
hadoop-2.6.0.tar.gz + spark-1.5.2-bin-hadoop2.6.tgz的集群搭建(单节点)(Ubuntu系统)
前言
本人呕心沥血所写,经过好一段时间反复锤炼和整理修改。感谢所参考的博友们!同时,欢迎前来查阅赏脸的博友们收藏和转载,附上本人的链接。http://www.cnblogs.com/zlslch/p/5847528.html
关于几个疑问和几处心得!
a.用NAT,还是桥接,还是only-host模式?
答: hostonly、桥接和NAT
b.用static的ip,还是dhcp的?
答:static
c.别认为快照和克隆不重要,小技巧,比别人灵活用,会很节省时间和大大减少错误。
d.重用起来脚本语言的编程,如paython或shell编程。
对于用scp -r命令或deploy.conf(配置文件),deploy.sh(实现文件复制的shell脚本文件),runRemoteCdm.sh(在远程节点上执行命令的shell脚本文件)。
e.重要Vmare Tools增强工具,或者,rz上传、sz下载。
f.大多数人常用

Xmanager Enterprise *安装步骤
用到的所需:
1、VMware-workstation-full-11.1.2.61471.1437365244.exe
2、ubuntukylin-14.04-desktop-amd64.iso
3、jdk-8u60-linux-x64.tar.gz
4、hadoop-2.6.0.tar.gz
5、scala-2.10.4.tgz
6、spark-1.5.2-bin-hadoop2.6.tgz
机器规划:
192.168.80.128 ---------------- SparkSignleNode
目录规划:
1、下载目录
/home/spark/Downloads/Spark_Cluster_Software ---------------- 存放所有安装软件

2、新建目录
3、安装目录
jdk-8u60-linux-x64.tar.gz -------------------------------------------------- /usr/local/jdk/jdk1.8.0_60
hadoop-2.6.0.tar.gz ---------------------------------------------------------- /usr/local/hadoop/hadoop-2.6.0
scala-2.10.4.tgz --------------------------------------------------------------- /usr/local/scala/scala-2.10.4
spark-1.5.2-bin-hadoop2.6.tgz ---------------------------------------------- /usr/local/spark/spark-1.5.2-bin-hadoop2.6
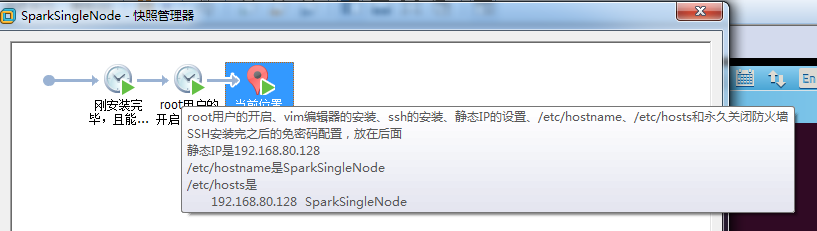
4、快照步骤
快照一:
刚安装完毕,且能连上网
快照二:
root用户的开启、vim编辑器的安装、ssh的安装、静态IP的设置、/etc/hostname和/etc/hosts和永久关闭防火墙
SSH安装完之后的免密码配置,放在后面
静态IP是192.168.80.128
/etc/hostname是SparkSingleNode
/etc/hosts是
192.168.80.128 SparkSingleNode
快照三:
安装jdk、安装scala、配置SSH免密码登录、安装python及ipython (这里,选择跳过也可以,ubuntu系统自带安装了python)
新建spark用户,(即用spark用户,去安装jdk、scala、配置SSH免密码、安装hadoop、安装spark...)
快照四:
安装hadoop(没格式化)、安装lrzsz、将自己写好的替换掉默认的配置文件、建立好目录
快照五:
安装hadoop(格式化)成功、进程启动正常
快照六:
spark的安装和配置工作完成
快照七:
启动hadoop、spark集群成功、查看50070、8088、8080、4040页面
第一步:
安装VMware-workstation虚拟机,我这里是VMware-workstation11版本。
详细见 ->
VMware workstation 11 的下载
VMWare Workstation 11的安装
VMware Workstation 11安装之后的一些配置
第二步:
安装ubuntukylin-14.04-desktop系统 (最好安装英文系统)
详细见 ->
Ubuntu各版本的历史发行界面
Ubuntukylin-14.04-desktop(带分区)安装步骤详解
Ubuntukylin-14.04-desktop( 不带分区)安装步骤详解
第三步:VMware Tools增强工具安装
详细见 ->
VMware里Ubuntukylin-14.04-desktop的VMware Tools安装图文详解
第四步:准备小修改(学会用快照和克隆,根据自身要求情况,合理位置快照)
详细见 ->
CentOS常用命令、快照、克隆大揭秘
E:Package 'Vim' has no installation candidate问题解决
解决Ubuntu系统的每次开机重启后,resolv.conf清空的问题
新建用户组、用户、用户密码、删除用户组、用户(适合CentOS、Ubuntu)
1、root用户的开启(Ubuntu系统,安装之后默认是没有root用户)
2、vim编辑器的安装
3、ssh的安装(SSH安装完之后的免密码配置,放在后面)
4、静态IP的设置
Ubuntu14.04安装之后的一些配置
5、/etc/hostname和/etc/hosts
root@SparkSingleNode:~# sudo cat /etc/hostname
SparkSingleNode
root@SparkSingleNode:~# sudo cat /etc/hosts
127.0.0.1 localhost
127.0.1.1 zhouls-virtual-machine
192.168.80.128 SparkSingleNode
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
6、永久关闭防火墙
一般,在搭建hadoop/spark集群时,最好是永久关闭防火墙,因为,防火墙会保护其进程间通信。
root@SparkSingleNode:~# sudo ufw status
Status: inactive
root@SparkSingleNode:~#

由此,表明Ubuntu14.04是默认没开启防火墙的。
三台机器都照做!
新建用户组、用户、用户密码、删除用户组、用户(适合CentOS、Ubuntu)
这个知识点,模糊了好久。!!!
生产中,习惯如下:
useradd,默认会将自身新建用户,添加到同名的用户组中。如,useradd zhouls,执行此命令后,默认就添加到同名的zhouls用户组中。
但是,在生产中,一般都不这么干。通常是,useradd -m -g 。否则,出现到时,用户建立出来了,但出现家目录没有哦。慎重!!!(重要的话,说三次)
###################Ubuntu系统里###########################
Ubuntu系统里,root用户执行,先怎么开启,见 Ubuntu14.04安装之后的一些配置
第一步:sudo groupadd 新建用户组
sudo groupadd spark 这是创建spark用户组
第二步:sudo useradd -m -g 已创建用户组 新建用户
sudo useradd -m -g spark spark 这是新建spark用户和家目录也创建,并增加到spark组中
第三步:sudo passwd 已创建用户
passwd spark spark用户密码
Changing password for user spark
New password :
Retype new password:
###################################
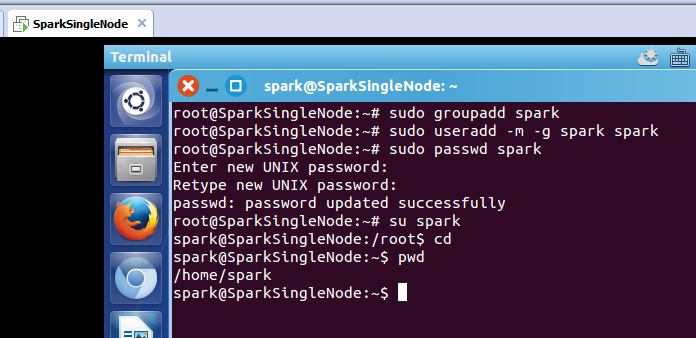
root@SparkSingleNode:~# sudo groupadd spark
root@SparkSingleNode:~# sudo useradd -m -g spark spark
root@SparkSingleNode:~# sudo passwd spark
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
root@SparkSingleNode:~# su spark
spark@SparkSingleNode:/root$ cd
spark@SparkSingleNode:~$ pwd
/home/spark
spark@SparkSingleNode:~$
安装前的思路梳理:
***********************************************************************************
* *
* 编程语言 -> hadoop 集群 -> spark 集群 *
* 1、安装jdk *
* 2、安装scala *
* 3、配置SSH免密码登录(SparkSingleNode自身)
* 4、安装python及ipython (这里,选择跳过也可以,ubuntu系统自带安装了python)
* 5、安装hadoop *
* 6、安装spark *
* 7、启动集群 *
* 8、查看页面 *
* 9、成功(记得快照) *
*******************************************************
用wget命令在线下载,养成习惯,放到/home/spark/Downloads/Spark_Cluster_Software/目录下,或者,安装了Vmare增强工具Tools,直接拖进去。也可以。
一、安装jdk
jdk-8u60-linux-x64.tar.gz -------------------------------------------------- /usr/local/jdk/jdk1.8.0_60
1、jdk-8u60-linux-x64.tar.gz的下载
下载,http://download.csdn.net/download/aqtata/9022063
2、jdk-8u60-linux-x64.tar.gz的上传
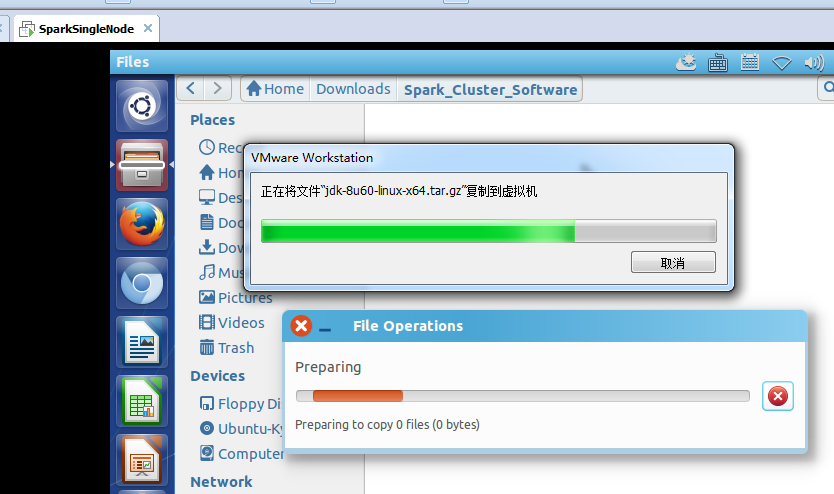

三台机器都照做!
3、首先,检查Ubuntu系统的自带openjdk
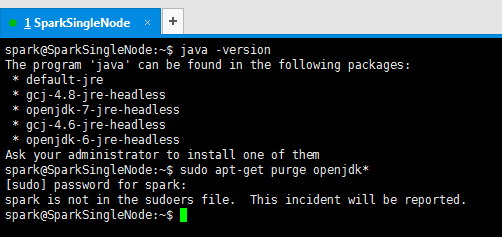
spark@SparkSingleNode:~$ java -version
The program 'java' can be found in the following packages:
* default-jre
* gcj-4.8-jre-headless
* openjdk-7-jre-headless
* gcj-4.6-jre-headless
* openjdk-6-jre-headless
Ask your administrator to install one of them
spark@SparkSingleNode:~$ sudo apt-get purge openjdk*
[sudo] password for spark:
spark is not in the sudoers file. This incident will be reported.
spark@SparkSingleNode:~$
由此,可见,此Ubuntu系统,没有自带的openjdk。
出现了, XXX 用户 is not in the sudoers file. This incident will be reported 的问题?
解决办法:
http://www.cnblogs.com/zox2011/archive/2013/05/28/3103824.html

spark@SparkSingleNode:~$ sudo apt-get purge openjdk*
Reading package lists... Done
Building dependency tree
Reading state information... Done
Note, selecting 'openjdk-jre' for regex 'openjdk*'
Note, selecting 'openjdk-6-jre-lib' for regex 'openjdk*'
Note, selecting 'openjdk-7' for regex 'openjdk*'
Note, selecting 'openjdk-6-jdk' for regex 'openjdk*'
Note, selecting 'openjdk-7-jre-zero' for regex 'openjdk*'
Note, selecting 'openjdk-6-source' for regex 'openjdk*'
Note, selecting 'openjdk-6-jre-headless' for regex 'openjdk*'
Note, selecting 'openjdk-6-dbg' for regex 'openjdk*'
Note, selecting 'openjdk-7-jdk' for regex 'openjdk*'
Note, selecting 'openjdk-7-jre-headless' for regex 'openjdk*'
Note, selecting 'openjdk-6-jre' for regex 'openjdk*'
Note, selecting 'openjdk-7-dbg' for regex 'openjdk*'
Note, selecting 'openjdk-7-jre-lib' for regex 'openjdk*'
Note, selecting 'uwsgi-plugin-jvm-openjdk-6' for regex 'openjdk*'
Note, selecting 'uwsgi-plugin-jvm-openjdk-7' for regex 'openjdk*'
Note, selecting 'openjdk-6-doc' for regex 'openjdk*'
Note, selecting 'openjdk-7-jre' for regex 'openjdk*'
Note, selecting 'openjdk-7-source' for regex 'openjdk*'
Note, selecting 'openjdk-6-jre-zero' for regex 'openjdk*'
Note, selecting 'openjdk-7-demo' for regex 'openjdk*'
Note, selecting 'openjdk-7-doc' for regex 'openjdk*'
Note, selecting 'openjdk-6-demo' for regex 'openjdk*'
Note, selecting 'uwsgi-plugin-jwsgi-openjdk-6' for regex 'openjdk*'
Note, selecting 'uwsgi-plugin-jwsgi-openjdk-7' for regex 'openjdk*'
Package 'openjdk-7' is not installed, so not removed
Package 'openjdk-jre' is not installed, so not removed
Package 'uwsgi-plugin-jvm-openjdk-6' is not installed, so not removed
Package 'uwsgi-plugin-jvm-openjdk-7' is not installed, so not removed
Package 'uwsgi-plugin-jwsgi-openjdk-6' is not installed, so not removed
4、现在,新建/usr/loca/下的jdk目录
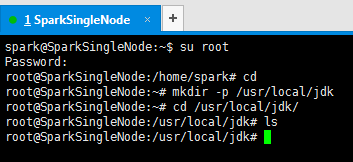
spark@SparkSingleNode:~$ su root
Password:
root@SparkSingleNode:/home/spark# cd
root@SparkSingleNode:~# mkdir -p /usr/local/jdk
root@SparkSingleNode:~# cd /usr/local/jdk/
root@SparkSingleNode:/usr/local/jdk# ls
root@SparkSingleNode:/usr/local/jdk#
5、将下载的jdk文件移到刚刚创建的/usr/local/jdk下

root@SparkSingleNode:/usr/local/jdk# su spark
spark@SparkSingleNode:/usr/local/jdk$ sudo cp /home/spark/Downloads/Spark_Cluster_Software/jdk-8u60-linux-x64.tar.gz /usr/local/jdk/
spark@SparkSingleNode:/usr/local/jdk$ cd /usr/local/jdk/
spark@SparkSingleNode:/usr/local/jdk$ ls
jdk-8u60-linux-x64.tar.gz
spark@SparkSingleNode:/usr/local/jdk$
最好用cp,不要轻易要mv
6、解压jdk文件
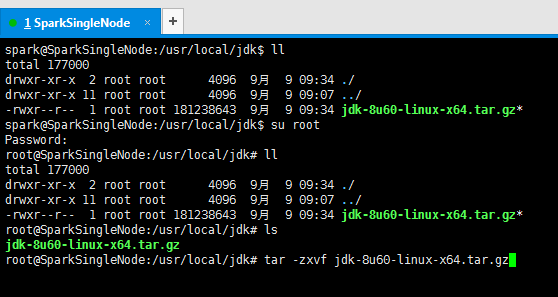
spark@SparkSingleNode:/usr/local/jdk$ ll
total 177000
drwxr-xr-x 2 root root 4096 9月 9 09:34 ./
drwxr-xr-x 11 root root 4096 9月 9 09:07 ../
-rwxr--r-- 1 root root 181238643 9月 9 09:34 jdk-8u60-linux-x64.tar.gz*
spark@SparkSingleNode:/usr/local/jdk$ su root
Password:
root@SparkSingleNode:/usr/local/jdk# ll
total 177000
drwxr-xr-x 2 root root 4096 9月 9 09:34 ./
drwxr-xr-x 11 root root 4096 9月 9 09:07 ../
-rwxr--r-- 1 root root 181238643 9月 9 09:34 jdk-8u60-linux-x64.tar.gz*
root@SparkSingleNode:/usr/local/jdk# ls
jdk-8u60-linux-x64.tar.gz
root@SparkSingleNode:/usr/local/jdk# tar -zxvf jdk-8u60-linux-x64.tar.gz
7、删除解压包,留下解压完成的文件目录,并修改权限(这是最重要的!)
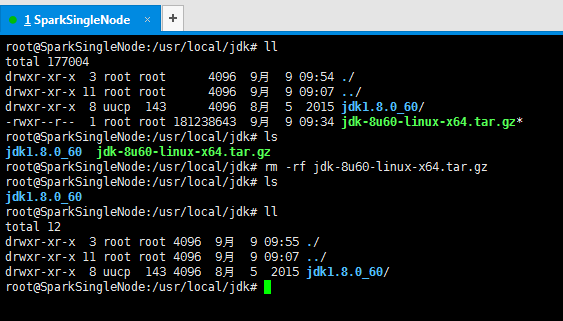
root@SparkSingleNode:/usr/local/jdk# ll
total 177004
drwxr-xr-x 3 root root 4096 9月 9 09:54 ./
drwxr-xr-x 11 root root 4096 9月 9 09:07 ../
drwxr-xr-x 8 uucp 143 4096 8月 5 2015 jdk1.8.0_60/
-rwxr--r-- 1 root root 181238643 9月 9 09:34 jdk-8u60-linux-x64.tar.gz*
root@SparkSingleNode:/usr/local/jdk# ls
jdk1.8.0_60 jdk-8u60-linux-x64.tar.gz
root@SparkSingleNode:/usr/local/jdk# rm -rf jdk-8u60-linux-x64.tar.gz
root@SparkSingleNode:/usr/local/jdk# ls
jdk1.8.0_60
root@SparkSingleNode:/usr/local/jdk# ll
total 12
drwxr-xr-x 3 root root 4096 9月 9 09:55 ./
drwxr-xr-x 11 root root 4096 9月 9 09:07 ../
drwxr-xr-x 8 uucp 143 4096 8月 5 2015 jdk1.8.0_60/
root@SparkSingleNode:/usr/local/jdk#
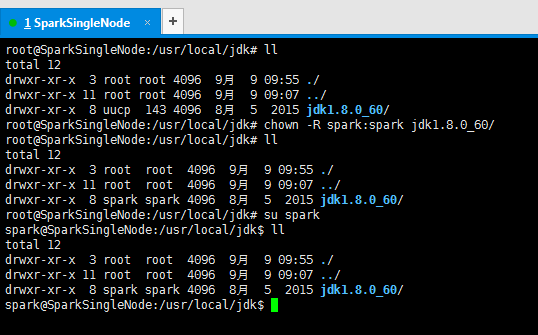
root@SparkSingleNode:/usr/local/jdk# ll
total 12
drwxr-xr-x 3 root root 4096 9月 9 09:55 ./
drwxr-xr-x 11 root root 4096 9月 9 09:07 ../
drwxr-xr-x 8 uucp 143 4096 8月 5 2015 jdk1.8.0_60/
root@SparkSingleNode:/usr/local/jdk# chown -R spark:spark jdk1.8.0_60/
root@SparkSingleNode:/usr/local/jdk# ll
total 12
drwxr-xr-x 3 root root 4096 9月 9 09:55 ./
drwxr-xr-x 11 root root 4096 9月 9 09:07 ../
drwxr-xr-x 8 spark spark 4096 8月 5 2015 jdk1.8.0_60/
root@SparkSingleNode:/usr/local/jdk# su spark
spark@SparkSingleNode:/usr/local/jdk$ ll
total 12
drwxr-xr-x 3 root root 4096 9月 9 09:55 ./
drwxr-xr-x 11 root root 4096 9月 9 09:07 ../
drwxr-xr-x 8 spark spark 4096 8月 5 2015 jdk1.8.0_60/
spark@SparkSingleNode:/usr/local/jdk$
***********************************************
chown -R 用户组:用户 文件
一般,我们也可以在之前,新建用户组时,为sparkuser,然后,它里面的用户,有spark1,spark2...
那么,对应就是, chown -R sparkuser:spark1 jdk1.8.0_60
如,对hadoop-2.6.0.tar.gz的被解压文件,做权限修改。
chown -R hduser:hadoop hadoop-2.6.0
**********************************************
8、修改环境变量
vim ~./bash_profile 或 vim /etc/profile
配置在这个文件~/.bash_profile,或者也可以,配置在那个全局的文件里,也可以哟。/etc/profile。
这里,我vim /etc/profile
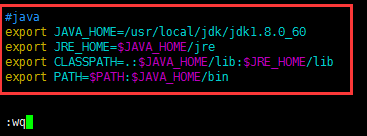
#java
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
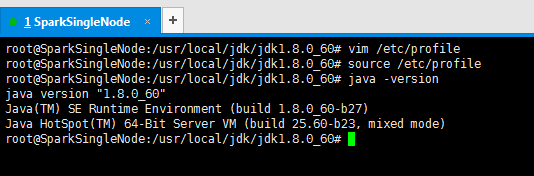
root@SparkSingleNode:/usr/local/jdk/jdk1.8.0_60# vim /etc/profile
root@SparkSingleNode:/usr/local/jdk/jdk1.8.0_60# source /etc/profile
root@SparkSingleNode:/usr/local/jdk/jdk1.8.0_60# java -version
java version "1.8.0_60"
Java(TM) SE Runtime Environment (build 1.8.0_60-b27)
Java HotSpot(TM) 64-Bit Server VM (build 25.60-b23, mixed mode)
root@SparkSingleNode:/usr/local/jdk/jdk1.8.0_60#
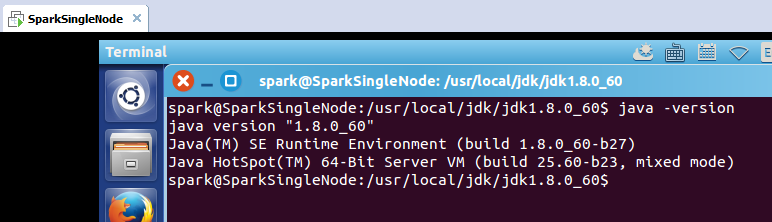
spark@SparkSingleNode:/usr/local/jdk/jdk1.8.0_60$ java -version
java version "1.8.0_60"
Java(TM) SE Runtime Environment (build 1.8.0_60-b27)
Java HotSpot(TM) 64-Bit Server VM (build 25.60-b23, mixed mode)
spark@SparkSingleNode:/usr/local/jdk/jdk1.8.0_60$
至此,表明java安装结束。
其他两台都照做!
二、安装scala
scala-2.10.4.tgz --------------------------------------------------------------- /usr/local/scala/scala-2.10.4
1、scala的下载
http://www.scala-lang.org/files/archive/
2、scala-2.10.4.tgz 的上传

其他两台都照做!
3、现在,新建/usr/loca/下的sacla目录
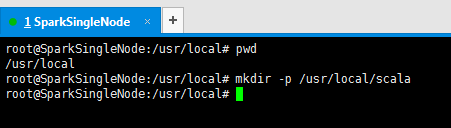
root@SparkSingleNode:/usr/local# pwd
/usr/local
root@SparkSingleNode:/usr/local# mkdir -p /usr/local/scala
root@SparkSingleNode:/usr/local#
4、将下载的scala文件移到刚刚创建的/usr/local/scala下

root@SparkSingleNode:/usr/local/scala# pwd
/usr/local/scala
root@SparkSingleNode:/usr/local/scala# ls
root@SparkSingleNode:/usr/local/scala# sudo cp /home/spark/Downloads/Spark_Cluster_Software/scala-2.10.4.tgz /usr/local/scala/
root@SparkSingleNode:/usr/local/scala# ls
scala-2.10.4.tgz
root@SparkSingleNode:/usr/local/scala#
最好用cp,不要轻易要mv
5、解压scala文件

root@SparkSingleNode:/usr/local/scala# pwd
/usr/local/scala
root@SparkSingleNode:/usr/local/scala# ls
scala-2.10.4.tgz
root@SparkSingleNode:/usr/local/scala# ll
total 29244
drwxr-xr-x 2 root root 4096 9月 9 10:15 ./
drwxr-xr-x 12 root root 4096 9月 9 10:14 ../
-rwxr--r-- 1 root root 29937534 9月 9 10:15 scala-2.10.4.tgz*
root@SparkSingleNode:/usr/local/scala# tar -zxvf scala-2.10.4.tgz
6、删除解压包,留下解压完成的文件目录,并修改权限(这是最重要的!!!)

root@SparkSingleNode:/usr/local/scala# ls
scala-2.10.4 scala-2.10.4.tgz
root@SparkSingleNode:/usr/local/scala# ll
total 29248
drwxr-xr-x 3 root root 4096 9月 9 10:17 ./
drwxr-xr-x 12 root root 4096 9月 9 10:14 ../
drwxrwxr-x 9 2000 2000 4096 3月 18 2014 scala-2.10.4/
-rwxr--r-- 1 root root 29937534 9月 9 10:15 scala-2.10.4.tgz*
root@SparkSingleNode:/usr/local/scala# rm -rf scala-2.10.4.tgz
root@SparkSingleNode:/usr/local/scala# ll
total 12
drwxr-xr-x 3 root root 4096 9月 9 10:18 ./
drwxr-xr-x 12 root root 4096 9月 9 10:14 ../
drwxrwxr-x 9 2000 2000 4096 3月 18 2014 scala-2.10.4/
root@SparkSingleNode:/usr/local/scala# chown -R spark:spark scala-2.10.4/
root@SparkSingleNode:/usr/local/scala# ll
total 12
drwxr-xr-x 3 root root 4096 9月 9 10:18 ./
drwxr-xr-x 12 root root 4096 9月 9 10:14 ../
drwxrwxr-x 9 spark spark 4096 3月 18 2014 scala-2.10.4/
root@SparkSingleNode:/usr/local/scala#
7、修改环境变量
vim ~./bash_profile 或 vim /etc/profile
配置在这个文件~/.bash_profile,或者也可以,配置在那个全局的文件里,也可以哟。/etc/profile。
这里,我vim /etc/profile
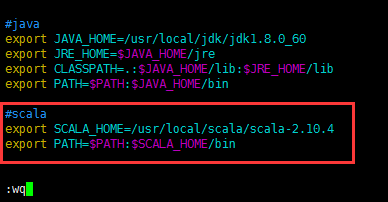
#scala
export SCALA_HOME=/usr/local/scala/scala-2.10.4
export PATH=$PATH:$SCALA_HOME/bin
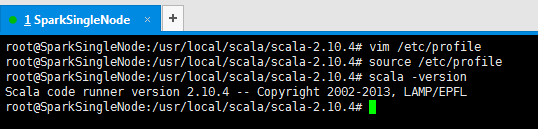
root@SparkSingleNode:/usr/local/scala/scala-2.10.4# vim /etc/profile
root@SparkSingleNode:/usr/local/scala/scala-2.10.4# source /etc/profile
root@SparkSingleNode:/usr/local/scala/scala-2.10.4# scala -version
Scala code runner version 2.10.4 -- Copyright 2002-2013, LAMP/EPFL
root@SparkSingleNode:/usr/local/scala/scala-2.10.4#
至此,表明scala安装结束。
其他两台都照做!
8、输入scala命令,可直接进入scala的命令行交互界面。
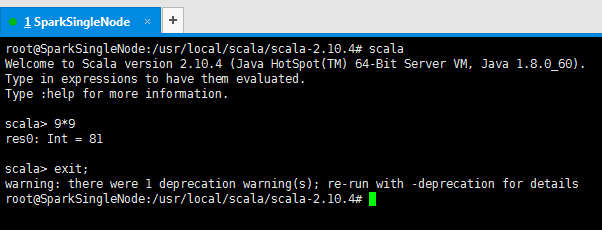
root@SparkSingleNode:/usr/local/scala/scala-2.10.4# scala
Welcome to Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_60).
Type in expressions to have them evaluated.
Type :help for more information.
scala> 9*9
res0: Int = 81
scala> exit;
warning: there were 1 deprecation warning(s); re-run with -deprecation for details
root@SparkSingleNode:/usr/local/scala/scala-2.10.4#
三、配置免密码登录
1、配置SSH实现无密码验证配置,首先切换到刚创建的spark用户下。
因为,我后续,是先搭建hadoop集群,在其基础上,再搭建spark集群,目的,是在spark用户下操作进行的。
所以,在这里,要梳理下的是,root和zhouls,都是管理员权限。在生产环境里,一般是不会动用这两个管理员用户的。
由于spark需要无密码登录作为worker的节点,而由于部署单节点的时候,当前节点既是master又是worker,所以此时需要生成无密码登录的ssh。方法如下:
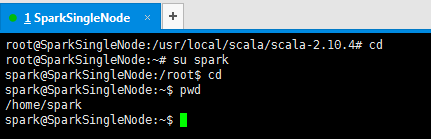
root@SparkSingleNode:/usr/local/scala/scala-2.10.4# cd
root@SparkSingleNode:~# su spark
spark@SparkSingleNode:/root$ cd
spark@SparkSingleNode:~$ pwd
/home/spark
spark@SparkSingleNode:~$
2 、创建.ssh目录,生成密钥
mkdir .ssh
ssh-keygen -t rsa 注意,ssh与keygen之间是没有空格的
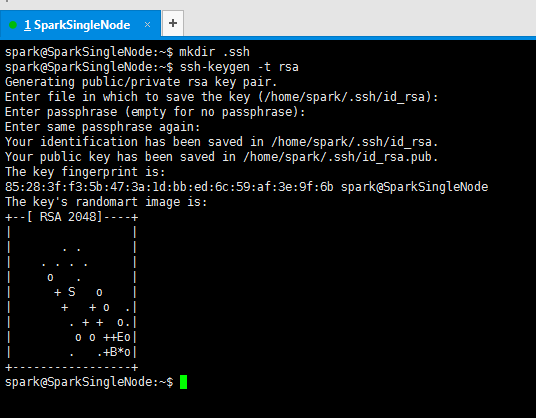
spark@SparkSingleNode:~$ mkdir .ssh
spark@SparkSingleNode:~$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/spark/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/spark/.ssh/id_rsa.
Your public key has been saved in /home/spark/.ssh/id_rsa.pub.
The key fingerprint is:
85:28:3f:f3:5b:47:3a:1d:bb:ed:6c:59:af:3e:9f:6b spark@SparkSingleNode
The key's randomart image is:
+--[ RSA 2048]----+
| |
| . . |
| . . . . |
| o . |
| + S o |
| + + o .|
| . + + o.|
| o o ++Eo|
| . .+B*o|
+-----------------+
spark@SparkSingleNode:~$
3 、切换到.ssh目录下,进行查看公钥和私钥
cd .ssh
ls

spark@SparkSingleNode:~$ cd .ssh
spark@SparkSingleNode:~/.ssh$ ls
id_rsa id_rsa.pub
spark@SparkSingleNode:~/.ssh$
4、将公钥复制到日志文件里。查看是否复制成功
cp id_rsa.pub authorized_keys
ls

spark@SparkSingleNode:~/.ssh$ cp id_rsa.pub authorized_keys
spark@SparkSingleNode:~/.ssh$ ls
authorized_keys id_rsa id_rsa.pub
spark@SparkSingleNode:~/.ssh$
5、查看日记文件具体内容

spark@SparkSingleNode:~/.ssh$ cat authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCqLwZVCWJOQT57Y9MAYw8YJtzqvJTnBob656jvKgLSaM5X8/cikS0HHGlfNqzldbP03+Z6ZrpaF2hyEV1v43kOhlqA9SFwTVhzbPzou2K0e7mgCjJlM4PQMOSZY+DUlHn08hDxdbgAhczj6pix4VNSORg2nBRLvk1CDFYSiviv+FRTxy4IhYfG0M74fOE/9jHnbXKNRmryexzSwEylVqISQFmt5X5ksqurTsIxc2M70mGnkoTAVNOMC/qNVw98FsTBwFLT9J8X3vtic7nn5PjLNi/Khyc/vOhiDpzRsJJ7r7BuaKvd/ENIu9WAjvSGvJKLfqx6SSGcociom7ol1S/Z spark@SparkSingleNode
spark@SparkSingleNode:~/.ssh$
6、退回到/home/spark/,来赋予权限
cd ..
chmod 700 .ssh 将.ssh文件夹的权限赋予700
chmod 600 .ssh/* 将.ssh文件夹里面的文件(id_rsa、id_rsa.pub、authorized_keys)的权限赋予600

spark@SparkSingleNode:~/.ssh$ cd ..
spark@SparkSingleNode:~$ pwd
/home/spark
spark@SparkSingleNode:~$ chmod 700 .ssh
spark@SparkSingleNode:~$ chmod 600 .ssh/*
spark@SparkSingleNode:~$
7、测试ssh无密码访问
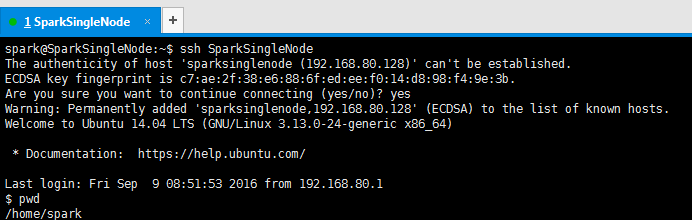
spark@SparkSingleNode:~$ ssh SparkSingleNode
The authenticity of host 'sparksinglenode (192.168.80.128)' can't be established.
ECDSA key fingerprint is c7:ae:2f:38:e6:88:6f:ed:ee:f0:14:d8:98:f4:9e:3b.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'sparksinglenode,192.168.80.128' (ECDSA) to the list of known hosts.
Welcome to Ubuntu 14.04 LTS (GNU/Linux 3.13.0-24-generic x86_64)
* Documentation: https://help.ubuntu.com/
Last login: Fri Sep 9 08:51:53 2016 from 192.168.80.1
$ pwd
/home/spark
spark@SparkSingleNode:~$ ssh SparkSingleNode
Welcome to Ubuntu 14.04 LTS (GNU/Linux 3.13.0-24-generic x86_64)
* Documentation: https://help.ubuntu.com/
Last login: Fri Sep 9 10:35:48 2016 from sparksinglenode
$ exit;
Connection to sparksinglenode closed.
spark@SparkSingleNode:~$
四、安装python及ipython (这里,选择跳过也可以,ubuntu系统自带安装了python)
默认的安装目录,是在/usr/lib/下

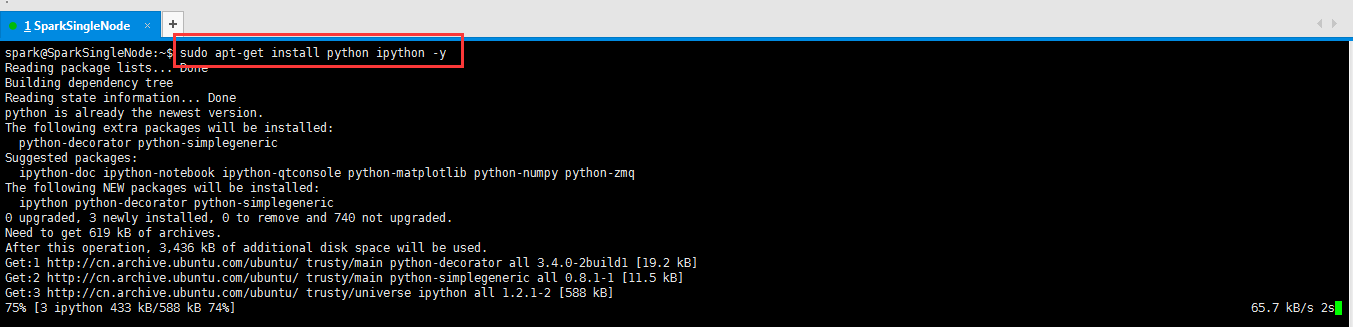
spark@SparkSingleNode:~$ sudo apt-get install python ipython -y
Reading package lists... Done
Building dependency tree
Reading state information... Done
python is already the newest version.
The following extra packages will be installed:
python-decorator python-simplegeneric
Suggested packages:
ipython-doc ipython-notebook ipython-qtconsole python-matplotlib python-numpy python-zmq
The following NEW packages will be installed:
ipython python-decorator python-simplegeneric
0 upgraded, 3 newly installed, 0 to remove and 740 not upgraded.
Need to get 619 kB of archives.
After this operation, 3,436 kB of additional disk space will be used.
Get:1 http://cn.archive.ubuntu.com/ubuntu/ trusty/main python-decorator all 3.4.0-2build1 [19.2 kB]
Get:2 http://cn.archive.ubuntu.com/ubuntu/ trusty/main python-simplegeneric all 0.8.1-1 [11.5 kB]
Get:3 http://cn.archive.ubuntu.com/ubuntu/ trusty/universe ipython all 1.2.1-2 [588 kB]
Fetched 619 kB in 31s (19.8 kB/s)
Selecting previously unselected package python-decorator.
(Reading database ... 147956 files and directories currently installed.)
Preparing to unpack .../python-decorator_3.4.0-2build1_all.deb ...
Unpacking python-decorator (3.4.0-2build1) ...
Selecting previously unselected package python-simplegeneric.
Preparing to unpack .../python-simplegeneric_0.8.1-1_all.deb ...
Unpacking python-simplegeneric (0.8.1-1) ...
Selecting previously unselected package ipython.
Preparing to unpack .../ipython_1.2.1-2_all.deb ...
Unpacking ipython (1.2.1-2) ...
Processing triggers for man-db (2.6.7.1-1) ...
Processing triggers for hicolor-icon-theme (0.13-1) ...
Processing triggers for gnome-menus (3.10.1-0ubuntu2) ...
Processing triggers for desktop-file-utils (0.22-1ubuntu1) ...
Processing triggers for bamfdaemon (0.5.1+14.04.20140409-0ubuntu1) ...
Rebuilding /usr/share/applications/bamf-2.index...
Processing triggers for mime-support (3.54ubuntu1) ...
Setting up python-decorator (3.4.0-2build1) ...
Setting up python-simplegeneric (0.8.1-1) ...
Setting up ipython (1.2.1-2) ...
spark@SparkSingleNode:~$
测试是否安装成功
spark@SparkSingleNode:~$ python --version
Python 2.7.6
spark@SparkSingleNode:~$ ipython --version
1.2.1
spark@SparkSingleNode:~$
同时,对ipython,想说的是。
IPYTHON and IPYTHON_OPTS are removed in Spark 2.0+ . Remove these from the environment and set PYSPARK_DRIVER_PYTHON and PYSPARK_DRIVER_PYTHON_OPTS instead .
在任何路径下,都可以执行python。
spark@SparkSingleNode:~$ python
Python 2.7.6 (default, Mar 22 2014, 22:59:56)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> exit()
spark@SparkSingleNode:~$ cd /usr/local/
spark@SparkSingleNode:/usr/local$ python
Python 2.7.6 (default, Mar 22 2014, 22:59:56)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> exit()
spark@SparkSingleNode:/usr/local$ cd /usr/lib/
spark@SparkSingleNode:/usr/lib$ python
Python 2.7.6 (default, Mar 22 2014, 22:59:56)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> exit()
spark@SparkSingleNode:/usr/lib$

五、安装hadoop
hadoop-2.6.0.tar.gz ---------------------------------------------------------- /usr/local/hadoop/hadoop-2.6.0
1、hadoop的下载
http://archive.apache.org/dist/hadoop/common/hadoop-2.6.0/

2、hadoop-2.6.0.tar.gz的上传
3、现在,新建/usr/loca/下的hadoop目录

root@SparkSingleNode:/usr/local# pwd
/usr/local
root@SparkSingleNode:/usr/local# mkdir -p /usr/local/hadoop
root@SparkSingleNode:/usr/local# ls
bin etc games hadoop include jdk lib man sbin scala share src
root@SparkSingleNode:/usr/local# cd hadoop/
root@SparkSingleNode:/usr/local/hadoop# pwd
/usr/local/hadoop
root@SparkSingleNode:/usr/local/hadoop# ls
root@SparkSingleNode:/usr/local/hadoop#
4、将下载的hadoop文件移到刚刚创建的/usr/local/hadoop下

最好用cp,不要轻易要mv
root@SparkSingleNode:/usr/local/hadoop# sudo cp /home/spark/Downloads/Spark_Cluster_Software/hadoop-2.6.0.tar.gz /usr/local/hadoop/
root@SparkSingleNode:/usr/local/hadoop# ls
hadoop-2.6.0.tar.gz
root@SparkSingleNode:/usr/local/hadoop#
5、解压hadoop文件

root@SparkSingleNode:/usr/local/hadoop# ls
hadoop-2.6.0.tar.gz
root@SparkSingleNode:/usr/local/hadoop# tar -zxvf hadoop-2.6.0.tar.gz
6、删除解压包,留下解压完成的文件目录
并修改所属的用户组和用户(这是最重要的!)
root@SparkSingleNode:/usr/local/hadoop# ls
hadoop-2.6.0 hadoop-2.6.0.tar.gz
root@SparkSingleNode:/usr/local/hadoop# rm -rf hadoop-2.6.0.tar.gz
root@SparkSingleNode:/usr/local/hadoop# ls
hadoop-2.6.0
root@SparkSingleNode:/usr/local/hadoop# ll
total 12
drwxr-xr-x 3 root root 4096 9月 9 11:33 ./
drwxr-xr-x 13 root root 4096 9月 9 11:28 ../
drwxr-xr-x 9 20000 20000 4096 11月 14 2014 hadoop-2.6.0/
root@SparkSingleNode:/usr/local/hadoop# chown -R spark:spark hadoop-2.6.0/
root@SparkSingleNode:/usr/local/hadoop# ll
total 12
drwxr-xr-x 3 root root 4096 9月 9 11:33 ./
drwxr-xr-x 13 root root 4096 9月 9 11:28 ../
drwxr-xr-x 9 spark spark 4096 11月 14 2014 hadoop-2.6.0/
root@SparkSingleNode:/usr/local/hadoop#
7、修改环境变量
vim ~./bash_profile 或 vim /etc/profile
配置在这个文件~/.bash_profile,或者也可以,配置在那个全局的文件里,也可以哟。/etc/profile。
这里,我vim /etc/profile
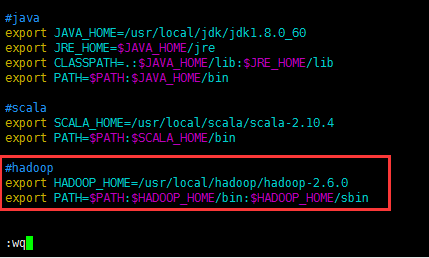
#hadoop
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
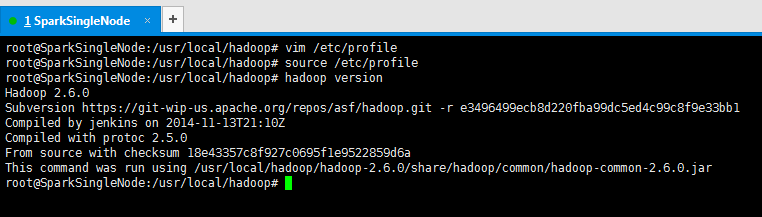
root@SparkSingleNode:/usr/local/hadoop# vim /etc/profile
root@SparkSingleNode:/usr/local/hadoop# source /etc/profile
root@SparkSingleNode:/usr/local/hadoop# hadoop version
Hadoop 2.6.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/hadoop-common-2.6.0.jar
root@SparkSingleNode:/usr/local/hadoop#
至此,表明hadoop安装结束。
配置hadoop的配置文件
经验起见,一般都是在NotePad++里,弄好,丢上去。

在windows里解压,打开它的配置,写好。
核心

<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://SparkSingleNode:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-2.6.0/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
上面配置的是,因为在hadoop1.0中引入了安全机制,所以从客户端发出的作业提交者全变成了hadoop,不管原始提交者是哪个用户,为了解决该问题,引入了安全违章功能,允许一个超级用户来代替其他用户来提交作业或者执行命令,而对外来看,执行者仍然是普通用户。所以 ,配置设为任意客户端 和 配置设为任意用户组 。
存储
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
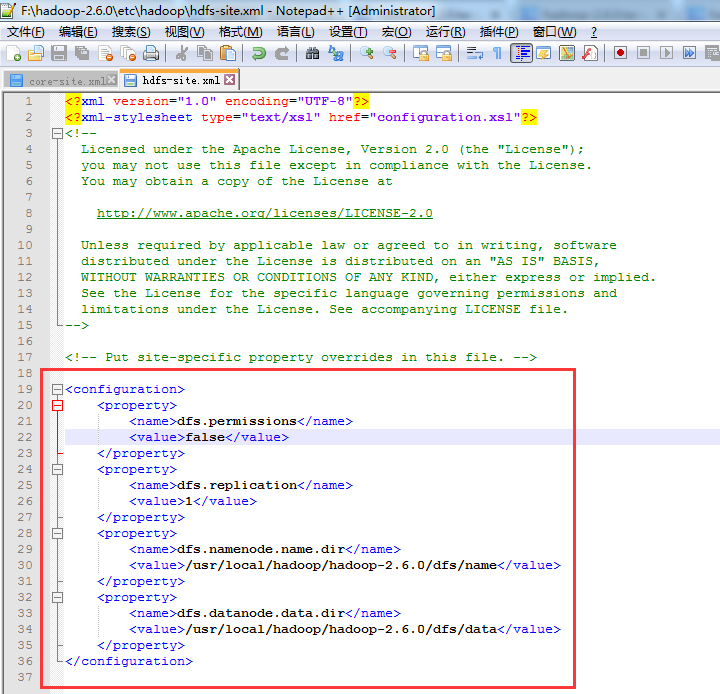
<configuration>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hadoop-2.6.0/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hadoop-2.6.0/dfs/data</value>
</property>
</configuration>
计算
 变成
变成 
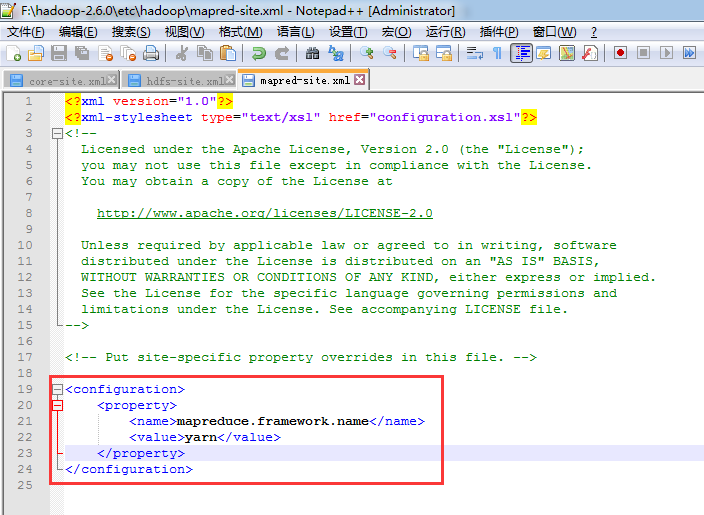
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
管理
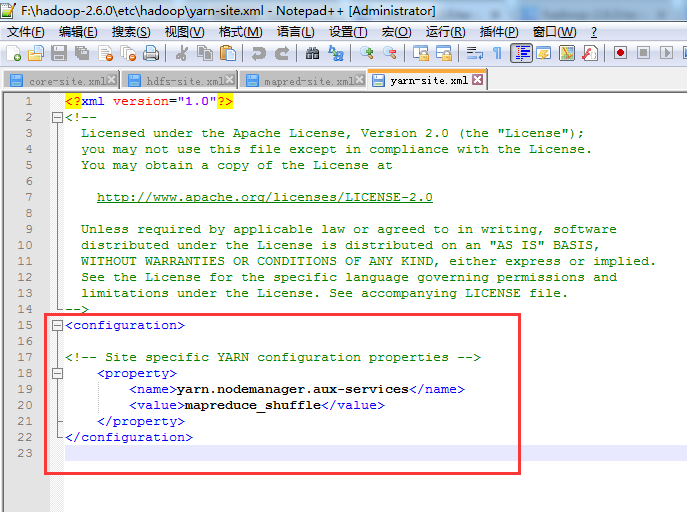
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
环境
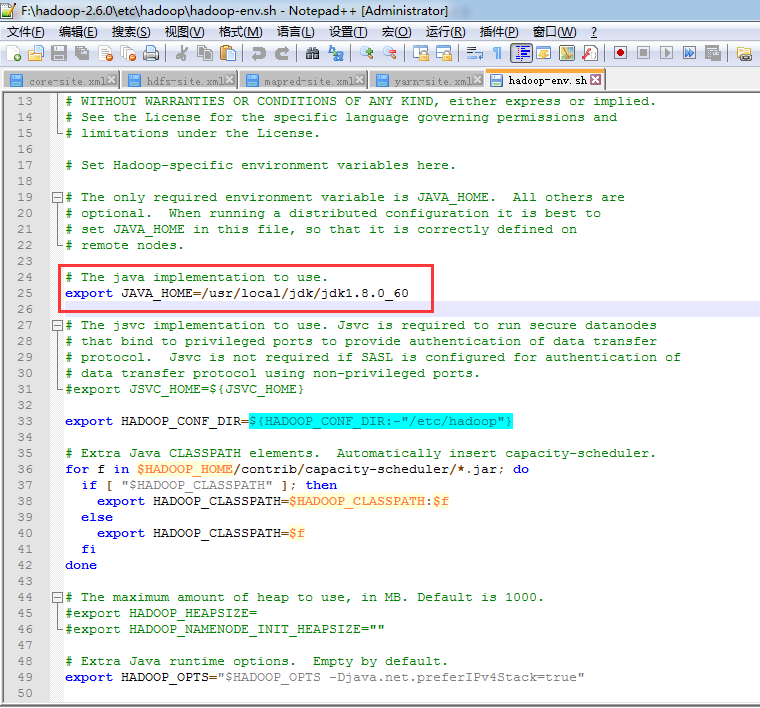
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60
# The jsvc implementation to use. Jsvc is required to run secure datanodes
# that bind to privileged ports to provide authentication of data transfer
# protocol. Jsvc is not required if SASL is configured for authentication of
# data transfer protocol using non-privileged ports.
#export JSVC_HOME=${JSVC_HOME}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
# Extra Java CLASSPATH elements. Automatically insert capacity-scheduler.
for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
if [ "$HADOOP_CLASSPATH" ]; then
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
else
export HADOOP_CLASSPATH=$f
fi
done
# The maximum amount of heap to use, in MB. Default is 1000.
#export HADOOP_HEAPSIZE=
#export HADOOP_NAMENODE_INIT_HEAPSIZE=""
# Extra Java runtime options. Empty by default.
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
# Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
#HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS"
# On secure datanodes, user to run the datanode as after dropping privileges.
# This **MUST** be uncommented to enable secure HDFS if using privileged ports
# to provide authentication of data transfer protocol. This **MUST NOT** be
# defined if SASL is configured for authentication of data transfer protocol
# using non-privileged ports.
export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER}
# Where log files are stored. $HADOOP_HOME/logs by default.
#export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER
# Where log files are stored in the secure data environment.
export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER}
###
# HDFS Mover specific parameters
###
# Specify the JVM options to be used when starting the HDFS Mover.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HADOOP_MOVER_OPTS=""
###
# Advanced Users Only!
###
# The directory where pid files are stored. /tmp by default.
# NOTE: this should be set to a directory that can only be written to by
# the user that will run the hadoop daemons. Otherwise there is the
# potential for a symlink attack.
export HADOOP_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
# A string representing this instance of hadoop. $USER by default.
export HADOOP_IDENT_STRING=$USER
主、从节点

SparkSingleNode
将SparkSingleNode的各自原有配置这几个文件,删去。

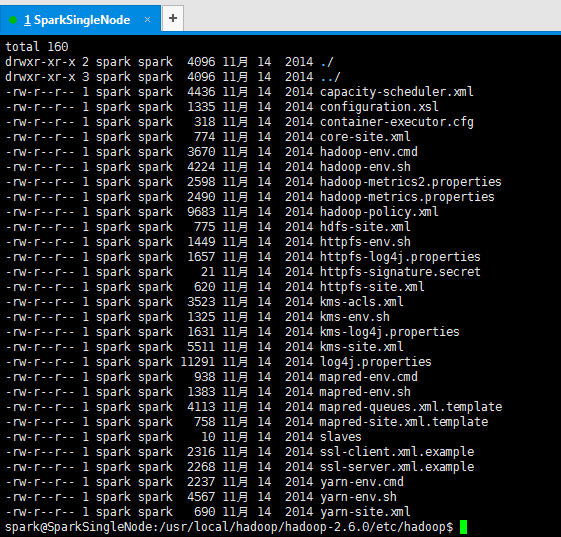
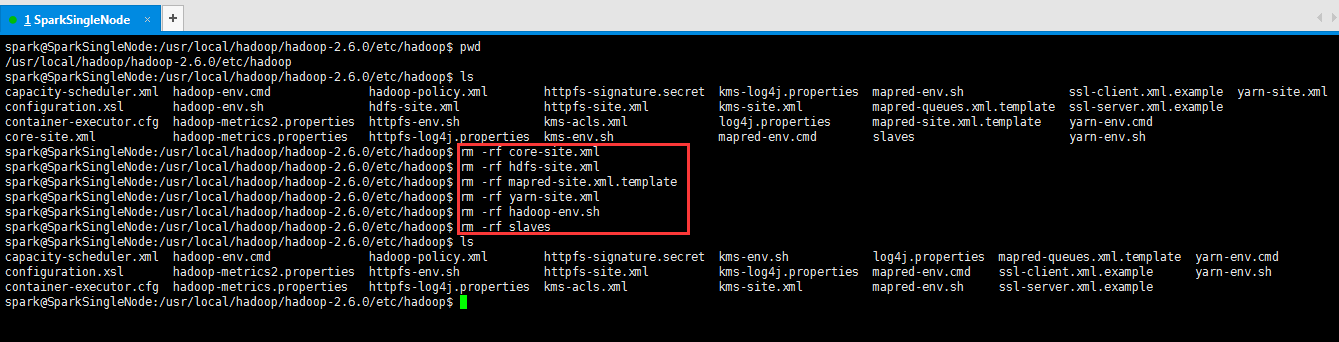
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ pwd
/usr/local/hadoop/hadoop-2.6.0/etc/hadoop
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ ls
capacity-scheduler.xml hadoop-env.cmd hadoop-policy.xml httpfs-signature.secret kms-log4j.properties mapred-env.sh ssl-client.xml.example yarn-site.xml
configuration.xsl hadoop-env.sh hdfs-site.xml httpfs-site.xml kms-site.xml mapred-queues.xml.template ssl-server.xml.example
container-executor.cfg hadoop-metrics2.properties httpfs-env.sh kms-acls.xml log4j.properties mapred-site.xml.template yarn-env.cmd
core-site.xml hadoop-metrics.properties httpfs-log4j.properties kms-env.sh mapred-env.cmd slaves yarn-env.sh
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ rm -rf core-site.xml
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ rm -rf hdfs-site.xml
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ rm -rf mapred-site.xml.template
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ rm -rf yarn-site.xml
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ rm -rf hadoop-env.sh
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ rm -rf slaves
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ ls
capacity-scheduler.xml hadoop-env.cmd hadoop-policy.xml httpfs-signature.secret kms-env.sh log4j.properties mapred-queues.xml.template yarn-env.cmd
configuration.xsl hadoop-metrics2.properties httpfs-env.sh httpfs-site.xml kms-log4j.properties mapred-env.cmd ssl-client.xml.example yarn-env.sh
container-executor.cfg hadoop-metrics.properties httpfs-log4j.properties kms-acls.xml kms-site.xml mapred-env.sh ssl-server.xml.example
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$
将写好的,丢上去。
root@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop# pwd
/usr/local/hadoop/hadoop-2.6.0/etc/hadoop
root@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop# rz
The program 'rz' is currently not installed. You can install it by typing:
apt-get install lrzsz
root@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop# sudo apt-get install lrzsz
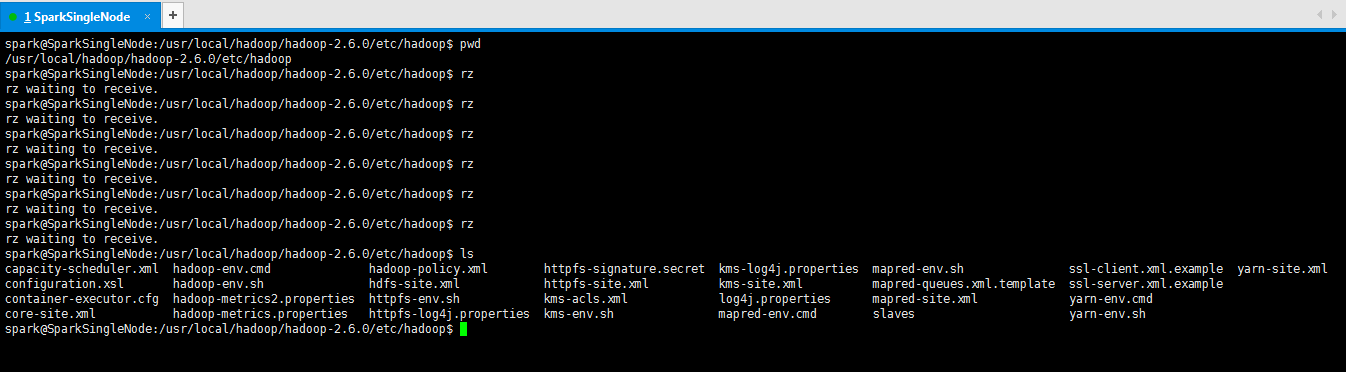
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ pwd
/usr/local/hadoop/hadoop-2.6.0/etc/hadoop
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ rz
rz waiting to receive.
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ rz
rz waiting to receive.
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ rz
rz waiting to receive.
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ rz
rz waiting to receive.
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ rz
rz waiting to receive.
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ rz
rz waiting to receive.
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ ls
capacity-scheduler.xml hadoop-env.cmd hadoop-policy.xml httpfs-signature.secret kms-log4j.properties mapred-env.sh ssl-client.xml.example yarn-site.xml
configuration.xsl hadoop-env.sh hdfs-site.xml httpfs-site.xml kms-site.xml mapred-queues.xml.template ssl-server.xml.example
container-executor.cfg hadoop-metrics2.properties httpfs-env.sh kms-acls.xml log4j.properties mapred-site.xml yarn-env.cmd
core-site.xml hadoop-metrics.properties httpfs-log4j.properties kms-env.sh mapred-env.cmd slaves yarn-env.sh
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$
新建目录
root@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0# mkdir -p /usr/local/hadoop/hadoop-2.6.0/dfs/name
root@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0# mkdir -p /usr/local/hadoop/hadoop-2.6.0/dfs/data
root@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0# mkdir -p /usr/local/hadoop/hadoop-2.6.0/tmp
推荐这种新建!但是得要到hadoop-2.6.0.tar.gz被解压完成,得到才做!
与
root@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0# mkdir dfs
root@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/dfs# mkdir name
root@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0/dfs# mkdir data
是一样的。

至此,hadoop的配置工作完成!
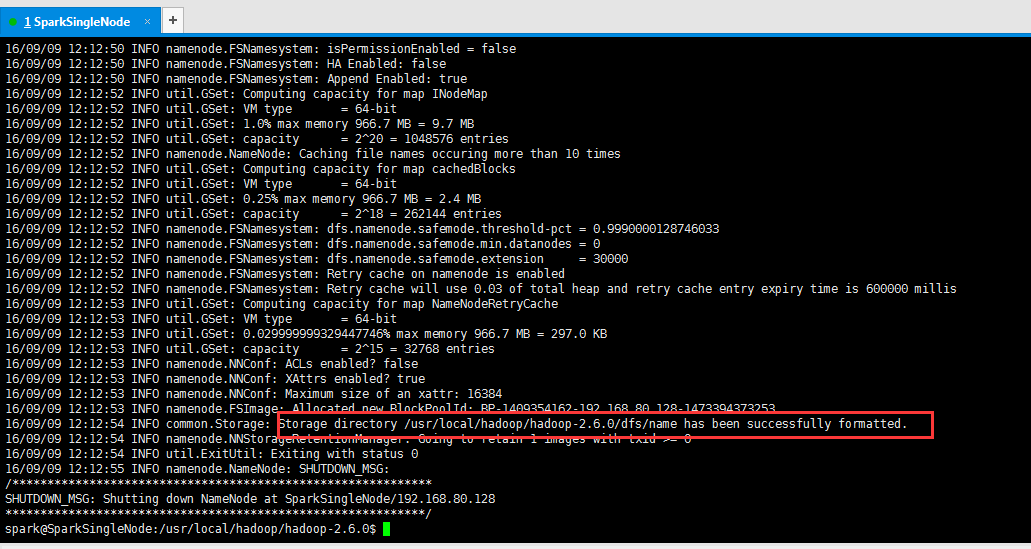
hadoop的格式化
在主节点(SparkSingleNode)的hadoop的安装目录下,进行如下命令操作
./bin/hadoop namenode -format

spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ pwd
/usr/local/hadoop/hadoop-2.6.0
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ ./bin/hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
16/09/09 12:12:41 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = SparkSingleNode/192.168.80.128
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.6.0
STARTUP_MSG: classpath = /usr/local/hadoop/hadoop-2.6.0/etc/hadoop:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-cli-1.2.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/curator-recipes-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/asm-3.2.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/httpclient-4.2.5.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-codec-1.4.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jsch-0.1.42.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-compress-1.4.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/hadoop-auth-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/htrace-core-3.0.4.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jasper-compiler-5.5.23.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/hamcrest-core-1.3.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-httpclient-3.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/gson-2.2.4.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/guava-11.0.2.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/netty-3.6.2.Final.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/curator-client-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/avro-1.7.4.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/activation-1.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jersey-json-1.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-configuration-1.6.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/xz-1.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-logging-1.1.3.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/slf4j-api-1.7.5.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/stax-api-1.0-2.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/junit-4.11.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/zookeeper-3.4.6.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/curator-framework-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-net-3.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jets3t-0.9.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-math3-3.1.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-collections-3.2.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jetty-6.1.26.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jsr305-1.3.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/servlet-api-2.5.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-el-1.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jettison-1.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-digester-1.8.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/log4j-1.2.17.jar:/usr/l
ocal/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-io-2.4.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jasper-runtime-5.5.23.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-lang-2.6.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/xmlenc-0.52.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/paranamer-2.3.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jersey-server-1.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jsp-api-2.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jersey-core-1.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/mockito-all-1.8.5.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/httpcore-4.2.5.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/hadoop-annotations-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/jetty-util-6.1.26.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/hadoop-common-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/hadoop-common-2.6.0-tests.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/hadoop-nfs-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/asm-3.2.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/htrace-core-3.0.4.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/guava-11.0.2.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/jsr305-1.3.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/commons-el-1.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/commons-io-2.4.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/jasper-runtime-5.5.23.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/jsp-api-2.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/hadoop-hdfs-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/hadoop-hdfs-nfs-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/hdfs/hadoop-hdfs-2.6.0-tests.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/commons-cli-1.2.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jersey-client-1.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/asm-3.2.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jline-0.9.94.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/commons-codec-1.4.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/commons-httpclient-3.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/guava-11.0.2.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/activation-1.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jersey-json-1.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/xz-1.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/commons-collections-3.2.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jetty-6.1.26.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jsr305-1.3.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/servlet-api-2.5.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jettison-1.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/usr/local/
hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/log4j-1.2.17.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/javax.inject-1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/commons-io-2.4.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/guice-3.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/commons-lang-2.6.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/aopalliance-1.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jersey-server-1.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jersey-core-1.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/hadoop-yarn-server-tests-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/hadoop-yarn-registry-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/hadoop-yarn-server-common-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/hadoop-yarn-api-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/hadoop-yarn-common-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/yarn/hadoop-yarn-client-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/asm-3.2.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/xz-1.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/junit-4.11.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/javax.inject-1.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/guice-3.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/lib/hadoop-annotations-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-tests.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0.jar:/usr/local/hadoop/hadoop-2.6.0/contrib/capacity-scheduler/*.jar:/usr/local/hadoop/hadoop-2.6.0/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1; compiled by 'jenkins' on 2014-11-13T21:10Z
STARTUP_MSG: java = 1.8.0_60
************************************************************/
16/09/09 12:12:41 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
16/09/09 12:12:41 INFO namenode.NameNode: createNameNode [-format]
16/09/09 12:12:48 WARN common.Util: Path /usr/local/hadoop/hadoop-2.6.0/dfs/name should be specified as a URI in configuration files. Please update hdfs configuration.
16/09/09 12:12:48 WARN common.Util: Path /usr/local/hadoop/hadoop-2.6.0/dfs/name should be specified as a URI in configuration files. Please update hdfs configuration.
Formatting using clusterid: CID-fcd6d126-a431-4df6-a9b3-f5caf6f14330
16/09/09 12:12:48 INFO namenode.FSNamesystem: No KeyProvider found.
16/09/09 12:12:49 INFO namenode.FSNamesystem: fsLock is fair:true
16/09/09 12:12:49 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
16/09/09 12:12:49 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
16/09/09 12:12:49 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
16/09/09 12:12:49 INFO blockmanagement.BlockManager: The block deletion will start around 2016 Sep 09 12:12:49
16/09/09 12:12:49 INFO util.GSet: Computing capacity for map BlocksMap
16/09/09 12:12:49 INFO util.GSet: VM type = 64-bit
16/09/09 12:12:49 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB
16/09/09 12:12:49 INFO util.GSet: capacity = 2^21 = 2097152 entries
16/09/09 12:12:49 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
16/09/09 12:12:49 INFO blockmanagement.BlockManager: defaultReplication = 1
16/09/09 12:12:49 INFO blockmanagement.BlockManager: maxReplication = 512
16/09/09 12:12:49 INFO blockmanagement.BlockManager: minReplication = 1
16/09/09 12:12:49 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
16/09/09 12:12:49 INFO blockmanagement.BlockManager: shouldCheckForEnoughRacks = false
16/09/09 12:12:49 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
16/09/09 12:12:49 INFO blockmanagement.BlockManager: encryptDataTransfer = false
16/09/09 12:12:49 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
16/09/09 12:12:50 INFO namenode.FSNamesystem: fsOwner = spark (auth:SIMPLE)
16/09/09 12:12:50 INFO namenode.FSNamesystem: supergroup = supergroup
16/09/09 12:12:50 INFO namenode.FSNamesystem: isPermissionEnabled = false
16/09/09 12:12:50 INFO namenode.FSNamesystem: HA Enabled: false
16/09/09 12:12:50 INFO namenode.FSNamesystem: Append Enabled: true
16/09/09 12:12:52 INFO util.GSet: Computing capacity for map INodeMap
16/09/09 12:12:52 INFO util.GSet: VM type = 64-bit
16/09/09 12:12:52 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB
16/09/09 12:12:52 INFO util.GSet: capacity = 2^20 = 1048576 entries
16/09/09 12:12:52 INFO namenode.NameNode: Caching file names occuring more than 10 times
16/09/09 12:12:52 INFO util.GSet: Computing capacity for map cachedBlocks
16/09/09 12:12:52 INFO util.GSet: VM type = 64-bit
16/09/09 12:12:52 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB
16/09/09 12:12:52 INFO util.GSet: capacity = 2^18 = 262144 entries
16/09/09 12:12:52 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
16/09/09 12:12:52 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
16/09/09 12:12:52 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
16/09/09 12:12:52 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
16/09/09 12:12:52 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
16/09/09 12:12:53 INFO util.GSet: Computing capacity for map NameNodeRetryCache
16/09/09 12:12:53 INFO util.GSet: VM type = 64-bit
16/09/09 12:12:53 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
16/09/09 12:12:53 INFO util.GSet: capacity = 2^15 = 32768 entries
16/09/09 12:12:53 INFO namenode.NNConf: ACLs enabled? false
16/09/09 12:12:53 INFO namenode.NNConf: XAttrs enabled? true
16/09/09 12:12:53 INFO namenode.NNConf: Maximum size of an xattr: 16384
16/09/09 12:12:53 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1409354162-192.168.80.128-1473394373253
16/09/09 12:12:54 INFO common.Storage: Storage directory /usr/local/hadoop/hadoop-2.6.0/dfs/name has been successfully formatted.
16/09/09 12:12:54 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
16/09/09 12:12:54 INFO util.ExitUtil: Exiting with status 0
16/09/09 12:12:55 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at SparkSingleNode/192.168.80.128
************************************************************/
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$
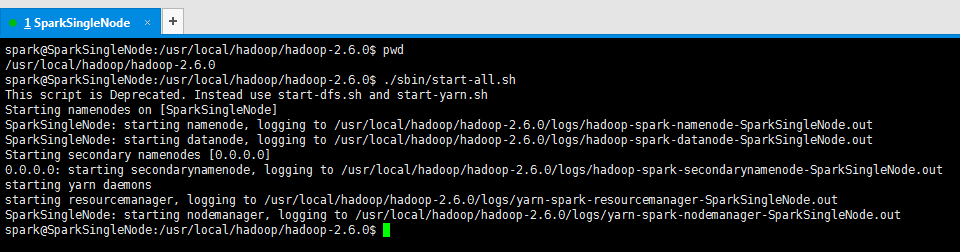
启动hadoop
./sbin/start-all.sh
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ pwd
/usr/local/hadoop/hadoop-2.6.0
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ ./sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [SparkSingleNode]
SparkSingleNode: starting namenode, logging to /usr/local/hadoop/hadoop-2.6.0/logs/hadoop-spark-namenode-SparkSingleNode.out
SparkSingleNode: starting datanode, logging to /usr/local/hadoop/hadoop-2.6.0/logs/hadoop-spark-datanode-SparkSingleNode.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/hadoop-2.6.0/logs/hadoop-spark-secondarynamenode-SparkSingleNode.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/hadoop-2.6.0/logs/yarn-spark-resourcemanager-SparkSingleNode.out
SparkSingleNode: starting nodemanager, logging to /usr/local/hadoop/hadoop-2.6.0/logs/yarn-spark-nodemanager-SparkSingleNode.out
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ jps

spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ jps
4787 DataNode
4679 NameNode
5610 Jps
5132 ResourceManager
5245 NodeManager
4959 SecondaryNameNode
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$



五、安装spark
spark-1.5.2-bin-hadoop2.6.tgz ---------------------------------------------- /usr/loca/spark/spark-1.5.2-bin-hadoop2.6
1、spark的下载
http://mirror.bit.edu.cn/apache/spark/spark-1.5.2/
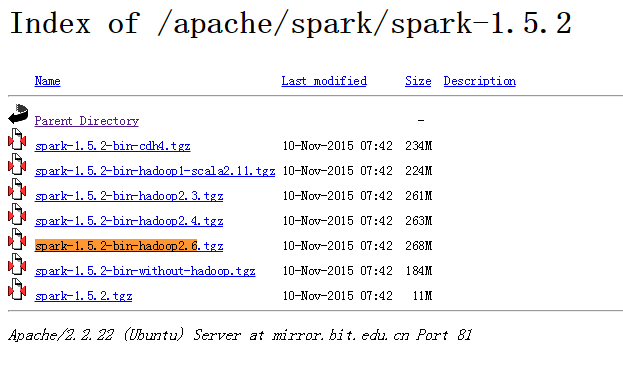
2、spark-1.5.2-bin-hadoop2.6.tgz的上传

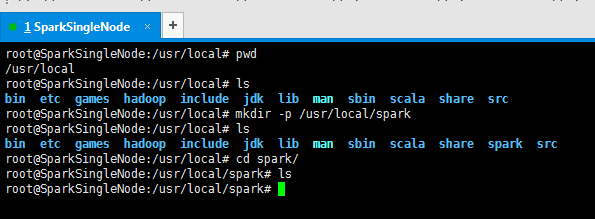
3、现在,新建/usr/local下的spark目录
root@SparkSingleNode:/usr/local# pwd
/usr/local
root@SparkSingleNode:/usr/local# ls
bin etc games hadoop include jdk lib man sbin scala share src
root@SparkSingleNode:/usr/local# mkdir -p /usr/local/spark
root@SparkSingleNode:/usr/local# ls
bin etc games hadoop include jdk lib man sbin scala share spark src
root@SparkSingleNode:/usr/local# cd spark/
root@SparkSingleNode:/usr/local/spark# ls
root@SparkSingleNode:/usr/local/spark#
4、将下载的spark文件移到刚刚创建的/usr/local/spark下

最好用cp,不要轻易要mv
root@SparkSingleNode:/usr/local/spark# pwd
/usr/local/spark
root@SparkSingleNode:/usr/local/spark# sudo cp /home/spark/Downloads/Spark_Cluster_Software/spark-1.5.2-bin-hadoop2.6.tgz /usr/local/spark/
root@SparkSingleNode:/usr/local/spark# ls
spark-1.5.2-bin-hadoop2.6.tgz
root@SparkSingleNode:/usr/local/spark#
5、解压spark文件

root@SparkSingleNode:/usr/local/spark# ls
spark-1.5.2-bin-hadoop2.6.tgz
root@SparkSingleNode:/usr/local/spark# tar -zxvf spark-1.5.2-bin-hadoop2.6.tgz
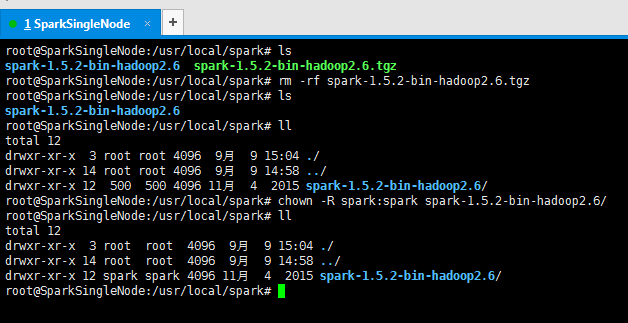
6、删除解压包,留下解压完成的文件目录
并修改所属的用户组和用户(这是最重要的!)
root@SparkSingleNode:/usr/local/spark# ls
spark-1.5.2-bin-hadoop2.6 spark-1.5.2-bin-hadoop2.6.tgz
root@SparkSingleNode:/usr/local/spark# rm -rf spark-1.5.2-bin-hadoop2.6.tgz
root@SparkSingleNode:/usr/local/spark# ls
spark-1.5.2-bin-hadoop2.6
root@SparkSingleNode:/usr/local/spark# ll
total 12
drwxr-xr-x 3 root root 4096 9月 9 15:04 ./
drwxr-xr-x 14 root root 4096 9月 9 14:58 ../
drwxr-xr-x 12 500 500 4096 11月 4 2015 spark-1.5.2-bin-hadoop2.6/
root@SparkSingleNode:/usr/local/spark# chown -R spark:spark spark-1.5.2-bin-hadoop2.6/
root@SparkSingleNode:/usr/local/spark# ll
total 12
drwxr-xr-x 3 root root 4096 9月 9 15:04 ./
drwxr-xr-x 14 root root 4096 9月 9 14:58 ../
drwxr-xr-x 12 spark spark 4096 11月 4 2015 spark-1.5.2-bin-hadoop2.6/
root@SparkSingleNode:/usr/local/spark#
7、修改环境变量
vim ~./bash_profile 或 vim /etc/profile
配置在这个文件~/.bash_profile,或者也可以,配置在那个全局的文件里,也可以哟。/etc/profile。
这里,我vim /etc/profile
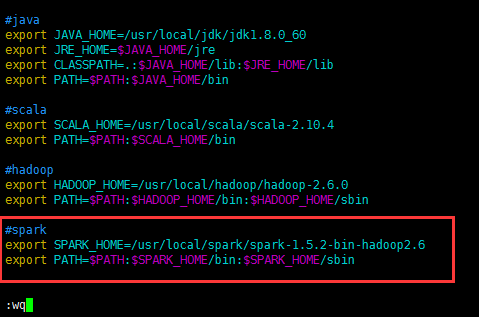
#spark
export SPARK_HOME=/usr/local/spark/spark-1.5.2-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin

root@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6# vim /etc/profile
root@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6# source /etc/profile
root@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6#
至此,表明spark安装结束。
其他两台机器都照做!
配置spark的配置文件
经验起见,一般都是在NotePad++里,弄好,丢上去

 变成
变成 
#!/usr/bin/env bash
# This file is sourced when running various Spark programs.
# Copy it as spark-env.sh and edit that to configure Spark for your site.
# Options read when launching programs locally with
# ./bin/run-example or ./bin/spark-submit
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public dns name of the driver program
# - SPARK_CLASSPATH, default classpath entries to append
# Options read by executors and drivers running inside the cluster
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public DNS name of the driver program
# - SPARK_CLASSPATH, default classpath entries to append
# - SPARK_LOCAL_DIRS, storage directories to use on this node for shuffle and RDD data
# - MESOS_NATIVE_JAVA_LIBRARY, to point to your libmesos.so if you use Mesos
# Options read in YARN client mode
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - SPARK_EXECUTOR_INSTANCES, Number of workers to start (Default: 2)
# - SPARK_EXECUTOR_CORES, Number of cores for the workers (Default: 1).
# - SPARK_EXECUTOR_MEMORY, Memory per Worker (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_DRIVER_MEMORY, Memory for Master (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_YARN_APP_NAME, The name of your application (Default: Spark)
# - SPARK_YARN_QUEUE, The hadoop queue to use for allocation requests (Default: ‘default’)
# - SPARK_YARN_DIST_FILES, Comma separated list of files to be distributed with the job.
# - SPARK_YARN_DIST_ARCHIVES, Comma separated list of archives to be distributed with the job.
# Options for the daemons used in the standalone deploy mode
# - SPARK_MASTER_IP, to bind the master to a different IP address or hostname
# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master
# - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y")
# - SPARK_WORKER_CORES, to set the number of cores to use on this machine
# - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)
# - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker
# - SPARK_WORKER_INSTANCES, to set the number of worker processes per node
# - SPARK_WORKER_DIR, to set the working directory of worker processes
# - SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. "-Dx=y")
# - SPARK_DAEMON_MEMORY, to allocate to the master, worker and history server themselves (default: 1g).
# - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y")
# - SPARK_SHUFFLE_OPTS, to set config properties only for the external shuffle service (e.g. "-Dx=y")
# - SPARK_DAEMON_JAVA_OPTS, to set config properties for all daemons (e.g. "-Dx=y")
# - SPARK_PUBLIC_DNS, to set the public dns name of the master or workers
# Generic options for the daemons used in the standalone deploy mode
# - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs)
# - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp)
# - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER)
# - SPARK_NICENESS The scheduling priority for daemons. (Default: 0)
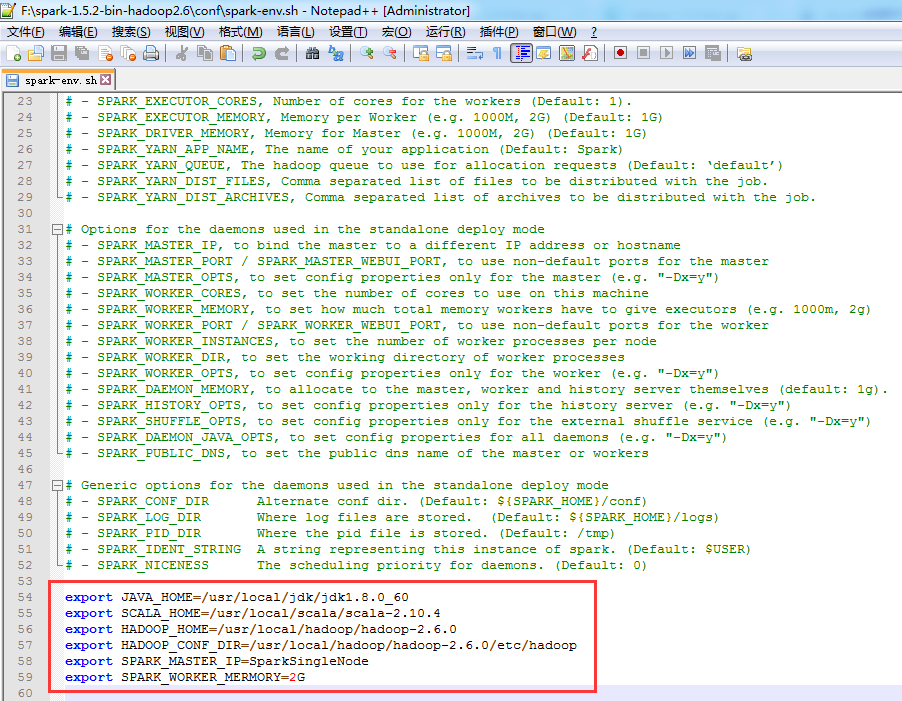
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60
export SCALA_HOME=/usr/local/scala/scala-2.10.4
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.6.0/etc/hadoop
export SPARK_MASTER_IP=SparkSingleNode
export SPARK_WORKER_MERMORY=2G (官网上说,至少是1g起步)
这里啊,我考虑在单节点里,玩玩spark,作为学习的入门。设为2G。当然,这个值,日后也可以更改,比如,变大到4G都可以的。
从节点
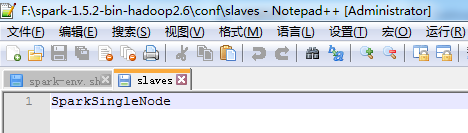
SparkSingleNode
将SparkSingleNode的各自原有配置这几个文件,删去
在这里,最好是复制,因为权限。

spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ pwd
/usr/local/spark/spark-1.5.2-bin-hadoop2.6
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ ls
bin CHANGES.txt conf data ec2 examples lib LICENSE licenses NOTICE python R README.md RELEASE sbin
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ cd conf/
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ ls
docker.properties.template fairscheduler.xml.template log4j.properties.template metrics.properties.template slaves.template spark-defaults.conf.template spark-env.sh.template
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ ll
total 40
drwxr-xr-x 2 spark spark 4096 11月 4 2015 ./
drwxr-xr-x 12 spark spark 4096 11月 4 2015 ../
-rw-r--r-- 1 spark spark 202 11月 4 2015 docker.properties.template
-rw-r--r-- 1 spark spark 303 11月 4 2015 fairscheduler.xml.template
-rw-r--r-- 1 spark spark 949 11月 4 2015 log4j.properties.template
-rw-r--r-- 1 spark spark 5886 11月 4 2015 metrics.properties.template
-rw-r--r-- 1 spark spark 80 11月 4 2015 slaves.template
-rw-r--r-- 1 spark spark 507 11月 4 2015 spark-defaults.conf.template
-rwxr-xr-x 1 spark spark 3418 11月 4 2015 spark-env.sh.template*
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$

spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ ls
docker.properties.template fairscheduler.xml.template log4j.properties.template metrics.properties.template slaves.template spark-defaults.conf.template spark-env.sh.template
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ cp spark-env.sh.template spark-env.sh
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ ls
docker.properties.template log4j.properties.template slaves.template spark-env.sh
fairscheduler.xml.template metrics.properties.template spark-defaults.conf.template spark-env.sh.template
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ ll
total 44
drwxr-xr-x 2 spark spark 4096 9月 9 15:22 ./
drwxr-xr-x 12 spark spark 4096 11月 4 2015 ../
-rw-r--r-- 1 spark spark 202 11月 4 2015 docker.properties.template
-rw-r--r-- 1 spark spark 303 11月 4 2015 fairscheduler.xml.template
-rw-r--r-- 1 spark spark 949 11月 4 2015 log4j.properties.template
-rw-r--r-- 1 spark spark 5886 11月 4 2015 metrics.properties.template
-rw-r--r-- 1 spark spark 80 11月 4 2015 slaves.template
-rw-r--r-- 1 spark spark 507 11月 4 2015 spark-defaults.conf.template
-rwxr-xr-x 1 spark spark 3418 9月 9 15:22 spark-env.sh*
-rwxr-xr-x 1 spark spark 3418 11月 4 2015 spark-env.sh.template*
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ rm -rf spark-env.sh.template
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ ls
docker.properties.template fairscheduler.xml.template log4j.properties.template metrics.properties.template slaves.template spark-defaults.conf.template spark-env.sh
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ vim spark-env.sh
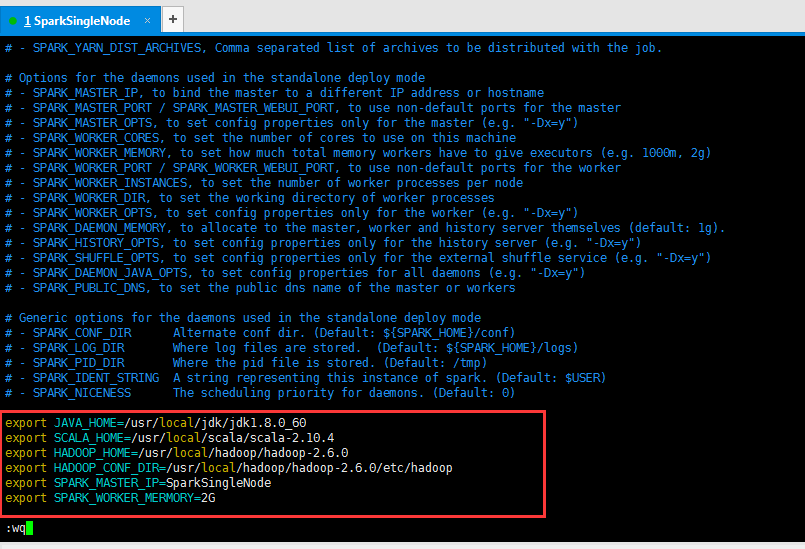
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60
export SCALA_HOME=/usr/local/scala/scala-2.10.4
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.6.0/etc/hadoop
export SPARK_MASTER_IP=SparkSingleNode
export SPARK_WORKER_MERMORY=2G (官网上说,至少是1g起步)
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ ls
docker.properties.template fairscheduler.xml.template log4j.properties.template metrics.properties.template slaves.template spark-defaults.conf.template spark-env.sh
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ cp slaves.template slaves
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ ll
total 44
drwxr-xr-x 2 spark spark 4096 9月 9 15:25 ./
drwxr-xr-x 12 spark spark 4096 11月 4 2015 ../
-rw-r--r-- 1 spark spark 202 11月 4 2015 docker.properties.template
-rw-r--r-- 1 spark spark 303 11月 4 2015 fairscheduler.xml.template
-rw-r--r-- 1 spark spark 949 11月 4 2015 log4j.properties.template
-rw-r--r-- 1 spark spark 5886 11月 4 2015 metrics.properties.template
-rw-r--r-- 1 spark spark 80 9月 9 15:25 slaves
-rw-r--r-- 1 spark spark 80 11月 4 2015 slaves.template
-rw-r--r-- 1 spark spark 507 11月 4 2015 spark-defaults.conf.template
-rwxr-xr-x 1 spark spark 3697 9月 9 15:25 spark-env.sh*
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ rm -rf slaves.template
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ ls
docker.properties.template fairscheduler.xml.template log4j.properties.template metrics.properties.template slaves spark-defaults.conf.template spark-env.sh
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ vim slaves
# A Spark Worker will be started on each of the machines listed below.
SparkSingleNode
至此,spark的配置工作完成!

七、启动集群
1、在haoop的安装目录下,启动hadoop集群。
/usr/local/hadoop/hadoop-2.6.0下,执行./sbin/start-all.sh
或,在任何路径下,$HADOOP_HOME/sbin/start-all.sh
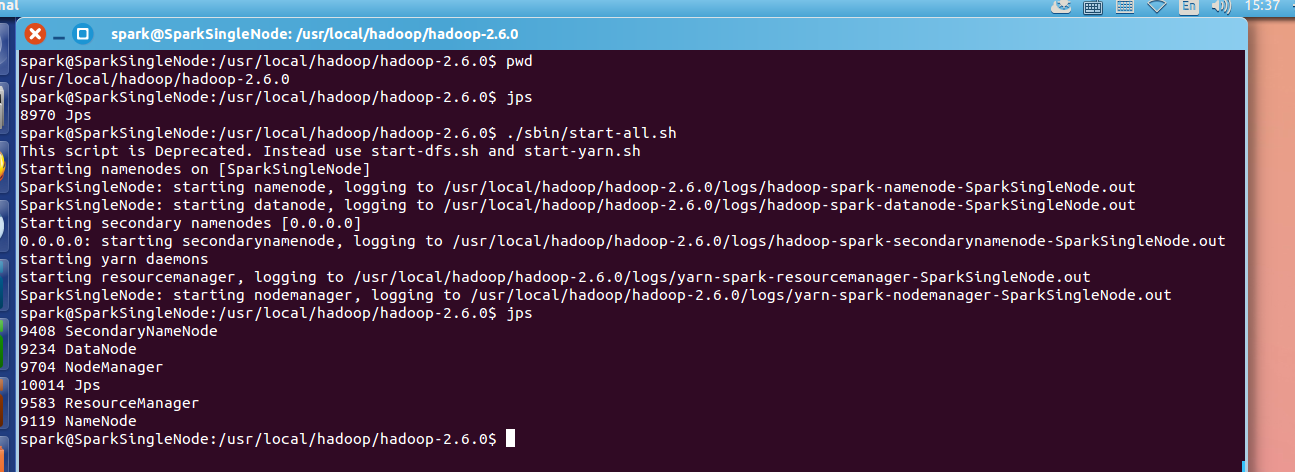
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ pwd
/usr/local/hadoop/hadoop-2.6.0
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ jps
8970 Jps
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ ./sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [SparkSingleNode]
SparkSingleNode: starting namenode, logging to /usr/local/hadoop/hadoop-2.6.0/logs/hadoop-spark-namenode-SparkSingleNode.out
SparkSingleNode: starting datanode, logging to /usr/local/hadoop/hadoop-2.6.0/logs/hadoop-spark-datanode-SparkSingleNode.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/hadoop-2.6.0/logs/hadoop-spark-secondarynamenode-SparkSingleNode.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/hadoop-2.6.0/logs/yarn-spark-resourcemanager-SparkSingleNode.out
SparkSingleNode: starting nodemanager, logging to /usr/local/hadoop/hadoop-2.6.0/logs/yarn-spark-nodemanager-SparkSingleNode.out
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ jps
9408 SecondaryNameNode
9234 DataNode
9704 NodeManager
10014 Jps
9583 ResourceManager
9119 NameNode
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$
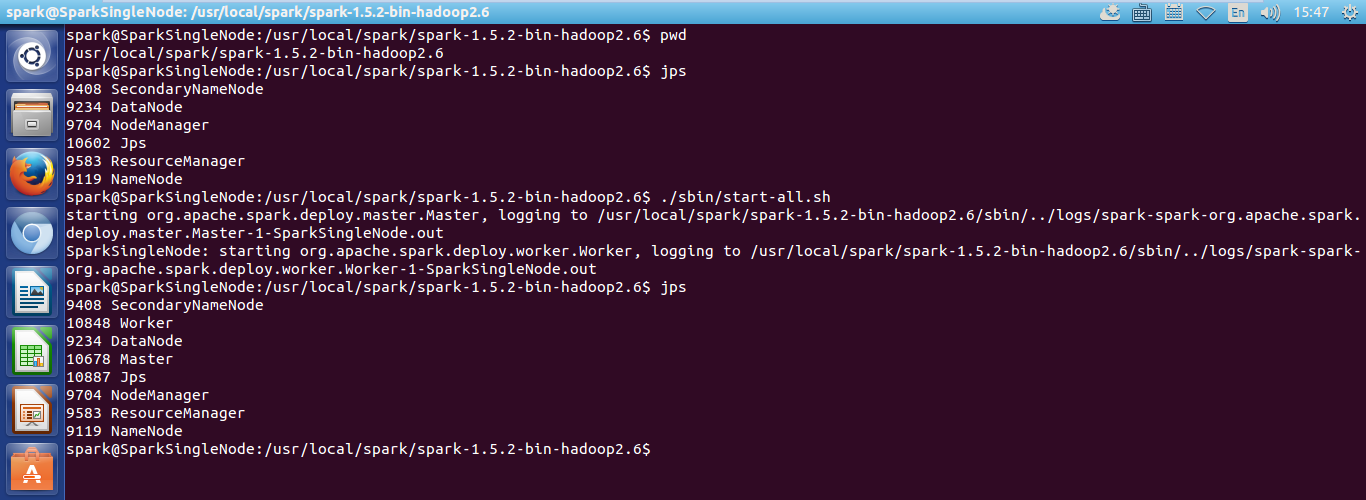
2、在spark的安装目录下,启动spark集群。
/usr/local/spark/spark-1.5.2-bin-hadoop2.6下,执行./sbin/start-all.sh
或, 在任何路径下,执行 $SPARK_HOME/sbin/start-all.sh
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ pwd
/usr/local/spark/spark-1.5.2-bin-hadoop2.6
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ jps
9408 SecondaryNameNode
9234 DataNode
9704 NodeManager
10602 Jps
9583 ResourceManager
9119 NameNode
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ ./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/spark-1.5.2-bin-hadoop2.6/sbin/../logs/spark-spark-org.apache.spark.deploy.master.Master-1-SparkSingleNode.out
SparkSingleNode: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/spark-1.5.2-bin-hadoop2.6/sbin/../logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-SparkSingleNode.out
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ jps
9408 SecondaryNameNode
10848 Worker
9234 DataNode
10678 Master
10887 Jps
9704 NodeManager
9583 ResourceManager
9119 NameNode
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$
由此,可见,hadoop的启动、spark的启动都正常!
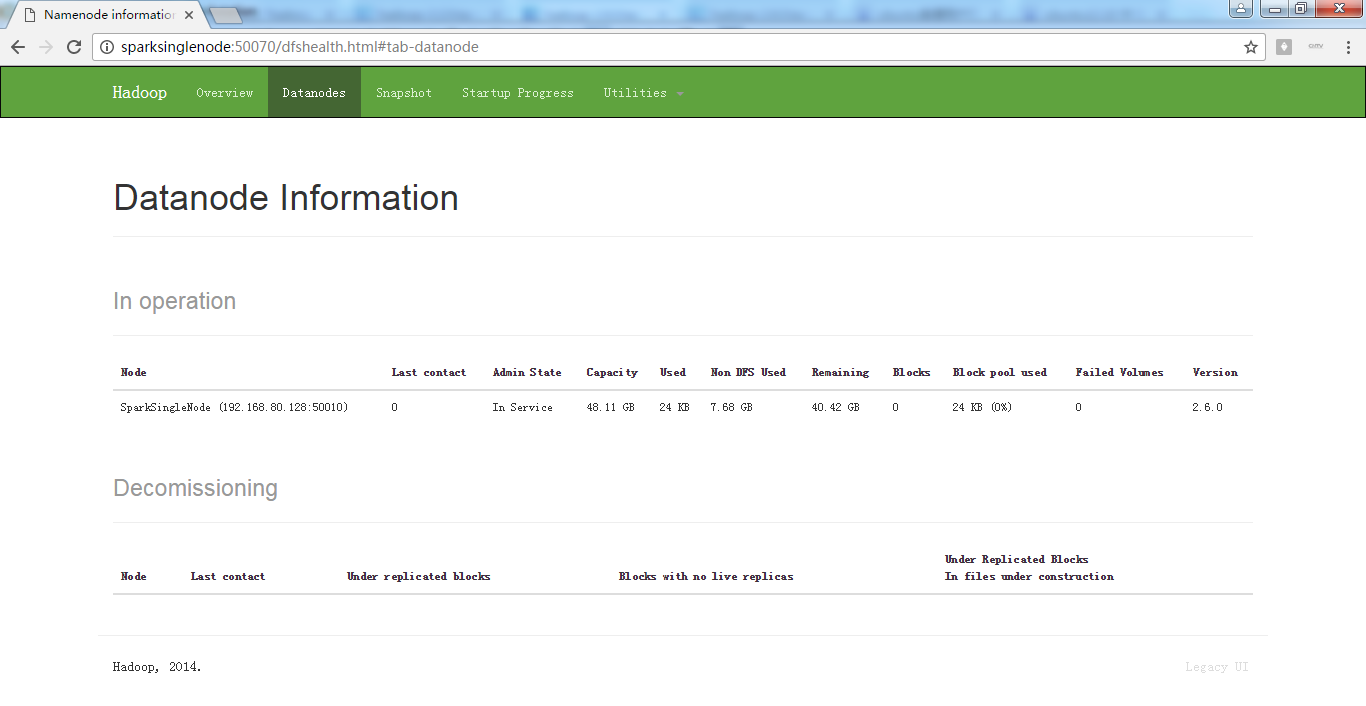
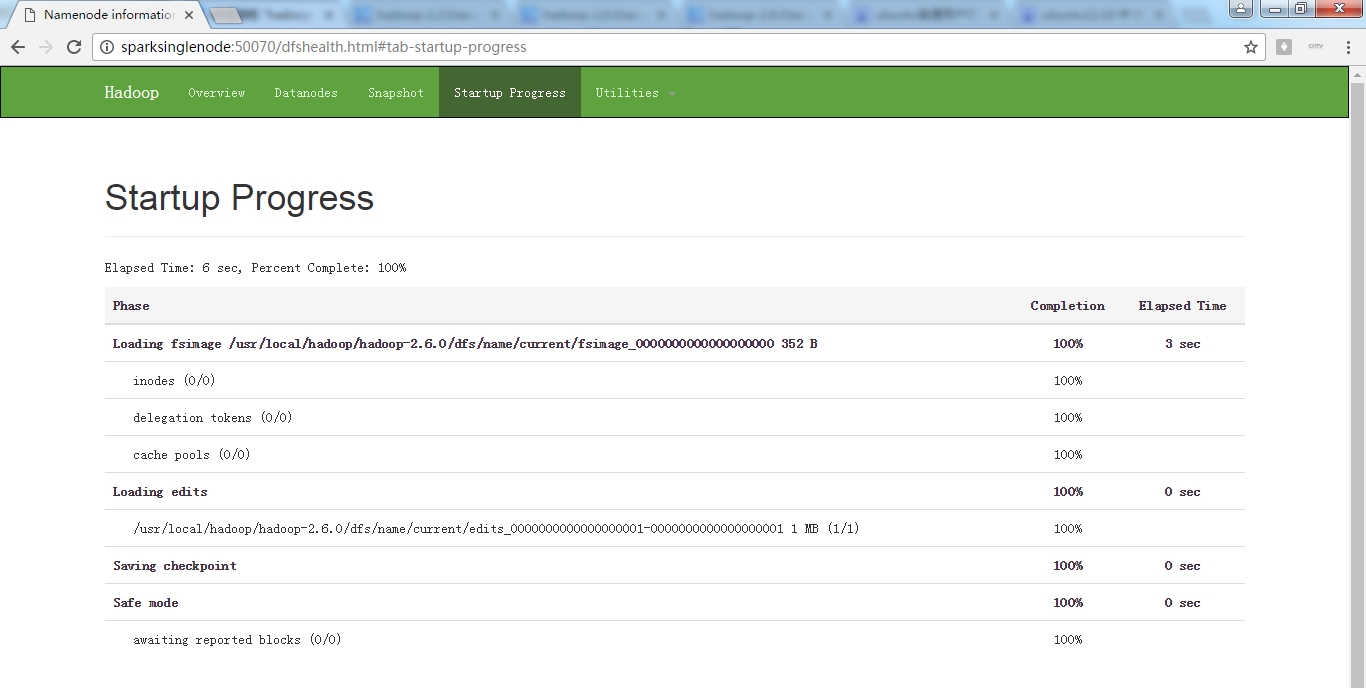
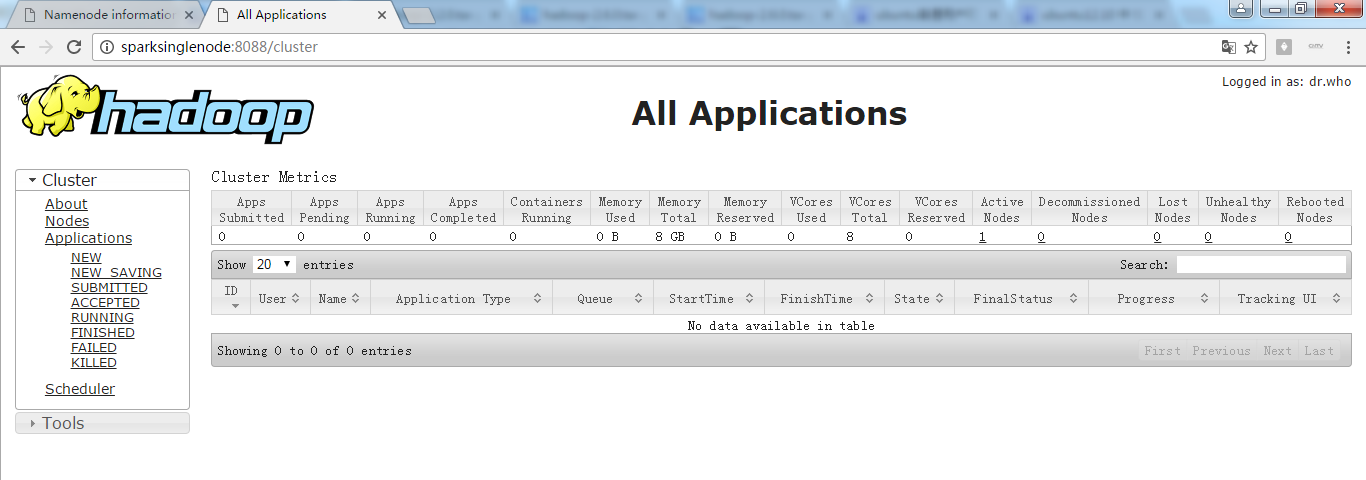
八、查看页面
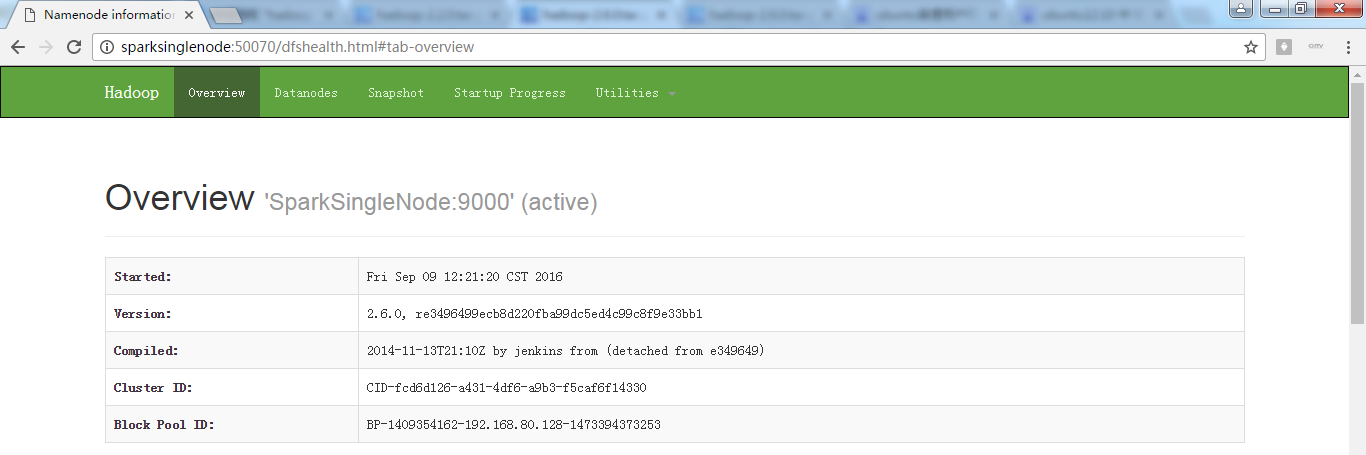
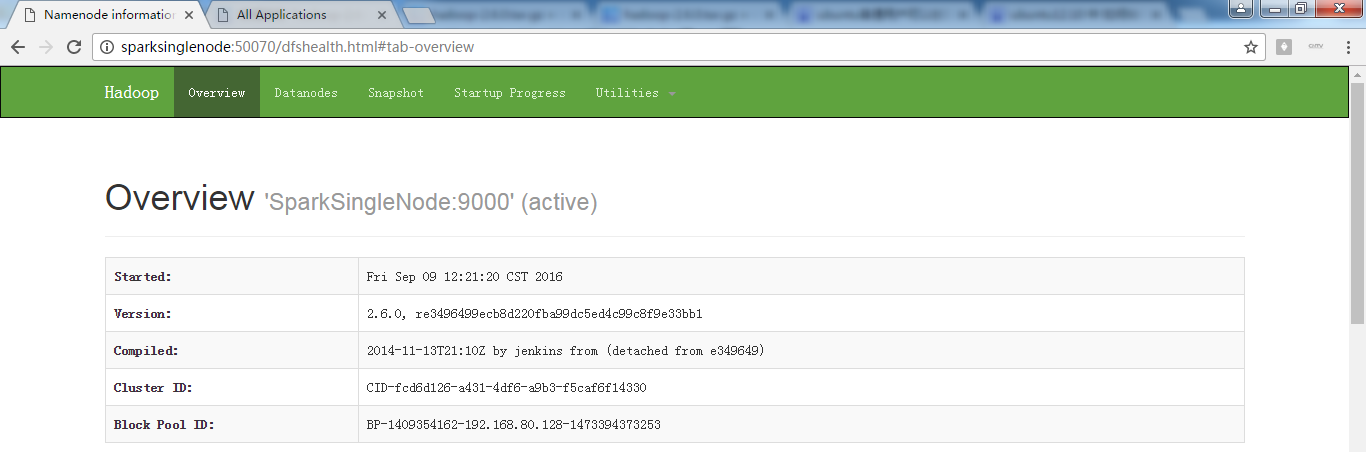
进入hadoop的hdfs的web页面。访问http://SparkSingleNode:50070 (安装之后,立即可以看到)
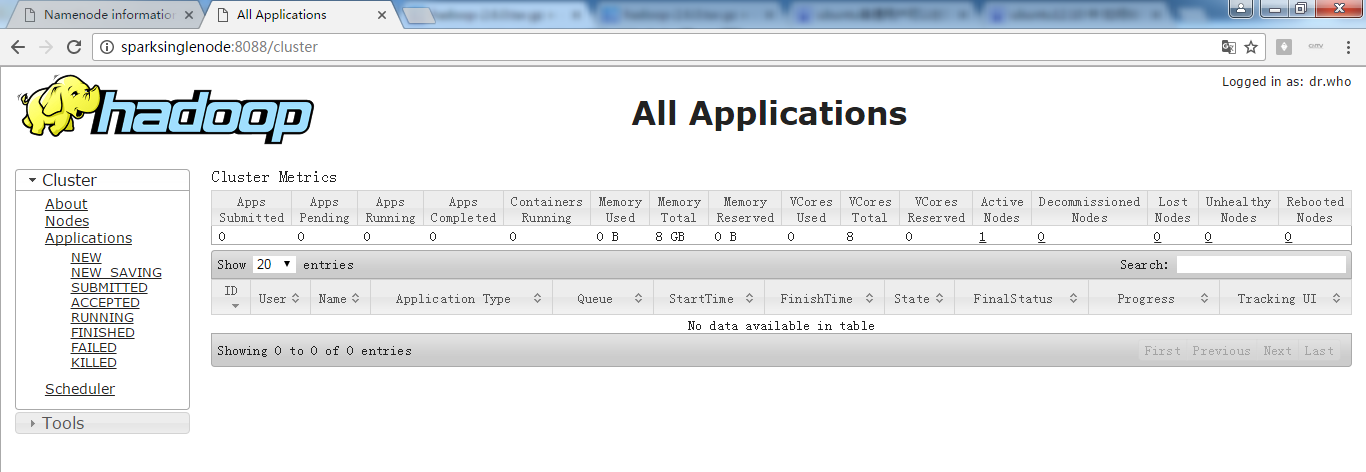
进入hadoop的yarn的web页面。访问http://SparkSingleNode:8088 (安装之后,立即可以看到)
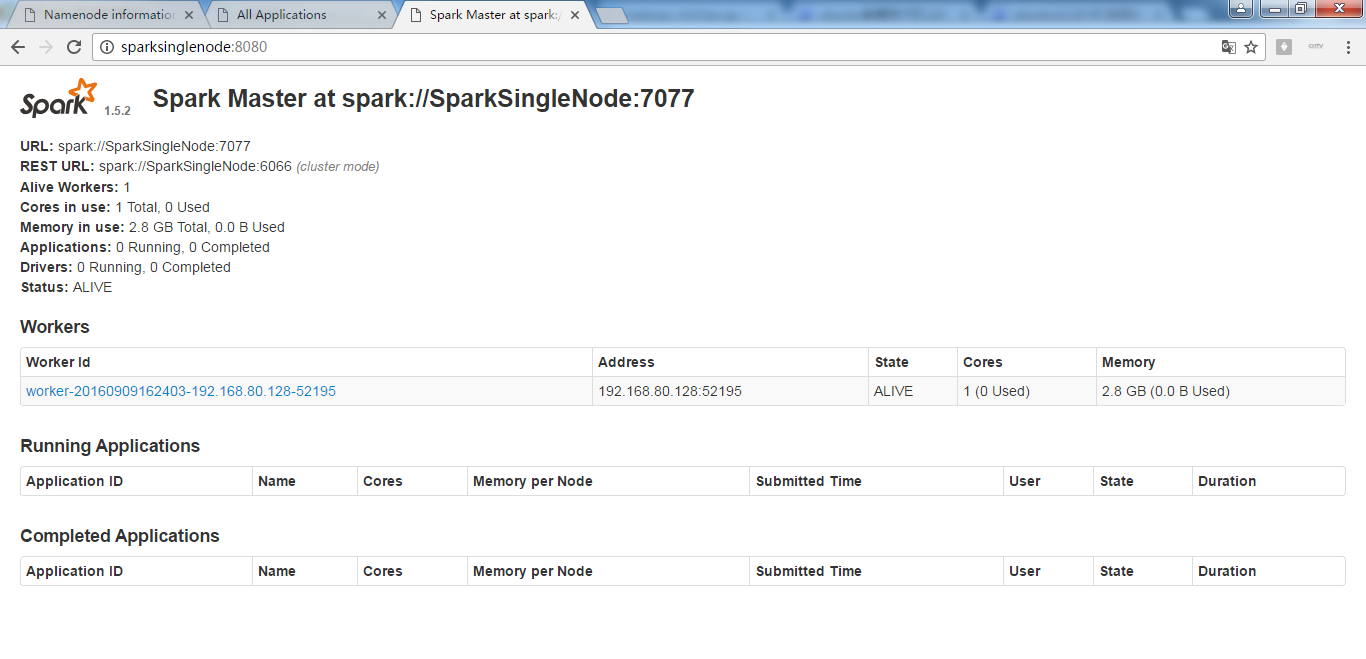
进入spark的web页面。访问 http://SparkSingleNode:8080 (安装之后,立即可以看到)
进入spark的shell的web页面。访问http//:SparkSingleNode:4040 (需开启spark shell)
我们也可以进入scala状态下的spark
在spark的安装目录下,执行./bin/spark-shell 注意,没空格
或者,在任何路径下,执行 $SPARK_HOME/bin/spark-shell --SparkSingleNode spark://SparkSingleNode:7077 注意,$SPARK_HOME,没空格
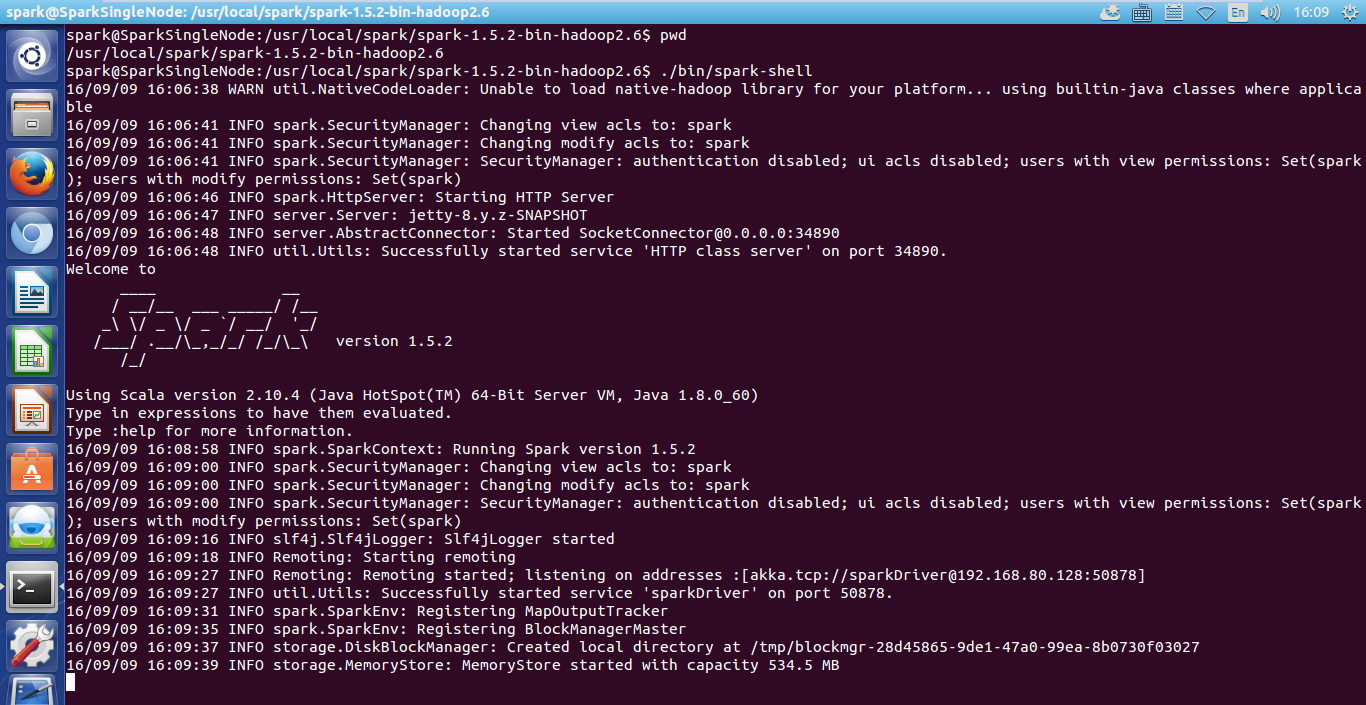
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ ./bin/spark-shell
16/09/09 16:26:07 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/09/09 16:26:09 INFO spark.SecurityManager: Changing view acls to: spark
16/09/09 16:26:09 INFO spark.SecurityManager: Changing modify acls to: spark
16/09/09 16:26:09 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); users with modify permissions: Set(spark)
16/09/09 16:26:10 INFO spark.HttpServer: Starting HTTP Server
16/09/09 16:26:11 INFO server.Server: jetty-8.y.z-SNAPSHOT
16/09/09 16:26:11 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:41641
16/09/09 16:26:11 INFO util.Utils: Successfully started service 'HTTP class server' on port 41641.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.5.2
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_60)
Type in expressions to have them evaluated.
Type :help for more information.
16/09/09 16:26:45 INFO spark.SparkContext: Running Spark version 1.5.2
16/09/09 16:26:46 INFO spark.SecurityManager: Changing view acls to: spark
16/09/09 16:26:46 INFO spark.SecurityManager: Changing modify acls to: spark
16/09/09 16:26:46 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); users with modify permissions: Set(spark)
16/09/09 16:26:49 INFO slf4j.Slf4jLogger: Slf4jLogger started
16/09/09 16:26:50 INFO Remoting: Starting remoting
16/09/09 16:26:52 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@192.168.80.128:44949]
16/09/09 16:26:52 INFO util.Utils: Successfully started service 'sparkDriver' on port 44949.
16/09/09 16:26:52 INFO spark.SparkEnv: Registering MapOutputTracker
16/09/09 16:26:52 INFO spark.SparkEnv: Registering BlockManagerMaster
16/09/09 16:26:53 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-8615ba01-4240-4c41-b85d-ca901305577b
16/09/09 16:26:53 INFO storage.MemoryStore: MemoryStore started with capacity 534.5 MB
16/09/09 16:26:54 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-ee23c689-2009-455d-ba60-995a42ef529a/httpd-13fe8fa0-3850-48d9-88ba-c78bb78edd91
16/09/09 16:26:54 INFO spark.HttpServer: Starting HTTP Server
16/09/09 16:26:54 INFO server.Server: jetty-8.y.z-SNAPSHOT
16/09/09 16:26:54 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:33301
16/09/09 16:26:54 INFO util.Utils: Successfully started service 'HTTP file server' on port 33301.
16/09/09 16:26:54 INFO spark.SparkEnv: Registering OutputCommitCoordinator
16/09/09 16:27:00 INFO server.Server: jetty-8.y.z-SNAPSHOT
16/09/09 16:27:00 INFO server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:4040
16/09/09 16:27:00 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
16/09/09 16:27:00 INFO ui.SparkUI: Started SparkUI at http://192.168.80.128:4040
16/09/09 16:27:02 WARN metrics.MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
16/09/09 16:27:02 INFO executor.Executor: Starting executor ID driver on host localhost
16/09/09 16:27:02 INFO executor.Executor: Using REPL class URI: http://192.168.80.128:41641
16/09/09 16:27:03 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 39805.
16/09/09 16:27:03 INFO netty.NettyBlockTransferService: Server created on 39805
16/09/09 16:27:03 INFO storage.BlockManagerMaster: Trying to register BlockManager
16/09/09 16:27:03 INFO storage.BlockManagerMasterEndpoint: Registering block manager localhost:39805 with 534.5 MB RAM, BlockManagerId(driver, localhost, 39805)
16/09/09 16:27:04 INFO storage.BlockManagerMaster: Registered BlockManager
16/09/09 16:27:05 INFO repl.SparkILoop: Created spark context..
Spark context available as sc.
16/09/09 16:27:10 INFO hive.HiveContext: Initializing execution hive, version 1.2.1
16/09/09 16:27:13 INFO client.ClientWrapper: Inspected Hadoop version: 2.6.0
16/09/09 16:27:13 INFO client.ClientWrapper: Loaded org.apache.hadoop.hive.shims.Hadoop23Shims for Hadoop version 2.6.0
16/09/09 16:27:17 INFO metastore.HiveMetaStore: 0: Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore
16/09/09 16:27:17 INFO metastore.ObjectStore: ObjectStore, initialize called
16/09/09 16:27:19 INFO DataNucleus.Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored
16/09/09 16:27:19 INFO DataNucleus.Persistence: Property datanucleus.cache.level2 unknown - will be ignored
16/09/09 16:27:21 WARN DataNucleus.Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
16/09/09 16:27:23 WARN DataNucleus.Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
16/09/09 16:27:35 INFO metastore.ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"
16/09/09 16:27:43 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
16/09/09 16:27:43 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
16/09/09 16:27:55 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
16/09/09 16:27:55 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
16/09/09 16:27:57 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is DERBY
16/09/09 16:27:57 INFO metastore.ObjectStore: Initialized ObjectStore
16/09/09 16:27:58 WARN metastore.ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
16/09/09 16:27:59 WARN metastore.ObjectStore: Failed to get database default, returning NoSuchObjectException
16/09/09 16:28:01 INFO metastore.HiveMetaStore: Added admin role in metastore
16/09/09 16:28:01 INFO metastore.HiveMetaStore: Added public role in metastore
16/09/09 16:28:02 INFO metastore.HiveMetaStore: No user is added in admin role, since config is empty
16/09/09 16:28:03 INFO metastore.HiveMetaStore: 0: get_all_databases
16/09/09 16:28:03 INFO HiveMetaStore.audit: ugi=spark ip=unknown-ip-addr cmd=get_all_databases
16/09/09 16:28:04 INFO metastore.HiveMetaStore: 0: get_functions: db=default pat=*
16/09/09 16:28:04 INFO HiveMetaStore.audit: ugi=spark ip=unknown-ip-addr cmd=get_functions: db=default pat=*
16/09/09 16:28:04 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MResourceUri" is tagged as "embedded-only" so does not have its own datastore table.
16/09/09 16:28:10 INFO session.SessionState: Created HDFS directory: /tmp/hive/spark
16/09/09 16:28:10 INFO session.SessionState: Created local directory: /tmp/spark
16/09/09 16:28:10 INFO session.SessionState: Created local directory: /tmp/2f4fd719-b203-418d-b492-8ed62d08a122_resources
16/09/09 16:28:11 INFO session.SessionState: Created HDFS directory: /tmp/hive/spark/2f4fd719-b203-418d-b492-8ed62d08a122
16/09/09 16:28:11 INFO session.SessionState: Created local directory: /tmp/spark/2f4fd719-b203-418d-b492-8ed62d08a122
16/09/09 16:28:11 INFO session.SessionState: Created HDFS directory: /tmp/hive/spark/2f4fd719-b203-418d-b492-8ed62d08a122/_tmp_space.db
16/09/09 16:28:11 INFO hive.HiveContext: default warehouse location is /user/hive/warehouse
16/09/09 16:28:11 INFO hive.HiveContext: Initializing HiveMetastoreConnection version 1.2.1 using Spark classes.
16/09/09 16:28:12 INFO client.ClientWrapper: Inspected Hadoop version: 2.6.0
16/09/09 16:28:12 INFO client.ClientWrapper: Loaded org.apache.hadoop.hive.shims.Hadoop23Shims for Hadoop version 2.6.0
16/09/09 16:28:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/09/09 16:28:15 INFO metastore.HiveMetaStore: 0: Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore
16/09/09 16:28:16 INFO metastore.ObjectStore: ObjectStore, initialize called
16/09/09 16:28:16 INFO DataNucleus.Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored
16/09/09 16:28:16 INFO DataNucleus.Persistence: Property datanucleus.cache.level2 unknown - will be ignored
16/09/09 16:28:16 WARN DataNucleus.Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
16/09/09 16:28:18 WARN DataNucleus.Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
16/09/09 16:28:27 INFO metastore.ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"
16/09/09 16:28:31 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
16/09/09 16:28:31 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
16/09/09 16:28:40 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
16/09/09 16:28:40 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
16/09/09 16:28:41 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is DERBY
16/09/09 16:28:42 INFO metastore.ObjectStore: Initialized ObjectStore
16/09/09 16:28:42 WARN metastore.ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
16/09/09 16:28:43 WARN metastore.ObjectStore: Failed to get database default, returning NoSuchObjectException
16/09/09 16:28:45 INFO metastore.HiveMetaStore: Added admin role in metastore
16/09/09 16:28:45 INFO metastore.HiveMetaStore: Added public role in metastore
16/09/09 16:28:45 INFO metastore.HiveMetaStore: No user is added in admin role, since config is empty
16/09/09 16:28:46 INFO metastore.HiveMetaStore: 0: get_all_databases
16/09/09 16:28:46 INFO HiveMetaStore.audit: ugi=spark ip=unknown-ip-addr cmd=get_all_databases
16/09/09 16:28:46 INFO metastore.HiveMetaStore: 0: get_functions: db=default pat=*
16/09/09 16:28:46 INFO HiveMetaStore.audit: ugi=spark ip=unknown-ip-addr cmd=get_functions: db=default pat=*
16/09/09 16:28:46 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MResourceUri" is tagged as "embedded-only" so does not have its own datastore table.
16/09/09 16:28:47 INFO session.SessionState: Created local directory: /tmp/64b097c1-1ac3-4f8b-94e5-6ce45fadf854_resources
16/09/09 16:28:47 INFO session.SessionState: Created HDFS directory: /tmp/hive/spark/64b097c1-1ac3-4f8b-94e5-6ce45fadf854
16/09/09 16:28:47 INFO session.SessionState: Created local directory: /tmp/spark/64b097c1-1ac3-4f8b-94e5-6ce45fadf854
16/09/09 16:28:47 INFO session.SessionState: Created HDFS directory: /tmp/hive/spark/64b097c1-1ac3-4f8b-94e5-6ce45fadf854/_tmp_space.db
16/09/09 16:28:47 INFO repl.SparkILoop: Created sql context (with Hive support)..
SQL context available as sqlContext.
scala>
成功!






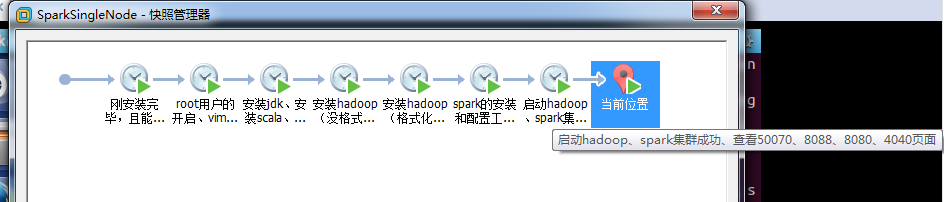
怎么,提交?
因为。我这篇博客是搭建的是spark on yarn模式! 请移步,
Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
Spark on YARN简介与运行wordcount(master、slave1和slave2)(博主推荐)
Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master、slave1和slave2)
Spark standalone简介与运行wordcount(master、slave1和slave2)
spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

