

Link of the Paper: https://arxiv.org/pdf/1502.03044.pdf
Main Points:
- Encoder-Decoder Framework: Encoder uses a convolutional neural network to extract a set of feature vectors which the authors refer to as annotation vectors. The extractor produces L vectors, each of which is a D-dimensional representation corresponding to a part of the image. a = { a1, ..., aL }, ai ∈ RD. In order to obtain a correspondence between the feature vectors and portions of the 2-D image, they extract features from a lower convolutional layer unlike previous work which instead used a fully connected layer. This allows the decoder to selectively focus on certain parts of an image by weighting a subset of all the feature vectors. Decoder uses a LSTM network to produce a caption by generating one word at every time step conditioned on a context vector, the previous hidden state and the previously generated words.
- Two attention-based image caption generators under a common framework: a "soft" deterministic attention mechanism trainable by standard back-propagation methods; and a "hard" stochastic attention mechanism trainable by maximizing an approximate variational lower bound or equivalently by Reinforce.
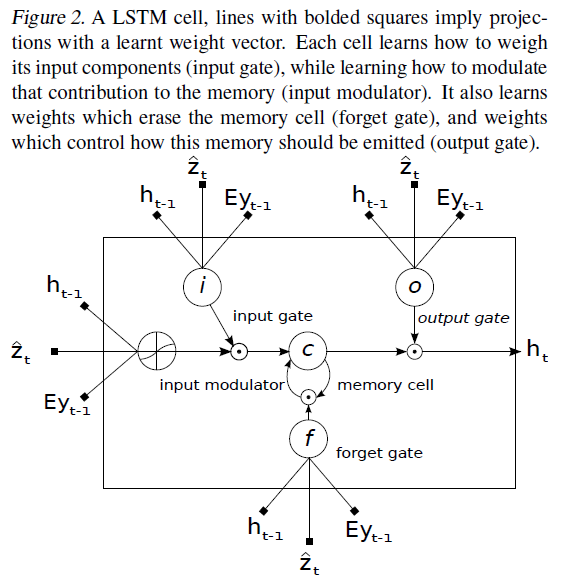
Other Key Points:
- Rather than compress an entire image into a static representation, attention allows for salient features to dynamically come to the forefront as needed. This is especially important when there is a lot of clutter in an image. Using representations ( such as those from the very top layer of a conv net ) that distill information in image down to the most salient objects is one effective solution that has been widely adopted in previous work. Unfortunately, this has one potential drawback of losing information which could be useful for richer, more descriptive captions. Using lower-level representation can help preserve this information.

