
RDD.scala(源码)
---- map、
--- flatMap、fliter、distinct、repartition、coalesce、sample、randomSplit、randomSampleWithRange、takeSample、union、++、sortBy、intersection
map源码
/**
* Return a new RDD by applying a function to all elements of this RDD.
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
flatMap源码
/**
* Return a new RDD by first applying a function to all elements of this
* RDD, and then flattening the results.
*/
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))
}
fliter源码
/**
* Return a new RDD containing only the elements that satisfy a predicate.
*/
def filter(f: T => Boolean): RDD[T] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[T, T](
this,
(context, pid, iter) => iter.filter(cleanF),
preservesPartitioning = true)
}
distinct源码
/**
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
}
/**
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(): RDD[T] = withScope {
distinct(partitions.length)
}
repartition源码

/**
* Return a new RDD that has exactly numPartitions partitions.
*
* Can increase or decrease the level of parallelism in this RDD. Internally, this uses
* a shuffle to redistribute data.
*
* If you are decreasing the number of partitions in this RDD, consider using `coalesce`,
* which can avoid performing a shuffle.
*/
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
coalesce源码
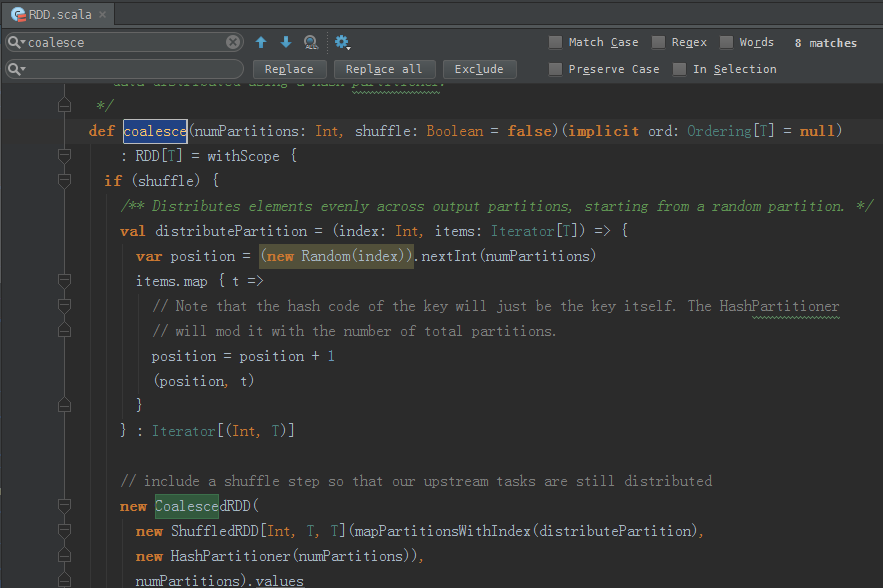
/**
* Return a new RDD that is reduced into `numPartitions` partitions.
*
* This results in a narrow dependency, e.g. if you go from 1000 partitions
* to 100 partitions, there will not be a shuffle, instead each of the 100
* new partitions will claim 10 of the current partitions.
*
* However, if you're doing a drastic coalesce, e.g. to numPartitions = 1,
* this may result in your computation taking place on fewer nodes than
* you like (e.g. one node in the case of numPartitions = 1). To avoid this,
* you can pass shuffle = true. This will add a shuffle step, but means the
* current upstream partitions will be executed in parallel (per whatever
* the current partitioning is).
*
* Note: With shuffle = true, you can actually coalesce to a larger number
* of partitions. This is useful if you have a small number of partitions,
* say 100, potentially with a few partitions being abnormally large. Calling
* coalesce(1000, shuffle = true) will result in 1000 partitions with the
* data distributed using a hash partitioner.
*/
def coalesce(numPartitions: Int, shuffle: Boolean = false)(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {
if (shuffle) {
/** Distributes elements evenly across output partitions, starting from a random partition. */
val distributePartition = (index: Int, items: Iterator[T]) => {
var position = (new Random(index)).nextInt(numPartitions)
items.map { t =>
// Note that the hash code of the key will just be the key itself. The HashPartitioner
// will mod it with the number of total partitions.
position = position + 1
(position, t)
}
} : Iterator[(Int, T)]
// include a shuffle step so that our upstream tasks are still distributed
new CoalescedRDD(
new ShuffledRDD[Int, T, T](mapPartitionsWithIndex(distributePartition),
new HashPartitioner(numPartitions)),
numPartitions).values
} else {
new CoalescedRDD(this, numPartitions)
}
}
sample源码
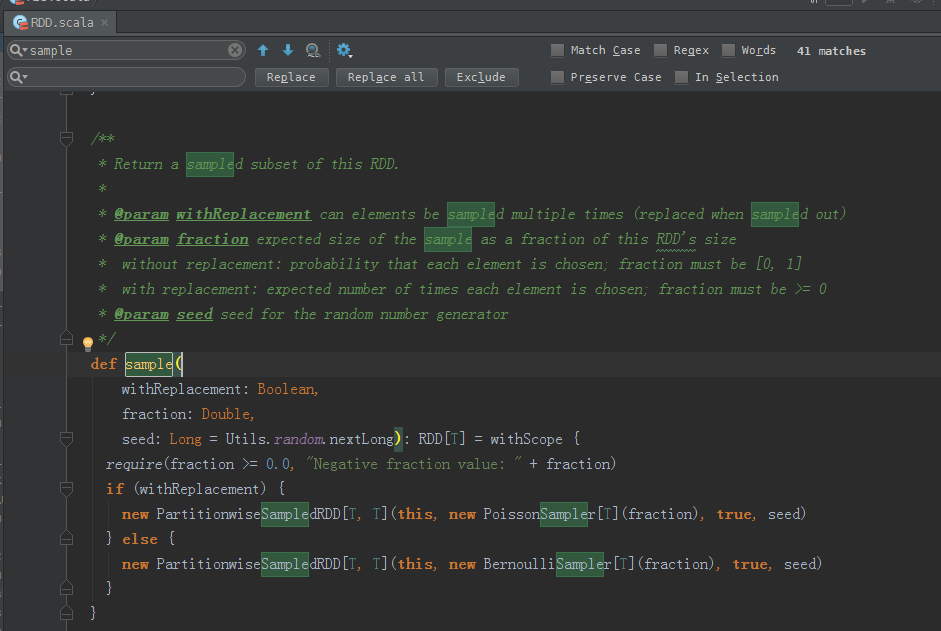
/**
* Return a sampled subset of this RDD.
*
* @param withReplacement can elements be sampled multiple times (replaced when sampled out)
* @param fraction expected size of the sample as a fraction of this RDD's size
* without replacement: probability that each element is chosen; fraction must be [0, 1]
* with replacement: expected number of times each element is chosen; fraction must be >= 0
* @param seed seed for the random number generator
*/
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T] = withScope {
require(fraction >= 0.0, "Negative fraction value: " + fraction)
if (withReplacement) {
new PartitionwiseSampledRDD[T, T](this, new PoissonSampler[T](fraction), true, seed)
} else {
new PartitionwiseSampledRDD[T, T](this, new BernoulliSampler[T](fraction), true, seed)
}
}
randomSplit源码
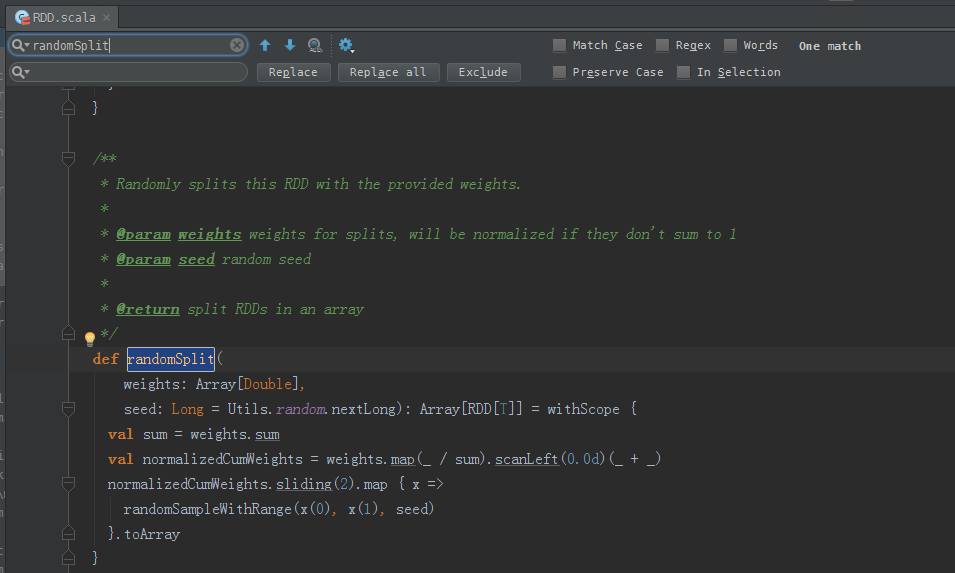
/**
* Randomly splits this RDD with the provided weights.
*
* @param weights weights for splits, will be normalized if they don't sum to 1
* @param seed random seed
*
* @return split RDDs in an array
*/
def randomSplit(
weights: Array[Double],
seed: Long = Utils.random.nextLong): Array[RDD[T]] = withScope {
val sum = weights.sum
val normalizedCumWeights = weights.map(_ / sum).scanLeft(0.0d)(_ + _)
normalizedCumWeights.sliding(2).map { x =>
randomSampleWithRange(x(0), x(1), seed)
}.toArray
}
randomSampleWithRange源码
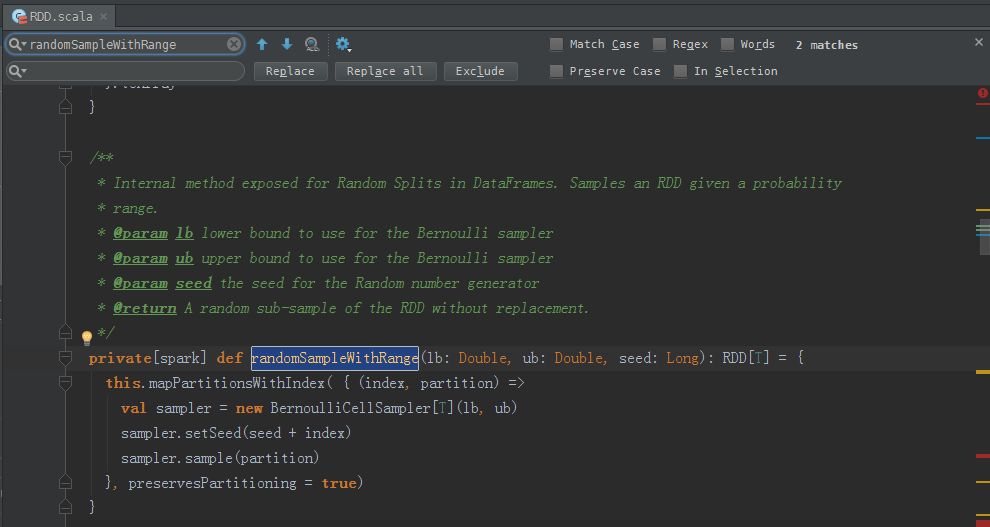
/**
* Internal method exposed for Random Splits in DataFrames. Samples an RDD given a probability
* range.
* @param lb lower bound to use for the Bernoulli sampler
* @param ub upper bound to use for the Bernoulli sampler
* @param seed the seed for the Random number generator
* @return A random sub-sample of the RDD without replacement.
*/
private[spark] def randomSampleWithRange(lb: Double, ub: Double, seed: Long): RDD[T] = {
this.mapPartitionsWithIndex( { (index, partition) =>
val sampler = new BernoulliCellSampler[T](lb, ub)
sampler.setSeed(seed + index)
sampler.sample(partition)
}, preservesPartitioning = true)
}
union源码
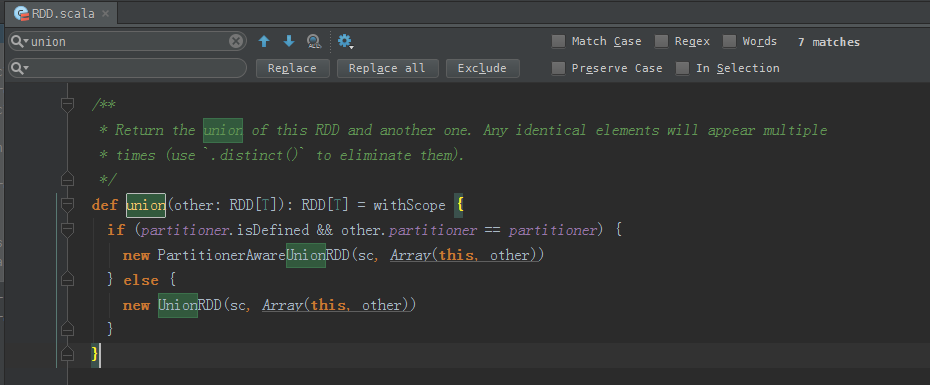
/**
* Return the union of this RDD and another one. Any identical elements will appear multiple
* times (use `.distinct()` to eliminate them).
*/
def union(other: RDD[T]): RDD[T] = withScope {
if (partitioner.isDefined && other.partitioner == partitioner) {
new PartitionerAwareUnionRDD(sc, Array(this, other))
} else {
new UnionRDD(sc, Array(this, other))
}
}
++源码
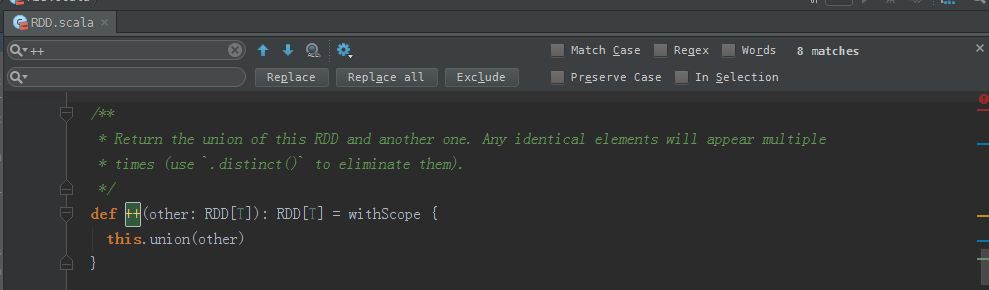
/**
* Return the union of this RDD and another one. Any identical elements will appear multiple
* times (use `.distinct()` to eliminate them).
*/
def ++(other: RDD[T]): RDD[T] = withScope {
this.union(other)
}
sortBy源码

/**
* Return this RDD sorted by the given key function.
*/
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope {
this.keyBy[K](f)
.sortByKey(ascending, numPartitions)
.values
}
intersection源码
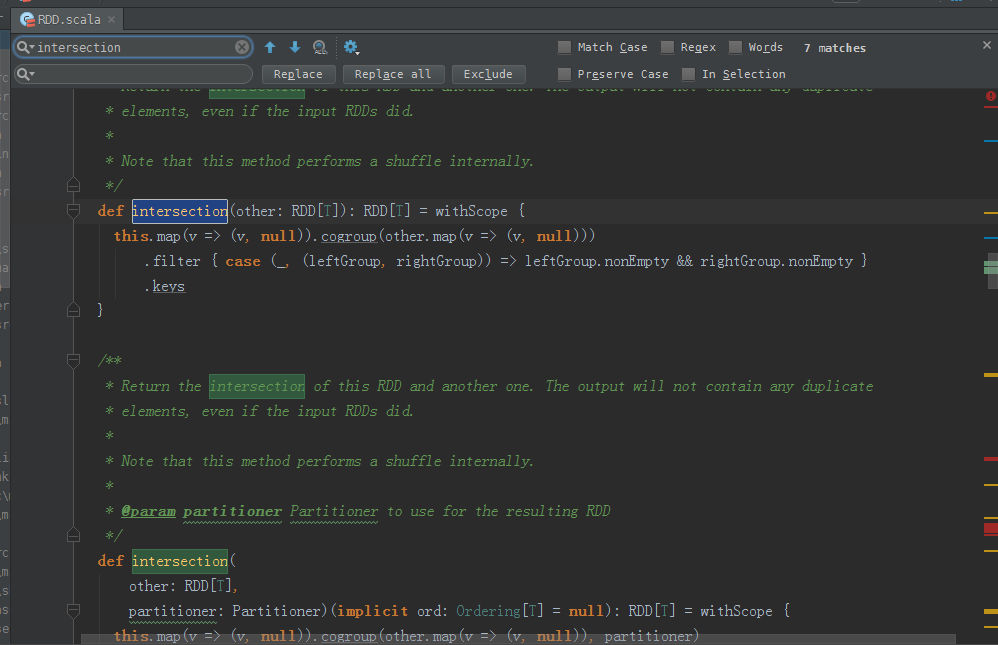
/**
* Return the intersection of this RDD and another one. The output will not contain any duplicate
* elements, even if the input RDDs did.
*
* Note that this method performs a shuffle internally.
*/
def intersection(other: RDD[T]): RDD[T] = withScope {
this.map(v => (v, null)).cogroup(other.map(v => (v, null)))
.filter { case (_, (leftGroup, rightGroup)) => leftGroup.nonEmpty && rightGroup.nonEmpty }
.keys
}
/**
* Return the intersection of this RDD and another one. The output will not contain any duplicate
* elements, even if the input RDDs did.
*
* Note that this method performs a shuffle internally.
*
* @param partitioner Partitioner to use for the resulting RDD
*/
def intersection(
other: RDD[T],
partitioner: Partitioner)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
this.map(v => (v, null)).cogroup(other.map(v => (v, null)), partitioner)
.filter { case (_, (leftGroup, rightGroup)) => leftGroup.nonEmpty && rightGroup.nonEmpty }
.keys
}
/**
* Return the intersection of this RDD and another one. The output will not contain any duplicate
* elements, even if the input RDDs did. Performs a hash partition across the cluster
*
* Note that this method performs a shuffle internally.
*
* @param numPartitions How many partitions to use in the resulting RDD
*/
def intersection(other: RDD[T], numPartitions: Int): RDD[T] = withScope {
intersection(other, new HashPartitioner(numPartitions))
}
glom源码
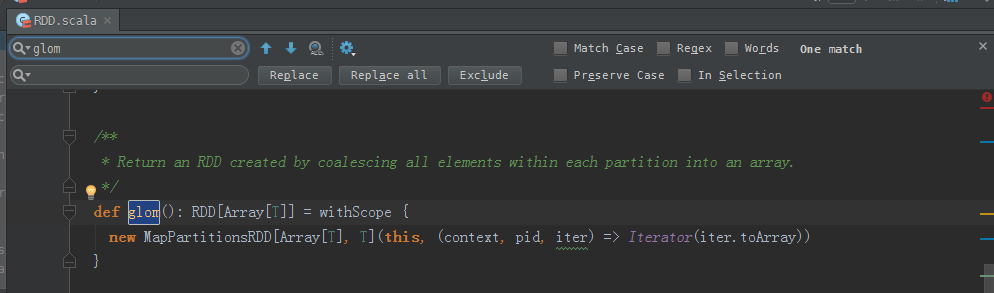
/**
* Return an RDD created by coalescing all elements within each partition into an array.
*/
def glom(): RDD[Array[T]] = withScope {
new MapPartitionsRDD[Array[T], T](this, (context, pid, iter) => Iterator(iter.toArray))
}
cartesian源码
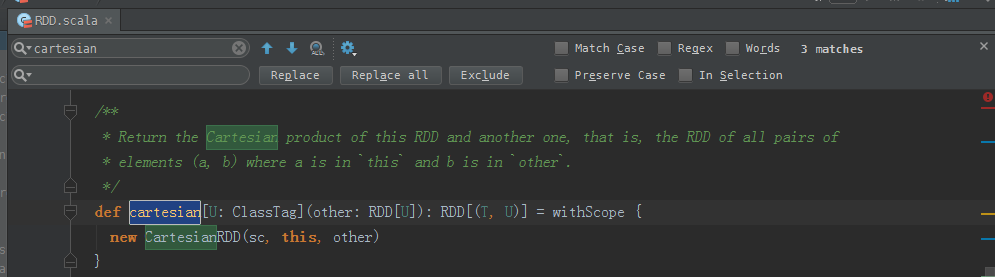
/**
* Return the Cartesian product of this RDD and another one, that is, the RDD of all pairs of
* elements (a, b) where a is in `this` and b is in `other`.
*/
def cartesian[U: ClassTag](other: RDD[U]): RDD[(T, U)] = withScope {
new CartesianRDD(sc, this, other)
}
groupBy源码
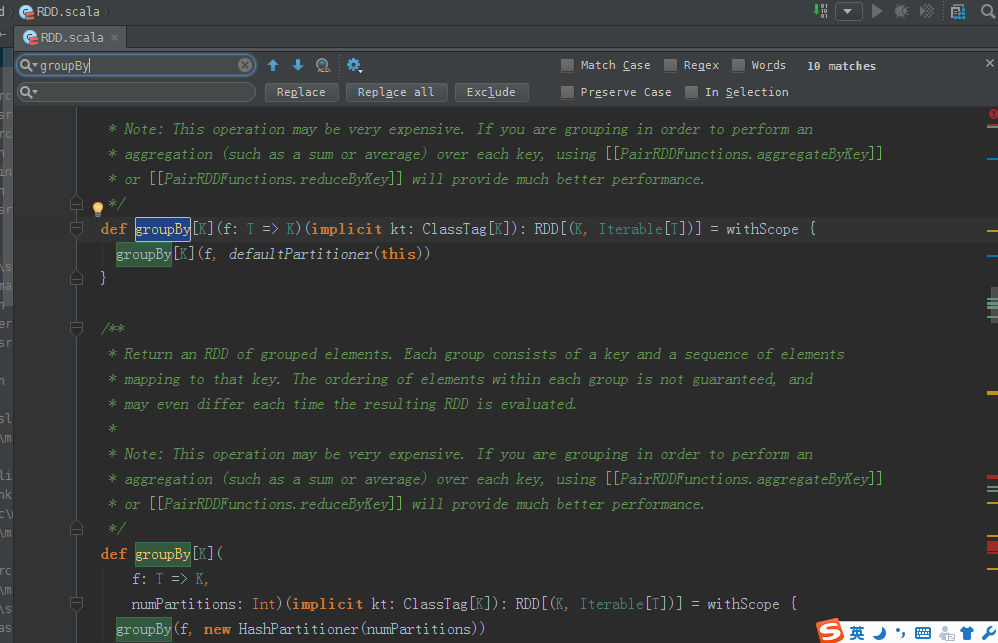
/**
* Return an RDD of grouped items. Each group consists of a key and a sequence of elements
* mapping to that key. The ordering of elements within each group is not guaranteed, and
* may even differ each time the resulting RDD is evaluated.
*
* Note: This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using [[PairRDDFunctions.aggregateByKey]]
* or [[PairRDDFunctions.reduceByKey]] will provide much better performance.
*/
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] = withScope {
groupBy[K](f, defaultPartitioner(this))
}
/**
* Return an RDD of grouped elements. Each group consists of a key and a sequence of elements
* mapping to that key. The ordering of elements within each group is not guaranteed, and
* may even differ each time the resulting RDD is evaluated.
*
* Note: This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using [[PairRDDFunctions.aggregateByKey]]
* or [[PairRDDFunctions.reduceByKey]] will provide much better performance.
*/
def groupBy[K](
f: T => K,
numPartitions: Int)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] = withScope {
groupBy(f, new HashPartitioner(numPartitions))
}
/**
* Return an RDD of grouped items. Each group consists of a key and a sequence of elements
* mapping to that key. The ordering of elements within each group is not guaranteed, and
* may even differ each time the resulting RDD is evaluated.
*
* Note: This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using [[PairRDDFunctions.aggregateByKey]]
* or [[PairRDDFunctions.reduceByKey]] will provide much better performance.
*/
def groupBy[K](f: T => K, p: Partitioner)(implicit kt: ClassTag[K], ord: Ordering[K] = null)
: RDD[(K, Iterable[T])] = withScope {
val cleanF = sc.clean(f)
this.map(t => (cleanF(t), t)).groupByKey(p)
}
pipe源码
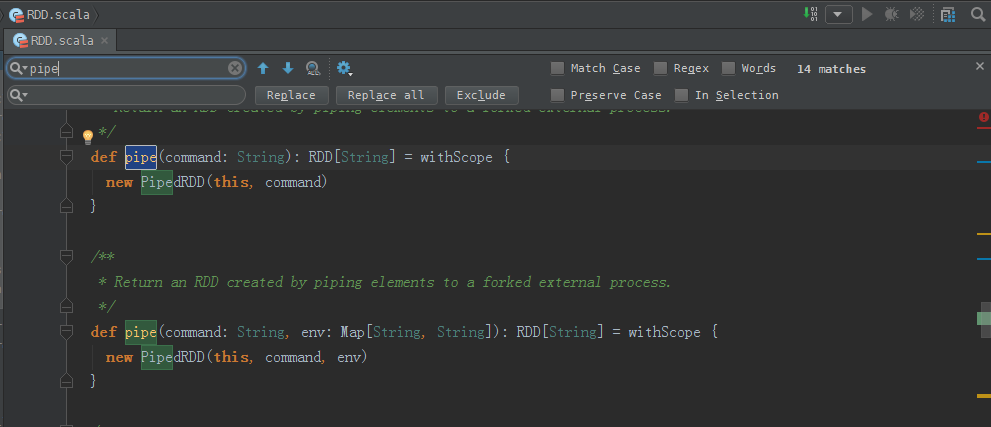
/**
* Return an RDD created by piping elements to a forked external process.
*/
def pipe(command: String): RDD[String] = withScope {
new PipedRDD(this, command)
}
/**
* Return an RDD created by piping elements to a forked external process.
*/
def pipe(command: String, env: Map[String, String]): RDD[String] = withScope {
new PipedRDD(this, command, env)
}
/**
* Return an RDD created by piping elements to a forked external process.
* The print behavior can be customized by providing two functions.
*
* @param command command to run in forked process.
* @param env environment variables to set.
* @param printPipeContext Before piping elements, this function is called as an opportunity
* to pipe context data. Print line function (like out.println) will be
* passed as printPipeContext's parameter.
* @param printRDDElement Use this function to customize how to pipe elements. This function
* will be called with each RDD element as the 1st parameter, and the
* print line function (like out.println()) as the 2nd parameter.
* An example of pipe the RDD data of groupBy() in a streaming way,
* instead of constructing a huge String to concat all the elements:
* def printRDDElement(record:(String, Seq[String]), f:String=>Unit) =
* for (e <- record._2){f(e)}
* @param separateWorkingDir Use separate working directories for each task.
* @return the result RDD
*/
def pipe(
command: Seq[String],
env: Map[String, String] = Map(),
printPipeContext: (String => Unit) => Unit = null,
printRDDElement: (T, String => Unit) => Unit = null,
separateWorkingDir: Boolean = false): RDD[String] = withScope {
new PipedRDD(this, command, env,
if (printPipeContext ne null) sc.clean(printPipeContext) else null,
if (printRDDElement ne null) sc.clean(printRDDElement) else null,
separateWorkingDir)
}
mapPartitions源码
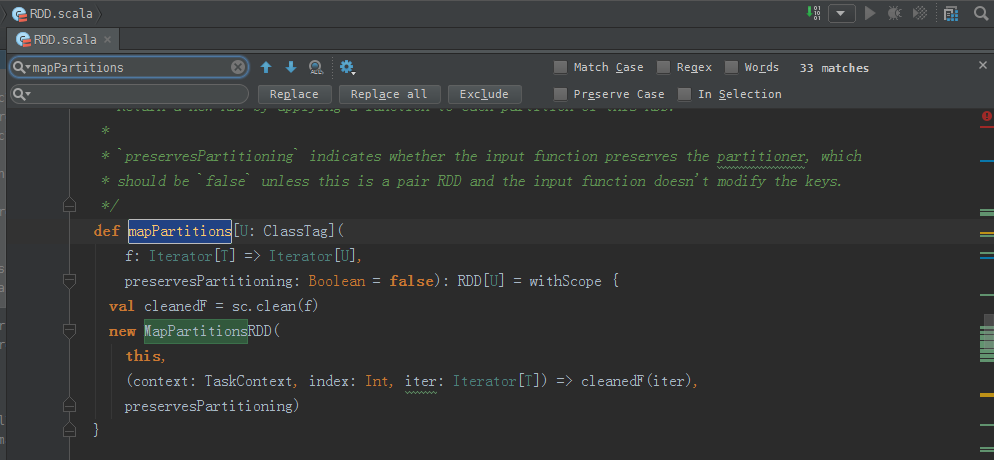
/**
* Return a new RDD by applying a function to each partition of this RDD.
*
* `preservesPartitioning` indicates whether the input function preserves the partitioner, which
* should be `false` unless this is a pair RDD and the input function doesn't modify the keys.
*/
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(iter),
preservesPartitioning)
}
mapPartitionsWithIndex源码
/**
* Return a new RDD by applying a function to each partition of this RDD, while tracking the index
* of the original partition.
*
* `preservesPartitioning` indicates whether the input function preserves the partitioner, which
* should be `false` unless this is a pair RDD and the input function doesn't modify the keys.
*/
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(index, iter),
preservesPartitioning)
}
mapPartitionsWithContext源码
/**
* :: DeveloperApi ::
* Return a new RDD by applying a function to each partition of this RDD. This is a variant of
* mapPartitions that also passes the TaskContext into the closure.
*
* `preservesPartitioning` indicates whether the input function preserves the partitioner, which
* should be `false` unless this is a pair RDD and the input function doesn't modify the keys.
*/
@DeveloperApi
@deprecated("use TaskContext.get", "1.2.0")
def mapPartitionsWithContext[U: ClassTag](
f: (TaskContext, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanF = sc.clean(f)
val func = (context: TaskContext, index: Int, iter: Iterator[T]) => cleanF(context, iter)
new MapPartitionsRDD(this, sc.clean(func), preservesPartitioning)
}
mapPartitionsWithSplit源码
/**
* Return a new RDD by applying a function to each partition of this RDD, while tracking the index
* of the original partition.
*/
@deprecated("use mapPartitionsWithIndex", "0.7.0")
def mapPartitionsWithSplit[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
mapPartitionsWithIndex(f, preservesPartitioning)
}
mapWith源码
/**
* Maps f over this RDD, where f takes an additional parameter of type A. This
* additional parameter is produced by constructA, which is called in each
* partition with the index of that partition.
*/
@deprecated("use mapPartitionsWithIndex", "1.0.0")
def mapWith[A, U: ClassTag]
(constructA: Int => A, preservesPartitioning: Boolean = false)
(f: (T, A) => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
val cleanA = sc.clean(constructA)
mapPartitionsWithIndex((index, iter) => {
val a = cleanA(index)
iter.map(t => cleanF(t, a))
}, preservesPartitioning)
}
flatMapWith源码
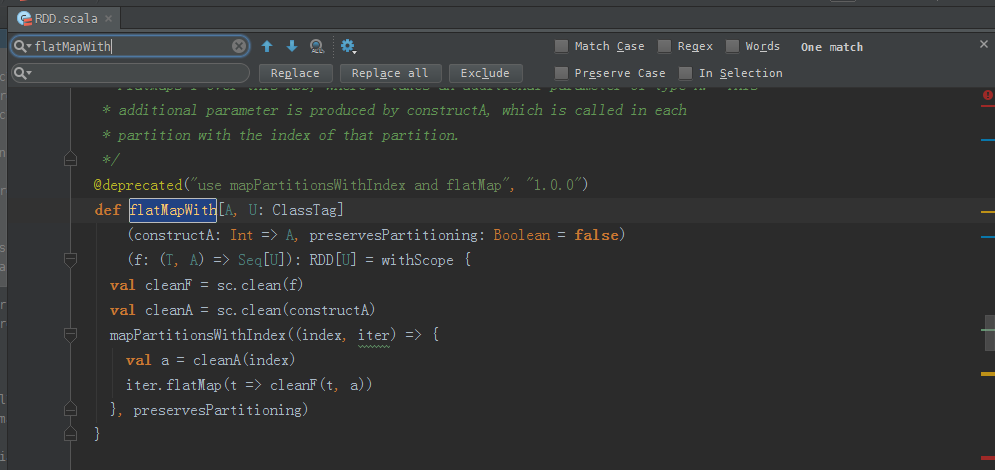
/**
* FlatMaps f over this RDD, where f takes an additional parameter of type A. This
* additional parameter is produced by constructA, which is called in each
* partition with the index of that partition.
*/
@deprecated("use mapPartitionsWithIndex and flatMap", "1.0.0")
def flatMapWith[A, U: ClassTag]
(constructA: Int => A, preservesPartitioning: Boolean = false)
(f: (T, A) => Seq[U]): RDD[U] = withScope {
val cleanF = sc.clean(f)
val cleanA = sc.clean(constructA)
mapPartitionsWithIndex((index, iter) => {
val a = cleanA(index)
iter.flatMap(t => cleanF(t, a))
}, preservesPartitioning)
}
foreachWith源码

/**
* Applies f to each element of this RDD, where f takes an additional parameter of type A.
* This additional parameter is produced by constructA, which is called in each
* partition with the index of that partition.
*/
@deprecated("use mapPartitionsWithIndex and foreach", "1.0.0")
def foreachWith[A](constructA: Int => A)(f: (T, A) => Unit): Unit = withScope {
val cleanF = sc.clean(f)
val cleanA = sc.clean(constructA)
mapPartitionsWithIndex { (index, iter) =>
val a = cleanA(index)
iter.map(t => {cleanF(t, a); t})
}
}
filterWith源码
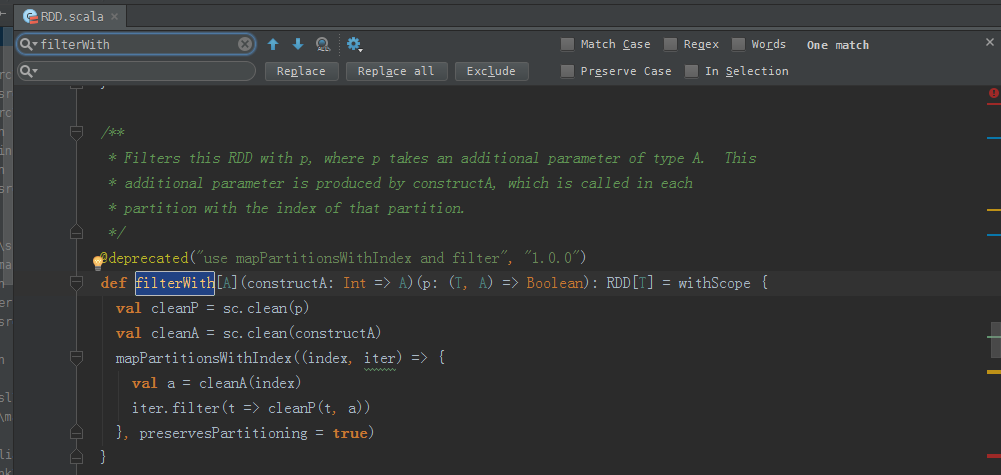
/**
* Filters this RDD with p, where p takes an additional parameter of type A. This
* additional parameter is produced by constructA, which is called in each
* partition with the index of that partition.
*/
@deprecated("use mapPartitionsWithIndex and filter", "1.0.0")
def filterWith[A](constructA: Int => A)(p: (T, A) => Boolean): RDD[T] = withScope {
val cleanP = sc.clean(p)
val cleanA = sc.clean(constructA)
mapPartitionsWithIndex((index, iter) => {
val a = cleanA(index)
iter.filter(t => cleanP(t, a))
}, preservesPartitioning = true)
}
zip源码
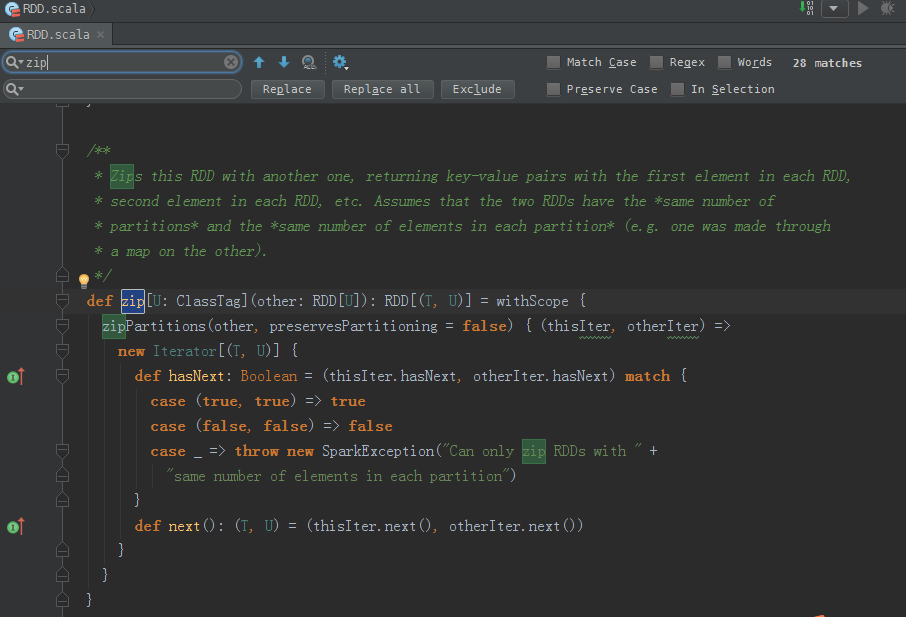
/**
* Zips this RDD with another one, returning key-value pairs with the first element in each RDD,
* second element in each RDD, etc. Assumes that the two RDDs have the *same number of
* partitions* and the *same number of elements in each partition* (e.g. one was made through
* a map on the other).
*/
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)] = withScope {
zipPartitions(other, preservesPartitioning = false) { (thisIter, otherIter) =>
new Iterator[(T, U)] {
def hasNext: Boolean = (thisIter.hasNext, otherIter.hasNext) match {
case (true, true) => true
case (false, false) => false
case _ => throw new SparkException("Can only zip RDDs with " +
"same number of elements in each partition")
}
def next(): (T, U) = (thisIter.next(), otherIter.next())
}
}
}
zipPartitions源码

/**
* Zip this RDD's partitions with one (or more) RDD(s) and return a new RDD by
* applying a function to the zipped partitions. Assumes that all the RDDs have the
* *same number of partitions*, but does *not* require them to have the same number
* of elements in each partition.
*/
def zipPartitions[B: ClassTag, V: ClassTag]
(rdd2: RDD[B], preservesPartitioning: Boolean)
(f: (Iterator[T], Iterator[B]) => Iterator[V]): RDD[V] = withScope {
new ZippedPartitionsRDD2(sc, sc.clean(f), this, rdd2, preservesPartitioning)
}
def zipPartitions[B: ClassTag, V: ClassTag]
(rdd2: RDD[B])
(f: (Iterator[T], Iterator[B]) => Iterator[V]): RDD[V] = withScope {
zipPartitions(rdd2, preservesPartitioning = false)(f)
}
def zipPartitions[B: ClassTag, C: ClassTag, V: ClassTag]
(rdd2: RDD[B], rdd3: RDD[C], preservesPartitioning: Boolean)
(f: (Iterator[T], Iterator[B], Iterator[C]) => Iterator[V]): RDD[V] = withScope {
new ZippedPartitionsRDD3(sc, sc.clean(f), this, rdd2, rdd3, preservesPartitioning)
}
def zipPartitions[B: ClassTag, C: ClassTag, V: ClassTag]
(rdd2: RDD[B], rdd3: RDD[C])
(f: (Iterator[T], Iterator[B], Iterator[C]) => Iterator[V]): RDD[V] = withScope {
zipPartitions(rdd2, rdd3, preservesPartitioning = false)(f)
}
def zipPartitions[B: ClassTag, C: ClassTag, D: ClassTag, V: ClassTag]
(rdd2: RDD[B], rdd3: RDD[C], rdd4: RDD[D], preservesPartitioning: Boolean)
(f: (Iterator[T], Iterator[B], Iterator[C], Iterator[D]) => Iterator[V]): RDD[V] = withScope {
new ZippedPartitionsRDD4(sc, sc.clean(f), this, rdd2, rdd3, rdd4, preservesPartitioning)
}
def zipPartitions[B: ClassTag, C: ClassTag, D: ClassTag, V: ClassTag]
(rdd2: RDD[B], rdd3: RDD[C], rdd4: RDD[D])
(f: (Iterator[T], Iterator[B], Iterator[C], Iterator[D]) => Iterator[V]): RDD[V] = withScope {
zipPartitions(rdd2, rdd3, rdd4, preservesPartitioning = false)(f)
}
foreach源码
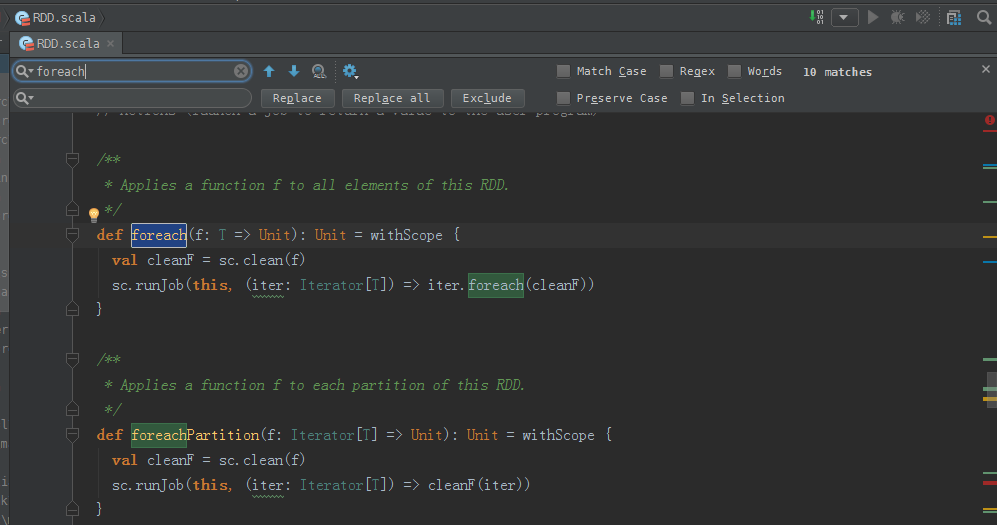
/**
* Applies a function f to all elements of this RDD.
*/
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}
/**
* Applies a function f to each partition of this RDD.
*/
def foreachPartition(f: Iterator[T] => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => cleanF(iter))
}
collect源码
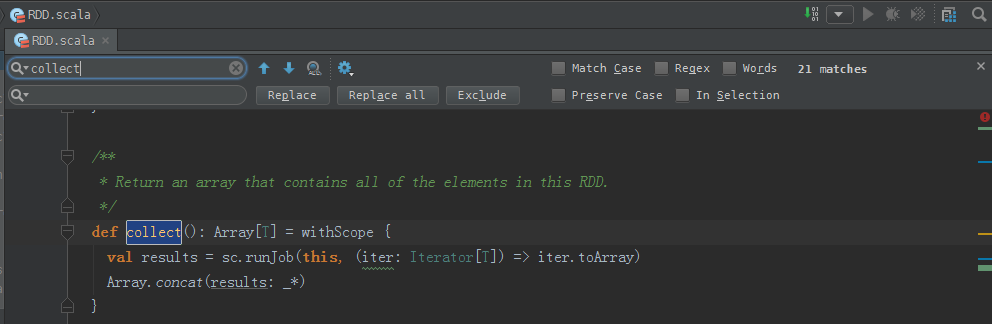
/**
* Return an array that contains all of the elements in this RDD.
*/
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
collectPartition源码
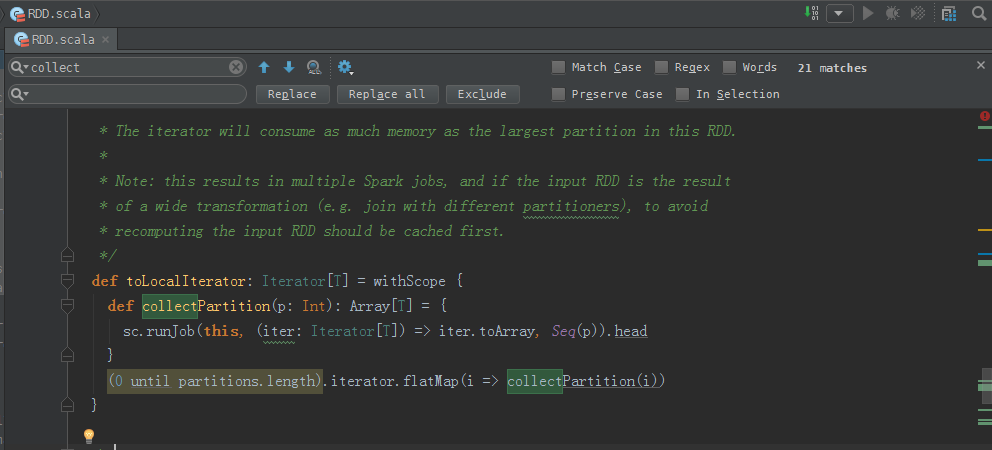
/**
* Return an iterator that contains all of the elements in this RDD.
*
* The iterator will consume as much memory as the largest partition in this RDD.
*
* Note: this results in multiple Spark jobs, and if the input RDD is the result
* of a wide transformation (e.g. join with different partitioners), to avoid
* recomputing the input RDD should be cached first.
*/
def toLocalIterator: Iterator[T] = withScope {
def collectPartition(p: Int): Array[T] = {
sc.runJob(this, (iter: Iterator[T]) => iter.toArray, Seq(p)).head
}
(0 until partitions.length).iterator.flatMap(i => collectPartition(i))
}
toArray源码
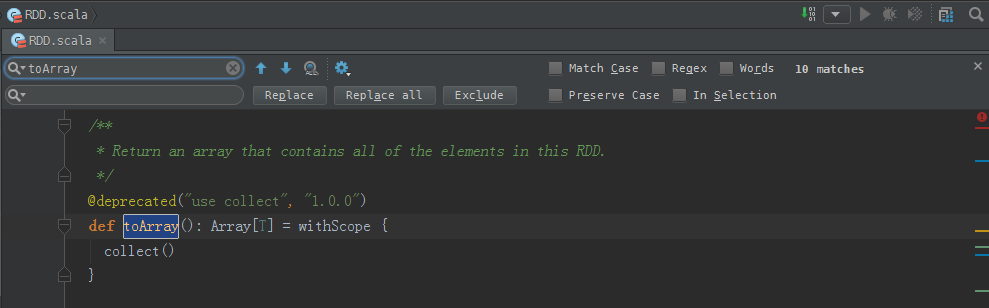
/**
* Return an array that contains all of the elements in this RDD.
*/
@deprecated("use collect", "1.0.0")
def toArray(): Array[T] = withScope {
collect()
}
collect源码
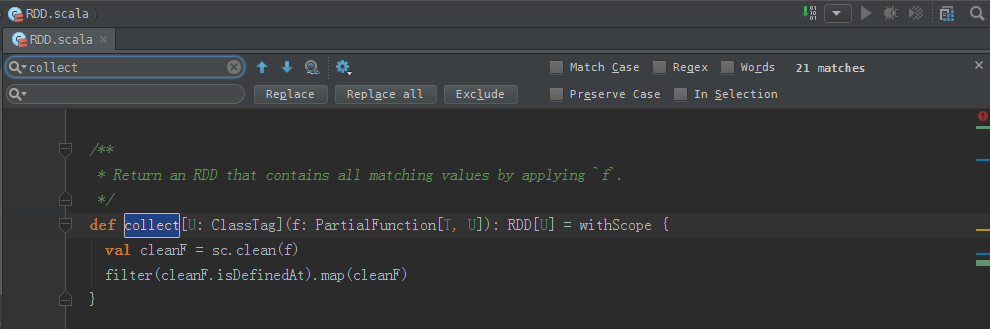
/**
* Return an RDD that contains all matching values by applying `f`.
*/
def collect[U: ClassTag](f: PartialFunction[T, U]): RDD[U] = withScope {
val cleanF = sc.clean(f)
filter(cleanF.isDefinedAt).map(cleanF)
}
其他的不一一赘述了
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

