
《Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information》DRCN 句子匹配
模型结构
首先是模型图:

传统的注意力机制无法保存多层原始的特征,根据DenseNet的启发,作者将循环网络的隐层的输出与最后一层连接。
另外加入注意力机制,代替原来的卷积。由于最后的特征维度过大,加入AE降维。
Word Representation Layer
层
自然语言的任务首先就是输入层,对每个词的one-hot表示进行embedding,

这几个公式很好理解,首先作者将词的embedding分为两部分,一部分参与训练,即EtrEtr,另一部分是固定不动的,即EfixEfix,
cp: 然后就是词级别的表示char-Conv,具体是:char -embeding --> conv---> maxpooling --->vector ,卷积的参数是可训练的。
fp: exact match的匹配特征,主要是a中的每个词是否在b中有对应的词
最后后将这些表示拼接起来,就得到了每个词的最后表示。
Densely connected Recurrent Networks
密集连接层
在这一层,作者收DenseNet启发,使用了密集连接和RNN结合的方法来实现对对句子的处理。首先hlthtl表示的是第l层的RNN的第t的隐层状态,

公式3是传统的多层RNN的结构,前一层的RNN的 隐层状态作为当前层的输入,然后就是RNN的计算方式,
公式4 借鉴了残差网络,当前层的输入不仅包含了前一层的隐层状态,同时包含了前一层的输入,但他们是相加的方式,作者认为这种相加的形式很可能会阻碍信息的流动,
公式5 因此借鉴DenseNet,作者使用了拼接了方式,这样不仅保留了两部分信息,同时拼接方法也最大程度的保留了各自的独有信息。但这就有一个问题了,多层的RNN的参数就不一样了,因为拼接的方式导致了每一层输入对应的参数规模是在不断变大的,这样就不能做的很深了。
Densely-connected Co-attentive networks
密集连接注意力
因为句子匹配考虑的两个句子之间关系,因此需要建模两个句子之间的交互,目前来说,注意力机制是一种非常好的方法,因此作者在这样也使用了注意力机制,在RNN的每一层使用soft-alignment
,最后将权重通过拼接加入到全连接,避免信息的丢失。
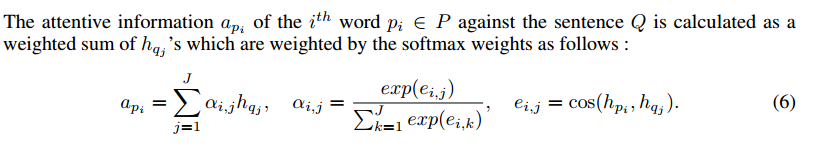
这个就是传统的co-attention计算方法,计算两个序列之间的在每个词上的对应关系,不过作者这里比较粗暴,直接使用了余弦相似度来计算每两个词之间的相似,这里也可以使用一个简单的MLP来计算。有意思的地方在下边

这个就很有意思了,我们传统的做法是得到每个词在对方句子上的概率分布之后,使用对方句子中每个词向量的加权和作为当前词的向量表示,而这里作者直接使用了计算出来的权值分布,将其作为一个特征引入到当前层的输入当中,这个感觉还是很有意思的。
Bottleneck component
瓶颈处理层
正如前边提到的,这种dense连接方式直接导致的一个问题就是随着模型的加深,参数量会变的越来越多,这样最后全连接层的压力就会特别大。因此作者在这里使用了一个AutoEncoder来解决这个问题。AutoEncoder可以帮助压缩得到的巨大向量表示,同时可以保持原始的信息。我个人感觉就是一个全连接层吧。从论文附录的实现细节来看。
分类层
这是处理两个句子关系常用的一种匹配方法,作拼接,相减,点乘,不过作者在这里也是用了相减的绝对值,然后将最终拼接的向量通过一个全连接层,然后根据任务进行softmax分类
实验结果
照例,上图,作者在NLI任务和Question Pair两个任务上进行了模型验证,效果当然是十分不错的。


感想
0、词向量的表示上,
1、将DenseNet的一些想法引入到了stack RNN中,
2、从残差连接到DenseNet,
3、注意力权值的使用方法,
4、利用AutoEncoder来压缩向量。
参考:
https://blog.csdn.net/u013398398/article/details/81463343
https://www.paperweekly.site/papers/notes/436
https://blog.csdn.net/xiayto/article/details/81247461

