hadoop系列三:mapreduce的使用(一)
转载请在页首明显处注明作者与出处
http://www.cnblogs.com/zhuxiaojie/p/7224772.html
一:说明
此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等。
当前使用的hadoop版本为2.6.4
上一篇:hadoop系列二:HDFS文件系统的命令及JAVA客户端API
在下面可以看到统计一本小说(斗破苍穹)哪些词语出现了最多。
本来mapreducer只想写一篇的,可是发现写一篇太长了,所以就进行了拆分。
所有的部分都提供代码下载
目录可以在右侧查看,点击目录跳转到相应的位置
一:说明 二:wordcount字数统计功能 2.1:准备文件 2.2:编写Mapper的代码 2.3编写Reduce的代码 2.4:编写main方法执行这个mapreduce 2.5:把代码放在hadoop中运行 三:自定义序列化的类 3.1:自定义一个序列化的输出bean 3.2:编写mapper 3.3:编写reducer 3.4:编写main方法 3.5:在hadoop中运行 四:数据分区(按照不同类型输出到不同的位置) 4.1:分区规则的代码 4.2:设置分区代码 4.3:分区的完整代码 4.4:在hadoop运行分区代码 五:数据排序及对象的重用 5.1:编写排序代码 5.2:编写mapper(对象的复用) 5.3:编写reducer 5.4:编写启动类 5.5:完整的代码 5.6:在hadoop中执行排序 六:统计一本小说中出现的词汇(包含Combiner) 6.1:准备工作 6.2:配置maven打包包含分词的依赖 6.3:数据汇总(Combiner) 6.4:排序阶段
二:wordcount字数统计功能
相应的代码在:代码地址--点我跳转
2.1:准备文件
既然是要统计字数,那么肯定是要有相应的文档,我们先准备一些这样的文档,我们准备两个文档,分别叫text1.txt和text2.txt
text1.txt
hello zhangsan
lisi nihao
hai zhangsan
nihao lisi
x xiaoming
text2.txt
zhangsan a lisi b wangwu c jiji 7 haha xiaoming xiaoming is gril
我们生成这样两个文件,待会去统计每个单词分别出现了多少次
2.2:编写Mapper的代码
直接贴上代码,相应的解释在注释中
import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * 这部分的输入是由mapreduce自动读取进来的 * 简单的统计单词出现次数<br> * KEYIN 默认情况下,是mapreduce所读取到的一行文本的起始偏移量,Long类型,在hadoop中有其自己的序列化类LongWriteable * VALUEIN 默认情况下,是mapreduce所读取到的一行文本的内容,hadoop中的序列化类型为Text * KEYOUT 是用户自定义逻辑处理完成后输出的KEY,在此处是单词,String * VALUEOUT 是用户自定义逻辑输出的value,这里是单词出现的次数,Long * @author Administrator * */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { //这是mapreduce读取到的一行字符串 String line = value.toString(); String[] words = line.split(" "); for (String word : words) { //将单词输出为key,次数输出为value,这行数据会输到reduce中 context.write(new Text(word), new LongWritable(1)); } } }
2.3编写Reduce的代码
同样直接上代码
import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /** * 第一个Text: 是传入的单词名称,是Mapper中传入的 * 第二个:LongWritable 是该单词出现了多少次,这个是mapreduce计算出来的,比如 hello出现了11次 * 第三个Text: 是输出单词的名称 ,这里是要输出到文本中的内容 * 第四个LongWritable: 是输出时显示出现了多少次,这里也是要输出到文本中的内容 * @author Administrator * */ public class WordCountReduce extends Reducer<Text, LongWritable, Text, LongWritable> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { long count = 0; for (LongWritable num : values) { count += num.get(); } context.write(key, new LongWritable(count)); } }
2.4:编写main方法执行这个mapreduce
写了mapper与reduce的代码,自然是需要一个main方法来把这些代码运行起来的,所以编写如下代码
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 相当于运行在yarn中的客户端 * @author Administrator * */ public class WordCountDriver { public static void main(String[] args) throws IOException { Configuration conf = new Configuration(); //如果是打包在linux上运行,则不需要写这两行代码 /* //指定运行在yarn中 conf.set("mapreduce.framework.name", "yarn"); //指定resourcemanager的主机名 conf.set("yarn.resourcemanager.hostname", "server1");*/ Job job = Job.getInstance(conf); //使得hadoop可以根据类包,找到jar包在哪里 job.setJarByClass(WordCountDriver.class); //指定Mapper的类 job.setMapperClass(WordCountMapper.class); //指定reduce的类 job.setReducerClass(WordCountReduce.class); //设置Mapper输出的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //设置最终输出的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //指定输入文件的位置,这里为了灵活,接收外部参数 FileInputFormat.setInputPaths(job, new Path(args[0])); //指定输入文件的位置,这里接收启动参数 FileOutputFormat.setOutputPath(job, new Path(args[1])); //将job中的参数,提交到yarn中运行 //job.submit(); try { job.waitForCompletion(true); //这里的为true,会打印执行结果 } catch (ClassNotFoundException | InterruptedException e) { e.printStackTrace(); } } }
2.5:把代码放在hadoop中运行
代码写完了,要怎么运行呢?
(1)首先,肯定不是直接执行main方法运行,因为目前的代码,并不知道hadoop部署在哪里,我们要做的是,把这个项目打包,如果是maven项目,则使用maven package命令打包,把相应的jar包,上传到服务器中。
(2)其次,需要把之前的两个文本文件,text1.txt和text2.txt上传到hdfs中,因为既然是大数据,那么在实际环境中,肯定不可能是这么小的数据来进行计算,肯定是有着大量的数据,而这些数据,靠一台服务器肯定是放不下去的,也只有像hdfs这种大文件存储,或者一些其它的专门存放大数据的地方,才能存放了,我们使用如下的命令,把文件上传到hdfs中,如果这些命令看不懂,可以先看上一章节,hdfs的使用。
//创建一个目录 hadoop fs -mkdir -p /wordcount/input //上传文件 hadoop fs -put text1.txt text2.txt /wordcount/input
(3)运行代码,带有main方法的代码,是可以使用java命令运行的,但是因为hadoop依赖了很多别的jar包,这样子运行代码,需要添加大量的依赖,写的命令很复杂,hadoop提供了这样的一个命令来执行代码
hadoop jar wordcount.jar com.zxj.hadoop.demo.mapreduce.wordcount.WordCountDriver /wordcount/input /wordcount/output
这里来解释一下这条命令的意思,jar说明使用hadoop中内置的jar命令,也就是执行一个jar包。wordcount.jar 这个是上传的代码,也就是我们之前写的代码,打包之后上传到服务器中的名字。com.zxj.hadoop.demo.mapreduce.wordcount.WordCountDriver是需要运行哪个类,因为一个jar包中有可能有多个main方法,这样可以指定使用哪个类启动。最后两个参数 /wordcount/input 和 /wordcount/output,这是我们的代码中自定义的两个参数,第一个是文件的目录(意味着可以读取一整个目录中的多个文件),第二个是输出结果的目录。
执行完成之后,会有如下结果,如果没有抛出异常,或者写明失败,带有success的就是成功了。
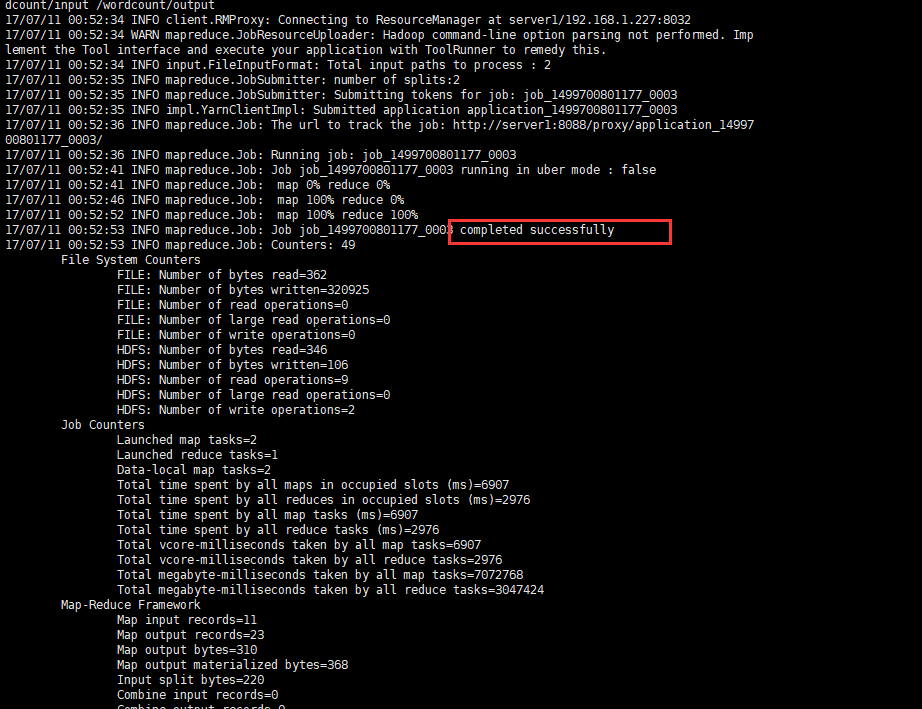
现在我们可以去看一下输出结果
查看输出的文件
hadoop fs -ls /wordcount/output

第一个文件代表执行成功,第二个文件是输出结果文件,执行如下命令查看
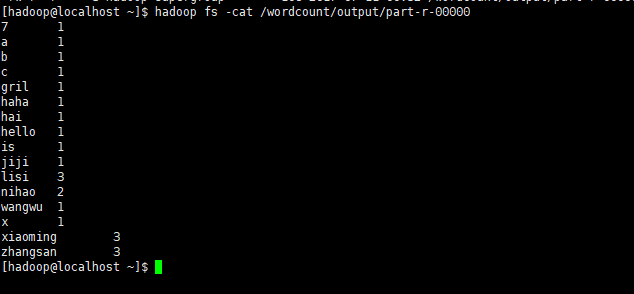
从上图发现,zhangsan出现了3次,xiaoming出现了3次,nihao出现了2次,其它的是1次
三:自定义序列化的类
代码地址:下载代码
当输出的结果比较复杂的时候,就没办法使用Text,LongWritable这种类型来输出,这个时候我们可以自定义一个序列化的类,这个序列化不是jdk的序列化,而是hadoop自已的序列化,我们需要实现它
如下文档,保存并命名为staff.txt:
张三 江西 打车 200 李四 广东 住宿 600 王五 北京 伙食 320 张三 江西 话费 50 张三 湖南 打车 900 周六 上海 采购 3000 李四 西藏 旅游 1000 王五 北京 借款 500 李四 上海 话费 50 周六 北京 打车 600 张三 广东 租房 3050
3.1:自定义一个序列化的输出bean
之前我们一直使用LongWriteable或者Text来作为输入的内容,但是如果看这两个对象的源码,它们都是实现了Writable接口的,这是一个hadoop自带的序列化接口。
现在我们要输出一些信息,单单靠一个Text已经无法达到我们的效果的时候,我们就可以自定义一个对象,然后实现Writable接口
如下的代码,就是自定义一个可序列化的bean
/** * 封装的bean */ public static class SpendBean implements Writable{ private Text userName; private IntWritable money; public SpendBean(Text userName, IntWritable money) { this.userName = userName; this.money = money; } /** * 反序列化时必须有一个空参的构造方法 */ public SpendBean(){} /** * 序列化的代码 * @param out * @throws IOException */ @Override public void write(DataOutput out) throws IOException { userName.write(out); money.write(out); } /** * 反序列化的代码 * @param in * @throws IOException */ @Override public void readFields(DataInput in) throws IOException { userName = new Text(); userName.readFields(in); money = new IntWritable(); money.readFields(in); } public Text getUserName() { return userName; } public void setUserName(Text userName) { this.userName = userName; } public IntWritable getMoney() { return money; } public void setMoney(IntWritable money) { this.money = money; } @Override public String toString() { return userName.toString() + "," + money.get(); } }
3.2:编写mapper
编写mapper
/** * Mapper */ public static class GroupUserMapper extends Mapper<LongWritable,Text,Text,SpendBean>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String val = value.toString(); String[] split = val.split("\t"); //这里就不作字符串异常的处理了,核心代码简单点 String name = split[0]; String province = split[1]; String type = split[2]; int money = Integer.parseInt(split[3]); SpendBean groupUser = new SpendBean(); groupUser.setUserName(new Text(name)); groupUser.setMoney(new IntWritable(money)); context.write(new Text(name),groupUser); } }
3.3:编写reducer
编写reducer
/** * reducer */ public static class GroupUserReducer extends Reducer<Text,SpendBean,Text,SpendBean> { /** * 姓名 * @param key * @param values * @param context * @throws IOException * @throws InterruptedException */ @Override protected void reduce(Text key, Iterable<SpendBean> values, Context context) throws IOException, InterruptedException { int money = 0;//消费金额 //遍历 for(SpendBean bean : values){ money += bean.getMoney().get(); } //输出汇总结果 context.write(key,new SpendBean(key,new IntWritable(money))); } }
3.4:编写main方法
编写main方法
/** * 编写启动类 * @param args */ public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(GroupUser.class); //设置jar中的启动类,可以根据这个类找到相应的jar包 job.setMapperClass(GroupUserMapper.class); //设置mapper的类 job.setReducerClass(GroupUserRecuder.class); //设置reducer的类 job.setMapOutputKeyClass(Text.class); //mapper输出的key job.setMapOutputValueClass(SpendBean.class); //mapper输出的value job.setOutputKeyClass(Text.class); //最终输出的数据类型 job.setOutputValueClass(SpendBean.class); FileInputFormat.setInputPaths(job,new Path(args[0]));//输入的文件位置 FileOutputFormat.setOutputPath(job,new Path(args[1]));//输出的文件位置 boolean b = job.waitForCompletion(true);//等待完成,true,打印进度条及内容 if(b){ //success } }
完整的代码如下,这里把几个类都写在一起了。
package com.zxj.hadoop.demo.mapreduce.staffspend.groupuser; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * @Author 朱小杰 * 时间 2017-07-23 .16:33 * 说明 ... */ public class GroupUser { /** * Mapper */ public static class GroupUserMapper extends Mapper<LongWritable,Text,Text,SpendBean>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String val = value.toString(); String[] split = val.split("\t"); //这里就不作字符串异常的处理了,核心代码简单点 String name = split[0]; String province = split[1]; String type = split[2]; int money = Integer.parseInt(split[3]); SpendBean groupUser = new SpendBean(); groupUser.setUserName(new Text(name)); groupUser.setMoney(new IntWritable(money)); context.write(new Text(name),groupUser); } } /** * reducer */ public static class GroupUserReducer extends Reducer<Text,SpendBean,Text,SpendBean> { /** * 姓名 * @param key * @param values * @param context * @throws IOException * @throws InterruptedException */ @Override protected void reduce(Text key, Iterable<SpendBean> values, Context context) throws IOException, InterruptedException { int money = 0;//消费金额 //遍历 for(SpendBean bean : values){ money += bean.getMoney().get(); } //输出汇总结果 context.write(key,new SpendBean(key,new IntWritable(money))); } } /** * 封装的bean */ public static class SpendBean implements Writable{ private Text userName; private IntWritable money; public SpendBean(Text userName, IntWritable money) { this.userName = userName; this.money = money; } /** * 反序列化时必须有一个空参的构造方法 */ public SpendBean(){} /** * 序列化的代码 * @param out * @throws IOException */ @Override public void write(DataOutput out) throws IOException { userName.write(out); money.write(out); } /** * 反序列化的代码 * @param in * @throws IOException */ @Override public void readFields(DataInput in) throws IOException { userName = new Text(); userName.readFields(in); money = new IntWritable(); money.readFields(in); } public Text getUserName() { return userName; } public void setUserName(Text userName) { this.userName = userName; } public IntWritable getMoney() { return money; } public void setMoney(IntWritable money) { this.money = money; } @Override public String toString() { return userName.toString() + "," + money.get(); } } /** * 编写启动类 * @param args */ public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(GroupUser.class); //设置jar中的启动类,可以根据这个类找到相应的jar包 job.setMapperClass(GroupUserMapper.class); //设置mapper的类 job.setReducerClass(GroupUserReducer.class); //设置reducer的类 job.setMapOutputKeyClass(Text.class); //mapper输出的key job.setMapOutputValueClass(SpendBean.class); //mapper输出的value job.setOutputKeyClass(Text.class); //最终输出的数据类型 job.setOutputValueClass(SpendBean.class); FileInputFormat.setInputPaths(job,new Path(args[0]));//输入的文件位置 FileOutputFormat.setOutputPath(job,new Path(args[1]));//输出的文件位置 boolean b = job.waitForCompletion(true);//等待完成,true,打印进度条及内容 if(b){ //success } } }
3.5:在hadoop中运行
然后执行maven clean package命令,重新打包,并且上传到服务器中。
我们也创建一个目录,来存放之前的员工消费信息
hadoop fs -mkdir -p /staffspend/input
把之前准备好的员工文件上传到这个目录
hadoop fs -put staff.txt /staffspend/input
然后准备执行任务
hadoop jar hadoop-mapreduce-1.0.jar com.zxj.hadoop.demo.mapreduce.staffspend.groupuser.GroupUser /staffspend/input /staffspend/output
执行成功后,查看输出文件
hadoop fs -cat /staffspend/output/part-r-00000

四:数据分区(按照不同类型输出到不同的位置)
下载代码:点我下载
这样的需求也经常会有,我可能并不是仅仅需要总的数据查看,我还可能要查看每一个类型,比如第三部分的文件中,我可能想分别查看每个省中,每个人分别用了多少钱。
这个时候我们对上第三部分的代码进行修改
我们要增加输出bean中的省份字段,红色位置是修改过的部分
/** * 封装的bean */ public static class SpendBean implements Writable{ private Text userName; private IntWritable money; private Text province; public SpendBean(Text userName, IntWritable money, Text province) { this.userName = userName; this.money = money; this.province = province; } /** * 反序列化时必须有一个空参的构造方法 */ public SpendBean(){} /** * 序列化的代码 * @param out * @throws IOException */ @Override public void write(DataOutput out) throws IOException { userName.write(out); money.write(out); province.write(out); } /** * 反序列化的代码 * @param in * @throws IOException */ @Override public void readFields(DataInput in) throws IOException { userName = new Text(); userName.readFields(in); money = new IntWritable(); money.readFields(in); province = new Text(); province.readFields(in); } public Text getUserName() { return userName; } public Text getProvince() { return province; } public void setProvince(Text province) { this.province = province; } public void setUserName(Text userName) { this.userName = userName; } public IntWritable getMoney() { return money; } public void setMoney(IntWritable money) { this.money = money; } @Override public String toString() { return "SpendBean{" + "userName=" + userName + ", money=" + money + ", province=" + province + '}'; } }
可以看到,上面的bean并没有改动什么特别的东西,完全是加了一个省份字段而已。
4.1:分区规则的代码
首先,如果要按照数据进行分区,我们肯定需要写分区的代码来告诉hadoop,我们写一个分区的类来继承org.apache.hadoop.mapreduce.Partitioner
hadoop中的分区,是在mapper结束后的reducer中,所以下面的代码是在reducer时运行的,我们对不同的省份进行规则划分,比如说江西就是对应的0分区
具体代码如下:
package com.zxj.hadoop.demo.mapreduce.staffspend.groupuser; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; import java.util.HashMap; import java.util.Map; /** * @Author 朱小杰 * 时间 2017-07-29 .11:14 * 说明 * key ,value是mapper中输出的类型,因为分区是在mapper完成之后进行的 */ public class ProvincePartitioner extends Partitioner<Text, GroupUser.SpendBean> { private static Map<String,Integer> provinces = new HashMap<>(); static { //这里给每一个省份编制一个分区 provinces.put("江西",0); provinces.put("广东",1); provinces.put("北京",2); provinces.put("湖南",3); provinces.put("上海",4); provinces.put("西藏",5); } /** * 给指定的数据一个分区 * @param text * @param spendBean * @param numPartitions * @return */ @Override public int getPartition(Text text, GroupUser.SpendBean spendBean, int numPartitions) { Integer province = provinces.get(spendBean.getProvince().toString()); province = province == null ? 6 : province; //如果在省份列表中找不到,则指定一个默认的分区 return province; } }
很简单的代码,我们划分了6个分区,如果有的省份在这6个分区中找不到,那余下的就会进入第7个分区中。
4.2:设置分区代码
分区的代码既然写完了,那么就需要在运行的时候,指定这分区的规则是我们刚才写的代码,位置在运行的main方法中,如下:
红色部分是重点部分,也是改过的部分
/** * 编写启动类 * @param args */ public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(GroupUser.class); //设置jar中的启动类,可以根据这个类找到相应的jar包 job.setMapperClass(GroupUserMapper.class); //设置mapper的类 job.setReducerClass(GroupUserReducer.class); //设置reducer的类 job.setPartitionerClass(ProvincePartitioner.class);//指定数据分区规则,不是必须要的,根据业务需求分区 job.setNumReduceTasks(7); //设置相应的reducer数量,这个数量要与分区的大最数量一致 job.setMapOutputKeyClass(Text.class); //mapper输出的key job.setMapOutputValueClass(SpendBean.class); //mapper输出的value job.setOutputKeyClass(Text.class); //最终输出的数据类型 job.setOutputValueClass(SpendBean.class); FileInputFormat.setInputPaths(job,new Path(args[0]));//输入的文件位置 FileOutputFormat.setOutputPath(job,new Path(args[1]));//输出的文件位置 boolean b = job.waitForCompletion(true);//等待完成,true,打印进度条及内容 if(b){ //success } }
这里再说明一下
job.setNumReduceTasks(7);如果
如果这个数值是1,那么所有的数据全部会输出到一个文件中。
假如是2,那么将会报错。
假如超出分区大小,比如写一个10,那么多出来的文件将会为空。所以一般是按最大需要分区数量写。
4.3:分区的完整代码
下面贴出完整的代码
分区代码:
package com.zxj.hadoop.demo.mapreduce.staffspend.groupuser; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; import java.util.HashMap; import java.util.Map; /** * @Author 朱小杰 * 时间 2017-07-29 .11:14 * 说明 * key ,value是mapper中输出的类型,因为分区是在mapper完成之后进行的 */ public class ProvincePartitioner extends Partitioner<Text, GroupUser.SpendBean> { private static Map<String,Integer> provinces = new HashMap<>(); static { //这里给每一个省份编制一个分区 provinces.put("江西",0); provinces.put("广东",1); provinces.put("北京",2); provinces.put("湖南",3); provinces.put("上海",4); provinces.put("西藏",5); } /** * 给指定的数据一个分区 * @param text * @param spendBean * @param numPartitions * @return */ @Override public int getPartition(Text text, GroupUser.SpendBean spendBean, int numPartitions) { Integer province = provinces.get(spendBean.getProvince().toString()); province = province == null ? 6 : province; //如果在省份列表中找不到,则指定一个默认的分区 return province; } }
其它代码,这些代码是写在一个文件中了
package com.zxj.hadoop.demo.mapreduce.staffspend.groupuser; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * @Author 朱小杰 * 时间 2017-07-23 .16:33 * 说明 ... */ public class GroupUser { /** * Mapper */ public static class GroupUserMapper extends Mapper<LongWritable,Text,Text,SpendBean>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String val = value.toString(); String[] split = val.split("\t"); //这里就不作字符串异常的处理了,核心代码简单点 String name = split[0]; String province = split[1]; String type = split[2]; int money = Integer.parseInt(split[3]); SpendBean groupUser = new SpendBean(); groupUser.setUserName(new Text(name)); groupUser.setMoney(new IntWritable(money)); groupUser.setProvince(new Text(province)); context.write(new Text(name),groupUser); } } /** * reducer */ public static class GroupUserReducer extends Reducer<Text,SpendBean,Text,SpendBean> { /** * 姓名 * @param key * @param values * @param context * @throws IOException * @throws InterruptedException */ @Override protected void reduce(Text key, Iterable<SpendBean> values, Context context) throws IOException, InterruptedException { int money = 0;//消费金额 //遍历 Text province = null; for(SpendBean bean : values){ money += bean.getMoney().get(); province = bean.getProvince(); } //输出汇总结果 context.write(key,new SpendBean(key,new IntWritable(money),province)); } } /** * 封装的bean */ public static class SpendBean implements Writable{ private Text userName; private IntWritable money; private Text province; public SpendBean(Text userName, IntWritable money, Text province) { this.userName = userName; this.money = money; this.province = province; } /** * 反序列化时必须有一个空参的构造方法 */ public SpendBean(){} /** * 序列化的代码 * @param out * @throws IOException */ @Override public void write(DataOutput out) throws IOException { userName.write(out); money.write(out); province.write(out); } /** * 反序列化的代码 * @param in * @throws IOException */ @Override public void readFields(DataInput in) throws IOException { userName = new Text(); userName.readFields(in); money = new IntWritable(); money.readFields(in); province = new Text(); province.readFields(in); } public Text getUserName() { return userName; } public Text getProvince() { return province; } public void setProvince(Text province) { this.province = province; } public void setUserName(Text userName) { this.userName = userName; } public IntWritable getMoney() { return money; } public void setMoney(IntWritable money) { this.money = money; } @Override public String toString() { return "SpendBean{" + "userName=" + userName + ", money=" + money + ", province=" + province + '}'; } } /** * 编写启动类 * @param args */ public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(GroupUser.class); //设置jar中的启动类,可以根据这个类找到相应的jar包 job.setMapperClass(GroupUserMapper.class); //设置mapper的类 job.setReducerClass(GroupUserReducer.class); //设置reducer的类 job.setPartitionerClass(ProvincePartitioner.class);//指定数据分区规则,不是必须要的,根据业务需求分区 job.setNumReduceTasks(7); //设置相应的reducer数量,这个数量要与分区的大最数量一致 job.setMapOutputKeyClass(Text.class); //mapper输出的key job.setMapOutputValueClass(SpendBean.class); //mapper输出的value job.setOutputKeyClass(Text.class); //最终输出的数据类型 job.setOutputValueClass(SpendBean.class); FileInputFormat.setInputPaths(job,new Path(args[0]));//输入的文件位置 FileOutputFormat.setOutputPath(job,new Path(args[1]));//输出的文件位置 boolean b = job.waitForCompletion(true);//等待完成,true,打印进度条及内容 if(b){ //success } } }
4.4:在hadoop运行分区代码
我们重新打包项目后,重新上传到服务器中,直接执行命令运行
hadoop jar hadoop-mapreduce-1.0.jar com.zxj.hadoop.demo.mapreduce.staffspend.groupuser.GroupUser /staffspend/input /staffspend/output2
结果会发现reducer的过程,明显慢了下来,因为是在reducer中分区,所以自然会慢了一些。
执行完成后,我们查看输出列表
hadoop fs -ls /staffspend/output2
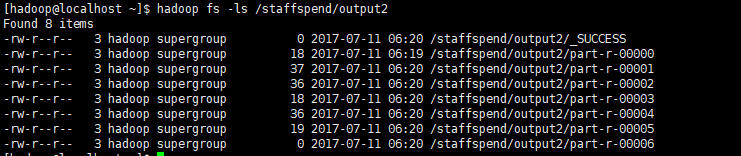
可以看到,这里有7个文件,对应着7个分区,执行命令查看内容
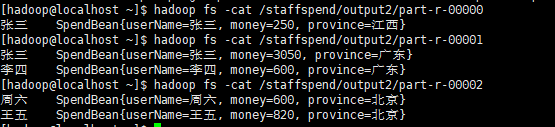
可以看到,这其中的数据,就是在一个省份中,每个人分别花了多少钱
五:数据排序及对象的重用
下载代码:点我下载
这一部分会讲到数据的排序,这种需求也是会经常会有的,比如上面的例子中,我就想知道公司哪个员工的经费是最多的。
其次就是对象的重用,既然是大数据,那么map的次数远远不止上亿这么简单,我们每次都要重复创建一个bean吗?
先准备一些数据,我们也可以用之前计算出来的数据,但是由于之前打印的格式不好,是toString()的默认格式,所以我这里再准备一份数据
张三 2980 李四 8965 王五 1987 小黑 6530 小陈 2963 小梅 980
我们开始编码
5.1:编写排序代码
首先再准备一份bean,这个bean和以前不一样,需要实现排序接口
/** * 我们需要实现一个新的接口,这个接口包含了排序接口以及序列化接口 */ public static class Spend implements WritableComparable<Spend>{ private Text name; //姓名 private IntWritable money; //花费 public Spend(){} public Spend(Text name, IntWritable money) { this.name = name; this.money = money; } public void set(Text name, IntWritable money) { this.name = name; this.money = money; } @Override public int compareTo(Spend o) { return o.getMoney().get() - this.money.get(); } @Override public void write(DataOutput out) throws IOException { name.write(out); money.write(out); } @Override public void readFields(DataInput in) throws IOException { name = new Text(); name.readFields(in); money = new IntWritable(); money.readFields(in); } public Text getName() { return name; } public void setName(Text name) { this.name = name; } public IntWritable getMoney() { return money; } public void setMoney(IntWritable money) { this.money = money; } @Override public String toString() { return name.toString() + "\t" + money.get(); } }
其实这个排序接口就是jdk自带的一个排序接口,使用方法与jdk的一致,所以就不讲的太深入,主要就是靠这个接口来进行排序。
5.2:编写mapper(对象的复用)
这部分的mapper很简单,没有什么特殊要讲的内容
public static class SortMapper extends Mapper<LongWritable,Text,Spend,Text>{ private Spend spend = new Spend(); private IntWritable moneyWritable = new IntWritable(); private Text text = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split("\t");//这里就不做异常处理了,只写核心逻辑 String name = split[0]; int money = Integer.parseInt(split[1]); text.set(name); moneyWritable.set(money); spend.set(text, moneyWritable); context.write(spend,text); } }
代码逻辑上并没有什么可说的,因为数据已经是汇总的数据了,只是进行一个排序而已,而排序的代码又写在bean中实现的接口上了,这里主要就是讨论一下对象的复用。
因为大数据动则数十亿上百亿的数据,如果重复创建这么多对象,那么将增加GC的工作,我们可以复用它,就是把它定义在上方,在调用它的set方法,可以更新这个对象的值。
可能有人会觉得,在第二次操作这个对象的时候,那不是会改变这个对象的值吗?没错的,是会改变。那么第一次操作这方法时创建的对象,保留的引用不是也会更新值吗?答案是不会的,生成的bean一经写出,就会序列化出去,这个时候已经是一个序列化的数据了,序列化的数据在reducer中将会反序列化,这个时候,和这个对象已经没有关系了。
5.3:编写reducer
reducer平淡出奇,实在是没有什么可说的,直接输出结果就行
public static class SortReducer extends Reducer<Spend,Text,Text,Spend>{ /** * 因为在这之前已经是汇总的结果了,所以这里直接输出就行了 * @param key * @param values 这里面只有一个,就是姓名 * @param context * @throws IOException * @throws InterruptedException */ @Override protected void reduce(Spend key, Iterable<Text> values, Context context) throws IOException, InterruptedException { context.write(values.iterator().next(),key); } }
5.4:编写启动类
启动类与也是一样的,只不过不需要加上分区的代码
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration config = new Configuration(); Job job = Job.getInstance(config); job.setJarByClass(SortGroupUser.class); job.setMapperClass(SortMapper.class); job.setReducerClass(SortReducer.class); job.setMapOutputKeyClass(Spend.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Spend.class); FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); boolean b = job.waitForCompletion(true); if(b){ //success } }
这里的代码就没有注释了,想看注释的可以看上面部分的代码
5.5:完整的代码
为了防止强迫证的同学,贴出完整的代码
package com.zxj.hadoop.demo.mapreduce.staffspend.groupuser; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * @Author 朱小杰 * 时间 2017-07-29 .15:48 * 说明 带有排序功能的统计, */ public class SortGroupUser { public static class SortMapper extends Mapper<LongWritable,Text,Spend,Text>{ private Spend spend = new Spend(); private IntWritable moneyWritable = new IntWritable(); private Text text = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split("\t");//这里就不做异常处理了,只写核心逻辑 String name = split[0]; int money = Integer.parseInt(split[1]); text.set(name); moneyWritable.set(money); spend.set(text, moneyWritable); context.write(spend,text); } } public static class SortReducer extends Reducer<Spend,Text,Text,Spend>{ /** * 因为在这之前已经是汇总的结果了,所以这里直接输出就行了 * @param key * @param values 这里面只有一个,就是姓名 * @param context * @throws IOException * @throws InterruptedException */ @Override protected void reduce(Spend key, Iterable<Text> values, Context context) throws IOException, InterruptedException { context.write(values.iterator().next(),key); } } /** * 我们需要实现一个新的接口,这个接口包含了排序接口以及序列化接口 */ public static class Spend implements WritableComparable<Spend>{ private Text name; //姓名 private IntWritable money; //花费 public Spend(){} public Spend(Text name, IntWritable money) { this.name = name; this.money = money; } public void set(Text name, IntWritable money) { this.name = name; this.money = money; } @Override public int compareTo(Spend o) { return o.getMoney().get() - this.money.get(); } @Override public void write(DataOutput out) throws IOException { name.write(out); money.write(out); } @Override public void readFields(DataInput in) throws IOException { name = new Text(); name.readFields(in); money = new IntWritable(); money.readFields(in); } public Text getName() { return name; } public void setName(Text name) { this.name = name; } public IntWritable getMoney() { return money; } public void setMoney(IntWritable money) { this.money = money; } @Override public String toString() { return name.toString() + "\t" + money.get(); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration config = new Configuration(); Job job = Job.getInstance(config); job.setJarByClass(SortGroupUser.class); job.setMapperClass(SortMapper.class); job.setReducerClass(SortReducer.class); job.setMapOutputKeyClass(Spend.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Spend.class); FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); boolean b = job.waitForCompletion(true); if(b){ //success } } }
mapper与reducer都写在这里面了。
5.6:在hadoop中执行排序
我们把新准备的数据命令为all.txt,然后上传到服务器,再上传到hadoop的hdfs中
创建目录
hadoop fs -mkdir -p /staffsort/input
上传文件
hadoop fs -put all.txt /staffsort/input
执行运算
hadoop jar hadoop-mapreduce-1.0.jar com.zxj.hadoop.demo.mapreduce.staffspend.groupuser.SortGroupUser /staffsort/input /staffsort/output
查看输出
hadoop fs -ls /staffsort/output
hadoop fs -cat /staffsort/output/part-r-00000

OK完成
六:统计一本小说中出现的词汇(包含Combiner)
下载代码:点我下载
本部分涵盖了Combiner的知识点,以及在应用场景上是计算了斗破苍穹中哪些词汇出现的次数最多,达到这样一个效果,需要进行两次mapreducer,第一次是汇总,第二次是排序
6.1:准备工作
1:斗破苍穹.txt(自行下载)
2:中文分词器 ansj(也可以用别的)
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.1</version>
</dependency>
6.2:配置maven打包包含分词的依赖
我们的代码是要打成jar包到hadoop中运行的,之前的代码中,我们并没有依赖其它的东西,这次我们要依赖分词器,因为hadoop中是不带有这个东西的,所以我们打包的时候,也要把这个分词器打包进来,所以我们使用maven-assembly-plugin插件。这个插件可能很多人都用过,可是你们觉得仅仅是配置打包其它的依赖这么简单吗?no!no!no!我们要打出来的包,只包含分词器呀,因为在pom文件中,还包含了hadoop的jar包,我们不需要hadoop的jar包也打进来,因为在hadoop运行环境中,这些代码是在hadoop中存在的,而且加上hadooop的jar后,打出来的包会变的特别大。
我们现在要做的是打现来的包,只包含我们自己的代码加上分词器的jar。
我们看一下怎么做,如果朋友们有更好的方案,请在评论中指点,不胜感激
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4.1</version>
<executions>
<execution>
<id>make-jar</id>
<!-- 绑定到package生命周期阶段上 -->
<phase>package</phase>
<goals>
<!-- 只执行一次 -->
<goal>single</goal>
</goals>
<configuration>
<descriptors> <!--描述文件路径-->
<descriptor>src/main/assemble/package.xml</descriptor>
</descriptors>
</configuration>
</execution>
</executions>
</plugin>
上面是pom文件中的配置,但是上面依赖了一个其它的配置文件,我们把它建在了相应的目录,具体内容如下
<assembly xmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.2" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.2 http://maven.apache.org/xsd/assembly-2.0.0.xsd"> <!-- 生成的文件中,会带有这一部分 --> <id>a</id> <!-- 根目录中是否包含项目目录,不需要 --> <includeBaseDirectory>false</includeBaseDirectory> <formats> <format>jar</format> </formats> <fileSets> <!-- 打包本工程的代码,如果没有这部分,那么打出来的包不包含本项目的代码 --> <fileSet> <!-- ${project.build.directory}是打包后的target目录 --> <directory>${project.build.directory}/classes</directory> <outputDirectory></outputDirectory> </fileSet> </fileSets> <dependencySets> <dependencySet> <useProjectArtifact>true</useProjectArtifact> <useProjectAttachments>true</useProjectAttachments> <!-- 输出的位置,这是在根目录中 --> <outputDirectory></outputDirectory> <!-- 把代码解压出来,否则会是一个jar包的形式在里面 --> <unpack>true</unpack> <includes> <!-- 可以设置只加入这个maven的依赖 --> <include>org.ansj:ansj_seg</include> <include>org.nlpcn:nlp-lang</include> <include>org.nutz:nutz</include> </includes> </dependencySet> </dependencySets> </assembly>
如上就配置完了
6.3:数据汇总(Combiner)
第一步,我们要对数据进行汇总,不然怎么排序呢?汇总的代码与之前wordcount差不多,但是数据量就多了,毕竟那不是我随意编写的测试数据,而是一本小说,所以这里我们用到Combiner。
简要的说一个Combiner的作用,Combiner就是在map的阶段,先进行一步汇总,减少reducer的汇总的数据量。这个马上会讲到。
现在先来准备一个Mapper,因为输出的就是词汇和数量,所以也不需要自定义bean
package com.zxj.hadoop.demo.mapreduce.story; import org.ansj.domain.Result; import org.ansj.domain.Term; import org.ansj.splitWord.analysis.ToAnalysis; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; import java.util.Iterator; import java.util.List; /** * @Author 朱小杰 * 时间 2017-07-29 .19:00 * 说明 统计一本小说哪些词出现的次数最多 */ public class StoryMapper extends Mapper<LongWritable, Text, Text, LongWritable> { private Text text = new Text(); private LongWritable longWritable = new LongWritable(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString().trim(); //剔除空的一行 if(!StringUtils.isBlank(line)){ //分词的代码 Result parse = ToAnalysis.parse(line); List<Term> terms = parse.getTerms(); Iterator<Term> iterator = terms.iterator(); while (iterator.hasNext()){ Term term = iterator.next(); longWritable.set(1); text.set(term.getName()); context.write(text,longWritable); } } } }
代码和以前不同的是,这里面加入了分词的代码,将每一个词,当作一个key输出。
reducer的代码
package com.zxj.hadoop.demo.mapreduce.story; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.Iterator; /** * @Author 朱小杰 * 时间 2017-07-29 .19:10 * 说明 统计小说 */ public class StoryReducer extends Reducer<Text, LongWritable, LongWritable, Text> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { Iterator<LongWritable> iterator = values.iterator(); long num = 0; while (iterator.hasNext()){ LongWritable longWritable = iterator.next(); num += longWritable.get(); } context.write(new LongWritable(num),key); } }
reducer的代码就是简单的汇总,然后将数据输出到文本中。
此时有必要说一个Combiner,我们先看一个怎么设置一个Combiner
Job job = .. job.setCombinerClass(SortCombiner.class);//设置Combiner
再看一下Combiner中的需要传一个什么东西
/** * Set the combiner class for the job. * @param cls the combiner to use * @throws IllegalStateException if the job is submitted */ public void setCombinerClass(Class<? extends Reducer> cls ) throws IllegalStateException { ensureState(JobState.DEFINE); conf.setClass(COMBINE_CLASS_ATTR, cls, Reducer.class); }
是不是很奇怪,这里竟然是接收一个reducer。那我们能不能直接设置为reducer的类呢?答案是不行的,因为阶段不一样,Combiner是在运行完map后,自行汇总了一次,而Combiner汇总完之后,会再传到reducer进行大汇总。从流程上面来说,是这样子的,我草草画了一个图,可以看一下
这个是原来没有Combiner的图

这是加有Combiner的图

从流程上面看到Mapper后,如果有Combiner,会进行Combiner,再进行Reducer,也就意味着,Mapper的输出,成为了Combiner的输出,且Combiner的输出,成为了Reducer的输入。
但是Combiner需要遵循一个规则。Combiner需要作为一个可插拔的插件,可有可无,就算移除Combiner,也不会对结果造成任何影响。
为什么要使用Combiner呢?就是在各个map中预先进行一次,然后减少在reducer阶段的数据量,这样能提升很高的效率。
贴出Combiner的代码
package com.zxj.hadoop.demo.mapreduce.story; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.Iterator; /** * @Author 朱小杰 * 时间 2017-07-29 .20:03 * 说明 ... */ public class SortCombiner extends Reducer<Text, LongWritable, Text, LongWritable> { private LongWritable longWritable = new LongWritable(); @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { Iterator<LongWritable> iterator = values.iterator(); long num = 0; while (iterator.hasNext()){ LongWritable longWritable = iterator.next(); num += longWritable.get(); } longWritable.set(num); context.write(key,longWritable); } }
可以看到,这里的逻辑与reducer中差不多,其实就是在map阶段进行了一步汇总而已,值得关注的是,输出与输入是一样的,因为Combiner汇总后还是要交给reducer进行大汇总的。
最后看main方法,main方法也差不多,就是加上了设置Combiner的代码而已
package com.zxj.hadoop.demo.mapreduce.story; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * @Author 朱小杰 * 时间 2017-07-29 .19:14 * 说明 ... */ public class StoryDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(StoryDriver.class); job.setMapperClass(StoryMapper.class); job.setReducerClass(StoryReducer.class); job.setCombinerClass(SortCombiner.class);//设置Combiner job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); job.setOutputKeyClass(LongWritable.class); job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); boolean b = job.waitForCompletion(true); if(b){ } } }
把小说命名为dpcq.txt,上传到hadoop中,记得文件编码哦,最好是utf-8编码
hadoop fs -mkdir -p /story/input
hadoop fs -put dpcq.txt /story/input
然后打包后,把包含分词器的jar上传到服务器并且在hadoop中运行
hadoop jar hadoop-mapreduce-1.0-a.jar com.zxj.hadoop.demo.mapreduce.story.StoryDriver /story/input /story/output
执行结果如下

但是这并不是我们想要的结果,我们需要它对词汇出现的数量进行排序,所以我们还要进行一个排序的mapreducer
6.4:排序阶段
通过上面的汇总,我们已经得到了每个词分别出现了多少次,这一部分我们要对其进行排序,这一部分极其简单,我们之前也看过排序是怎么做的,实现一个Comparable接口而已,但是实际上我们这里并不需要实现,因为我们是根据词汇出现的次数来排序,我们来看一个LongWritable的源码

可以想象,LongWritable已经实现了排序接口,不需要我们去处理,不过LongWritable实现的是一个正序的排序,我们要拉到最底下才能看到哪个词汇出现了最多,如果我们要看倒序排的话,我们就要自己实现咯,如下就让long类型的数据是倒序排的
package com.zxj.hadoop.demo.mapreduce.story.sort; import org.apache.hadoop.io.LongWritable; /** * @Author 朱小杰 * 时间 2017-07-29 .21:00 * 说明 一个倒序的Long */ public class MyLongWritable extends LongWritable { @Override public int compareTo(LongWritable o) { if(o.get() > this.get()){ return 1; }else if (o.get() == this.get()){ return 0; }else{ return -1; } } }
这里直接继承了LongWritable,重写了它的排序代码,不过留一个悬念,为什么实现的代码不直接使用
return (int)(o.get() - this.get())
这不是会简单好多吗?为什么不使用呢?大家可以在评论里面回答哈!
好,我们已经定义了一个倒序的MyLongWribable,排序的时候,我们就用它好了
其它的代码就特别简单了,看mapper如下
package com.zxj.hadoop.demo.mapreduce.story.sort; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * @Author 朱小杰 * 时间 2017-07-29 .20:43 * 说明 ... */ public class SortMapper extends Mapper<LongWritable, Text, MyLongWritable, Text> { private Text text = new Text(); private MyLongWritable longWritable = new MyLongWritable(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String content = value.toString().trim(); if(!StringUtils.isBlank(content)){ String[] split = content.split("\t"); if(split.length == 2){ long number = Long.parseLong(split[0]);//出现的次数 String word = split[1]; //词汇 longWritable.set(number); text.set(word); context.write(longWritable,text); } } } }
如果你看明白了上面的一些说明,那么对于这里的代码,肯定是能看的懂的,否则自行回去复习哈。这里为什么输出的key是LongWritable呢?不是写自定义的MyLongWritable呢?因为这个key是hadoop传入的,这里面的值是代码着读取文件的位置,所以我们不能用我们自定义的排序Long,但是其它地方,就可以用了,比如在输出的地方
再看reducer的代码
package com.zxj.hadoop.demo.mapreduce.story.sort; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * @Author 朱小杰 * 时间 2017-07-29 .20:49 * 说明 ... */ public class SortReducer extends Reducer<MyLongWritable, Text, Text, MyLongWritable> { @Override protected void reduce(MyLongWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException { context.write(values.iterator().next(),key); } }
再看reducer的代码,那简直是简单到没话说了,给啥就输出啥,现在我们也知道,排序是按照reducer的输入key来进行排序的,那么它就会根据我们自定义的排序规则进行排序。
再看main方法,我甚至都有不想贴main方法的冲动了,没什么可写的嘛。
package com.zxj.hadoop.demo.mapreduce.story.sort; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * @Author 朱小杰 * 时间 2017-07-29 .20:50 * 说明 ... */ public class SortDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(SortDriver.class); job.setMapperClass(SortMapper.class); job.setReducerClass(SortReducer.class); job.setMapOutputKeyClass(MyLongWritable.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(MyLongWritable.class); FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); boolean b = job.waitForCompletion(true); if(b){ //success } } }
代码写完了,我们就把它放到mapreducer中运行,打包上传到服务器,直接执行命令
hadoop jar hadoop-mapreduce-1.0-a.jar com.zxj.hadoop.demo.mapreduce.story.sort.SortDriver /story/output /story/output2
自定义的参数中,第一个/story/output是上一次对小说进行词汇汇总的输出目录,因为我们排序就是要对这个输出结果进行排序,并不是乱写的哦。
执行完成之后,查看结果

出现最多的是逗号,好吧,我们应该排除标点符号的

这些词汇都是分词器进行划分的,与hadoop并无关系,如果觉得词汇表达不准,也可以换一个分词器,或者自己自定义一些词汇。
好了,这就完成了,掌声在哪里?
小伙伴A:啪啪啪啪啪啪啪啪啪啪啪啪啪啪啪~~~
小伙伴B:啪啪啪啪啪啪啪啪啪啪啪啪啪啪啪~~~
小伙伴C:啪啪啪啪啪啪啪啪啪啪啪啪啪啪啪~~~
小伙伴D:啪啪啪啪啪啪啪啪啪啪啪啪啪啪啪~~~
七:补充
本来是写完了的,想想还是又补充了一些东西。
7.1:大量小文件的优化
mapreducer读取文件时,每个文件都会生成一个maptask,所以当有大量小文件的时候,会造成效率低下,这个时候的做法就是要么在程序运行之前,将小文件合并,要么就是使用另一种方式
//如果不设置,默认使用的是TextInputFormat.class /* job.setInputFormatClass(CombineTextInputFormat.class); CombineTextInputFormat.setMaxInputSplitSize(job,4 * 1024 * 1024);//最大分片 CombineTextInputFormat.setMinInputSplitSize(job,2 * 1024 * 1024);//最小分片*/
它会将小文件合并成为一个maptast

