
多叉树 IMultiTree -- ESBasic 可复用的.NET类库(22)
1.缘起:
假设我们要描述一个集团公司的组织结构,这个集团公司的体系分为如下几层:集团、公司、子公司、部门、小组。即一个集团由多个公司构成,每个公司又有几个子公司构成,每个子公司拥有多个部门,每个部门又内分为几个小组。
很明显,这种体系结构就是一个多叉树。我设计了ESBasic.ObjectManagement.Trees.Multiple.IMultiTree来抽象多叉树,其提供了很多简便的方法让我们对多叉树进行节点查询和操作。
多叉树的形象示意图如下:
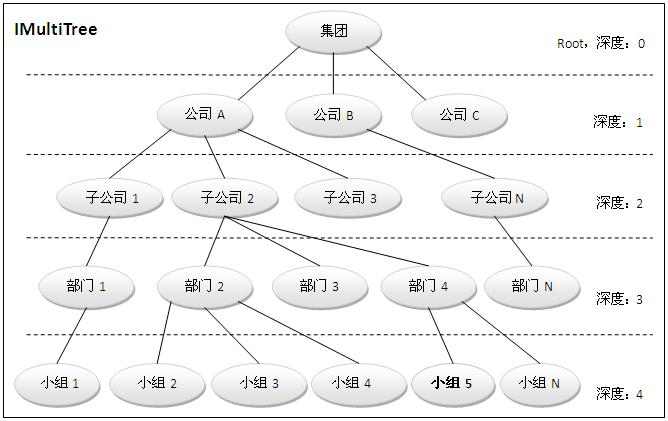
从上图中我们看到,集团是根节点,其深度索引为0。任何一个父节点下都有0~N(N>0)个子节点。并且每往下一层级,节点的深度索引就增加1。
还有一个很重要的概念我要先介绍一下:节点路径(Path),我又称之为序列码(Sequence Code)。所谓节点路径是指从根节点到目标节点的完整路径。比如:“集团,公司A,子公司2,部门4,小组5”就是一个节点路径,根据这个路径我们可以非常迅速地定位到示例图中名为“小组5”的节点。示例路径中使用中文逗号“,”进行分隔,我们将其称之为路径分隔符(Separator)。
2.适用场合:
任何可以使用多叉树来描述数据结构的地方,都可以使用IMultiTree。但是还要额外注意使用MultiTree时必须满足的几个要求:
(1)每个节点都必须有一个唯一的ID。
(2)节点值的ID和FatherID在系统运行的过程中不会发生变化。
(3)节点的ID是string类型,或者可以转化为string类型。(为了更方便地使用节点路径。)
3.设计思想与实现
多叉树是由节点构成的,在ESBasic的多叉树描述中,使用MNode<TVal>泛型类来抽象节点,其定义如下:
/// MNode IMultiTree中的节点类型
/// </summary>
[Serializable]
public class MNode<TVal> where TVal : IMTreeVal
{
#region Ctor
public MNode() { }
public MNode(TVal val ,MNode<TVal> _parent)
{
this.theValue = val;
this.parent = _parent;
}
#endregion
#region Parent
private MNode<TVal> parent;
public MNode<TVal> Parent
{
get { return parent; }
}
#endregion
#region TheValue
private TVal theValue = default(TVal);
public TVal TheValue
{
get { return theValue; }
set { theValue = value; }
}
#endregion
#region Children
private IList<MNode<TVal>> children = new List<MNode<TVal>>();
public IList<MNode<TVal>> Children
{
get { return children; }
set { children = value; }
}
#endregion
#region AddChild
public MNode<TVal> AddChild(TVal child)
{
MNode<TVal> childNode = new MNode<TVal>(child ,this);
this.children.Add(childNode);
return childNode;
}
#endregion
public override string ToString()
{
return this.theValue.ToString();
}
}
从其定义可以看到,一个节点使用了一个List来存储其所有子节点。如果一个节点没有任何子节点,则List中的元素个数为0,而不是List为null。
MNode泛型参数的约束表明,我们的元素要能够存储到IMultiTree的节点中,必须实现IMTreeVal接口,其定义如下:
{
string CurrentID { get;}
string FatherID { get;}
/// <summary>
/// DepthIndex 当前节点在多叉树中的深度索引。Root的深度索引为0。
/// 若不想使用深度索引,请返回-1或负数。
/// </summary>
int DepthIndex { get; }
}
IMTreeVal就是节点的值,简称为“节点值”,它说明了自己的ID、父节点的ID。根据这两个属性,可以确定当前节点在IMultiTree中的位置。IMTreeVal还有一个DepthIndex属性用于指明自己所处位置的深度索引值。
你在实现节点值的时候,除了实现IMTreeVal接口定义的属性外,更重要的是需要把你的系统所需要的信息放在节点值中,比如像类似Name、Level、CreateTime等等数据。
MNode提供了AddChild方法,我们可以直接调用此方法为目标节点增加子节点。
下面我们来看IMultiTree定义:
/// IMultiTree 多叉树基础接口。该接口的实现必须是线程安全的。
/// zhuweisky 2005.07.28
/// </summary>
public interface IMultiTree<TVal> where TVal : IMTreeVal
{
/// <summary>
/// Initialize 使用已经存在的某个树(或子树)来构造一个新树。
/// </summary>
void Initialize(MNode<TVal> _rootNode);
/// <summary>
/// Initialize 通过各个节点的内部值,重新构造多叉树的层级关系。
/// </summary>
void Initialize(TVal rootVal, IList<TVal> members);
/// <summary>
/// Root 返回多叉树的根节点。
/// </summary>
MNode<TVal> Root { get;}
/// <summary>
/// Count 多叉树的当前节点总数。
/// </summary>
int Count {get ;}
/// <summary>
/// GetNodesOnDepthIndex 获取某一深度的所有节点。Root的深度索引为0
/// </summary>
IList<MNode<TVal>> GetNodesOnDepthIndex(int depthIndex);
/// <summary>
/// GetNodesOnDepthIndex 获取所属idPath体系下并且深度为depthIndex的所有节点。Root的深度索引为0
/// </summary>
IList<MNode<TVal>> GetNodesOnDepthIndex(string idPath, char separator ,int depthIndex);
MNode<TVal> GetNodeByID(string valID);
/// <summary>
/// GetNodeByPath 根据节点的ID的路径快速搜索到对应的节点,如idPath--0.1.1.0.2.5。比GetNodeByID效率要高。
/// </summary>
MNode<TVal> GetNodeByPath(string idPath, char separator);
/// <summary>
/// GetOffsprings 获取某个节点的所有子孙节点。
/// </summary>
IList<MNode<TVal>> GetOffsprings(MNode<TVal> curNode);
/// <summary>
/// GetLeaves 获取某个路径下的所有叶子节点。如果Path已经是叶子节点,则返回包含自己的列表。
/// </summary>
IList<TVal> GetLeaves(string path, char separator);
/// <summary>
/// ActionOnEachNode 从root开始对每个节点进行一次action。
/// </summary>
void ActionOnEachNode(CbGeneric<MNode<TVal>> action);
}
初始化Initialize方法有一个重载,其两个方法分别表示可以从节点值列表来从头构造一个多叉树,也可以使用已经存在的多叉树的某个子树来形成一个新树。
GetNodesOnDepthIndex方法用于获取位于某一深度索引上的所有节点。比如,我要获取缘起示例图中的表示部门的所有节点的集合,那么只需要使用参数3(深度索引值)来调用GetNodesOnDepthIndex方法即可。
如果我只想获取公司A下所有部门节点集合,那么可以调用另外一个参数比较多的GetNodesOnDepthIndex重载方法。
对于查询目标节点,IMultiTree提供了两个方法:GetNodeByID和GetNodeByPath。GetNodeByID表示根据节点值的ID进行查找,GetNodeByPath表示根据节点路径进行查找。由于根据节点值的ID查找节点需要对所有节点进行遍历,所以其效率要比GetNodeByPath低很多。所以,在知道节点的路径的情况下,你应该使用GetNodeByPath方法来查找节点。
GetOffsprings方法用于获取当前节点的所有子孙节点的集合。也即,以当前节点为子树的根,获取这个子树中除根意外的所有节点。
GetLeaves方法用于获取某个路径下的所有叶子节点。所谓叶子节点,就是没有任何子节点的节点。比如缘起示例图中深度索引值为4的所有节点都是子节点。位于最大深度索引处的节点一定都是子节点,这是没有问题的。但是,还有一些叶子节点可能位于各个其它的深度索引处。比如缘起示例图中的深度索引值为2的“分公司3”就是一个叶子节点。
ActionOnEachNode方法表示对多叉树中的每个节点执行目标动作,具体动作的内容由方法的参数指示。实际就是使用一个执行因子遍历每个节点。
在了解了IMultiTree接口的面貌之后,我们来看MultiTree的具体实现。
类似MultiTree这样的数据结构的实现中,用到最多的技巧应该就是递归了。在MultiTree的实现中,除了递归外,还要注意以下几点:
(1)MultiTree是可以序列化的,表示其可以被持久化存储或远程传递。
(2)MultiTree是线程安全的,可以在多线程的环境中使用。而且MultiTree使用了读写锁进行线程安全控制,以减少不必要的线程阻塞。
(3)关于使用节点值列表来初始化多叉树的Initialize方法,我们看到其实现时首先判断节点值是否正确实现了 DepthIndex属性,如果有实现该属性,则将节点按照深度索引值分类,然后再按照深度索引的递增顺序初始化多叉树的每一层级。
(4)ActionOnEachNode方法实现时,并没有捕获任何异常,这表示如果针对某个节点的Action抛出异常时,后续的节点将再没有机会执行Action。所以最好确保你的Action不会抛出任何异常。
4. 使用时的注意事项
(1) 关于节点路径(序列码)的另外一个非常合适的用途是当我们使用数据库存储类似组织结构的数据时,可以为对应的Table加上一个SequenceCode列。这个列的值有两个用途:一是可以指明该元素在多叉树中对应的节点所处的完整位置;一是根据SequenceCode我们可以非常直观地知道该元素的直接上级和所有间接上级是谁。
(2) 节点值在实现IMTreeVal接口时,DepthIndex属性并不是必须要实现的,如果在加载树之前不知道每个节点值的DepthIndex,那么可以直接返回-1。但是如果正确实现了DepthIndex属性,那么可以大大加快IMultiTree初始化的速度。这点从MultiTree的Initialize方法可以看出来,如果节点值的DepthIndex属性返回的不是-1,那么在加载节点时,会大大的缩小遍历的范围。
(3) IMultiTree的ActionOnEachNode方法可以看作是一个扩展方法,它使得具体的应用程序可以扩展IMultiTree没有提供的功能。当然,这也可以通过继承IMultiTree来做到。至于选择哪种方式,需要根据扩展量的大小和复杂程度来判定。
(4) IMultiTree并没有直接提供为某个节点增加子节点的方法。如果要为目标节点增加子节点,那么请直接调用目标节点的AddChild方法。
(5) 由于MultiTree的节点是开放的,其节点数可能随时发生变化,所以每次调用Count属性时,都是采用递归统计节点数,而且不能有缓存。如果你的多叉树的节点数量非常多,那么请尽可能少地直接调用该属性进行节点数统计。也许,你可以根据你的多叉树的特点来设计一种能正确缓存节点数量的方案。
5.扩展
关于IMultiTree的最直接的扩展是IAgileMultiTree,由于IAgileMultiTree非常重要,而且使用得也很广泛,所以我们将在下一节全面介绍它。
注: ESBasic已经开源,点击这里下载源码。
ESBasic开源前言

