
层级结构缓存IHiberarchyCache -- ESBasic 可复用的.NET类库(24)
1.缘起:
从IMultiTree到IAgileMultiTree,一切进展得都不错。但是,还有改进的地方。多叉树的一个优点在于,根据指定的节点能够非常迅速地找到其所有的子节点。但是缺点在于,根据节点值的ID定位到目标节点不够快,因为需要对所有的节点进行遍历操作。当节点非常多、层次非常深时,这种定位操作可能会严重的影响效率。
我设计了层级结构缓存ESBasic.ObjectManagement.Cache.IHiberarchyCache来加速这种根据节点值ID定位节点的访问。所谓“层级结构”,就是类似我们在IMultiTree章节缘起中介绍的那个多叉树式的组织结构。
使用IHiberarchyCache可以使两种操作都足够快:一是根据ID找到目标对象,另一种是根据ID找到其所有下级对象。
IHiberarchyCache融合了IAgileMultiTree和Dictionary两种对象容器的优势,以达到对层级结构的高效缓存。
层级结构缓存的形象示意图如下:
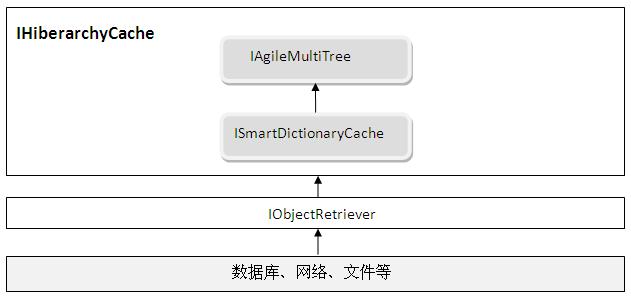
从示意图可以看到,IHiberarchyCache内部是借助IAgileMultiTree和ISmartDictionaryCache来实现的。
2.适用场合:
如果你在使用IAgileMultiTree的同时,经常需要根据节点值ID来定位节点,而且希望这种定位非常迅速,那么你可以改用IHiberarchyCache。
3.设计思想与实现
所有希望能够存储在IHiberarchyCache中的节点值必须实现IHiberarchyVal接口,该接口从IMTreeVal继承,其定义如下:
{
string SequenceCode { get; }
}
其相比于IMTreeVal增加了一个SequenceCode属性,以表明节点值在多叉树中的具体位置。
最初的IMultiTree对节点值是否有SequenceCode并没有任何要求,也就是说没有SequenceCode特性也可以正常使用IMultiTree。接着,IAgileMultiTree将SequenceCode作为一个设计参数纳入到核心机制中。到现在IHiberarchyCache,SequenceCode已经是节点值必须实现的一个属性了,否则,IHiberarchyCache将无法正常工作。这是一个逐渐强化SequenceCode作用的过程。
接下来我们来看IHiberarchyCache接口的定义:
{
/// <summary>
/// RootID 设置根节点的ID。
/// </summary>
string RootID { set; }
/// <summary>
/// SequenceCodeSplitter 节点路径(序列号)的分割符。
/// </summary>
char SequenceCodeSplitter { get; set; }
IObjectRetriever<string ,TVal> ObjectRetriever { set; }
int Count { get; }
void Initialize();
/// <summary>
/// Get 如果目标对象在缓存中不存在,则通过ObjectRetriever去提取。
/// </summary>
TVal Get(string id);
/// <summary>
/// HaveContained 缓存中是否一经包含了目标对象。
/// </summary>
bool HaveContained(string id);
/// <summary>
/// GetAllKeyListCopy 获取所有ID的列表的拷贝。
/// </summary>
IList<string> GetAllKeyListCopy();
/// <summary>
/// GetAllValListCopy 获取所有的节点值列表的拷贝。
/// </summary>
IList<TVal> GetAllValListCopy();
/// <summary>
/// GetChildrenOf 获取parentID的所有孩子节点的节点值列表。
/// </summary>
IList<TVal> GetChildrenOf(string parentID);
/// <summary>
/// GetChildrenCount 获取parentID直接下级的个数。
/// </summary>
int GetChildrenCount(string parentID);
/// <summary>
/// CreateHiberarchyTree 返回表示层级信息的最单纯的数据结构。
/// 注意:返回的Tree实际上与内部的AgileMultiTree是引用的根节点是同一个节点。
/// </summary>
MultiTree<TVal> CreateHiberarchyTree();
/// <summary>
/// GetNodesOnDepthIndex 获取某一深度的所有节点。Root的深度索引为0
/// </summary>
IList<TVal> GetNodesOnDepthIndex(int depthIndex);
/// <summary>
/// GetNodesOnDepthIndex 获取所属parentID体系下并且深度为depthIndex的所有节点。Root的深度索引为0
/// </summary>
IList<TVal> GetNodesOnDepthIndex(string parentID, int depthIndex);
}
RootID属性表明了根节点值的ID,IHiberarchyCache将会以该ID的节点值来初始化层级结构的根。
接下来的SequenceCodeSplitter、ObjectRetriever和Count属性的含义我们在前面介绍IMultiTree时已经详细介绍过了,这里就不再赘述。
以-Copy结尾的方法返回的都是对象集合的一个拷贝,在方法返回后,这个集合中的元素个数可以被修改,不会影响到IHiberarchyCache的内部缓存。
注意,GetChildrenOf方法返回的是TVal的IList,而不是MNode的IList。这是因为在IHiberarchyCache中,节点的概念已经被淡化了,它只是在IHiberarchyCache的内部实现时使用,用于加快类似获取某个元素的所有下级对象的访问。而外部根本不用在乎IHiberarchyCache内部的具体实现方式,所以不需要将MNode暴露出来。
而且,如果IHiberarchyCache的某个方法暴露出了MNode节点对象,则有可能产生危险,因为当用户获取了某MNode节点对象的引用后,就可以调用其AddChild方法手动向IHiberarchyCache内部多叉树中添加节点,而这个节点在内部的ISmartDictionaryCache缓存中并不存在,从而导致IHiberarchyCache内部的两个缓存的状态不一致。
CreateHiberarchyTree方法用于创建一个新的MultiTree,返回的MultiTree与IHiberarchyCache内部的多叉树拥有完全一样的结构。
GetNodesOnDepthIndex方法的含义与IMultiTree是完全一致的。
接下来我们将注意力转移到HiberarchyCache的具体实现上来。
正如示意图所展示的,HiberarchyCache内部使用了IAgileMultiTree和ISmartDictionaryCache,从而达到了我们在缘起部分希望达到的效果。但是图中还有一个细节我们应该注意到,那就是数据流的方向。我们看到,IAgileMultiTree的数据的来源是ISmartDictionaryCache,这意味着,如果目标对象在当前IHiberarchyCache实例中不存在,则会先通过IObjectRetriever将其加载到ISmartDictionaryCache中,然后IAgileMultiTree再从ISmartDictionaryCache中取出加载到多叉树中。那么,IAgileMultiTree是如何从ISmartDictionaryCache加载数据的了?是通过一个适配器,这个适配器叫做HiberarchyAgileNodePicker,其类图如下所示:
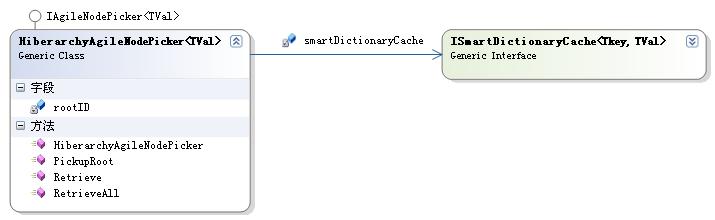
它将ISmartDictionaryCache适配为一个IAgileNodePicker对象给IAgileMultiTree使用。这一点我们可以从HiberarchyCache的Initialize方法的实现中一窥究竟。
关于HiberarchyCache的具体实现,其中的关键点罗列如下:
(1)关于线程安全的部分。由于内部仅有的两个容器ISmartDictionaryCache和IAgileMultiTree的实现都是线程安全的,所以HiberarchyCache本身也是线程安全的,而且不用做任何额外的处理。
(2)CreateHiberarchyTree方法返回的是内部多叉树的一个浅表拷贝。
(3)其它很多方法都是借助内部的IAgileMultiTree来完成的。
4. 使用时的注意事项
(1) IHiberarchyCache加速了根据节点值ID定位节点的查找访问,这是通过使用额外的内存空间为代价的,即典型的“以空间换时间”的例子。幸运的是,需要重复存储的只是节点值ID,而不是整个节点值对象,所以这个额外的内存开销并不是特别大。在大多数情况下,这个开销是值得的。
(2) 在介绍IMultiTree时,我们提到不要轻易调用其Count属性,因为每次调用都会进行一次递归统计动作,可能会影响性能。但是IHiberarchyCache的Count属性却可以非常快的返回,因为它直接返回了内部字典的Count属性,而不需要做额外的动作。
(3) IHiberarchyCache内部使用的两个缓存容器IAgileMultiTree和ISmartDictionaryCache,它们的状态是完全一致的。也就是说,如果一个对象存在于ISmartDictionaryCache中,那么在IAgileMultiTree中一定就能找到与之对应的节点,反之亦然。
(4) CreateHiberarchyTree方法返回的多叉树是只读的,这一点要特别注意。因为它只是IHiberarchyCache内部多叉树的一个浅表拷贝,所以对它的修改会导致IHiberarchyCache的内部状态不一致。通常,我使用CreateHiberarchyTree方法都是为了将返回的实例进行持久化存储的。
5.扩展
层级结构缓存IHiberarchyCache暂时没有任何扩展。
注: ESBasic已经开源,点击这里下载源码。
ESBasic开源前言

