

Elasticsearch之批量操作bulk
1、bulk相当于数据库里的bash操作。
2、引入批量操作bulk,提高工作效率,你想啊,一批一批添加与一条一条添加,谁快?
3、bulk API可以帮助我们同时执行多个请求
4、bulk的格式:
action:index/create/update/delete
metadata:_index,_type,_id
request body:_source (删除操作不需要加request body)
{ action: { metadata }}
{ request body }
5、bulk里为什么不支持get呢?
答:批量操作,里面放get操作,没啥用!所以,官方也不支持。
6、create 和index的区别
如果数据存在,使用create操作失败,会提示文档已经存在,使用index则可以成功执行。
7、bulk一次最大处理多少数据量?
bulk会把将要处理的数据载入内存中,所以数据量是有限制的,最佳的数据量不是一个确定的数值,它取决于你的硬件,你的文档大小以及复杂性,你的索引以及搜索的负载。
一般建议是1000-5000个文档,如果你的文档很大,可以适当减少队列,大小建议是5-15MB,默认不能超过100M,可以在es的配置文件(即$ES_HOME下的config下的elasticsearch.yml)中。
elasticsearch-.yml(中文配置详解)
来修改这个值http.max_content_length: 100mb【不建议修改,太大的话bulk也会慢】,
https://www.elastic.co/guide/en/elasticsearch/reference/2.4/modules-http.html
批量操作bulk例子
(1) 比如,我这里,在$ES_HOME里,新建一文件,命名为request。(这里为什么命名为request,去看官网就是)在Linux里,有无后缀没区别。
[hadoop@djt002 elasticsearch-2.4.3]$ pwd
/usr/local/elasticsearch/elasticsearch-2.4.3
[hadoop@djt002 elasticsearch-2.4.3]$ ll
total 56
drwxrwxr-x. 2 hadoop hadoop 4096 Feb 20 22:54 bin
drwxrwxr-x. 3 hadoop hadoop 4096 Feb 21 01:28 config
drwxrwxr-x. 3 hadoop hadoop 4096 Feb 20 22:59 data
drwxrwxr-x. 2 hadoop hadoop 4096 Feb 20 22:54 lib
-rw-rw-r--. 1 hadoop hadoop 11358 Aug 24 00:46 LICENSE.txt
drwxrwxr-x. 2 hadoop hadoop 4096 Feb 21 00:33 logs
drwxrwxr-x. 5 hadoop hadoop 4096 Dec 8 00:41 modules
-rw-rw-r--. 1 hadoop hadoop 150 Aug 24 00:46 NOTICE.txt
drwxrwxr-x. 2 hadoop hadoop 4096 Feb 20 22:59 plugins
-rw-rw-r--. 1 hadoop hadoop 8700 Aug 24 00:46 README.textile
[hadoop@djt002 elasticsearch-2.4.3]$ vim request
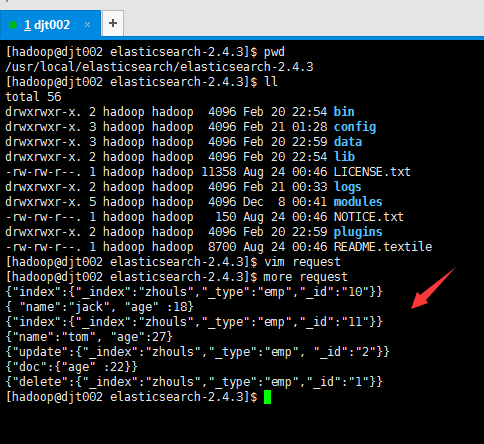
[hadoop@djt002 elasticsearch-2.4.3]$ more request
{"index":{"_index":"zhouls","_type":"emp","_id":"10"}}
{ "name":"jack", "age" :18}
{"index":{"_index":"zhouls","_type":"emp","_id":"11"}}
{"name":"tom", "age":27}
{"update":{"_index":"zhouls","_type":"emp", "_id":"2"}}
{"doc":{"age" :22}}
{"delete":{"_index":"zhouls","_type":"emp","_id":"1"}}
[hadoop@djt002 elasticsearch-2.4.3]$
或者
{ "index" : {"_index":"zhouls","_type":"emp","_id":"21"}}
{ "name" : "test21"}
例子:
{ "index" : { "_index" : "zhouls", "_type" : "type1", "_id" : "1" } }
{ "field1" : "value1" }
{ "index" : { "_index" : "zhouls", "_type" : "type1", "_id" : "2" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "zhouls", "_type" : "type1", "_id" : "2" } } (删除操作不需要加request body)
{ "create" : { "_index" : "zhouls", "_type" : "type1", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_index" : "zhouls", "_type" : "type1","_id" : "1" } }
{ "doc" : {"field2" : "value2"} }
(2)使用文件的方式
vi requests
写入批量操作语句。比如,下面
{"index":{"_index":"zhouls","_type":"emp","_id":"10"}}
{ "name":"jack", "age" :18}
{"index":{"_index":"zhouls","_type":"emp","_id":"11"}}
{"name":"tom", "age":27}
{"update":{"_index":"zhouls","_type":"emp", "_id":"2"}}
{"doc":{"age" :22}}
{"delete":{"_index":"zhouls","_type":"emp","_id":"1"}}
在$ES_HOME目录下,执行下面命令
curl -PUT '192.168.80.200:9200/_bulk' --data-binary @request;
或
curl -XPOST '192.168.80.200:9200/_bulk' --data-binary @request;

[hadoop@djt002 elasticsearch-2.4.3]$ curl -PUT '192.168.80.200:9200/_bulk' --data-binary @request;
{"took":123,"errors":true,"items":[{"index":{"_index":"zhouls","_type":"emp","_id":"10","_version":1,"_shards":{"total":2,"successful":1,"failed":0},"status":201}},{"index":{"_index":"zhouls","_type":"emp","_id":"11","_version":1,"_shards":{"total":2,"successful":1,"failed":0},"status":201}},{"update":{"_index":"zhouls","_type":"emp","_id":"2","status":404,"error":{"type":"document_missing_exception","reason":"[emp][2]: document missing","index":"zhouls","shard":"-1"}}},{"delete":{"_index":"zhouls","_type":"emp","_id":"1","_version":1,"_shards":{"total":2,"successful":1,"failed":0},"status":404,"found":false}}]}[hadoop@djt002 elasticsearch-2.4.3]$
之后,再查看下。
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/1?pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "1",
"found" : false
}
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/2?pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "2",
"found" : false
}
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/11?pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "11",
"_version" : 4,
"found" : true,
"_source" : {
"name" : "tom",
"age" : 27
}
}
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/10?pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "10",
"_version" : 4,
"found" : true,
"_source" : {
"name" : "jack",
"age" : 18
}
}
(3) bulk请求可以在URL中声明/_index 或者/_index/_type
这个,自行去测试!
官网
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

