hadoop系列一:hadoop集群安装
转载请在页首明显处注明作者与出处
http://www.cnblogs.com/zhuxiaojie/p/6384393.html
一:说明
此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等。
当前使用的hadoop版本为2.6.4
二:准备工作
2.1:准备
安装虚拟机
在虚拟机中安装centos操作系统,我安装了四个,主机名分别为server1到server4,具体可以随意安装,不限制数量,当然,如果是集群那就要两台以上
修改centos的主机名,并且修改/etc/hosts中的文件,使得所有的机器可以互相ping通主机名,并且去除127.0.0.1那一行的解析,这些是必须的,不然以后运行会报错
下载jdk,设置java环境变量
下载hadoop2.6.4,当然,为了方便也设置了hadoop目录中bin的环境变量,以后我们用${HADOOP_HOME}来表示hadoop的目录
为了方便,我把防火墙给关了,建议初学者先关闭防火墙,因为初学者还不知道需要用到哪些端口,当然,在生产环境的服务器中,就老老实实的一个一个开端口吧。
三:开始安装
3.1:创建用户及目录
建议是专门创建一个用户去管理hadoop集群
useradd hadoop
passwd hadoop
然后编辑/etc/sudoers,使得hadoop可以使用sudo命令去使用root权限,非必须
vim /etc/sudoers
找到这个位置,添加最后的一行
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
创建一个hadoop专用的目录,解压开的hadoop目录我会放到这里,记得目录所属者给hadoop
mkdir /data/program
3.2:编辑配置文件
首先把目录所属者给hadoop用户
(1)修改${HADOOP_HOME}/etc/hadoop/中的hadoop-env.sh,找到配置JAVA_HOME的位置,修改并且编辑为正确的JAVA_HOME地址

因为hadoop在集群状态中, 是需要通过ssh协议来启动其它机器的应用的,所以需要配置
(2)修改${HADOOP_HOME}/etc/hadoop/core-site.xml,加入如下的配置,并且配置的目录,所属者给hadoop
<!-- 指定HADOOP所使用的文件系统中,namenode的位置及端口 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://server1:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoopdata</value>
</property>
(3)修改${HADOOP_HOME}/etc/hadoop/hdfs-site.xml,加入下面的配置
<!-- 指定HDFS副本的数量,也就是备份,默认值是3 -->
<property>
<name>dfs.replication</name>
<value>5</value>
</property>
<!-- secondnamenode 的地址 -->
<property>
<name>dfs.secondary.http.address</name>
<value>server1:50090</value>
</property>
(4)复制一份${HADOOP_HOME}/etc/hadoop/mapred-site.xml.template 为 mapred-site.xml,并且打开编辑
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5)编辑${HADOOP_HOME}/etc/hadoo/yarn-site.xml,并且打开编辑
<!-- 指定YARN中(ResourceManager)的地址 ,server1是一个主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>server1</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
这个时候就算是全部编辑完了,可以使用scp命令把配置好的hadoop复制到其它机器中。
3.3:启动集群
进入server1启动namenode
我们先对namenode进行格式化
hadoop namenode -format
进入hadoop的sbin目录
cd ${HADOOP_HOME}/sbin
./hadoop-daemon.sh start namenode
这样就启动了namenode服务,可以通过jps命令查看,并且namenode提供了一个图形化界面.
http://namenode的地址:50070/
比如 http://server1:50070
打开后如下
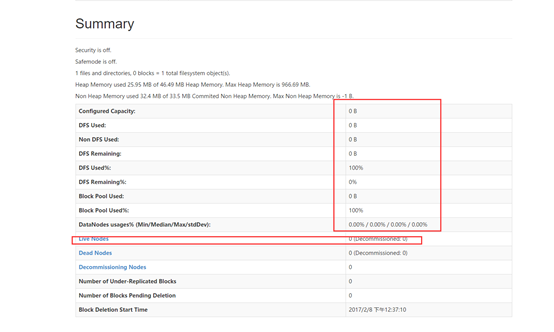
当然,由于我们只启动了namenode,并没有启动datanode,所以我们看到的hdfs的大小为0,也没有任何活着节点
因为我们搭建的是hadoop的集群,所以现在我们去server2中启动datanode
同样进入${HADOOP_HOME}/sbin目录
./hadoop-daemon.sh start datanode
启动成功后,继续在server3,server4中用同样的命令启动datanode。
hadoop集群中datanode节点的添加不需要什么特别的操作,启动一个,就算动添加了一个,因为我们之前在配置文件中有配置过namenode的位置,所以其它的节点可以找到namenode
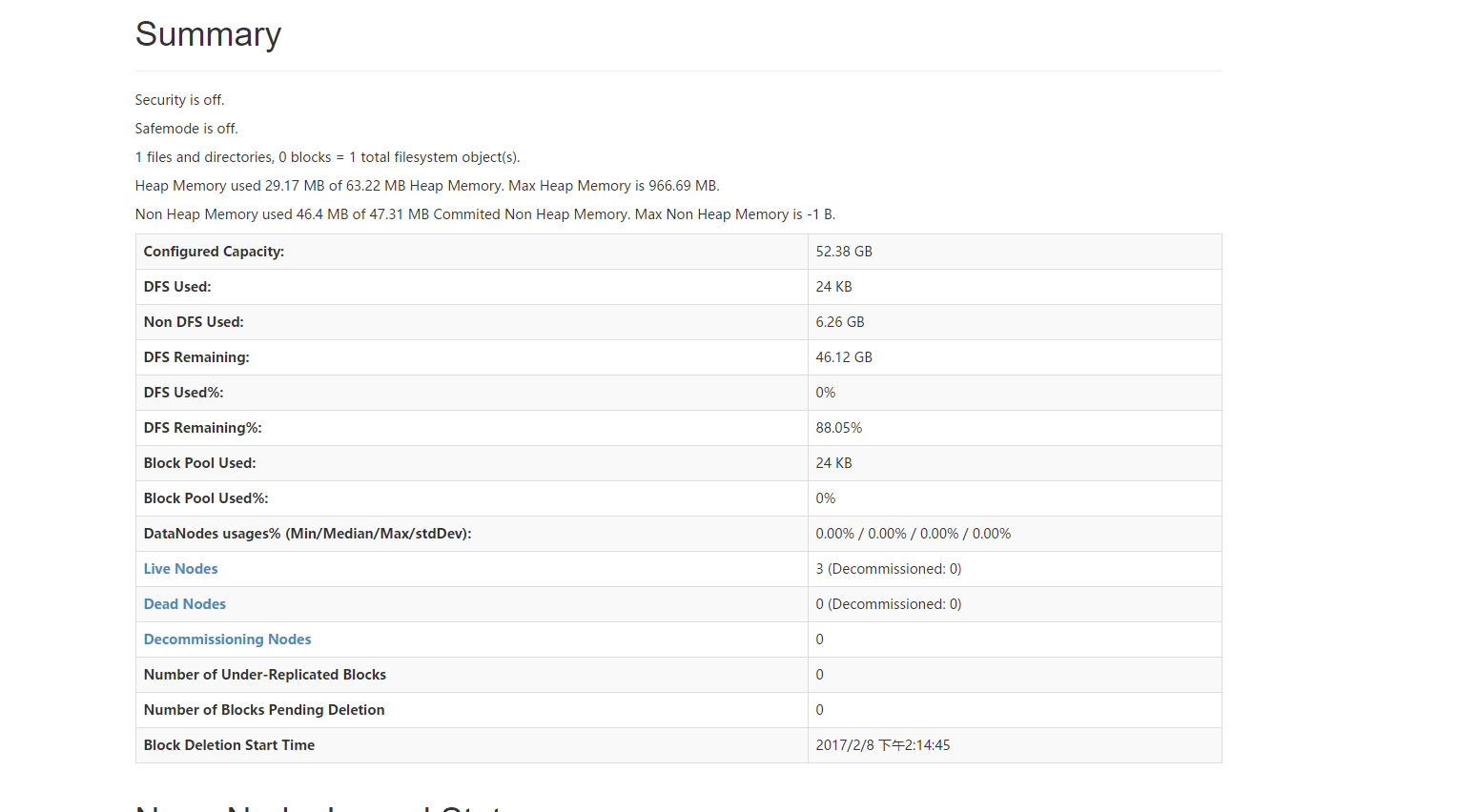
上面是我启动了三个datanode的页面,可以看到有三个节点是活着的。
3.4:批量启动脚本
我们现在有四台机器,那么我们启动的时候要执行四次命令,并且切换四台机器,而hadoop集群日后可能会非常大,甚至数千台,这个时候肯定不可能一个一个启动的,肯定会有批量启动脚本
先进入server1机器,因为这是namenode的机器,我们从这里启动脚本
我们还是切换到${HADOOP_HOME}/etc/hadoop目录,这里面有一个slaves文件,我们打开
发现里面的内容就是localhost,那么其实这个文件就是集群列表的配置文件,至于启动的脚本,hadoop其实已经写好了,我们只需要配置这个文件,hadoop的启动脚本就会遍历这个文件中所有的机器,并且去启动相应的进程。
我们把四台机器全部配置进去
server1
server2
server3
server4
然后保存退出。
然后进入到${HADOOP_HOME}/sbin
我们使用如下命令启动
./start-dfs.sh
这个时候就会使用ssh协议去其它机器启动hadoop节点。
当然这个时候,麻烦的就是会不停的提示需要输入每一台机器的密码,所以这个时候,我们需要配置免密登陆。
使用如下命令会生成一对公私钥
ssh-keygen
然后我们把相应的公钥复制到其它机器,
ssh-copy-id server1
这个时候会要求输入server1的密码,我们输入,就复制成功了,因为使用了ssh协议,即使是本机,也需要进行这样的操作。
我们陆续把从server1成生在密钥,复制到server1,server2,server3,server4中,复制完成后,
我们就可以从server1中使用ssh协议访问任意的一台机器而不需要密码了。
最后,我们可以使用这个命令启动整个集群
./start-all.sh
当然,是不建议使用这个命令的,一般会分开启动
./start-dfs.sh
./start-yarn.sh
如下就启动完成了,并且不需要密码
3.5:hadoop相应的脚本
start-all.sh 启动所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、JobTracker、 TaskTrack
stop-all.sh 停止所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、JobTracker、 TaskTrack
start-dfs.sh 启动Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode
stop-dfs.sh 停止Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode
hadoop-daemons.sh start namenode 单独启动NameNode守护进程
hadoop-daemons.sh stop namenode 单独停止NameNode守护进程
hadoop-daemons.sh start datanode 单独启动DataNode守护进程
hadoop-daemons.sh stop datanode 单独停止DataNode守护进程
hadoop-daemons.sh start secondarynamenode 单独启动SecondaryNameNode守护进程
hadoop-daemons.sh stop secondarynamenode 单独停止SecondaryNameNode守护进程
start-mapred.sh 启动Hadoop MapReduce守护进程JobTracker和TaskTracker
stop-mapred.sh 停止Hadoop MapReduce守护进程JobTracker和TaskTracker
hadoop-daemons.sh start jobtracker 单独启动JobTracker守护进程
hadoop-daemons.sh stop jobtracker 单独停止JobTracker守护进程
hadoop-daemons.sh start tasktracker 单独启动TaskTracker守护进程
hadoop-daemons.sh stop tasktracker 单独启动TaskTracker守护进程
四:安装时可能会遇到的问题
4.1:错误一
org.apache.hadoop.ipc.Client: Retrying connect to server: server1/192.168.1.4:9000. Already tried 3 time(s)
这是因为namenode所在机器,把namenode的主机名解析成了127.0.0.1,所以绑定的是这个IP,其它机器自然没法访问到namenode
解决办法是,
停止一切namenode与datanode。
删除在在如下配置文件配置的目录
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoopdata</value>
</property>
并且重新格式化namenode
hadoop namenode -format
然后重启namenode与datanode就可以

