponse indexResponse = transportClient.prepareIndex(index, type, "3").setSource(objectMapper.writeValueAsString(person)).get(); 199 200 System.out.println(indexResponse.getVersion()); 201 } 202 203 /** 204 * index -4 es helper 205 * 测试数据这样使用 206 * @throws Exception 207 */ 208 @Test 209 public void test7() throws Exception { 210 XContentBuilder builder = XContentFactory.jsonBuilder()//XContentFactory 这个是ES官方提供的可以构建Json字符串的工具类. 211 .startObject() 212 .field("name", "jessic") 213 .field("age", 28) 214 .endObject(); 215 216 IndexResponse indexResponse = transportClient.prepareIndex(index, type, "4") 217 .setSource(builder) 218 .get(); 219 System.out.println(indexResponse.getVersion()); 220 } 221 222 223 /** 224 * get 查询 225 * 通过id查询 226 * @throws Exception 227 */ 228 @Test 229 public void test8() throws Exception { 230 GetResponse getResponse = transportClient.prepareGet(index, type, "4")//查询id为4的数据 231 .get(); 232 System.out.println(getResponse.getSourceAsString()); 233 } 234 235 /** 236 * 局部更新 237 * @throws Exception 238 */ 239 @Test 240 public void test9() throws Exception { 241 XContentBuilder builder = XContentFactory.jsonBuilder()//XContentFactory 这个是ES官方提供的可以构建Json字符串的工具类. 242 .startObject() 243 .field("age", 29) 244 .endObject(); 245 246 UpdateResponse updateResponse = transportClient.prepareUpdate(index, type, "4")//更新id为4的数据 247 .setDoc(builder) 248 .get(); 249 System.out.println(updateResponse.getVersion());//version打印2 数据更新 250 } 251 252 /** 253 * 删除 254 * 通过id删除 255 * @throws Exception 256 */ 257 @Test 258 public void test10() throws Exception { 259 transportClient.prepareDelete(index, type, "4")//删除id为4的数据 260 .get(); 261 } 262 263 /** 264 * count 取总数 类似于sql中的 select count(1) from table; 265 * 求总数 266 * 类似于mysql中的select count(*) 267 */ 268 @Test 269 public void test11() throws Exception { 270 long count = transportClient.prepareCount(index)//查找索引库中的数据个数 271 .setTypes(type) 272 .get() 273 .getCount(); 274 System.out.println(count); 275 } 276 277 278 /** 279 * bulk 批量操作 适合初始化数据的时候使用,提高效率 280 * 批量操作 bulk 281 * @throws Exception 282 */ 283 @Test 284 public void test12() throws Exception { 285 BulkRequestBuilder prepareBulk = transportClient.prepareBulk(); 286 287 //for循环执行---- 288 //index请求 289 IndexRequest indexRequest = new IndexRequest(index, type, "10"); 290 indexRequest.source("{\"name\":\"zhangsan\",\"age\":17}"); 291 //delete请求 292 DeleteRequest deleteRequest = new DeleteRequest(index, type, "1"); 293 294 295 prepareBulk.add(indexRequest );//bulkBuilder中可以添加多个操作,这里一个是建立索引的操作. 296 prepareBulk.add(deleteRequest);//一个是删除的操作 297 298 //执行 bulk 299 BulkResponse bulkResponse = prepareBulk.get(); 300 if(bulkResponse.hasFailures()){//批量操作中可能有的操作会出现问题,这个地方对操作失败的处理 301 //有执行失败的 302 BulkItemResponse[] items = bulkResponse.getItems(); 303 for (BulkItemResponse bulkItemResponse : items) { 304 //获取失败信息,并打印 305 System.out.println(bulkItemResponse.getFailureMessage()); 306 } 307 }else{ 308 System.out.println("全部执行成功!"); 309 } 310 } 311 312 /** 313 * 查询 314 * 315 * QUERY_AND_FETCH:只追求查询性能的时候可以选择 316 * QUERY_THEN_FETCH:默认 317 * DFS_QUERY_AND_FETCH:只需要排名准确即可 318 * DFS_QUERY_THEN_FETCH:对效率要求不是非常高,对查询准确度要求非常高,建议使用这一种 319 * @throws Exception 320 */ 321 @Test 322 public void test13() throws Exception { 323 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 324 .setTypes(type)//指定类型 325 .setQuery(QueryBuilders.matchQuery("name", "tom hehe"))//指定查询条件 326 .setSearchType(SearchType.DFS_QUERY_THEN_FETCH)//指定查询方式 327 .get(); 328 329 SearchHits hits = searchResponse.getHits(); 330 long totalHits = hits.getTotalHits(); 331 System.out.println("总数:"+totalHits); 332 333 //获取满足条件数据的详细内容 334 SearchHit[] hits2 = hits.getHits(); 335 for (SearchHit searchHit : hits2) { 336 System.out.println(searchHit.getSourceAsString()); 337 } 338 }


这里,我仅仅是以DFS_QUERY_THEN_FETCH为例,自己可以去试试其他的3个。
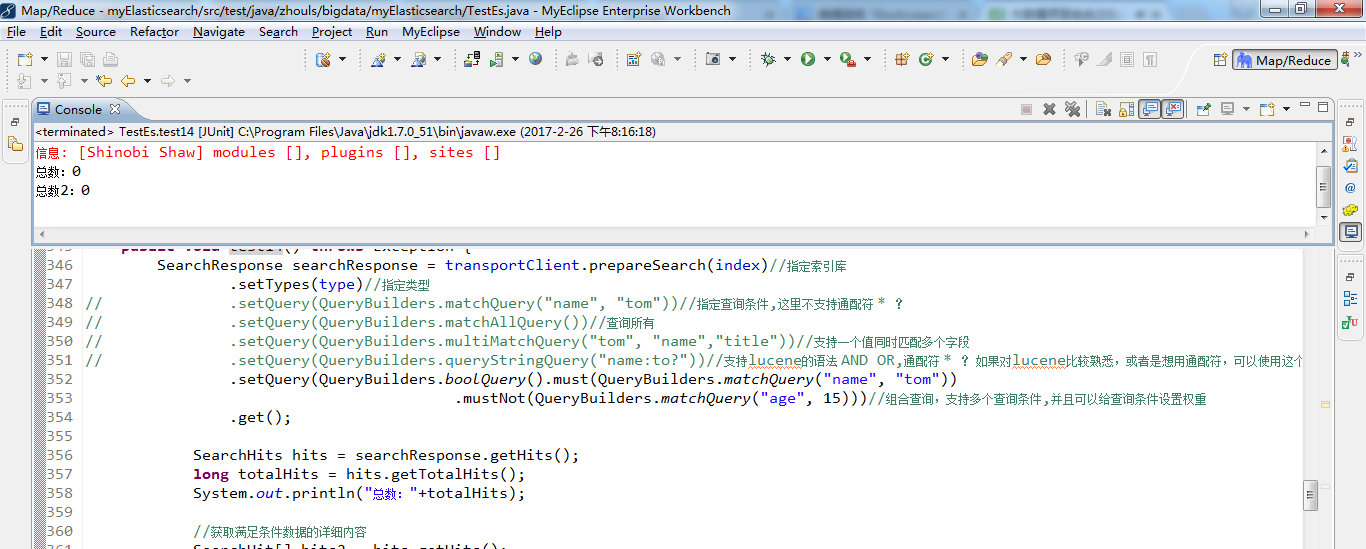
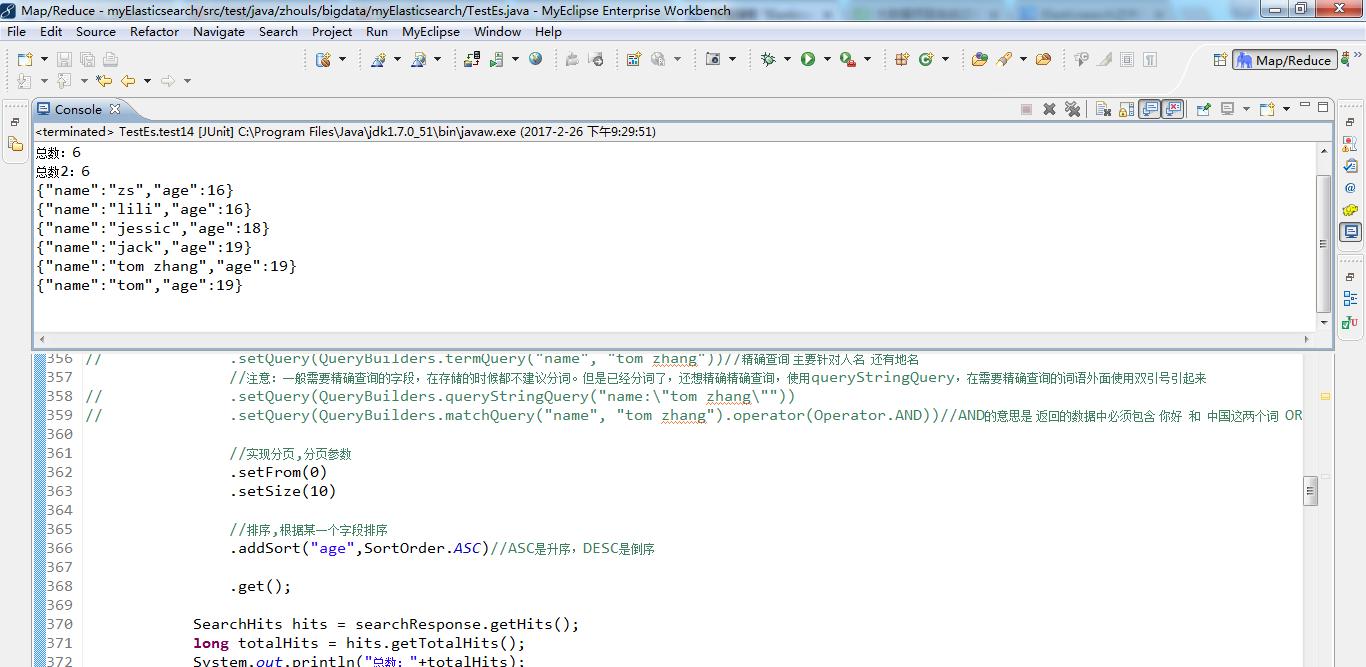
1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 .setExplain(true)//按照查询数据的匹配度返回数据 11 .get(); 12 13 SearchHits hits = searchResponse.getHits(); 14 long totalHits = hits.getTotalHits(); 15 System.out.println("总数:"+totalHits); 16 17 //获取满足条件数据的详细内容 18 SearchHit[] hits2 = hits.getHits(); 19 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 20 for (SearchHit searchHit : hits2) { 21 System.out.println(searchHit.getSourceAsString()); 22 } 23 }



1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 // .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 .setQuery(QueryBuilders.matchAllQuery())//查询所有 11 .setExplain(true)//按照查询数据的匹配度返回数据 12 .get(); 13 14 SearchHits hits = searchResponse.getHits(); 15 long totalHits = hits.getTotalHits(); 16 System.out.println("总数:"+totalHits); 17 18 //获取满足条件数据的详细内容 19 SearchHit[] hits2 = hits.getHits(); 20 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 21 for (SearchHit searchHit : hits2) { 22 System.out.println(searchHit.getSourceAsString()); 23 } 24 }

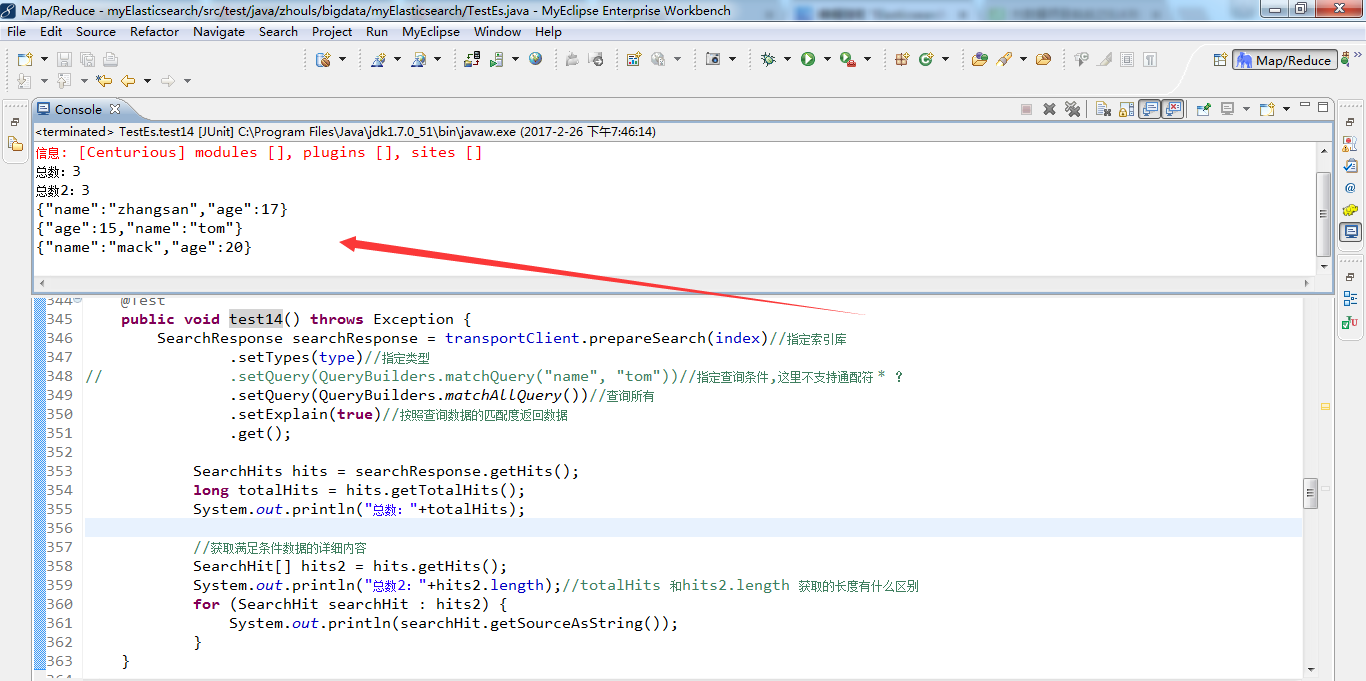

1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 // .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 // .setQuery(QueryBuilders.matchAllQuery())//查询所有 11 .setQuery(QueryBuilders.multiMatchQuery("tom", "name","title"))//支持一个值同时匹配多个字段 12 .setExplain(true)//按照查询数据的匹配度返回数据 13 .get(); 14 15 SearchHits hits = searchResponse.getHits(); 16 long totalHits = hits.getTotalHits(); 17 System.out.println("总数:"+totalHits); 18 19 //获取满足条件数据的详细内容 20 SearchHit[] hits2 = hits.getHits(); 21 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 22 for (SearchHit searchHit : hits2) { 23 System.out.println(searchHit.getSourceAsString()); 24 } 25 }


4、 queryStringQuery("name:to?") 或 queryStringQuery("name:to*")
?匹配一个 *匹配多个
1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 // .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 // .setQuery(QueryBuilders.matchAllQuery())//查询所有 11 // .setQuery(QueryBuilders.multiMatchQuery("tom", "name","title"))//支持一个值同时匹配多个字段 12 .setQuery(QueryBuilders.queryStringQuery("name:to?"))//queryStringQuery查询,支持lucene的语法 AND OR,通配符 * ? 如果对lucene比较熟悉,或者是想用通配符,可以使用这个 13 .setExplain(true)//按照查询数据的匹配度返回数据 14 .get(); 15 16 SearchHits hits = searchResponse.getHits(); 17 long totalHits = hits.getTotalHits(); 18 System.out.println("总数:"+totalHits); 19 20 //获取满足条件数据的详细内容 21 SearchHit[] hits2 = hits.getHits(); 22 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 23 for (SearchHit searchHit : hits2) { 24 System.out.println(searchHit.getSourceAsString()); 25 } 26 }



5、must、should、mustNot
这里,must类似于and。should类似于or
5.1must(QueryBuilders.matchQuery("name", "tom") must(QueryBuilders.matchQuery("age", 15))
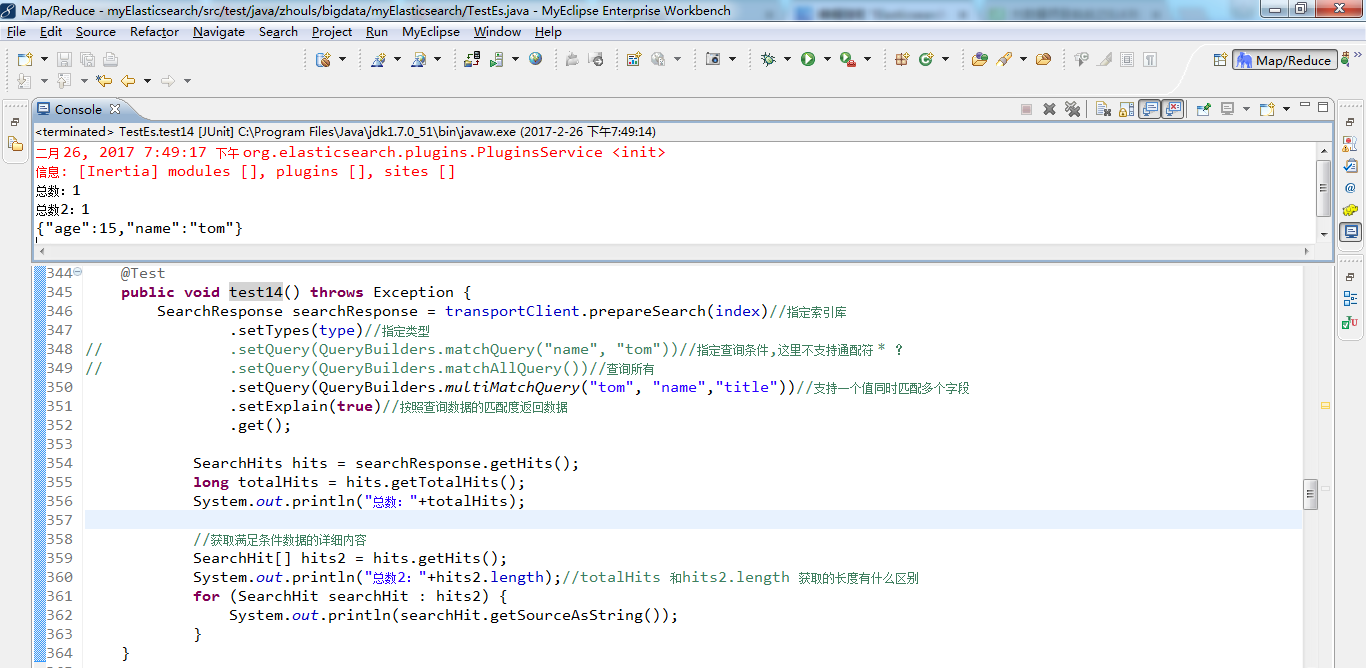
1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 // .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 // .setQuery(QueryBuilders.matchAllQuery())//查询所有 11 // .setQuery(QueryBuilders.multiMatchQuery("tom", "name","title"))//支持一个值同时匹配多个字段 12 // .setQuery(QueryBuilders.queryStringQuery("name:to?"))//支持lucene的语法 AND OR,通配符 * ? 如果对lucene比较熟悉,或者是想用通配符,可以使用这个 13 .setQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "tom")) 14 .must(QueryBuilders.matchQuery("age", 15)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 15 .get(); 16 17 SearchHits hits = searchResponse.getHits(); 18 long totalHits = hits.getTotalHits(); 19 System.out.println("总数:"+totalHits); 20 21 //获取满足条件数据的详细内容 22 SearchHit[] hits2 = hits.getHits(); 23 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 24 for (SearchHit searchHit : hits2) { 25 System.out.println(searchHit.getSourceAsString()); 26 } 27 }


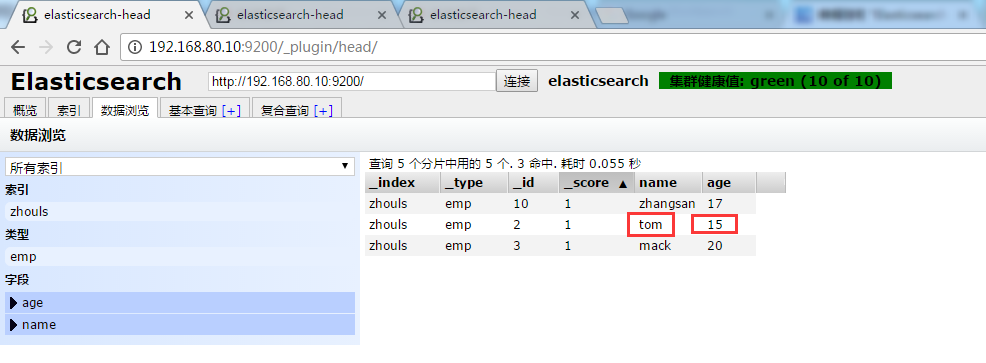
5.2 must(QueryBuilders.matchQuery("name", "tom")) mustNot(QueryBuilders.matchQuery("age", 15))
和 must(QueryBuilders.matchQuery("name", "tom")) mustNot(QueryBuilders.matchQuery("age", 16))
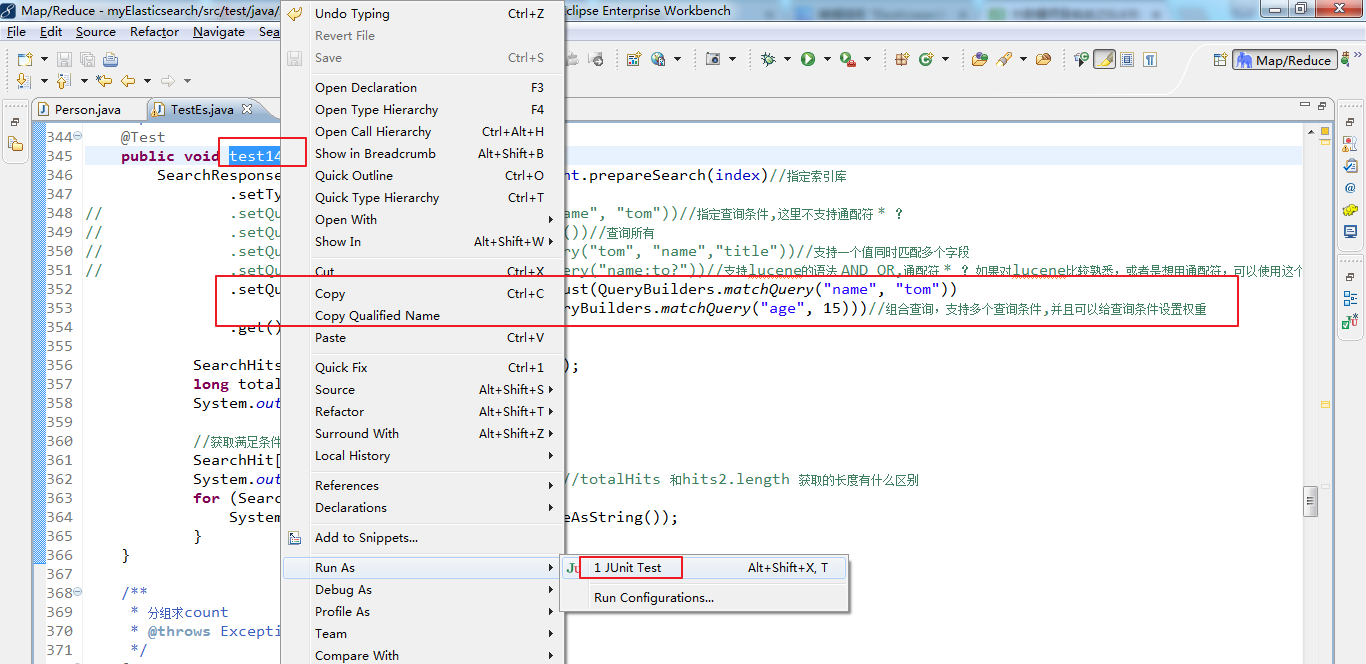
1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 // .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 // .setQuery(QueryBuilders.matchAllQuery())//查询所有 11 // .setQuery(QueryBuilders.multiMatchQuery("tom", "name","title"))//支持一个值同时匹配多个字段 12 // .setQuery(QueryBuilders.queryStringQuery("name:to?"))//支持lucene的语法 AND OR,通配符 * ? 如果对lucene比较熟悉,或者是想用通配符,可以使用这个 13 .setQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "tom")) 14 .mustNot(QueryBuilders.matchQuery("age", 16)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 15 .get(); 16 17 SearchHits hits = searchResponse.getHits(); 18 long totalHits = hits.getTotalHits(); 19 System.out.println("总数:"+totalHits); 20 21 //获取满足条件数据的详细内容 22 SearchHit[] hits2 = hits.getHits(); 23 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 24 for (SearchHit searchHit : hits2) { 25 System.out.println(searchHit.getSourceAsString()); 26 } 27 } 28


5.3 智力查询
为了更好地展现这效果,现我将现有的索引库删除。


[hadoop@HadoopMaster elasticsearch-2.4.3]$ jps
2167 Jps
1985 Elasticsearch
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XDELETE 'http://192.168.80.10:9200/zhouls/'
{"acknowledged":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
然后,再去看下,没了。



然后,新建如下:
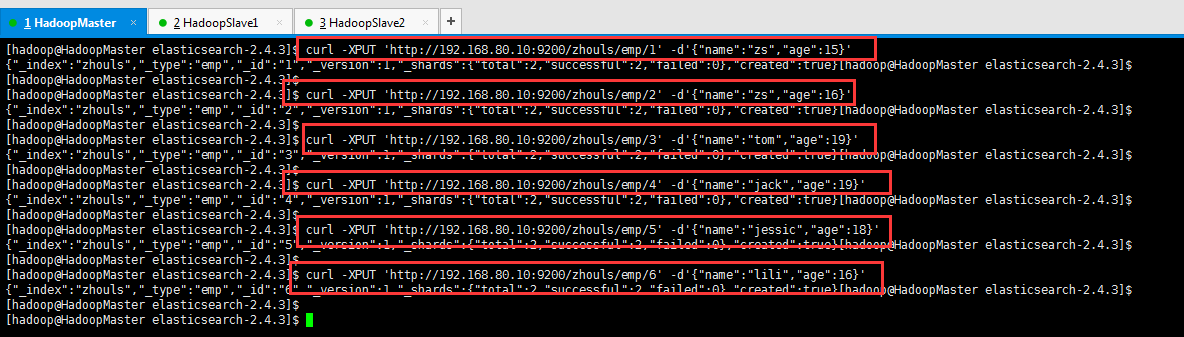
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/1' -d'{"name":"zs","age":15}'
{"_index":"zhouls","_type":"emp","_id":"1","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/2' -d'{"name":"zs","age":16}'
{"_index":"zhouls","_type":"emp","_id":"2","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/3' -d'{"name":"tom","age":19}'
{"_index":"zhouls","_type":"emp","_id":"3","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/4' -d'{"name":"jack","age":19}'
{"_index":"zhouls","_type":"emp","_id":"4","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/5' -d'{"name":"jessic","age":18}'
{"_index":"zhouls","_type":"emp","_id":"5","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/6' -d'{"name":"lili","age":16}'
{"_index":"zhouls","_type":"emp","_id":"6","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$

.should(QueryBuilders.matchQuery("name", "zs")) .should(QueryBuilders.matchQuery("age", 19))
1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 // .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 // .setQuery(QueryBuilders.matchAllQuery())//查询所有 11 // .setQuery(QueryBuilders.multiMatchQuery("tom", "name","title"))//支持一个值同时匹配多个字段 12 // .setQuery(QueryBuilders.queryStringQuery("name:to?"))//支持lucene的语法 AND OR,通配符 * ? 如果对lucene比较熟悉,或者是想用通配符,可以使用这个 13 // .setQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "tom")) 14 // .mustNot(QueryBuilders.matchQuery("age", 16)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 15 .setQuery(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("name", "zs")) 16 .should(QueryBuilders.matchQuery("age", 19)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 17 18 .get(); 19 20 SearchHits hits = searchResponse.getHits(); 21 long totalHits = hits.getTotalHits(); 22 System.out.println("总数:"+totalHits); 23 24 //获取满足条件数据的详细内容 25 SearchHit[] hits2 = hits.getHits(); 26 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 27 for (SearchHit searchHit : hits2) { 28 System.out.println(searchHit.getSourceAsString()); 29 } 30 }

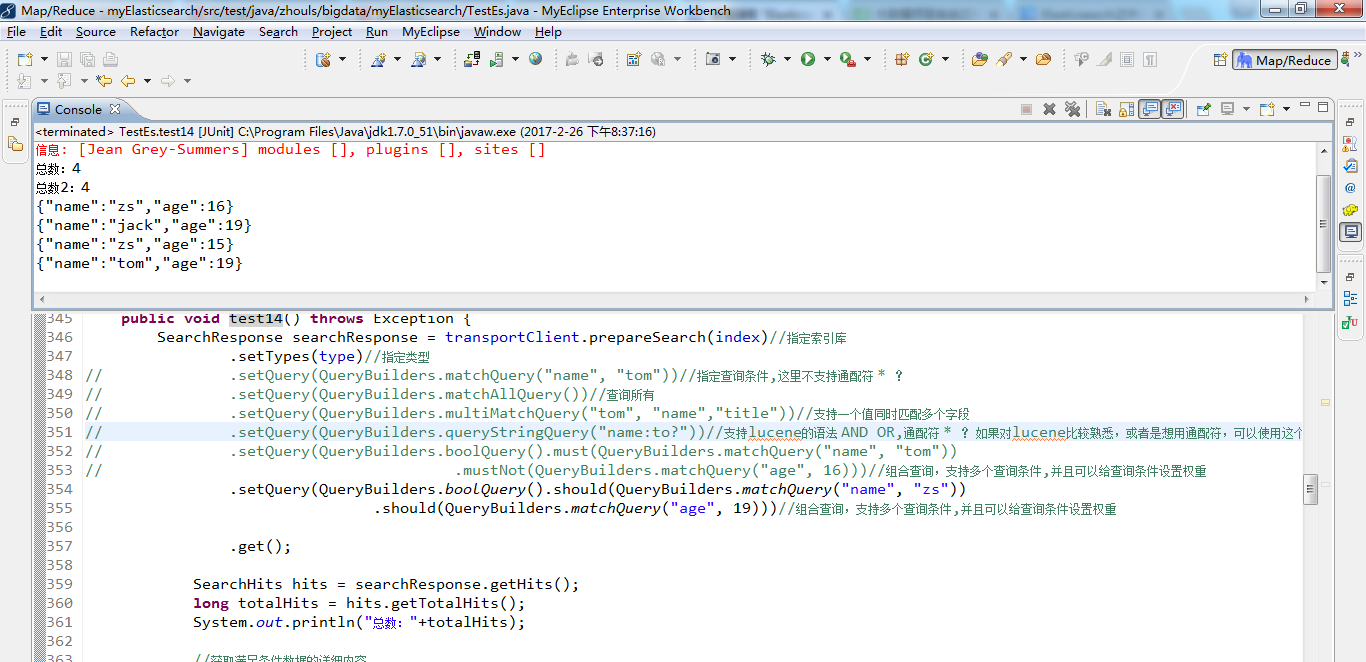
.should(QueryBuilders.matchQuery("name", "zs").boost(8.0f)) .should(QueryBuilders.matchQuery("age", 19).boost(1.0f))
1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 // .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 // .setQuery(QueryBuilders.matchAllQuery())//查询所有 11 // .setQuery(QueryBuilders.multiMatchQuery("tom", "name","title"))//支持一个值同时匹配多个字段 12 // .setQuery(QueryBuilders.queryStringQuery("name:to?"))//支持lucene的语法 AND OR,通配符 * ? 如果对lucene比较熟悉,或者是想用通配符,可以使用这个 13 // .setQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "tom")) 14 // .mustNot(QueryBuilders.matchQuery("age", 16)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 15 .setQuery(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("name", "zs").boost(8.0f)) 16 .should(QueryBuilders.matchQuery("age", 19).boost(1.0f)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 17 18 .get(); 19 20 SearchHits hits = searchResponse.getHits(); 21 long totalHits = hits.getTotalHits(); 22 System.out.println("总数:"+totalHits); 23 24 //获取满足条件数据的详细内容 25 SearchHit[] hits2 = hits.getHits(); 26 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 27 for (SearchHit searchHit : hits2) { 28 System.out.println(searchHit.getSourceAsString()); 29 } 30 }



5.4 termQuery("name", "tom zhang")
1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 // .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 // .setQuery(QueryBuilders.matchAllQuery())//查询所有 11 // .setQuery(QueryBuilders.multiMatchQuery("tom", "name","title"))//支持一个值同时匹配多个字段 12 // .setQuery(QueryBuilders.queryStringQuery("name:to?"))//支持lucene的语法 AND OR,通配符 * ? 如果对lucene比较熟悉,或者是想用通配符,可以使用这个 13 // .setQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "tom")) 14 // .mustNot(QueryBuilders.matchQuery("age", 16)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 15 // .setQuery(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("name", "zs").boost(8.0f)) 16 // .should(QueryBuilders.matchQuery("age", 19).boost(1.0f)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 17 .setQuery(QueryBuilders.termQuery("name", "tom zhang"))//精确查询 主要针对人名 还有地名 18 //注意:一般需要精确查询的字段,在存储的时候都不建议分词。但是已经分词了,还想精确精确查询,使用queryStringQuery,在需要精确查询的词语外面使用双引号引起来 19 20 21 .get(); 22 23 SearchHits hits = searchResponse.getHits(); 24 long totalHits = hits.getTotalHits(); 25 System.out.println("总数:"+totalHits); 26 27 //获取满足条件数据的详细内容 28 SearchHit[] hits2 = hits.getHits(); 29 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 30 for (SearchHit searchHit : hits2) { 31 System.out.println(searchHit.getSourceAsString()); 32 } 33 }
为了更好地分析,我这里,又再次将test4运行

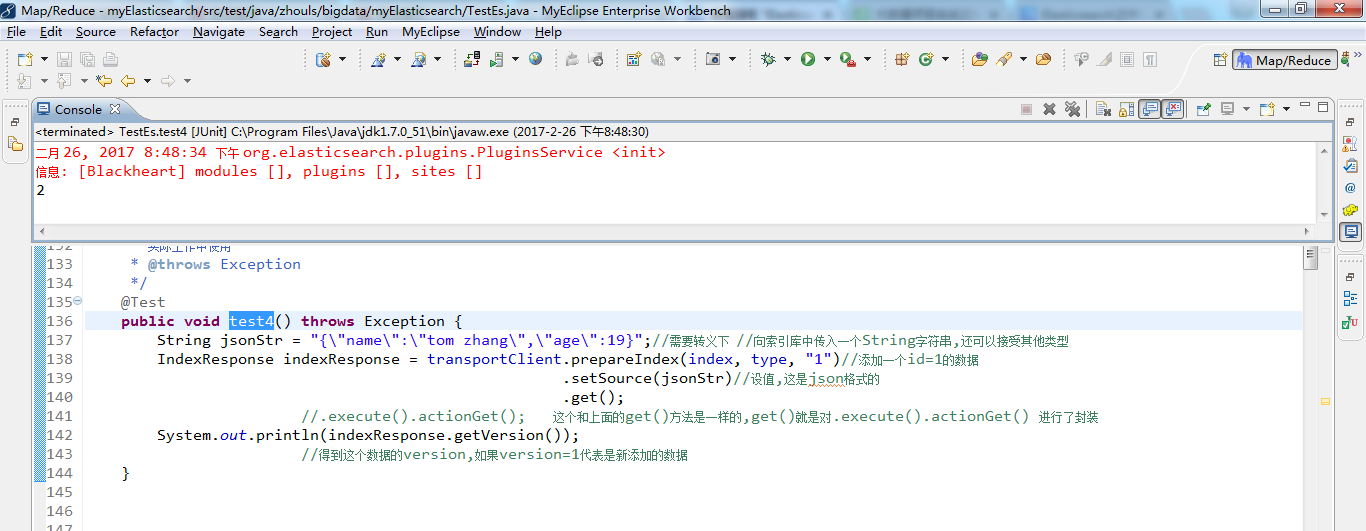

变成,


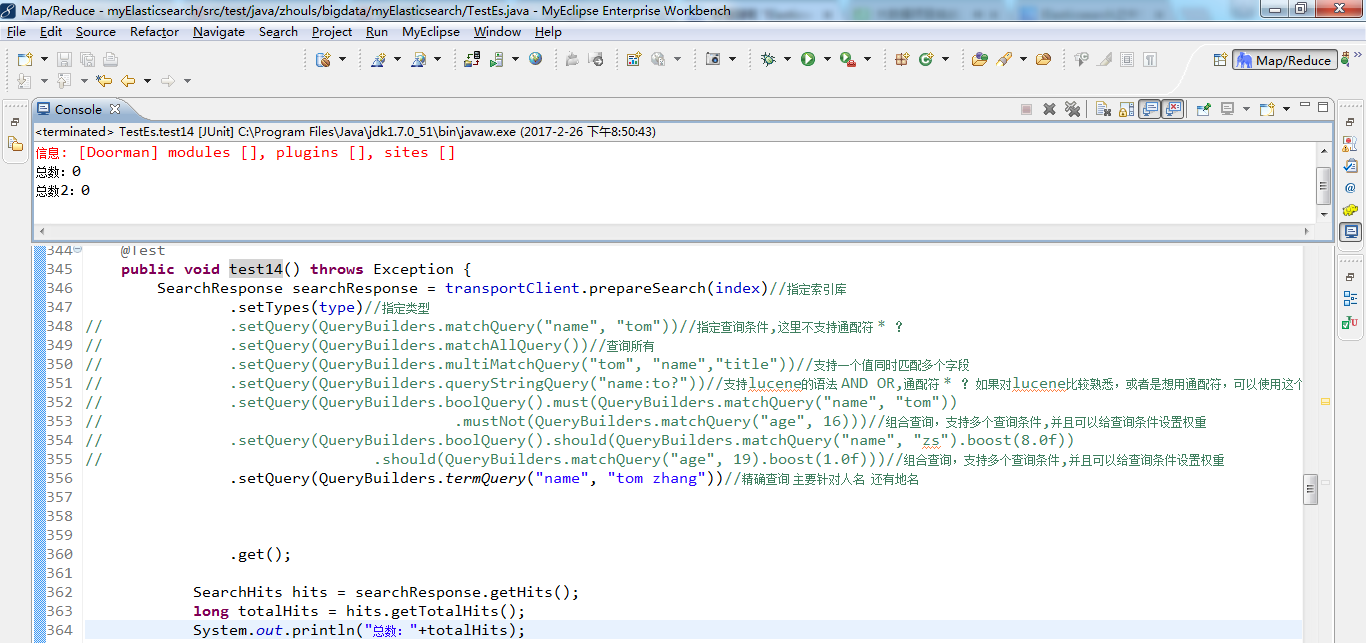
出现这个情况,是对的。
因为,默认是tom zhang中间有空格,是看成两个。
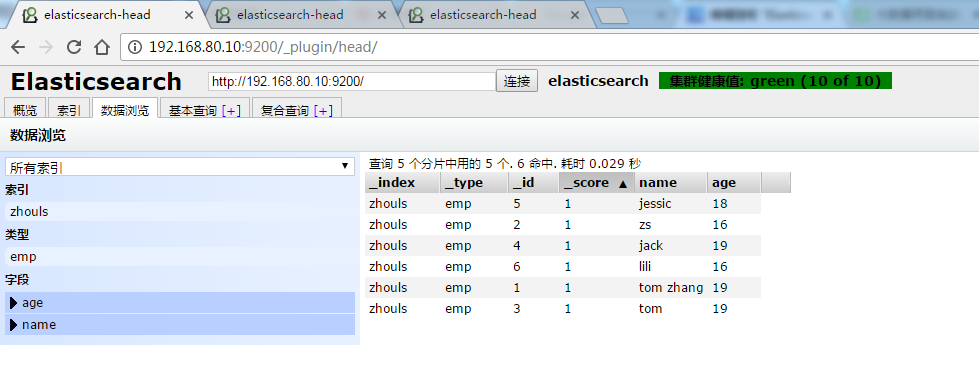
5.5 queryStringQuery("name:\"tom zhang\"")
1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 // .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 // .setQuery(QueryBuilders.matchAllQuery())//查询所有 11 // .setQuery(QueryBuilders.multiMatchQuery("tom", "name","title"))//支持一个值同时匹配多个字段 12 // .setQuery(QueryBuilders.queryStringQuery("name:to?"))//支持lucene的语法 AND OR,通配符 * ? 如果对lucene比较熟悉,或者是想用通配符,可以使用这个 13 // .setQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "tom")) 14 // .mustNot(QueryBuilders.matchQuery("age", 16)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 15 // .setQuery(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("name", "zs").boost(8.0f)) 16 // .should(QueryBuilders.matchQuery("age", 19).boost(1.0f)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 17 // .setQuery(QueryBuilders.termQuery("name", "tom zhang"))//精确查询 主要针对人名 还有地名 18 //注意:一般需要精确查询的字段,在存储的时候都不建议分词。但是已经分词了,还想精确精确查询,使用queryStringQuery,在需要精确查询的词语外面使用双引号引起来 19 .setQuery(QueryBuilders.queryStringQuery("name:\"tom zhang\"")) 20 21 .get(); 22 23 SearchHits hits = searchResponse.getHits(); 24 long totalHits = hits.getTotalHits(); 25 System.out.println("总数:"+totalHits); 26 27 //获取满足条件数据的详细内容 28 SearchHit[] hits2 = hits.getHits(); 29 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 30 for (SearchHit searchHit : hits2) { 31 System.out.println(searchHit.getSourceAsString()); 32 } 33 }


在索引库中存储了两份东西,一份就是之前所的分词的数据,还有一份是这个字段对应的内容。

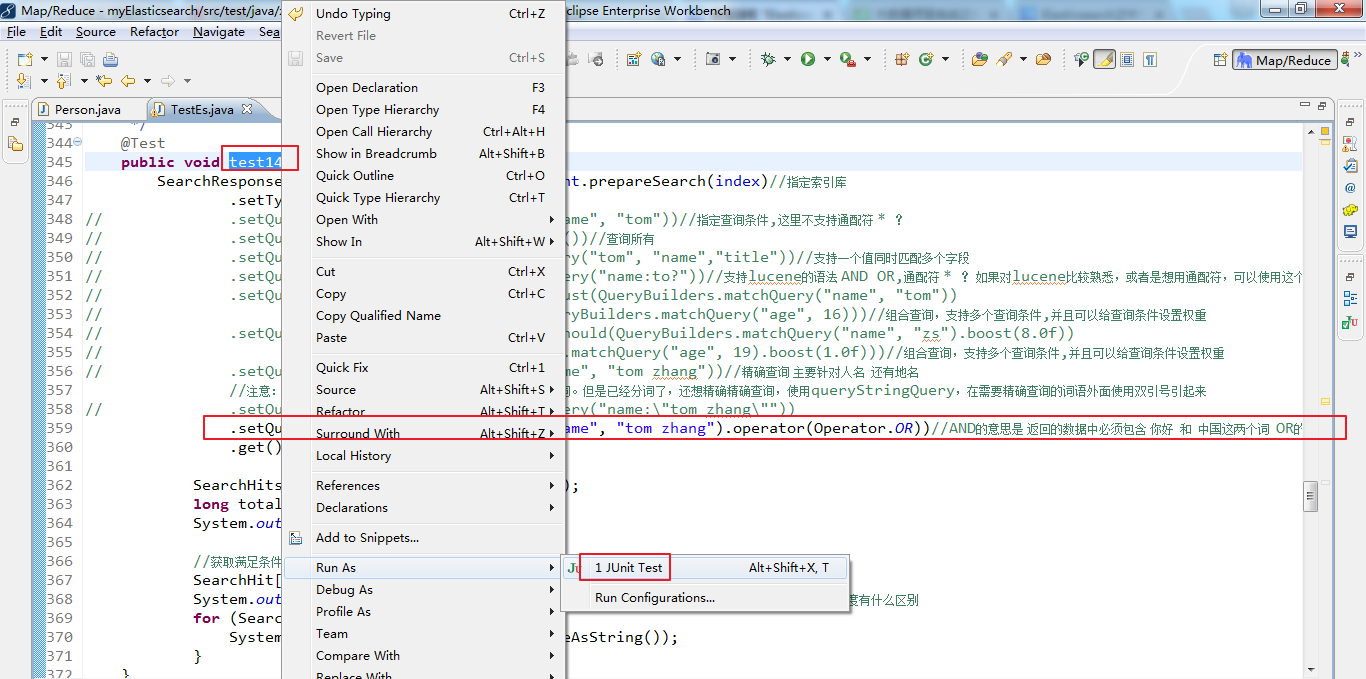
5.6 matchQuery("name", "tom zhang").operator(Operator.OR) 或 matchQuery("name", "tom zhang").operator(Operator.AND)
默认情况下,是OR。
1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 // .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 // .setQuery(QueryBuilders.matchAllQuery())//查询所有 11 // .setQuery(QueryBuilders.multiMatchQuery("tom", "name","title"))//支持一个值同时匹配多个字段 12 // .setQuery(QueryBuilders.queryStringQuery("name:to?"))//支持lucene的语法 AND OR,通配符 * ? 如果对lucene比较熟悉,或者是想用通配符,可以使用这个 13 // .setQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "tom")) 14 // .mustNot(QueryBuilders.matchQuery("age", 16)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 15 // .setQuery(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("name", "zs").boost(8.0f)) 16 // .should(QueryBuilders.matchQuery("age", 19).boost(1.0f)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 17 // .setQuery(QueryBuilders.termQuery("name", "tom zhang"))//精确查询 主要针对人名 还有地名 18 //注意:一般需要精确查询的字段,在存储的时候都不建议分词。但是已经分词了,还想精确精确查询,使用queryStringQuery,在需要精确查询的词语外面使用双引号引起来 19 // .setQuery(QueryBuilders.queryStringQuery("name:\"tom zhang\"")) 20 .setQuery(QueryBuilders.matchQuery("name", "tom zhang").operator(Operator.OR))//AND的意思是 返回的数据中必须包含 你好 和 中国这两个词 OR的意思是只包含一个词即可 21 .get(); 22 23 SearchHits hits = searchResponse.getHits(); 24 long totalHits = hits.getTotalHits(); 25 System.out.println("总数:"+totalHits); 26 27 //获取满足条件数据的详细内容 28 SearchHit[] hits2 = hits.getHits(); 29 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 30 for (SearchHit searchHit : hits2) { 31 System.out.println(searchHit.getSourceAsString()); 32 } 33 }

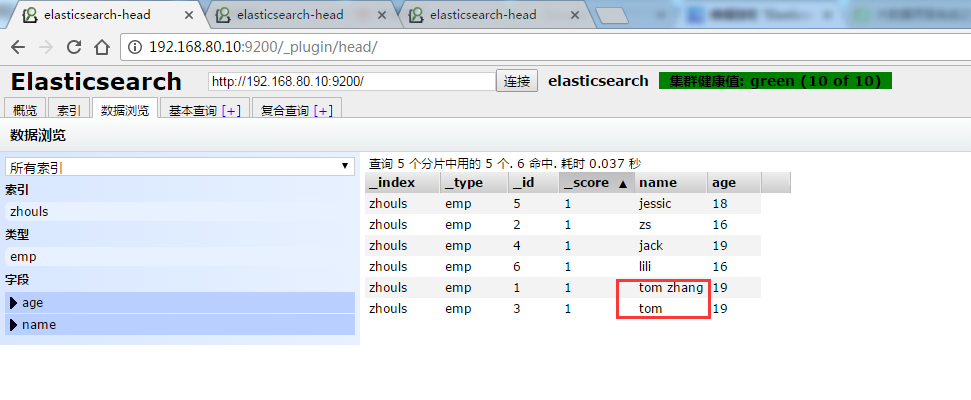
1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 // .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 // .setQuery(QueryBuilders.matchAllQuery())//查询所有 11 // .setQuery(QueryBuilders.multiMatchQuery("tom", "name","title"))//支持一个值同时匹配多个字段 12 // .setQuery(QueryBuilders.queryStringQuery("name:to?"))//支持lucene的语法 AND OR,通配符 * ? 如果对lucene比较熟悉,或者是想用通配符,可以使用这个 13 // .setQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "tom")) 14 // .mustNot(QueryBuilders.matchQuery("age", 16)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 15 // .setQuery(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("name", "zs").boost(8.0f)) 16 // .should(QueryBuilders.matchQuery("age", 19).boost(1.0f)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 17 // .setQuery(QueryBuilders.termQuery("name", "tom zhang"))//精确查询 主要针对人名 还有地名 18 //注意:一般需要精确查询的字段,在存储的时候都不建议分词。但是已经分词了,还想精确精确查询,使用queryStringQuery,在需要精确查询的词语外面使用双引号引起来 19 // .setQuery(QueryBuilders.queryStringQuery("name:\"tom zhang\"")) 20 .setQuery(QueryBuilders.matchQuery("name", "tom zhang").operator(Operator.AND))//AND的意思是 返回的数据中必须包含 你好 和 中国这两个词 OR的意思是只包含一个词即可 21 .get(); 22 23 SearchHits hits = searchResponse.getHits(); 24 long totalHits = hits.getTotalHits(); 25 System.out.println("总数:"+totalHits); 26 27 //获取满足条件数据的详细内容 28 SearchHit[] hits2 = hits.getHits(); 29 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 30 for (SearchHit searchHit : hits2) { 31 System.out.println(searchHit.getSourceAsString()); 32 } 33 }



5.7 控制分页展现效果查询
尤其是,如果想往web项目去考虑的话,则,完全可由 .setFrom(数字) 和 .setSize(数字)控制来达到。
比如,有
.setFrom(20) .setSize(10)
.setFrom(30) .setSize(10)
1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 // .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 // .setQuery(QueryBuilders.matchAllQuery())//查询所有 11 // .setQuery(QueryBuilders.multiMatchQuery("tom", "name","title"))//支持一个值同时匹配多个字段 12 // .setQuery(QueryBuilders.queryStringQuery("name:to?"))//支持lucene的语法 AND OR,通配符 * ? 如果对lucene比较熟悉,或者是想用通配符,可以使用这个 13 // .setQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "tom")) 14 // .mustNot(QueryBuilders.matchQuery("age", 16)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 15 // .setQuery(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("name", "zs").boost(8.0f)) 16 // .should(QueryBuilders.matchQuery("age", 19).boost(1.0f)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 17 // .setQuery(QueryBuilders.termQuery("name", "tom zhang"))//精确查询 主要针对人名 还有地名 18 //注意:一般需要精确查询的字段,在存储的时候都不建议分词。但是已经分词了,还想精确精确查询,使用queryStringQuery,在需要精确查询的词语外面使用双引号引起来 19 // .setQuery(QueryBuilders.queryStringQuery("name:\"tom zhang\"")) 20 // .setQuery(QueryBuilders.matchQuery("name", "tom zhang").operator(Operator.AND))//AND的意思是 返回的数据中必须包含 你好 和 中国这两个词 OR的意思是只包含一个词即可 21 22 //实现分页,分页参数 23 .setFrom(0) 24 .setSize(10) 25 26 27 .get(); 28 29 SearchHits hits = searchResponse.getHits(); 30 long totalHits = hits.getTotalHits(); 31 System.out.println("总数:"+totalHits); 32 33 //获取满足条件数据的详细内容 34 SearchHit[] hits2 = hits.getHits(); 35 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 36 for (SearchHit searchHit : hits2) { 37 System.out.println(searchHit.getSourceAsString()); 38 } 39 }



5.8 排序,根据某一个字段排序(升序或倒序)
ASC是升序,DESC是倒序。
1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 // .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 // .setQuery(QueryBuilders.matchAllQuery())//查询所有 11 // .setQuery(QueryBuilders.multiMatchQuery("tom", "name","title"))//支持一个值同时匹配多个字段 12 // .setQuery(QueryBuilders.queryStringQuery("name:to?"))//支持lucene的语法 AND OR,通配符 * ? 如果对lucene比较熟悉,或者是想用通配符,可以使用这个 13 // .setQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "tom")) 14 // .mustNot(QueryBuilders.matchQuery("age", 16)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 15 // .setQuery(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("name", "zs").boost(8.0f)) 16 // .should(QueryBuilders.matchQuery("age", 19).boost(1.0f)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 17 // .setQuery(QueryBuilders.termQuery("name", "tom zhang"))//精确查询 主要针对人名 还有地名 18 //注意:一般需要精确查询的字段,在存储的时候都不建议分词。但是已经分词了,还想精确精确查询,使用queryStringQuery,在需要精确查询的词语外面使用双引号引起来 19 // .setQuery(QueryBuilders.queryStringQuery("name:\"tom zhang\"")) 20 // .setQuery(QueryBuilders.matchQuery("name", "tom zhang").operator(Operator.AND))//AND的意思是 返回的数据中必须包含 你好 和 中国这两个词 OR的意思是只包含一个词即可 21 22 //实现分页,分页参数 23 .setFrom(0) 24 .setSize(10) 25 26 //排序,根据某一个字段排序 27 .addSort("age",SortOrder.DESC)//ASC是升序,DESC是倒序 28 29 .get(); 30 31 SearchHits hits = searchResponse.getHits(); 32 long totalHits = hits.getTotalHits(); 33 System.out.println("总数:"+totalHits); 34 35 //获取满足条件数据的详细内容 36 SearchHit[] hits2 = hits.getHits(); 37 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 38 for (SearchHit searchHit : hits2) { 39 System.out.println(searchHit.getSourceAsString()); 40 } 41 }


from(18).to(19) gte(18).lte(19) gte(18).lt(19)
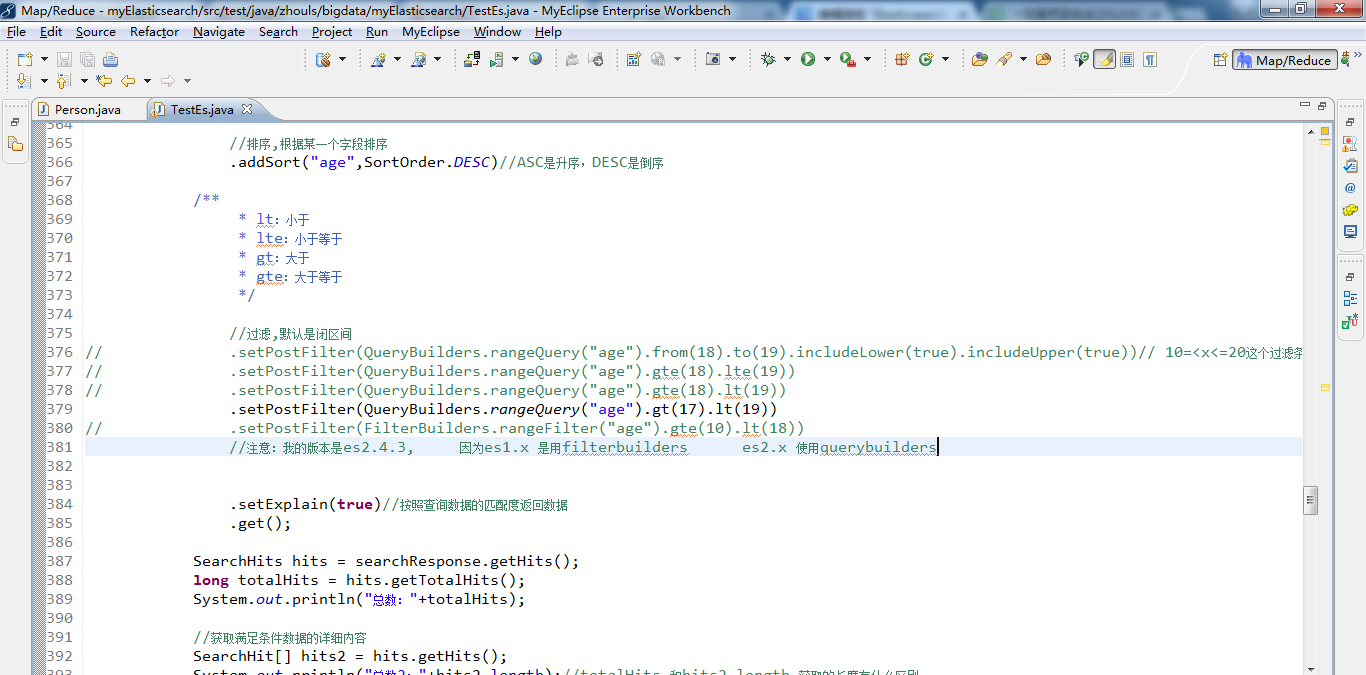
1 /** 2 * search查询详解 3 * @throws Exception 4 */ 5 @Test 6 public void test14() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index)//指定索引库 8 .setTypes(type)//指定类型 9 // .setQuery(QueryBuilders.matchQuery("name", "tom"))//指定查询条件,这里不支持通配符 * ? 10 // .setQuery(QueryBuilders.matchAllQuery())//查询所有 11 // .setQuery(QueryBuilders.multiMatchQuery("tom", "name","title"))//支持一个值同时匹配多个字段 12 // .setQuery(QueryBuilders.queryStringQuery("name:to?"))//支持lucene的语法 AND OR,通配符 * ? 如果对lucene比较熟悉,或者是想用通配符,可以使用这个 13 // .setQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "tom")) 14 // .mustNot(QueryBuilders.matchQuery("age", 16)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 15 // .setQuery(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("name", "zs").boost(8.0f)) 16 // .should(QueryBuilders.matchQuery("age", 19).boost(1.0f)))//组合查询,支持多个查询条件,并且可以给查询条件设置权重 17 // .setQuery(QueryBuilders.termQuery("name", "tom zhang"))//精确查询 主要针对人名 还有地名 18 //注意:一般需要精确查询的字段,在存储的时候都不建议分词。但是已经分词了,还想精确精确查询,使用queryStringQuery,在需要精确查询的词语外面使用双引号引起来 19 // .setQuery(QueryBuilders.queryStringQuery("name:\"tom zhang\"")) 20 // .setQuery(QueryBuilders.matchQuery("name", "tom zhang").operator(Operator.AND))//AND的意思是 返回的数据中必须包含 你好 和 中国这两个词 OR的意思是只包含一个词即可 21 22 //实现分页,分页参数 23 .setFrom(0) 24 .setSize(10) 25 26 //排序,根据某一个字段排序 27 .addSort("age",SortOrder.DESC)//ASC是升序,DESC是倒序 28 29 /** 30 * lt:小于 31 * lte:小于等于 32 * gt:大于 33 * gte:大于等于 34 */ 35 36 //过滤,默认是闭区间 37 // .setPostFilter(QueryBuilders.rangeQuery("age").from(18).to(19).includeLower(true).includeUpper(true))// 10=<x<=20这个过滤条件可以缓存,多次查询效率高 38 // .setPostFilter(QueryBuilders.rangeQuery("age").gte(18).lte(19)) 39 // .setPostFilter(QueryBuilders.rangeQuery("age").gte(18).lt(19)) 40 .setPostFilter(QueryBuilders.rangeQuery("age").gt(17).lt(19)) 41 // .setPostFilter(FilterBuilders.rangeFilter("age").gte(10).lt(18)) 42 //注意:我的版本是es2.4.3, 因为es1.x 是用filterbuilders es2.x 使用querybuilders 43 44 45 .setExplain(true)//按照查询数据的匹配度返回数据 46 .get(); 47 48 SearchHits hits = searchResponse.getHits(); 49 long totalHits = hits.getTotalHits(); 50 System.out.println("总数:"+totalHits); 51 52 //获取满足条件数据的详细内容 53 SearchHit[] hits2 = hits.getHits(); 54 System.out.println("总数2:"+hits2.length);//totalHits 和hits2.length 获取的长度有什么区别 55 for (SearchHit searchHit : hits2) { 56 System.out.println(searchHit.getSourceAsString()); 57 } 58 }





高亮(后续)
按查询匹配度排序(后续)
test15测试(统计相同年龄的学员个数)
统计:facet(已废弃)使用aggregations 替代
根据字段进行分组统计
根据字段分组,统计其他字段的值
size设置为0,会获取所有数据,否则,默认只会返回前10个分组的数据。


为了更好的演示效果,我这里先删除现有的数据。

[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XDELETE 'http://192.168.80.10:9200/zhouls/'
{"acknowledged":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$


[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/1' -d'{"name":"tom","age":18}'
{"_index":"zhouls","_type":"emp","_id":"1","_version":1,"_shards":{"total":2,"successful":1,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/2' -d'{"name":"jack","age":29}'
{"_index":"zhouls","_type":"emp","_id":"2","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/3' -d'{"name":"jessica","age":18}'
{"_index":"zhouls","_type":"emp","_id":"3","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/4' -d'{"name":"dave","age":19}'
{"_index":"zhouls","_type":"emp","_id":"4","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/5' -d'{"name":"lilei","age":18}'
{"_index":"zhouls","_type":"emp","_id":"5","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/6' -d'{"name":"lili","age":29}'
{"_index":"zhouls","_type":"emp","_id":"6","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
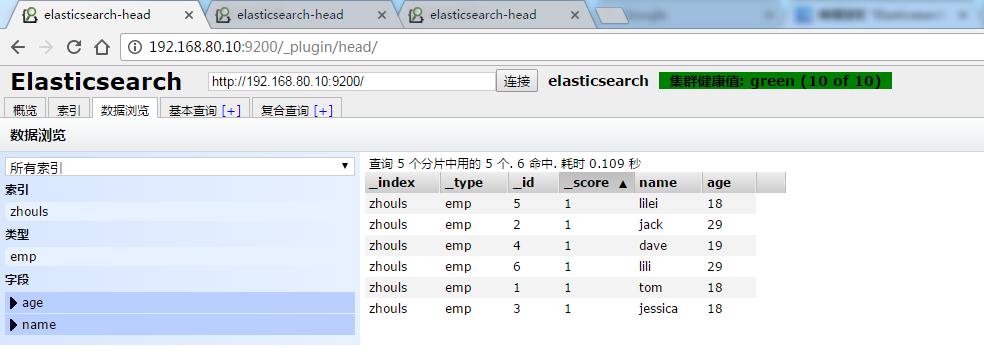

1 /** 2 * 分组求count 3 * @throws Exception 4 */ 5 @Test 6 public void test15() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index).setTypes(type) 8 .setQuery(QueryBuilders.matchAllQuery()) 9 //添加分组字段 10 .addAggregation(AggregationBuilders.terms("term_age").field("age").size(0))//设置为0默认会返回所有分组的数据 11 .get(); 12 //获取分组信息 13 Terms terms = searchResponse.getAggregations().get("term_age"); 14 List<Bucket> buckets = terms.getBuckets(); 15 for (Bucket bucket : buckets) { 16 System.out.println(bucket.getKey()+"--"+bucket.getDocCount()); 17 } 18 }



现在,我再增添一些数据,

[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/7' -d'{"name":"tom1","age":30}'
{"_index":"zhouls","_type":"emp","_id":"7","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/8' -d'{"name":"tom2","age":31}'
{"_index":"zhouls","_type":"emp","_id":"8","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/9' -d'{"name":"tom3","age":32}'
{"_index":"zhouls","_type":"emp","_id":"9","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/10' -d'{"name":"tom4","age":33}'
{"_index":"zhouls","_type":"emp","_id":"10","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/11' -d'{"name":"tom5","age":34}'
{"_index":"zhouls","_type":"emp","_id":"11","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/12' -d'{"name":"tom6","age":35}'
{"_index":"zhouls","_type":"emp","_id":"12","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/13' -d'{"name":"tom7","age":36}'
{"_index":"zhouls","_type":"emp","_id":"13","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/14' -d'{"name":"tom8","age":37}'
{"_index":"zhouls","_type":"emp","_id":"14","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/15' -d'{"name":"tom9","age":38}'
{"_index":"zhouls","_type":"emp","_id":"15","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
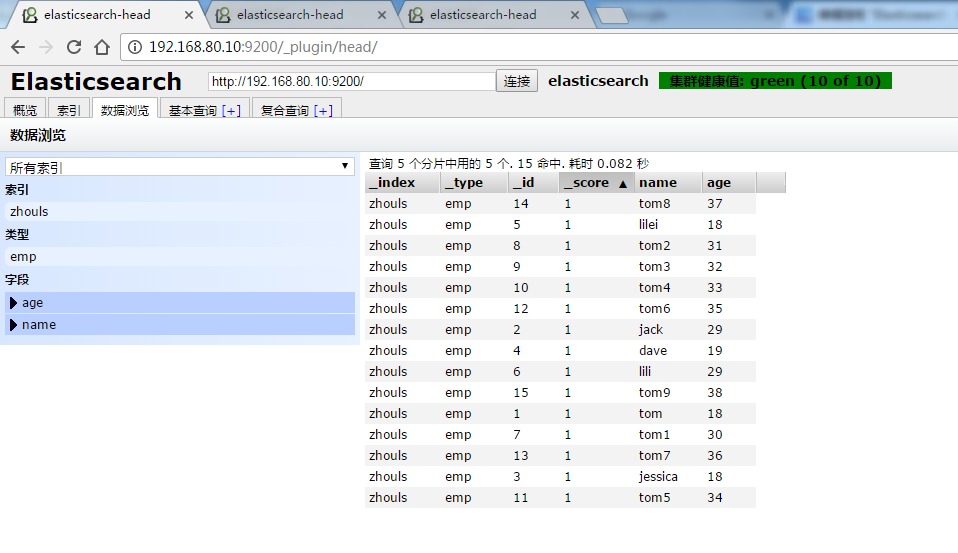

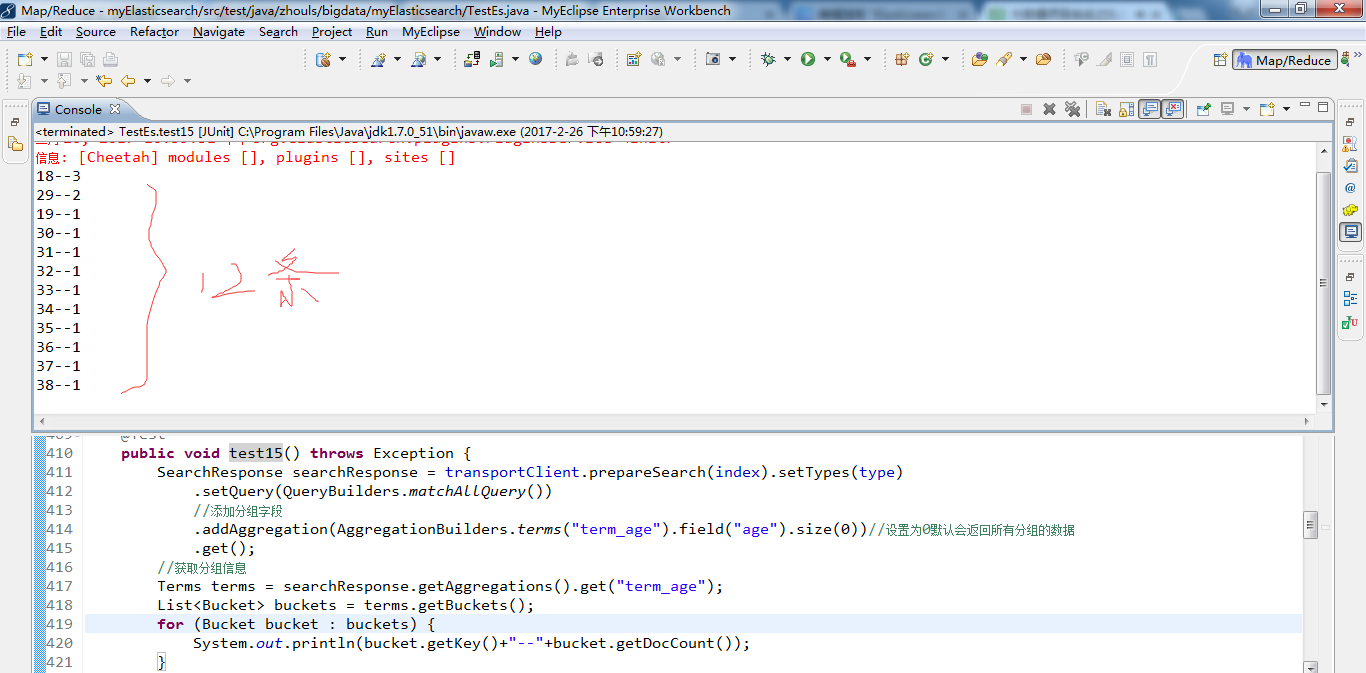
问题来了:明明是15条数据的,怎么只返回12条呢?这是默认分组,返回10条数据。
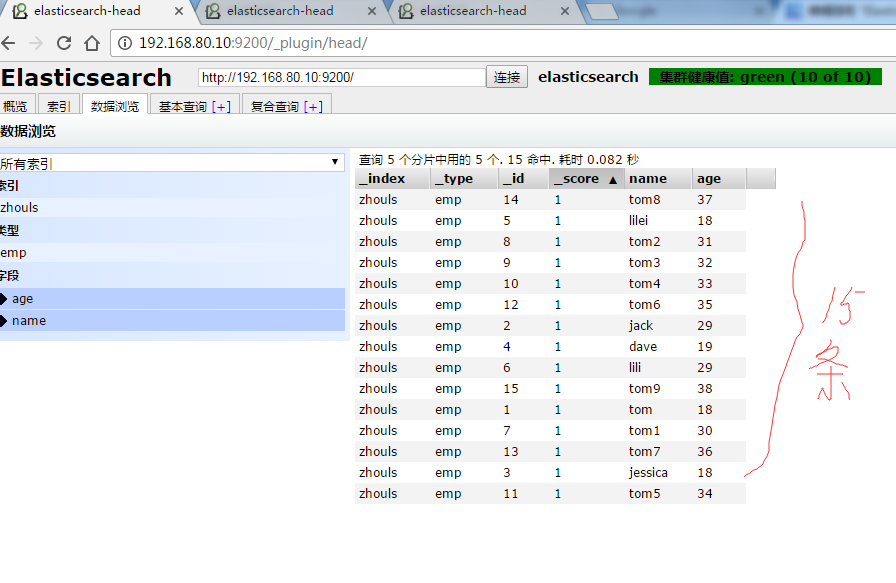

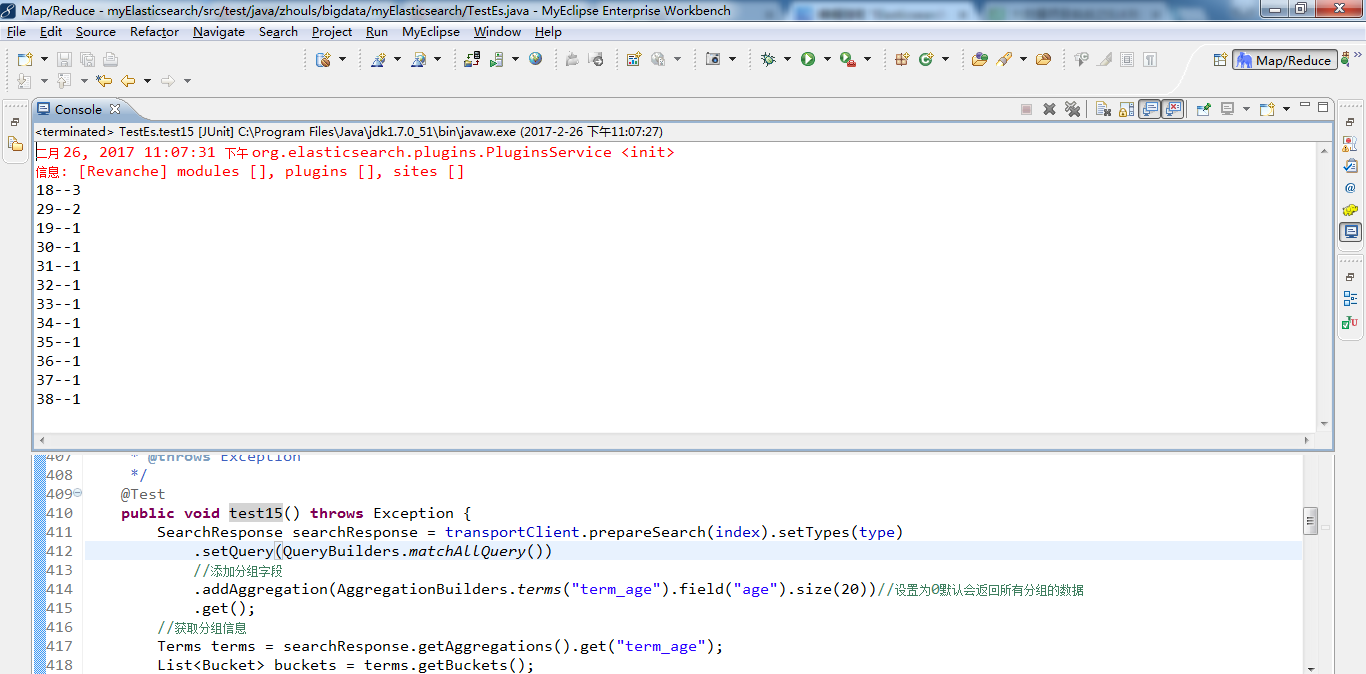

test16测试(统计每个学员的总成绩)

为了更好的演示效果,我这里先删除现有的数据。

[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XDELETE 'http://192.168.80.10:9200/zhouls'
{"acknowledged":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$

现在,我再增添一些数据,
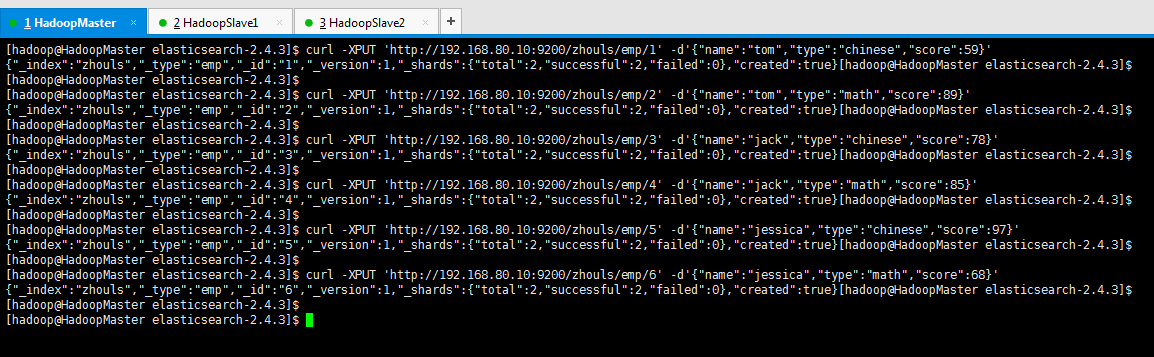
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/1' -d'{"name":"tom","type":"chinese","score":59}'
{"_index":"zhouls","_type":"emp","_id":"1","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/2' -d'{"name":"tom","type":"math","score":89}'
{"_index":"zhouls","_type":"emp","_id":"2","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/3' -d'{"name":"jack","type":"chinese","score":78}'
{"_index":"zhouls","_type":"emp","_id":"3","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/4' -d'{"name":"jack","type":"math","score":85}'
{"_index":"zhouls","_type":"emp","_id":"4","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/5' -d'{"name":"jessica","type":"chinese","score":97}'
{"_index":"zhouls","_type":"emp","_id":"5","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/6' -d'{"name":"jessica","type":"math","score":68}'
{"_index":"zhouls","_type":"emp","_id":"6","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
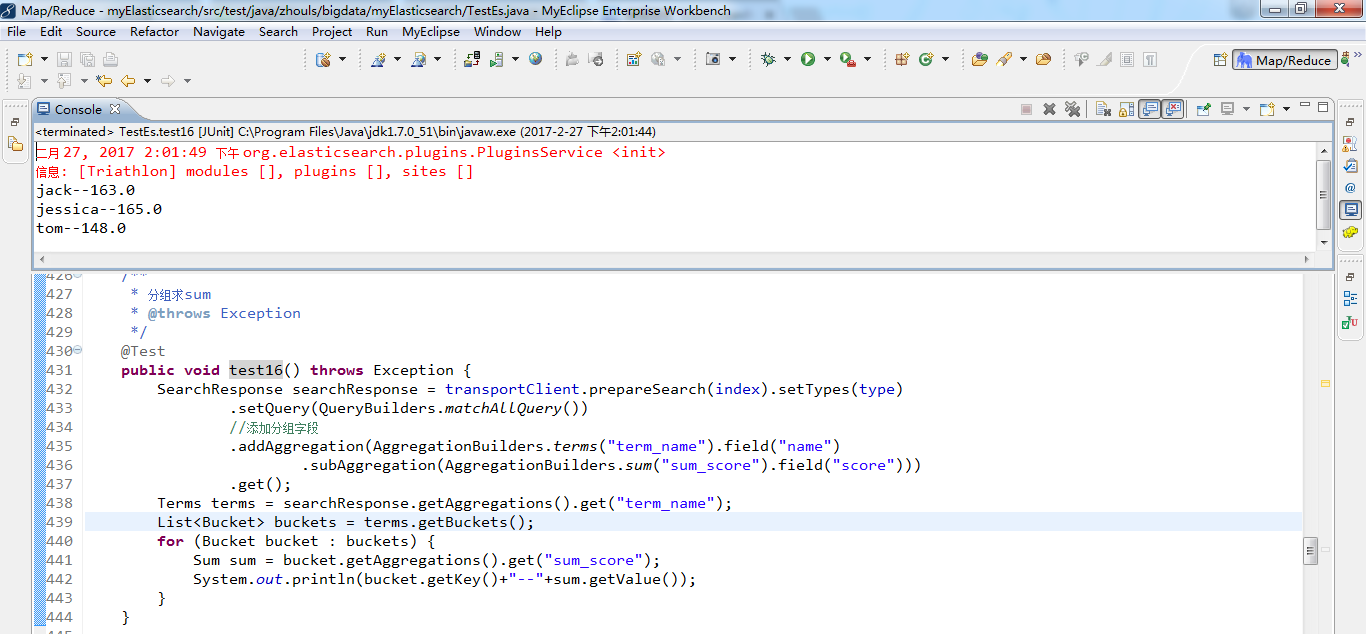
得到


1 /** 2 * 分组求sum 3 * @throws Exception 4 */ 5 @Test 6 public void test16() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch(index).setTypes(type) 8 .setQuery(QueryBuilders.matchAllQuery()) 9 //添加分组字段 10 .addAggregation(AggregationBuilders.terms("term_name").field("name") 11 .subAggregation(AggregationBuilders.sum("sum_score").field("score"))) 12 .get(); 13 Terms terms = searchResponse.getAggregations().get("term_name"); 14 List<Bucket> buckets = terms.getBuckets(); 15 for (Bucket bucket : buckets) { 16 Sum sum = bucket.getAggregations().get("sum_score"); 17 System.out.println(bucket.getKey()+"--"+sum.getValue()); 18 } 19 }


如何来程序编程,控制删除es里的索引库?
答:以下是直接用命令行来删除。
Elasticsearch之curl删除索引库
curl -XDELETE 'http://192.168.80.10:9200/zhouls'
transportClient.admin().indices().prepareDelete("zhouls").get();
注意:这样会把索引库及索引库中的所有数据都删掉,慎用。
es的分页
与SQL使用LIMIT来控制单“页”数量类似,Elasticsearch使用的是from以及size两个参数:
from:从哪条结果开始,默认值为0
size:每次返回多少个结果,默认值为10
假设每页显示5条结果,那么1至3页的请求就是:
GET /_search?size=5
GET /_search?size=5&from=5
GET /_search?size=5&from=10
注意:不要一次请求过多或者页码过大的结果,这么会对服务器造成很大的压力。因为它们会在返回前排序。一个请求会经过多个分片。每个分片都会生成自己的排序结果。然后再进行集中整理,以确保最终结果的正确性。
我们就先预想一下我们在搜索一个拥有5个主分片的索引。当我们请求第一页搜索的时候,每个分片产生自己前十名,然后将它们返回给请求节点,然后这个节点会将50条结果重新排序以产生最终的前十名。
现在想想一下我们想获得第1,000页,也就是第10,001到第10,010条结果,与之前同理,每一个分片都会先产生自己的前10,010名,然后请求节点统一处理这50,050条结果,然后再丢弃掉其中的50,040条!
现在你应该明白了,在分布式系统中,大页码请求所消耗的系统资源是呈指数式增长的。这也是为什么网络搜索引擎不会提供超过1,000条搜索结果的原因。
比如
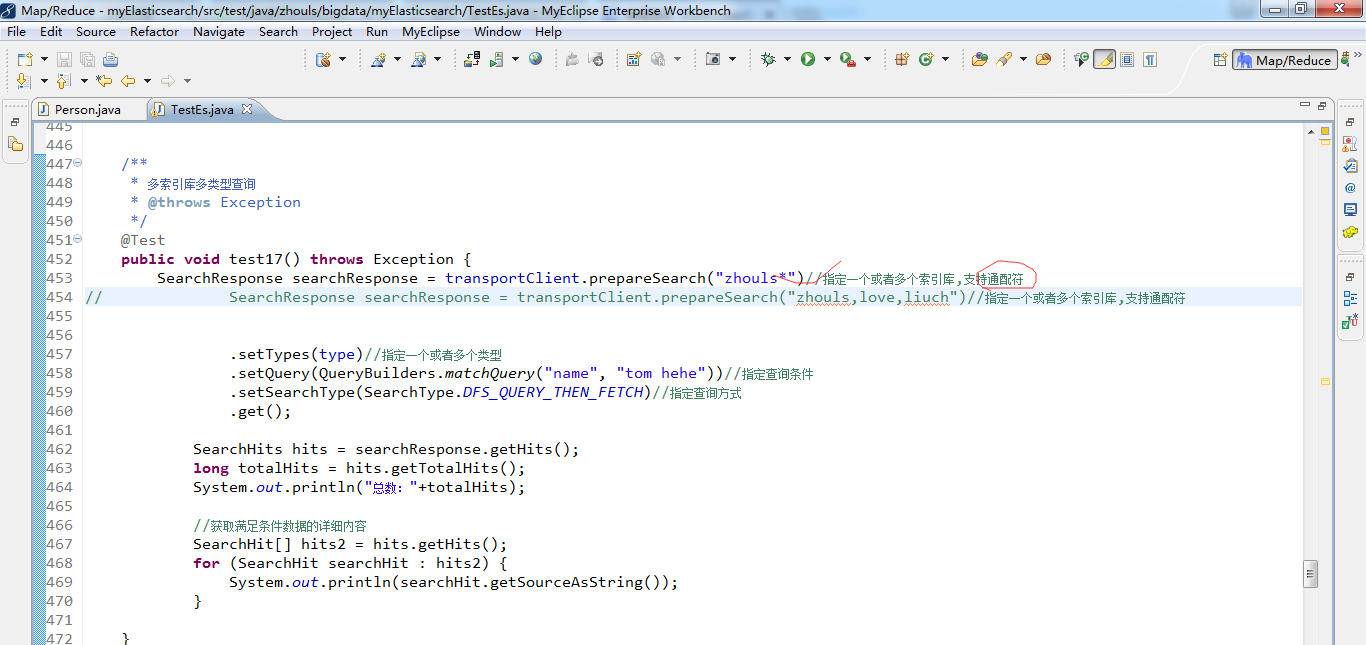
test17测试(多索引库多类型查询)(非常重要)
es作为分布式搜索引擎,天生就可以支持多个索引库以及多个类型,这一点非常非常重要!
注意:对于索引库,可支持通配符。
对于类型,不可支持通配符。
1 /** 2 * 多索引库多类型查询 3 * @throws Exception 4 */ 5 @Test 6 public void test17() throws Exception { 7 SearchResponse searchResponse = transportClient.prepareSearch("zhouls*")//指定一个或者多个索引库,支持通配符 8 // SearchResponse searchResponse = transportClient.prepareSearch("zhouls,love,liuch")//指定一个或者多个索引库,支持通配符 9 10 11 .setTypes(type)//指定一个或者多个类型,但不支持通配符 12 // .setTypes("emp","emp1")//指定一个或者多个类型,但不支持通配符 13 14 15 .setQuery(QueryBuilders.matchQuery("name", "tom hehe"))//指定查询条件 16 .setSearchType(SearchType.DFS_QUERY_THEN_FETCH)//指定查询方式 17 .get(); 18 19 SearchHits hits = searchResponse.getHits(); 20 long totalHits = hits.getTotalHits(); 21 System.out.println("总数:"+totalHits); 22 23 //获取满足条件数据的详细内容 24 SearchHit[] hits2 = hits.getHits(); 25 for (SearchHit searchHit : hits2) { 26 System.out.println(searchHit.getSourceAsString()); 27 } 28 29 }





Elasticsearch之settings和mappings
Elasticsearch之settings和mappings的意义
简单的说,就是
settings是修改分片和副本数的
mappings是修改字段和类型的
记住,可以用url方式来操作它们,也可以用java方式来操作它们。建议用url方式,因为简单很多。
1、ES中的settings
查询索引库的settings信息
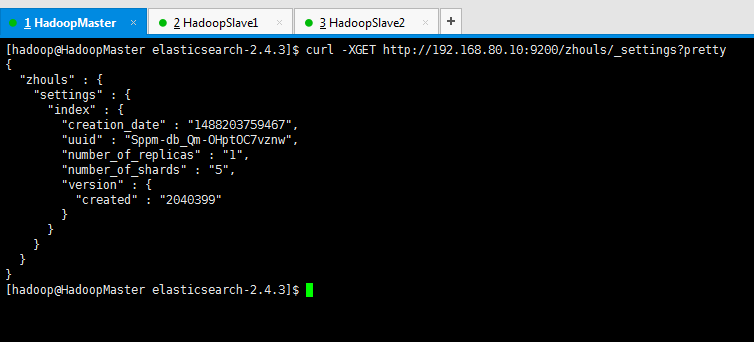
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XGET http://192.168.80.10:9200/zhouls/_settings?pretty
{
"zhouls" : {
"settings" : {
"index" : {
"creation_date" : "1488203759467",
"uuid" : "Sppm-db_Qm-OHptOC7vznw",
"number_of_replicas" : "1",
"number_of_shards" : "5",
"version" : {
"created" : "2040399"
}
}
}
}
}
[hadoop@HadoopMaster elasticsearch-2.4.3]$
settings修改索引库默认配置
例如:分片数量,副本数量
查看:curl -XGET http://192.168.80.10:9200/zhouls/_settings?pretty
操作不存在索引:curl -XPUT '192.168.80.10:9200/liuch/' -d'{"settings":{"number_of_shards":3,"number_of_replicas":0}}'
操作已存在索引:curl -XPUT '192.168.80.10:9200/zhouls/_settings' -d'{"index":{"number_of_replicas":1}}'
总结:就是,不存在索引时,可以指定副本和分片,如果已经存在,则只能修改副本。
在创建新的索引库时,可以指定索引分片的副本数。默认是1,这个很简单
2、ES中的mappings
ES的mapping如何用?什么时候需要手动,什么时候需要自动?
Mapping,就是对索引库中索引的字段名称及其数据类型进行定义,类似于mysql中的表结构信息。不过es的mapping比数据库灵活很多,它可以动态识别字段。一般不需要指定mapping都可以,因为es会自动根据数据格式识别它的类型,如果你需要对某些字段添加特殊属性(如:定义使用其它分词器、是否分词、是否存储等),就必须手动添加mapping。
我们在es中添加索引数据时不需要指定数据类型,es中有自动影射机制,字符串映射为string,数字映射为long。通过mappings可以指定数据类型是否存储等属性。
查询索引库的mapping信息
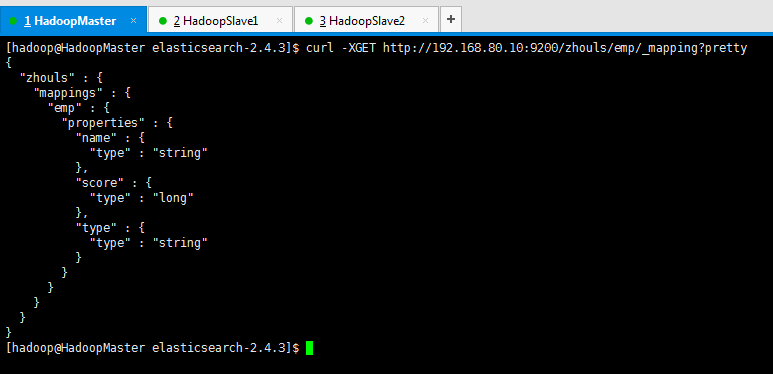
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XGET http://192.168.80.10:9200/zhouls/emp/_mapping?pretty
{
"zhouls" : {
"mappings" : {
"emp" : {
"properties" : {
"name" : {
"type" : "string"
},
"score" : {
"type" : "long"
},
"type" : {
"type" : "string"
}
}
}
}
}
}
[hadoop@HadoopMaster elasticsearch-2.4.3]$
mappings修改字段相关属性
例如:字段类型,使用哪种分词工具啊等,如下:
注意:下面可以使用indexAnalyzer定义分词器,也可以使用index_analyzer定义分词器
操作不存在的索引
curl -XPUT '192.168.80.10:9200/zhouls' -d'{"mappings":{"emp":{"properties":{"name":{"type":"string","analyzer": "ik_max_word"}}}}}'
操作已存在的索引
curl -XPOST http://192.168.80.10:9200/zhouls/emp/_mapping -d'{"properties":{"name":{"type":"string","analyzer": "ik_max_word"}}}'
这里,我就不多赘述了,自行去测试吧!只是做一个引子。
java操作settings和mappings
java操作settings

1 /** 2 *创建索引库,指定分片数量和副本数量 3 */ 4 @Test 5 public void test18() throws Exception { 6 HashMap<String, Object> settings = new HashMap<String, Object>(); 7 settings.put("number_of_shards", 5); 8 settings.put("number_of_replicas", 0); 9 CreateIndexRequestBuilder prepareCreate = transportClient.admin() 10 .indices() 11 .prepareCreate("liuch"); 12 prepareCreate.setSettings(settings).get(); 13 } 14 15 16 17 18 19 /** 20 * 更新索引库的副本数量 21 */ 22 @Test 23 public void test19() throws Exception { 24 25 HashMap<String, Object> settings = new HashMap<String, Object>(); 26 settings.put("number_of_replicas", 1); 27 UpdateSettingsRequestBuilder prepareUpdateSettings = transportClient.admin() 28 .indices() 29 .prepareUpdateSettings("liuch"); 30 prepareUpdateSettings.setSettings(settings).get(); 31 32 }
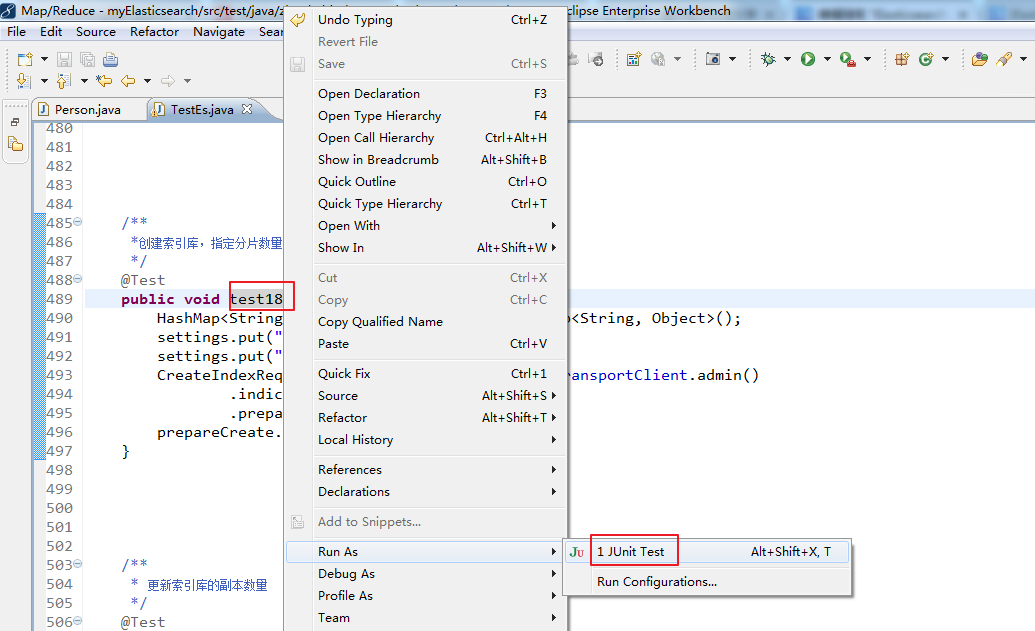




[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XGET http://192.168.80.10:9200/liuch/_settings?pretty
{
"liuch" : {
"settings" : {
"index" : {
"creation_date" : "1488210760317",
"uuid" : "Fi4Hw4wqTKqWAsczlb36Cw",
"number_of_replicas" : "0",
"number_of_shards" : "5",
"version" : {
"created" : "2040399"
}
}
}
}
}
[hadoop@HadoopMaster elasticsearch-2.4.3]$

java操作mappings
1 /** 2 * 创建索引库指定settings和mappings 3 */ 4 @Test 5 public void test20() throws Exception { 6 //settings 信息 7 HashMap<String, Object> settings = new HashMap<String, Object>(); 8 settings.put("number_of_replicas", 5); 9 settings.put("number_of_replicas", 0); 10 11 //mappings 信息 12 XContentBuilder mappings = XContentFactory.jsonBuilder() 13 .startObject() 14 .field("dynamic","strict") 15 .startObject("properties") 16 .startObject("name") 17 .field("type","string") 18 .field("analyzer","ik_max_word") 19 .endObject() 20 .endObject() 21 .endObject(); 22 CreateIndexRequestBuilder prepareCreate = transportClient.admin() 23 .indices() 24 .prepareCreate("love"); 25 prepareCreate.setSettings(settings).addMapping("emp",mappings).get(); 26 }

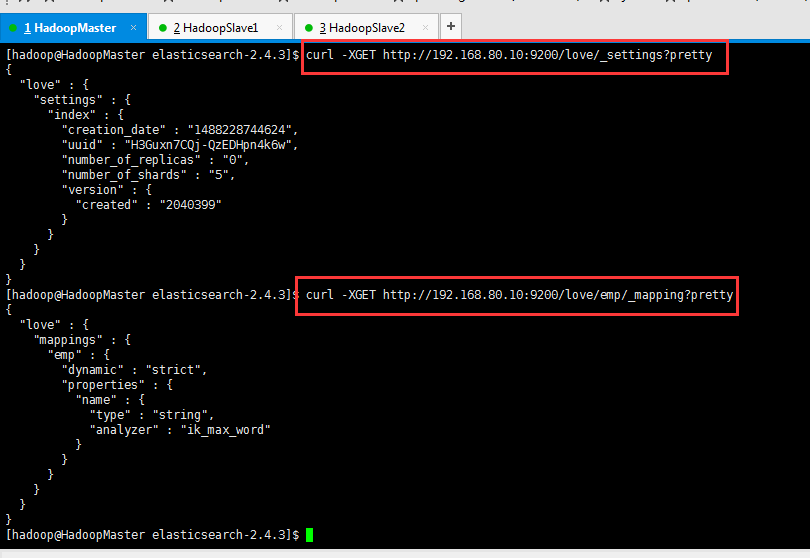
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XGET http://192.168.80.10:9200/love/_settings?pretty
{
"love" : {
"settings" : {
"index" : {
"creation_date" : "1488228744624",
"uuid" : "H3Guxn7CQj-QzEDHpn4k6w",
"number_of_replicas" : "0",
"number_of_shards" : "5",
"version" : {
"created" : "2040399"
}
}
}
}
}
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XGET http://192.168.80.10:9200/love/emp/_mapping?pretty
{
"love" : {
"mappings" : {
"emp" : {
"dynamic" : "strict",
"properties" : {
"name" : {
"type" : "string",
"analyzer" : "ik_max_word"
}
}
}
}
}
}
[hadoop@HadoopMaster elasticsearch-2.4.3]$


test21测试(分片查询)
默认是randomize across shards
索引库里有分片,分片有副本。
那么,我们查询,到底是去主分片里查呢,还是去副本查呢?注意:默认情况下,是随机的!
如,索引库有5个主分片,则到这里面去查。
索引库里有5个主分片,且分片里有副本。则会找些副本,然后到这些副本的节点去查。
随机选取,表示随机的从分片中取数据。
_local:指查询操作会优先在本地节点有的分片中查询,没有的话再在其它节点查询。
_only_local:指查询只会在本地节点有的分片中查询
_primary:指查询只在主分片中查询
_replica:指查询只在副本中查询
_primary_first:指查询会先在主分片中查询,如果主分片找不到(挂了),就会在副本中查询
_replica_first:指查询会先在副本中查询,如果副本找不到(挂了),就会在主分片中查询
_only_node:指在指定id的节点里面进行查询,如果该节点只有要查询索引的部分分片,就只在这部分分片中查找,所以查询结果可能不完整。如_only_node:123在节点id为123的节点中查询。
查看节点id:curl -XGET 'http://localhost:9200/_nodes?pretty'
_only_nodes:指定对个节点id,查询多个节点中的数据
_prefer_node : nodeid 优先在指定的节点上执行查询
_shards : 0,1,2,3,4:查询指定分片的数据
源码:org.elasticsearch.cluster.routing.OperationRouting类中的preferenceActiveShardIterator方法
如,setPreference("_shards:3") //则表示指定分片查询方式 可以指定只查询指定分片中的数据,提高查询效率
为了,更好的演示效果,我将现有的索引库删除,如下

[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XDELETE 'http://192.168.80.10:9200/zhouls'
{"acknowledged":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XDELETE 'http://192.168.80.10:9200/love'
{"acknowledged":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XDELETE 'http://192.168.80.10:9200/liuch'
{"acknowledged":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
/** * 分片查询方式 * @throws Exception */ @Test public void test4() throws Exception { SearchRequestBuilder builder = client.prepareSearch("zhouls") .setTypes("user") //.setPreference("_local") //.setPreference("_only_local") //.setPreference("_primary") //.setPreference("_replica") //.setPreference("_primary_first") //.setPreference("_replica_first") //.setPreference("_only_node:crKxtA2fRTG1UZdPN8QtaA") //.setPreference("_prefer_node:nJL_MqcsSle6gY7iujoAlw") .setPreference("_shards:3") ; SearchResponse searchResponse = builder.get(); SearchHits hits = searchResponse.getHits(); SearchHit[] hits2 = hits.getHits(); for (SearchHit searchHit : hits2) { System.out.println(searchHit.getSourceAsString()); } }
极速查询
/** * 极速查询:通过路由插入数据(同一类别数据在一个分片) * @throws Exception */ @Test public void test5() throws Exception { Acount acount = new Acount("13602546655","tom1","male",16); Acount acount2 = new Acount("13602546655","tom2","male",17); Acount acount3 = new Acount("13602546655","tom3","male",18); Acount acount4 = new Acount("18903762536","john1","male",28); Acount acount5 = new Acount("18903762536","john2","male",29); Acount acount6 = new Acount("18903762536","john3","male",30); List<Acount> list = new ArrayList<Acount>(); list.add(acount); list.add(acount2); list.add(acount3); list.add(acount4); list.add(acount5); list.add(acount6); BulkProcessor bulkProcessor = BulkProcessor.builder( client, new BulkProcessor.Listener() { public void beforeBulk(long executionId, BulkRequest request) { // TODO Auto-generated method stub System.out.println(request.numberOfActions()); } public void afterBulk(long executionId, BulkRequest request, Throwable failure) { // TODO Auto-generated method stub System.out.println(failure.getMessage()); } public void afterBulk(long executionId, BulkRequest request, BulkResponse response) { // TODO Auto-generated method stub System.out.println(response.hasFailures()); } }) .setBulkActions(1000) // 每个批次的最大数量 .setBulkSize(new ByteSizeValue(1, ByteSizeUnit.GB))// 每个批次的最大字节数 .setFlushInterval(TimeValue.timeValueSeconds(5))// 每批提交时间间隔 .setConcurrentRequests(1) //设置多少个并发处理线程 //可以允许用户自定义当一个或者多个bulk请求失败后,该执行如何操作 .setBackoffPolicy( BackoffPolicy.exponentialBackoff(TimeValue.timeValueMillis(100), 3)) .build(); for (Acount a : list) { ObjectMapper mapper = new ObjectMapper(); byte[] json = mapper.writeValueAsBytes(a); bulkProcessor.add(new IndexRequest("zhouls", "user") .routing(a.getPhone().substring(0, 3)) .source(json)); } //阻塞至所有的请求线程处理完毕后,断开连接资源 bulkProcessor.awaitClose(3, TimeUnit.MINUTES); client.close(); } /** * 极速查询:通过路由极速查询,也可以通过分片shards查询演示 * * @throws Exception */ @Test public void test6() throws Exception { SearchRequestBuilder builder = client.prepareSearch("zhouls")//可以指定多个索引库 .setTypes("user");//支持多个类型,但不支持通配符 builder.setQuery(QueryBuilders.matchAllQuery()) .setRouting("13602546655".substring(0, 3)) //.setRouting("18903762536".substring(0, 3)) ; SearchResponse searchResponse = builder.get(); SearchHits hits = searchResponse.getHits(); SearchHit[] hits2 = hits.getHits(); for (SearchHit searchHit : hits2) { System.out.println(searchHit.getSourceAsString()); } }
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步