
Spark RDD/Core 编程 API入门系列 之rdd实战(rdd基本操作实战及transformation和action流程图)(源码)(三)
本博文的主要内容是:
1、rdd基本操作实战
2、transformation和action流程图
3、典型的transformation和action
RDD有3种操作:
1、 Trandformation 对数据状态的转换,即所谓算子的转换
2、 Action 触发作业,即所谓得结果的
3、 Contoller 对性能、效率和容错方面的支持,如cache、persist、checkpoint
Contoller包括cache、persist、checkpoint。
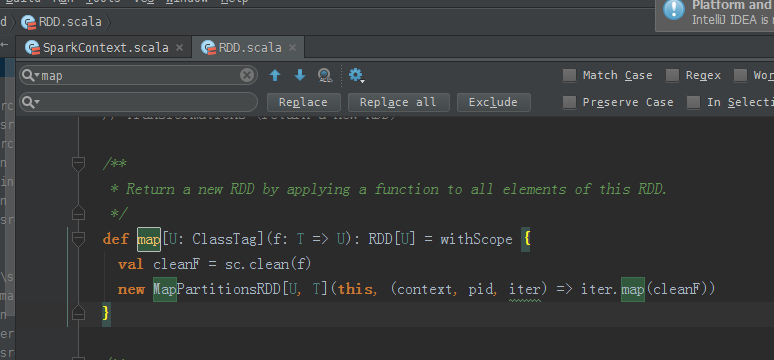
/**
* Return a new RDD by applying a function to all elements of this RDD.
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
传入类型是T,返回类型是U。

元素之间,为什么reduce操作,要符合结合律和交换律?
答:因为,交换律,不知,哪个数据先过来。所以,必须符合交换律。
在交换律基础上,想要reduce操作,必须要符合结合律。
/**
* Reduces the elements of this RDD using the specified commutative and
* associative binary operator.
*/
def reduce(f: (T, T) => T): T = withScope {
val cleanF = sc.clean(f)
val reducePartition: Iterator[T] => Option[T] = iter => {
if (iter.hasNext) {
Some(iter.reduceLeft(cleanF))
} else {
None
}
}
var jobResult: Option[T] = None
val mergeResult = (index: Int, taskResult: Option[T]) => {
if (taskResult.isDefined) {
jobResult = jobResult match {
case Some(value) => Some(f(value, taskResult.get))
case None => taskResult
}
}
}
sc.runJob(this, reducePartition, mergeResult)
// Get the final result out of our Option, or throw an exception if the RDD was empty
jobResult.getOrElse(throw new UnsupportedOperationException("empty collection"))
}
RDD.scala(源码)
这里,新建包com.zhouls.spark.cores


package com.zhouls.spark.cores
/**
* Created by Administrator on 2016/9/27.
*/
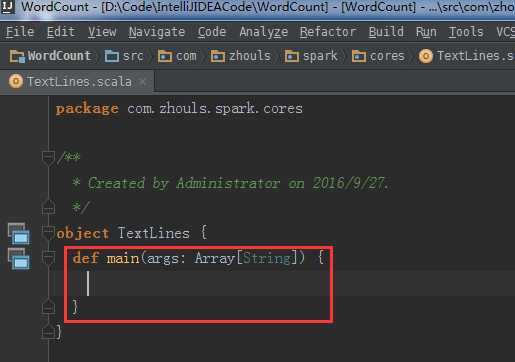
object TextLines {
}
下面,开始编代码
本地模式
自动 ,会写好
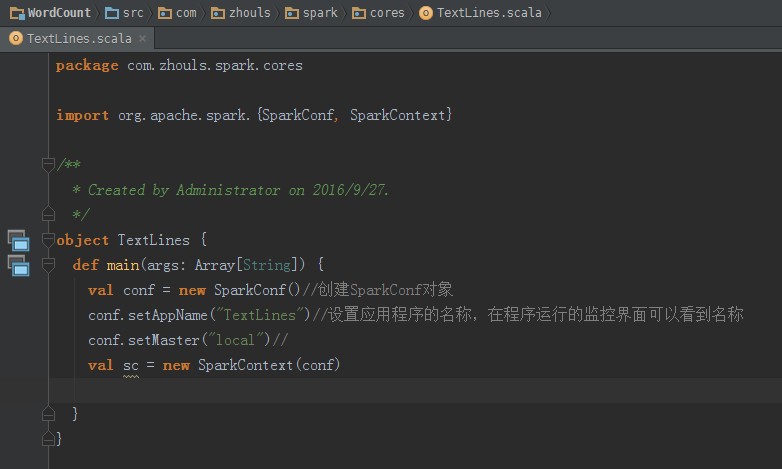
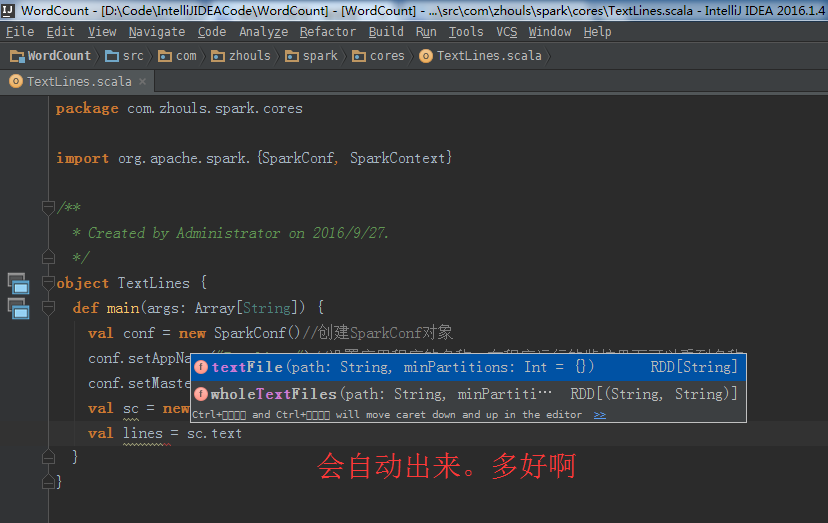

源码来看,



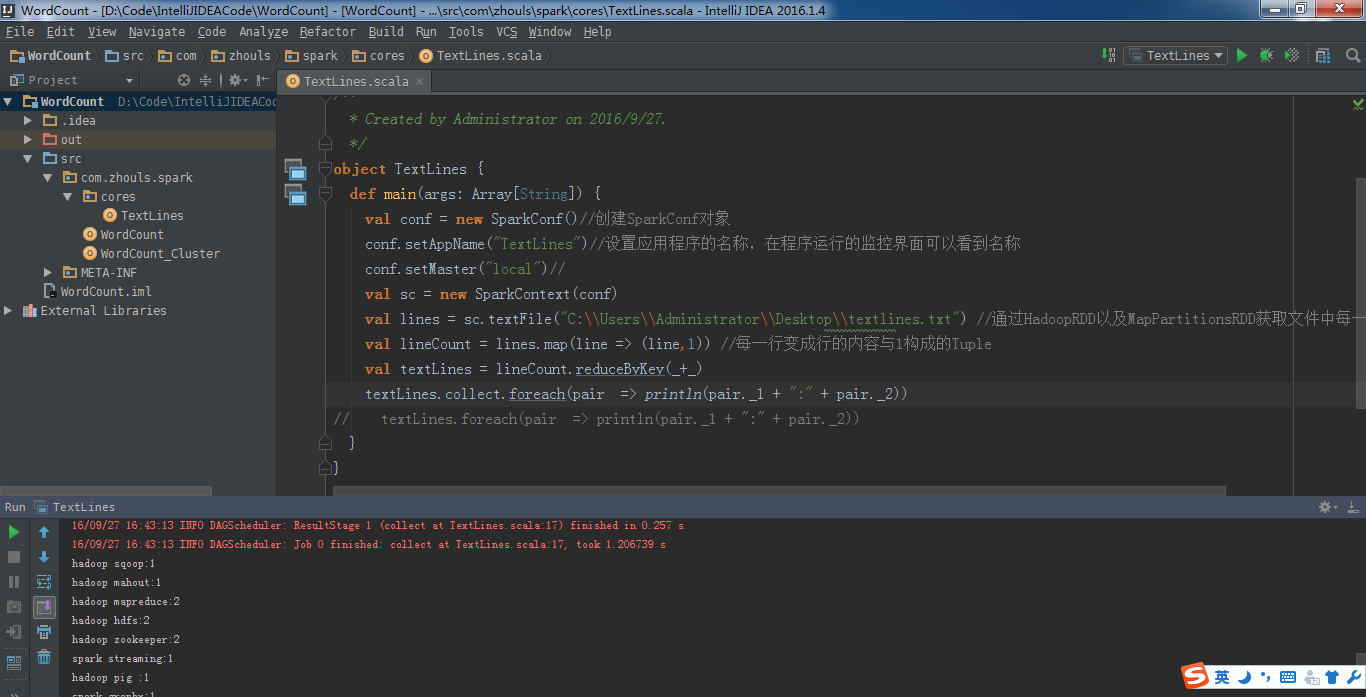
所以, val lines = sc.textFile("C:\\Users\\Administrator\\Desktop\\textlines.txt") //通过HadoopRDD以及MapPartitionsRDD获取文件中每一行的内容本身
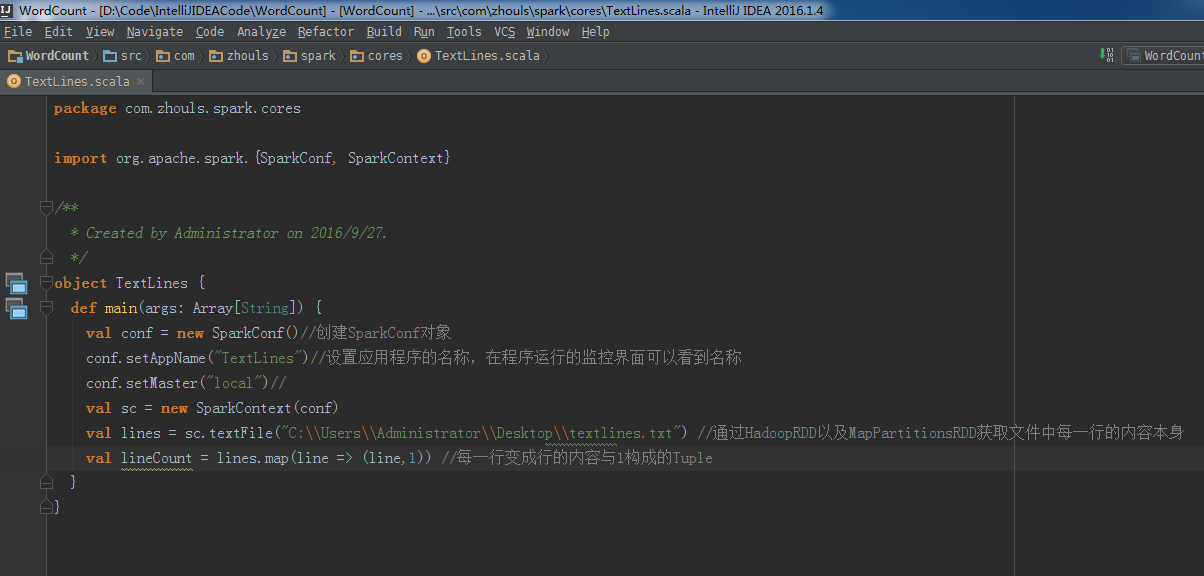
val lineCount = lines.map(line => (line,1)) //每一行变成行的内容与1构成的Tuple
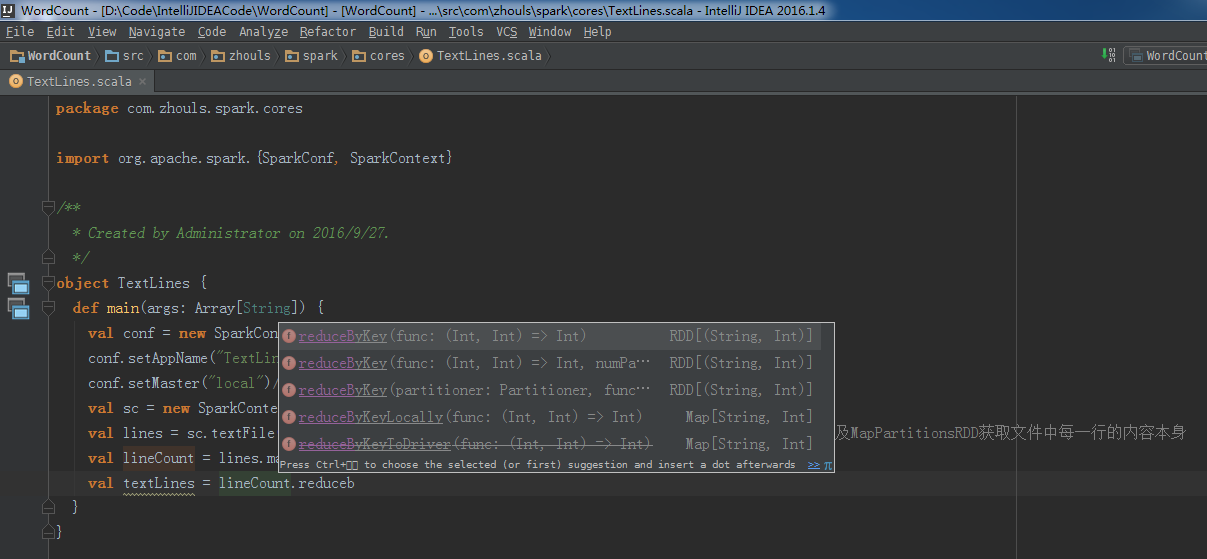

val textLines = lineCount.reduceByKey(_+_)
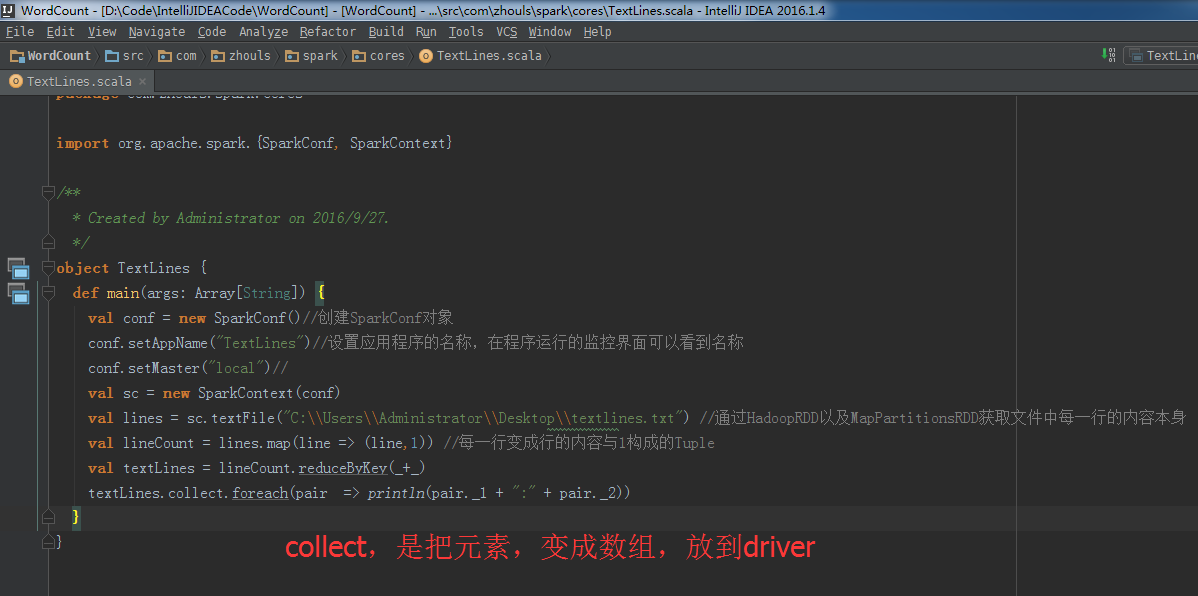
textLines.collect.foreach(pair => println(pair._1 + ":" + pair._2))

成功!
现在,将此行代码,
textLines.collect.foreach(pair => println(pair._1 + ":" + pair._2))
改一改
textLines.foreach(pair => println(pair._1 + ":" + pair._2))
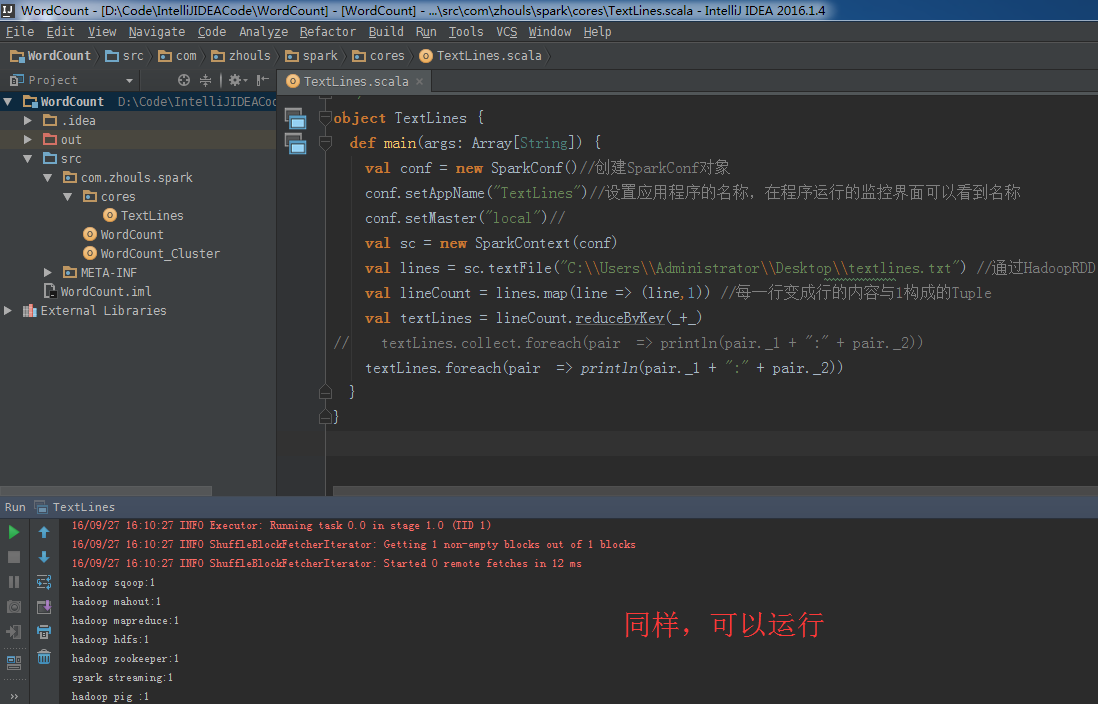
总结:
本地模式里,
textLines.collect.foreach(pair => println(pair._1 + ":" + pair._2))
改一改
textLines.foreach(pair => println(pair._1 + ":" + pair._2))
运行正常,因为在本地模式下,是jvm,但这样书写,是不正规的。
集群模式里,
textLines.collect.foreach(pair => println(pair._1 + ":" + pair._2))
改一改
textLines.foreach(pair => println(pair._1 + ":" + pair._2))
运行无法通过,因为结果是分布在各个节点上。
collect源码:
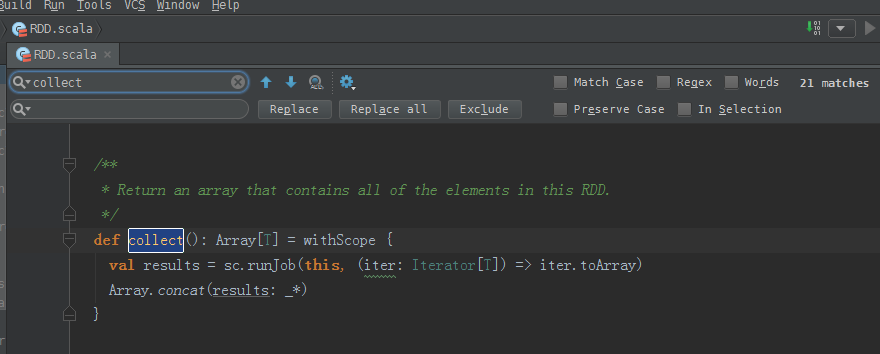
/**
* Return an array that contains all of the elements in this RDD.
*/
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
得出,collect后array中就是一个元素,只不过这个元素是一个Tuple。
Tuple是元组。通过concat合并!
foreach源码:
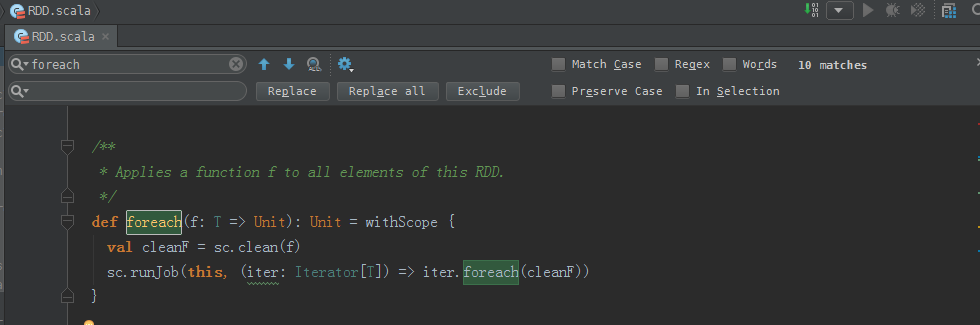
/**
* Applies a function f to all elements of this RDD.
*/
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}

rdd实战(rdd基本操作实战)至此!
rdd实战(transformation流程图)
拿wordcount为例!
启动hdfs集群
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ sbin/start-dfs.sh

启动spark集群
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ sbin/start-all.sh
启动spark-shell
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/bin$ ./spark-shell --master spark://SparkSingleNode:7077 --executor-memory 1g
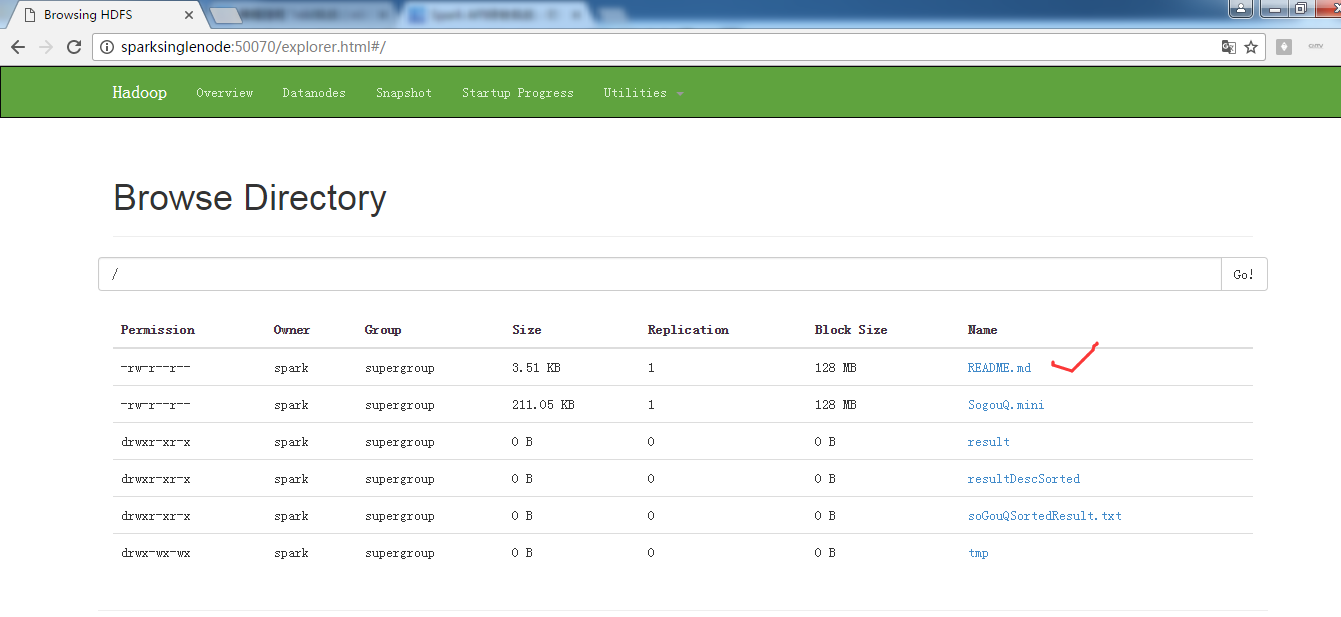
scala> val partitionsReadmeRdd = sc.textFile("hdfs://SparkSingleNode:9000/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).saveAsTextFile("~/partition1README.txt")
或者
scala> val readmeRdd = sc.textFile("hdfs://SparkSingleNode:9000/README.md")
scala> val partitionsReadmeRdd = readmeRdd.flatMap(_.split(" ")).map(word => (word,1)).reduceByKey(_+_,1)
.saveAsTextFile("~/partition1README.txt")


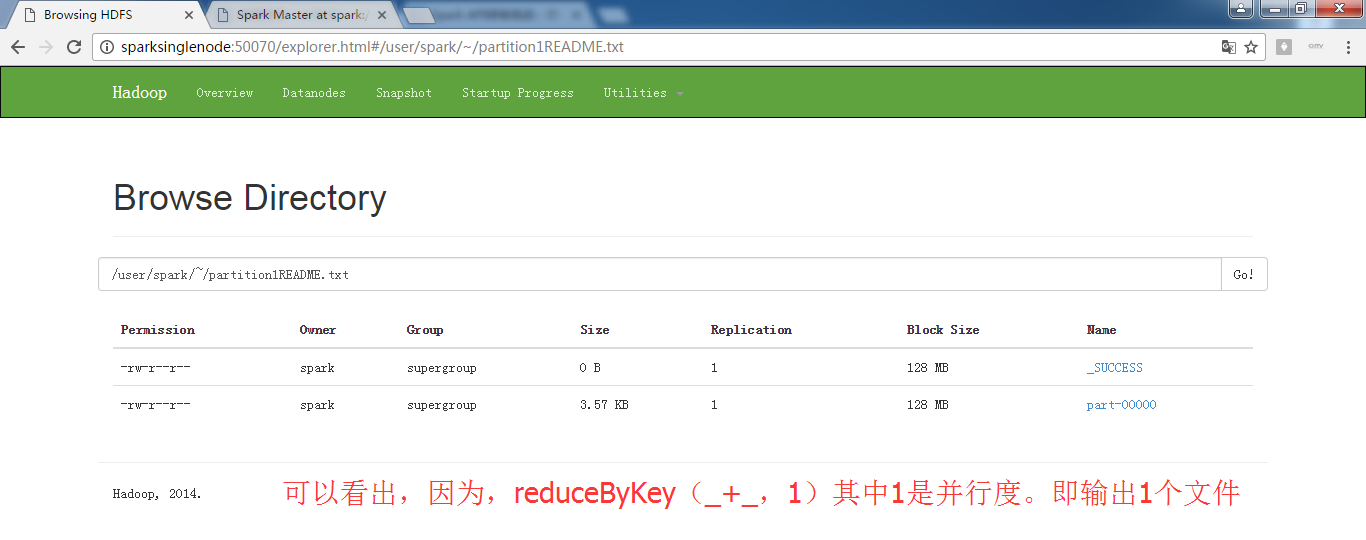

注意,~目录,不是这里。

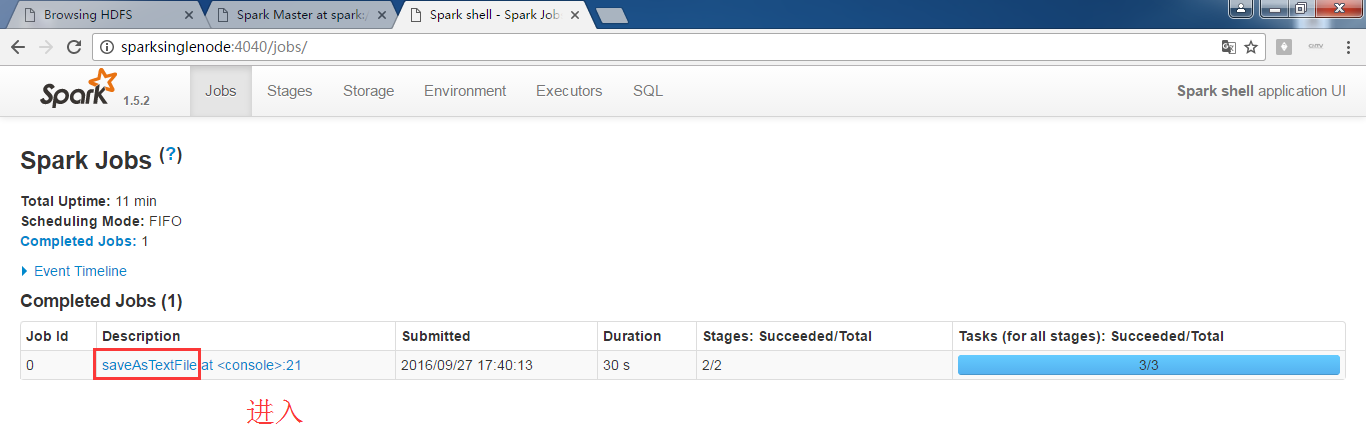

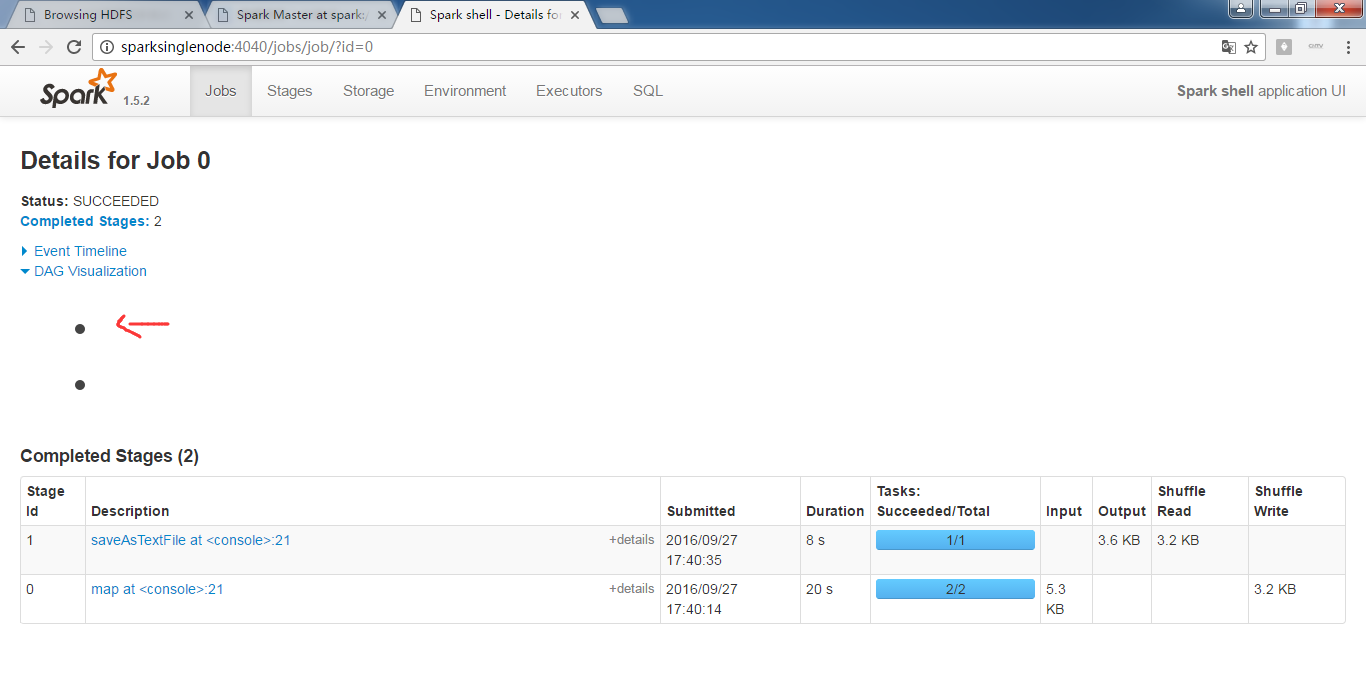
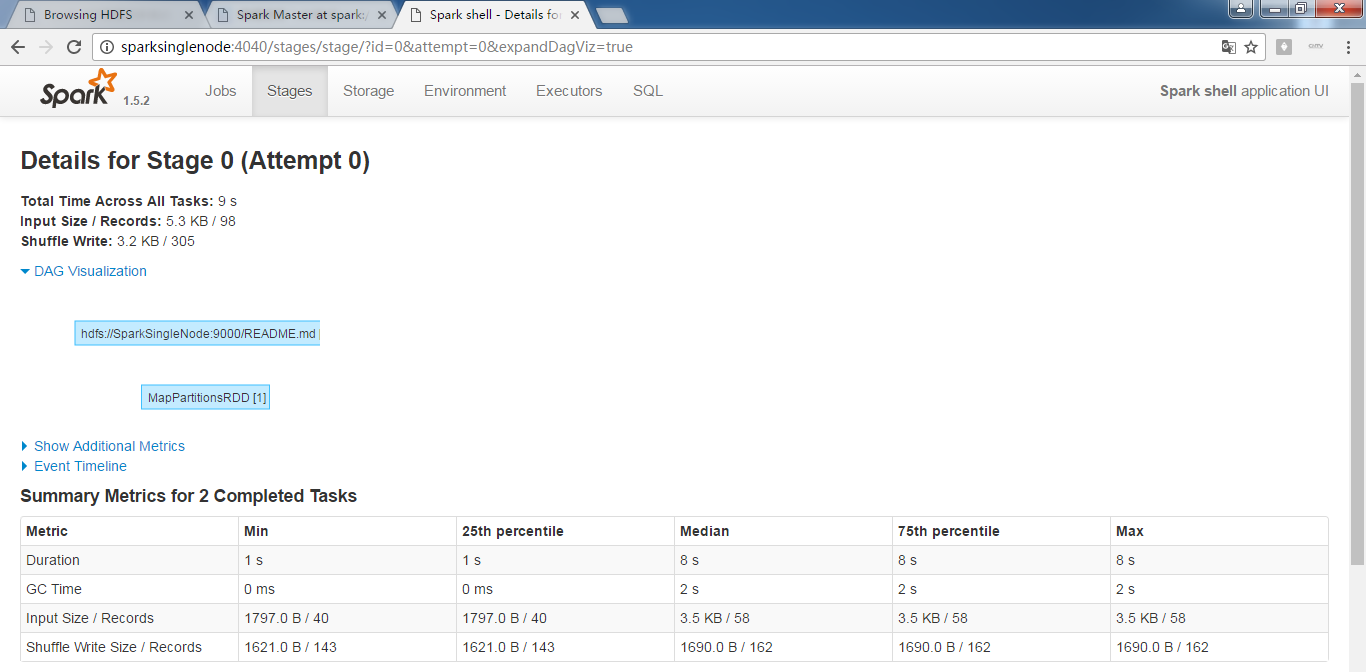
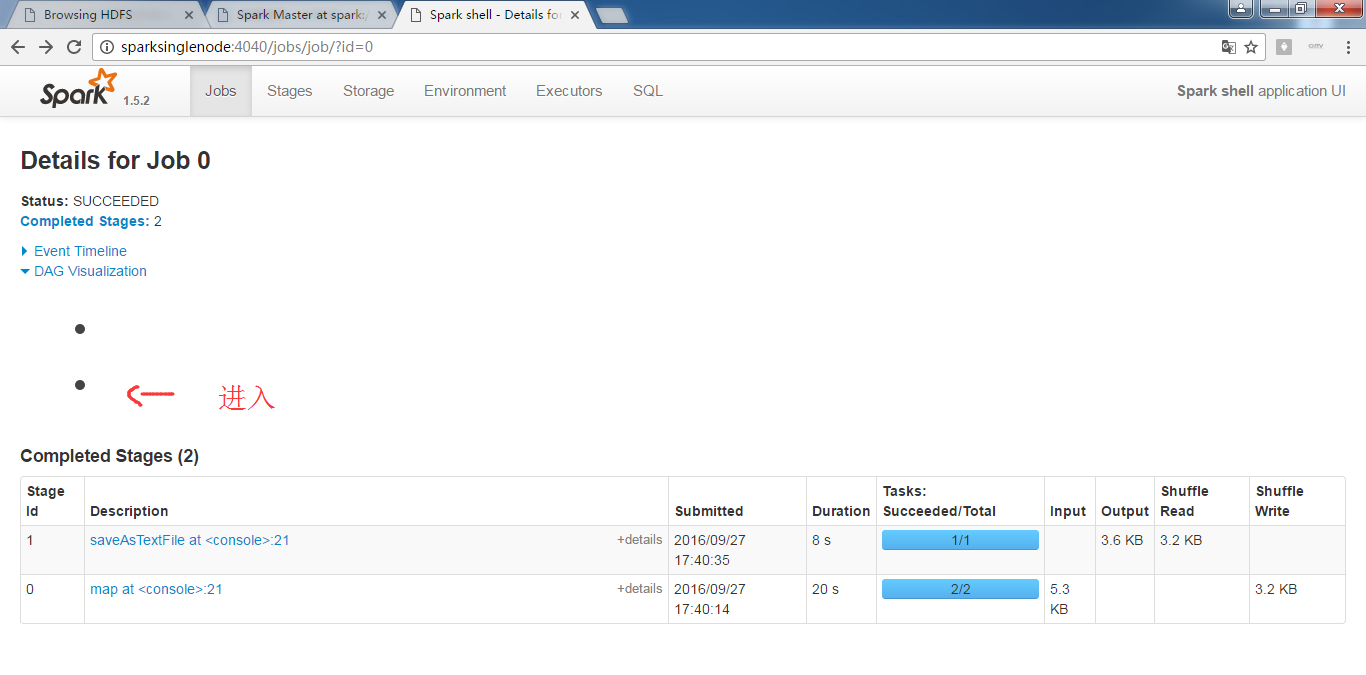

为什么,我的,不是这样的显示呢?
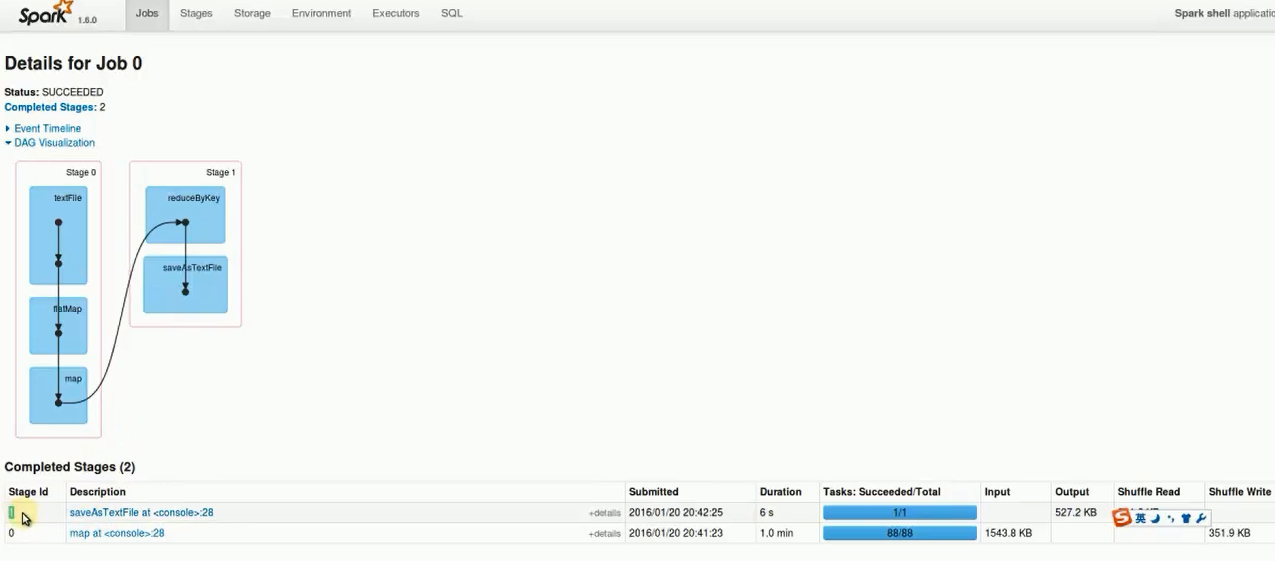
RDD的transformation和action执行的流程图
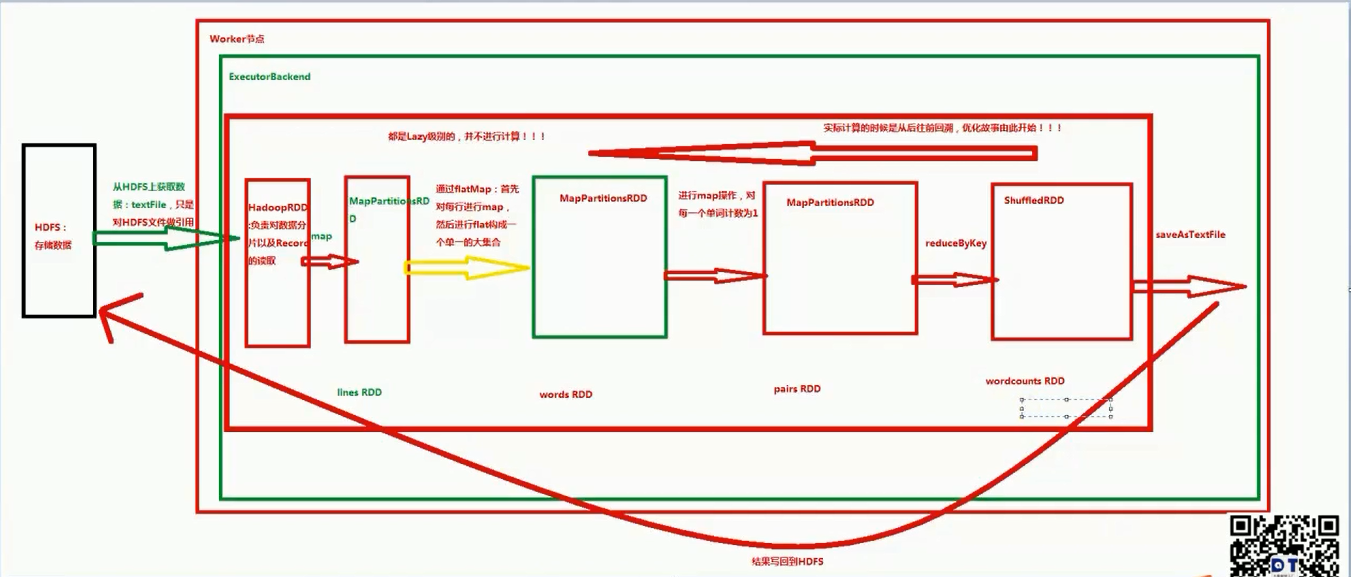
典型的transformation和action

作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号