


Link of the Paper: https://arxiv.org/abs/1411.4555
Main Points:
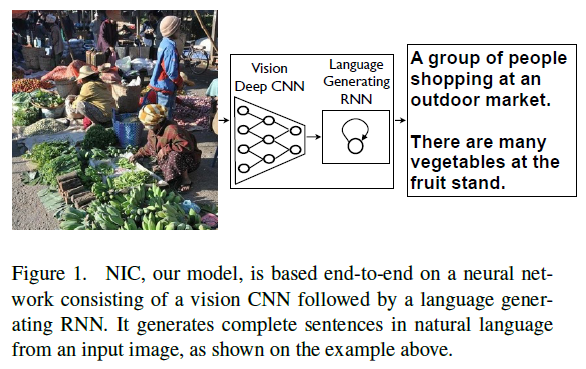
- A generative model ( NIC, GoogLeNet + LSTM ) based on a deep recurrent architecture: the model is trained to maximize the likelihoodP(S|I) of the target description sentence given the training image I. S = { S1, S2, ... } is the target sequence of words and each word St comes from a given dictionary, that describes the image adequately.
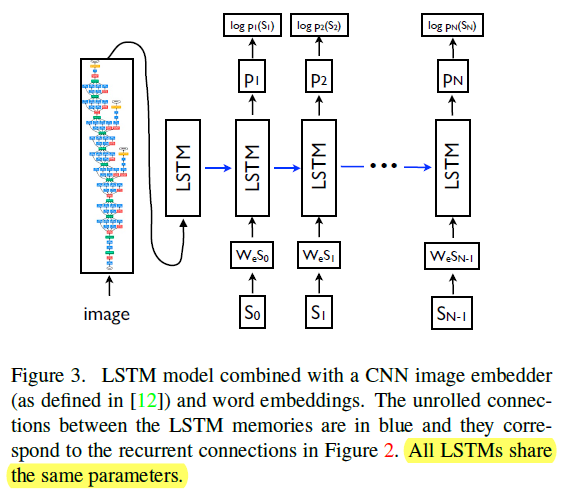
- The authors use a CNN as an image "encoder", by first pre-training it for an image classification task and using the last hidden layer as an input to the RNN decoder that generates sentences. They call this model the Neural Image Caption, or NIC.
Other Key Points:
- A description must capture not only the objects contained in an image, but it also must express how these objects relate to each other as well as their attributes and the activities they are involved in.
- The inspiration of Image Captioning could come from advances in Machine Translation.
- There are multiple approaches that can be used to generate a sentence given an image, with NIC. The first one is Sampling where the authors just sample the first word according to p1, then provide the corresponding embedding as input and sample p2, continuing like this until we sample the special end-of-sentence token or some maximum length. The second one is Beamsearch: iteratively consider the set of the k best sentences up to time t as candidates to generate sentences of size t+1, and keep only the resulting best k of them. This better approximates S = arg maxS' p(S'|I).
